Chromosome-level genome assembly of Salvia miltiorrhiza with orange roots uncovers the role of Sm2OGD3 in catalyzing 15,16-dehydrogenation of tanshinones
橙根丹参染色体水平基因组组装揭示 Sm2OGD3 催化丹参酮 15,16 - 位脱氢的功能

摘要
丹参是治疗心脑血管疾病的常用传统中药材。其根部因大量积累丹参酮 ⅡA、丹参酮 Ⅰ 等红色色素,通常呈现砖红色。本研究鉴定得到一份橙根丹参株系(shh) 。与普通红根丹参相比,该株系根部中C15、C16 位为单键 的丹参酮含量显著上升,而C15、C16 位为双键 的丹参酮含量明显下降。
本研究完成了橙根丹参 shh 的高质量染色体水平基因组组装 。系统发育基因组分析显示,两份红根丹参材料的亲缘关系更近,表明 shh 并非现有红根丹参株系突变而来。结合比较基因组与转录组分析发现,shh 的Sm2OGD3 基因发生了一段 1.0 kb 片段缺失。基因回补实验证实,在 shh 毛状根中过表达完整Sm2OGD3 ,可恢复呋喃 D 环型丹参酮的积累。
体外酶活实验进一步表明,Sm2OGD3 可分别催化隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ,生成丹参酮 ⅡA、丹参酮 Ⅰ 与 1,2 - 二氢丹参酮 Ⅰ。综上,Sm2OGD3 是丹参酮 15,16 - 脱氢酶,为丹参酮生物合成的关键酶 。本研究结果为解析药用活性成分丹参酮的代谢网络提供了新依据。
引言
丹参是我国经典中药材,也是药用植物生物学研究的模式物种 1,临床上广泛用于心脑血管疾病的治疗,同时对肿瘤、神经退行性疾病等也具有一定防治作用 2,3。丹参根部合成的脂溶性丹参酮是其主要活性成分 4,5。
隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ、亚甲基二氢丹参醌等化合物的 C15、C16 位为单键;而丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ、丹参酮 ⅡA、丹参酮 ⅡB、亚甲基丹参醌的 C15、C16 位则为双键 6,7。
丹参酮的生物合成大致分为四个阶段:首先合成五碳异戊二烯单元 ------ 异戊烯焦磷酸及其异构体二甲基烯丙基焦磷酸;其次生成中间体牻牛儿基牻牛儿基焦磷酸;接着合成萜类母核柯巴基焦磷酸与迷迭香二烯;最后经多步修饰生成各类丹参酮组分 1。目前,前三个合成阶段及相关催化酶基因已基本阐明 8-12,但第四阶段涉及羟基化、氧化、杂环化、脱氢、去甲基化等多种修饰反应,过程复杂,相关分子机制仍有待解析。
现有研究证实,CYP76、CYP71 亚家族的细胞色素 P450(CYP450)参与丹参酮合成。SmCYP76AH1 催化迷迭香二烯羟基化生成铁锈醇;SmCYP76AH3 可进一步将铁锈醇转化为 11 - 羟基铁锈醇、柳杉酚与 11 - 羟基柳杉酚 13,14。11 - 羟基铁锈醇和 11 - 羟基柳杉酚会在 SmCYP76AK1 作用下发生 C20 位羟基化;SmCYP71D411 则催化柳杉酚生成 20 - 羟基柳杉酚 14,15。此外,SmCYP71D375 可催化迷迭香酮、4 - 亚甲基迷迭香酮及 Ro 组分发生羟基化与杂环化,形成 C15、C16 位为单键的 D 环结构,该步反应也可由 SmCYP71D373 催化完成 15。
除 CYP450 外,2 - 氧代戊二酸依赖型双加氧酶(2OGD)超家族也被证实参与丹参酮生物合成 16-18。2OGD 是一类定位于细胞质的非血红素铁氧化酶,也是自然界功能最多样的氧化酶之一 19。该家族蛋白含有保守的2 - 组氨酸 - 1 - 羧酸三联体 (HX (D/E) X50--210H)与 RXS 基序,以二价铁离子为活性中心辅因子,2 - 氧代戊二酸和分子氧为辅底物,催化各类有机底物发生氧化反应 20。其催化的反应类型包括羟基化、脱烷基、去甲基、脱氢、环氧化、差向异构、环化、卤化、过氧化物生成以及环的扩环 / 缩环等 19-23。
目前研究较为深入的 2OGD 主要包括参与赤霉素代谢的赤霉素 20 - 氧化酶、赤霉素 2 - 氧化酶、赤霉素 3 - 氧化酶,以及参与黄酮代谢的黄酮合酶 Ⅰ、黄烷酮 3β- 羟化酶、黄酮醇合酶、无色花色素合酶等 22,23。相较于 CYP450,丹参中 2OGD 的研究仍相对薄弱,但这类基因普遍被认为是丹参酮合成的重要候选基因 16,24。丹参基因组共注释到 132 个Sm2OGD 家族基因 16。已有报道显示,下调Sm2OGD5 表达会显著降低转基因丹参毛状根中迷迭香酮、隐丹参酮和丹参酮 ⅡA 的含量,但该蛋白的催化功能尚不明确 16。另有研究表明,Sm2OGD25 可催化柳杉酚羟基化,生成海帕根素 B 与交格素 C 17;Sm2OGD14 能够分别催化隐丹参酮、异隐丹参酮生成丹参酮 ⅡA、异丹参酮 ⅡA 18。
丹参的根与根茎是传统药用部位,因周皮大量积累丹参酮 ⅡA、丹参酮 Ⅰ 等红色脂溶性成分,外观呈红色,故得名 "丹参"4,5,25,26。本研究以橙根丹参株系 shh 为材料,发现其根部 C15、C16 位单键型丹参酮含量升高,双键型不饱和丹参酮含量显著降低。为解析该表型背后的物质代谢差异,本研究完成了 shh 的染色体水平全基因组测序与组装。结合比较基因组、转录组分析发现,该株系Sm2OGD3 基因存在片段缺失突变。体外酶活与转基因毛状根回补实验证实,Sm2OGD3 负责催化丹参酮 C15、C16 位脱氢。上述结果表明,Sm2OGD3 片段缺失是橙根丹参 shh 中 15,16 - 位不饱和丹参酮含量下降的主要原因。
结果
橙根(shh)与红根(99--3)丹参株系的丹参酮代谢组对比及超高效液相色谱分析
丹参酮主要富集于丹参根的周皮组织中 4,5,多数丹参酮类化合物呈现出从橙色至红色的不同色泽 25,26。例如,丹参酮 ⅡA、丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ 的甲醇溶液为红色,而隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ 的甲醇溶液则呈橙色(图 1d)。
普通丹参株系(如 99--3)的根系因大量积累丹参酮 ⅡA、丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ 等红色丹参酮,整体表现为砖红色(图 1b)。本研究发现一份天然丹参株系,其根系为橙色(图 1a)。该株系于 1999 年在我国陕西省首次发现,后移栽至中国医学科学院药用植物研究所试验苗圃,通过根插方式繁育至今已有约 20 年,将其命名为山黄(shh) 。
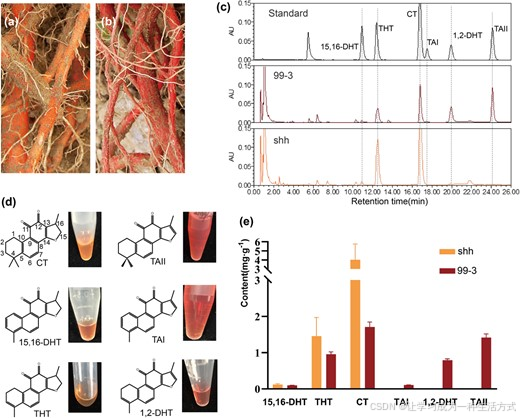
图 1 丹参株系 shh 与 99--3 中丹参酮的超高效液相色谱分析
橙根株系 shh (a) 与红根株系 99--3 (b) 的根系表型差异;(c) 99--3 和 shh 成熟根系的超高效液相色谱检测图谱;(d) 各类丹参酮单体的显色特征。其中隐丹参酮、丹参酮 ⅡA 浓度均为 2 mg/mL,15,16 - 二氢丹参酮 Ⅰ、丹参酮 Ⅰ 浓度为 0.5 mg/mL,1,2,15,16 - 四氢丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ 浓度为 1 mg/mL;(e) shh 与 99--3 成熟根系中各丹参酮组分的含量。误差线代表标准误 。缩写说明:CT = 隐丹参酮;TAII = 丹参酮 ⅡA;15,16-DHT=15,16 - 二氢丹参酮 Ⅰ;TAI = 丹参酮 Ⅰ;THT=1,2,15,16 - 四氢丹参酮 Ⅰ;1,2-DHT=1,2 - 二氢丹参酮 Ⅰ。
为解析 shh 株系的化学成分变化,本研究对 99--3 与 shh 的根系样本开展代谢组对比分析。采用正交偏最小二乘判别分析(OPLS-DA) 筛选差异代谢物,筛选标准:变量重要性投影值(VIP)>1.0、P <0.05、差异倍数>1.5 或 <0.67。共鉴定出 29 个含量存在显著差异的代谢物,其中丹参酮 ⅡA、隐丹参酮、1,2,15,16 - 四氢丹参酮 Ⅰ、丹参酮 Ⅰ 为 VIP 值排名前四的组分(附表 S1)。C15、C16 位含双键的丹参酮 ⅡA、丹参酮 Ⅰ、丹参酮甲酯,含量分别下调至原来的 1/17.78、1/46.24、1/39.06;而 C15、C16 位为单键的丹参酮类物质,包括 1,2,15,16 - 四氢丹参酮 Ⅰ、隐丹参酮、甲基隐丹参酮、隐丹参酮酸酐,含量分别上调 2.24 倍、1.76 倍、3.87 倍、19.76 倍。此外,丹参酮合成通路上游产物柳杉酚、迷迭香酮 Ⅰ、脱氢迷迭香酮的含量也分别提升 2.00 倍、1.94 倍、2.56 倍。
利用超高效液相色谱(UPLC)进一步验证两株系间丹参酮积累的显著差异(图 1c)。红根株系 99--3 中,C15、C16 位双键型的丹参酮 ⅡA、丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ 含量依次为 1.42 mg/g、0.11 mg/g、0.79 mg/g(鲜重),而这三类物质在 shh 根系中几乎检测不到(图 1e)。与之相反,shh 根系中 C15、C16 位单键型的隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ 含量,分别为 99--3 株系的 2.36 倍、1.23 倍、1.52 倍(图 1e)。综合以上结果可推断:shh 株系体内丹参酮的 15,16 - 位脱氢过程受到抑制 。
橙根丹参株系 shh 的染色体水平基因组组装
目前已有四份红根丹参的全基因组组装数据发表 15,27-29,但尚无橙根丹参的基因组序列。为挖掘调控 shh 丹参酮合成差异的关键基因,本研究完成了该橙根株系染色体水平全基因组组装 (图 2a)。
基于 28.73 Gb 二代 Illumina 短读长数据开展 17-mer 分析,预估 shh 基因组大小为 581.68 Mb,基因组杂合度为 1.34%(附表 S2)。本研究整合多种测序技术开展基因组测序(附表 S3),最终获得 64.90 Gb PacBio 长读长数据、66.57 Gb Illumina 二代数据以及 124.14 Gb 10×Genomics 条码测序数据。
初步组装得到基因组总长 530.97 Mb,支架 N50 为 2.01 Mb,重叠群 N50 为 1.05 Mb,覆盖预估基因组大小的 91.28%。其重叠群 N50 长度,是以往丹参基因组组装版本的 2~83 倍(表 2)。
进一步利用 133.51 Gb Hi-C 数据辅助染色体挂载 30,最终将 371 个支架(总长 496.5 Mb,占组装基因组的 93.51%)锚定至 8 条假染色体 (附图 S1、S2)。经 Hi-C 优化后,超级支架 N50 达到 60.28 Mb,最长支架长度为 77.73 Mb(表 1、附表 S4)。
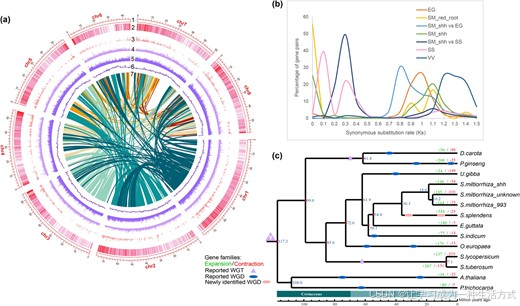
图 2 丹参株系 shh 的基因组特征、同义替换率分布及系统发育基因组分析
(a) shh 基因组组装全景图。最外层空心区块代表 8 条假染色体 ;第 2 至第 5 圈依次为基因密度、shh 幼根与成熟根间差异表达基因密度、长末端重复序列、转座元件分布;第 6、7 圈分别为 GC 含量及共线性区块分布。(b) 沟酸浆、红根丹参、橙根丹参 shh、一串红、葡萄的旁系同源基因同义替换率(Ks )分布,以及 shh 分别与一串红、沟酸浆共线性区块中同源基因对的Ks 分布。(c) shh 与其他 13 个物种的系统发育树,包含:3 份丹参材料(99--3、未知品系丹参)、一串红、沟酸浆、芝麻、狸藻、油橄榄、番茄、马铃薯、人参、胡萝卜、拟南芥、毛果杨。
利用 BWA 软件将二代 Illumina 短读长序列比对至组装基因组,以此评估组装完整性与测序均一性 31。结果显示,序列比对率达 95.96%,基因组覆盖率 99.74%,平均测序深度为 46.77%。进一步采用 BUSCO、CEGMA 开展评估 32,33,分别鉴定出 88% 的单拷贝直系同源基因、89.52% 的真核生物核心保守基因(附表 S5)。以上结果表明,橙根丹参 shh 的染色体水平基因组组装具备高连续性与高完整性。
结合同源比对与从头预测两种方法,对基因组重复序列进行鉴定(附表 S6、S7)。结果显示,shh 基因组中重复序列占比约 56.65%(图 2a);其中长末端重复序列(LTR) 为最主要的转座元件,占全基因组的 49.30%。
综合从头预测、同源预测、转录组辅助预测 三种策略,共注释得到 32191 个蛋白编码基因,编码区(CDS)平均长度为 1191 bp(表 1、附表 S8)。基因总数与已发表的丹参基因组数据相近(表 2)。在全部蛋白编码基因中,30538 个基因(占 94.9%)完成功能注释,注释数据库包括瑞士蛋白库、非冗余蛋白库、京都基因与基因组百科全书、蛋白结构域数据库、基因本体论、蛋白家族数据库等(附表 S9)。
系统发育基因组分析解析橙根株系 shh 的演化地位
获得完整基因组后,本研究进一步探究 shh 的演化起源。将 shh 基因组与其他植物基因组开展比对,比对材料包括:6 种鼠尾草属植物(丹参 99--3、未知品系丹参、丹参 DSS3、南丹参、西班牙鼠尾草、一串红)、7 种唇形目植物(沟酸浆、芝麻、狸藻、油橄榄、黄芩)、2 种茄科植物(番茄、马铃薯)、2 种伞形目植物(人参、胡萝卜),以及拟南芥、毛果杨。基于单拷贝基因家族,采用最大似然法 构建系统发育树。
|------------------------------------------------|---------------|
| Parameter | Value |
| Estimated genome size (by k -mer analysis) | 581.68 Mb |
| Assembly size | 530.97 Mb |
| Contig N50 | 1.05 Mb |
| Scaffold N50 | 2.01 Mb |
| Scaffold N50 (after Hi-C) | 60.28 Mb |
| Longest scaffold | 77.73 Mb |
| Chromosome anchoring rate | 94.9% |
| Number of protein-coding genes | 32 191 |
| Average transcript length | 3034 bp |
| Average CDS length | 1191 bp |
|--------------|---------------------|------------------------------------------|-----------------------------|------------------------|----------------------|-----------------------------------------------|
| Line | Genome size | Sequencing strategy | Contig/Scaffold N50 | Assembly level | Completeness | No. of annotated protein coding genes |
| Unknown | 641 Mb | Illumina PacBio RS II | 82.8 Kb/1.2 Mb | Scaffold | 89.11% | 34 598 |
| 99--3 | 538 Mb | Illumina PacBio RS II Roche 454 | 12.38 Kb/51.02 Kb | Scaffold | NA | 30 478 |
| DSS3 | 594.75 Mb | PacBio Sequel Hi-C | 2.7 Mb/NA | Chromosome | 92.5% | 32 483 |
| bh2--7 | 557 Mb | Illumina PacBio RS | 505.21 Kb/1.26 Mb | Scaffold | 91.10% | 33 760 |
| shh | 530.97 Mb | PacBio Sequel Illumina 10X Genomics Hi-C | 1.01 Mb/2.01 Mb | Chromosome | 89.52% | 32 191 |
系统发育树结果显示,3 份丹参株系与一串红聚为一支;丹参与一串红的共同祖先大约在3630 万年前(MYA) 发生分化(图 2c)。值得注意的是,两份红根丹参株系亲缘关系很近,分化时间约为 1620 万年前;而橙根株系 shh 与红根丹参的共同祖先分化时间则约为 1860 万年前(图 2c)。
本研究进一步将丹参 DSS3、南丹参、西班牙鼠尾草、黄芩纳入分析并构建新的系统发育树,结果显示南丹参与多份丹参株系聚群,且和红根丹参 99--3 的亲缘关系最近(附图 S3)。南丹参与丹参 99--3 的分化时间约为 1040 万年前(附图 S4)。已有研究表明,在唇形科演化支中,南丹参与丹参的分化时间约为 394 万年前 34,说明二者在分子水平上相似度极高,且南丹参根部在实际应用中可作为丹参的替代品 34。shh 与丹参 99--3、南丹参的共同祖先分化时间约为 1380 万年前(附图 S4)。
橙根株系 shh 与各红根丹参、南丹参聚类在一起,证明 shh 并非现有红根丹参株系的突变体 。据此推测,shh、红根丹参与南丹参的共同祖先应为红根类型物种。
本研究继而探究:橙根丹参是否发生了物种特异性全基因组复制(WGD) ,并由此导致丹参酮积累模式改变。为此,我们对旁系同源基因及共线性区块开展同义替换率(Ks) 分布分析。结果表明,一串红在与丹参分化后,先后发生了两次物种特异性全基因组复制事件;而 shh 未检测到近期全基因组复制事件,各红根丹参株系同样无近期全基因组复制发生(图 2b)。这说明无近期全基因组复制是丹参物种的共有特征 ,shh 体内丹参酮含量变化并非由全基因组复制导致。
橙根(shh)与红根(99--3)丹参中丹参酮合成相关已知基因的转录组比较分析
丹参酮属于脂溶性二萜类天然产物,经由萜类生物合成途径生成。目前已在红根丹参中鉴定出 19 个参与丹参酮合成的酶编码基因家族 1。为明确这类基因在 shh 中的特征,本研究在 shh 基因组中,对上述已报道的功能基因进行全基因组同源基因鉴定 8,9,11-13,15,结果在 shh 基因组中均能找到对应的同源基因(附表 S10)。
转录组差异分析显示,在成熟根周皮组织中,这类基因在 shh 与 99--3 中的表达水平无显著差异(图 3)。上述结果表明,shh 丹参酮积累的改变,并非由已知合成酶基因功能缺失或表达量大幅变化引起 。
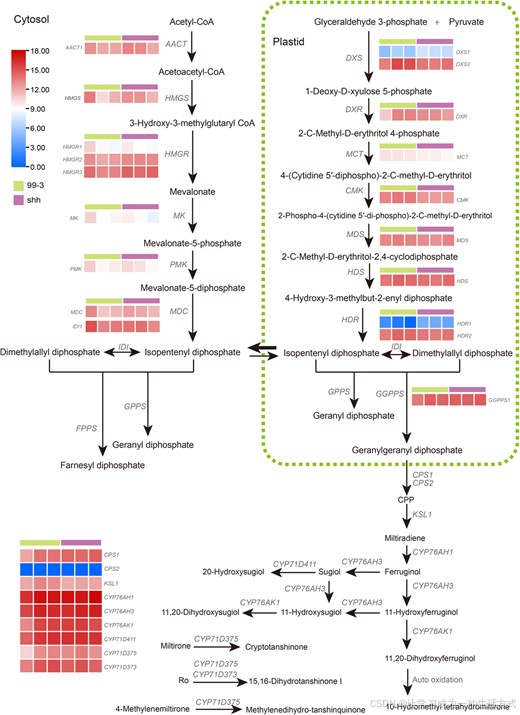
图 3 shh 与 99--3 成熟根周皮中丹参酮合成相关已知基因的转录组分析
每份株系设置 3 个生物学重复;表达量采用经ZeroToOne 标准化 后取对数的TPM 值展示。
比较基因组与转录组联合分析证实:橙根株系 shh 的 Sm2OGD3 发生片段缺失突变
为进一步解析 shh 丹参酮组分改变的分子机制,本研究利用 99--3 与 shh 成熟根周皮的转录组数据开展差异分析 24。以校正后P 值(padj)<0.05 为筛选阈值,共鉴定得到 3416 个差异表达基因(DEG)(附图 S5),其中 2162 个基因在 shh 中表达下调,包含 12 个Sm2OGD 家族基因(图 4a)。
2 - 氧代戊二酸依赖型双加氧酶(2OGD)是一大类氧化酶,近年研究证实丹参 2OGD 家族成员参与丹参酮的生物合成 16-18,24。为筛选催化生成 C15、C16 位双键型丹参酮的候选Sm2OGD 基因,本研究设定三项筛选标准:① 相较于 99--3,基因在 shh 根周皮中显著下调;② 在 99--3 根周皮中高表达;③ 在花、茎、叶、根等不同组织中,特异性在 99--3 根系高表达。
聚类热图结果显示,12 个下调的Sm2OGD 基因中,SMil_00016113、SMil_00018668、SMil_00020342 与丹参酮合成通路关键基因(SmCYP76AH1 、SmCYP76AH3 、SmCYP76AK1 、SmCYP71D411 、SmCYP71D373 、SmCYP71D375 )存在共表达关系(图 4a、附图 S6)。
结合已有研究 16 分析发现,SMil_00020342 在 99--3 茎中的表达量远高于根系(附图 S7),说明该基因与丹参酮合成无关。因此,最终选取SMil_00016113 与SMil_00018668 开展后续研究。
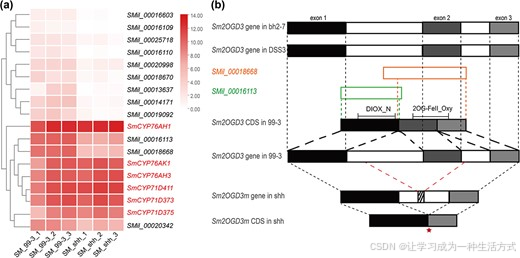
图 4 丹参 Sm2OGD3 基因的基因组与转录组分析
(a) 热图展示 12 个差异表达Sm2OGD 基因在 shh 与 99--3 成熟根周皮中的表达水平。聚类分析结果显示,SMil_00016113、SMil_00018668、SMil_00020342 的表达模式,与已知参与丹参酮合成的SmCYP76AH1 、SmCYP76AH3 、SmCYP76AK1 、SmCYP71D411 、SmCYP71D373 、SmCYP71D375 高度相似。(b) 丹参 bh2--7、DSS3、99--3 与 shh 株系中Sm2OGD3 基因的序列比对分析。Sm2OGD3 基因包含3 个外显子 (实心方框)和2 个内含子 (带黑框白色方框);99--3 基因组注释得到的两个基因模型 SMil_00018668、SMil_00016113,分别以橙框、绿框白色方框标示。图中标注了 Sm2OGD3 蛋白的两个保守结构域:DIOX_N 与 2OG-FeII_Oxy。红色虚线表示突变基因Sm2OGD3m 缺失一段 1.0 kb 片段,该片段包含完整的第二个外显子,以及部分第一段、第二段内含子序列;红色星号代表第一个提前终止密码子。
已有研究将SMil_00018668 命名为Sm2OGD3 16。利用 NCBI 非冗余蛋白数据库开展 ** 蛋白序列比对(BLASTp)** 发现,SMil_00016113 与 SMil_00018668 编码的均为不完整蛋白:仅含 DIOX_N 结构域的 SMil_00016113,对应 2OGD 基因的 5' 端区域;含 2OG-FeII_Oxy 结构域的 SMil_00018668,则对应基因的 3' 端区域(图 4b)。
为明确二者来源,本研究将两条序列分别与 3 份红根丹参(99--3 28、bh2--7 15、DSS3 29)的基因组序列进行核酸序列比对(BLASTn) 。结果显示,在 bh2--7 与 DSS3 基因组中,两个序列均定位至同一个含 3 个外显子的Sm2OGD 基因:其中 SMil_00016113 对应第一个外显子,SMil_00018668 对应第二、第三个外显子(图 4b)。
将序列比对至 99--3 基因组时发现,SMil_00016113 位于 5164 号支架,SMil_00018668 位于 2881 号支架。由于 99--3 基因组组装质量相对偏低,推测两个序列存在组装错位。为验证二者在 99--3 中是否源自同一个Sm2OGD 基因,本研究设计特异性引物(附表 S11),分别以 99--3 根系 ** 基因组 DNA(gDNA)和 互补 DNA(cDNA)** 为模板进行 PCR 扩增。实验证实,SMil_00016113 与 SMil_00018668 确实属于 99--3 中的同一个Sm2OGD 基因(图 4b)。
基于上述结果,本研究校正得到 99--3 中Sm2OGD3 的全长基因组序列与编码区序列(附表 S12)。校正后的编码区序列开放阅读框全长 1119 个核苷酸,编码 373 个氨基酸。
将 SMil_00016113 与 SMil_00018668 比对至 shh 基因组,仅匹配到一段 1.2 kb 的基因组序列:该序列 5' 端对应 SMil_00016113,3' 端对应 SMil_00018668 的 3' 区,但缺失了 SMil_00018668 的 5' 端序列(图 4b)。与 99--3 正常Sm2OGD3 相比,shh 的这段序列缺失约 1.0 kb 片段,对应完整第二个外显子,以及部分第一、第二个内含子。本研究将 shh 中的该突变基因命名为Sm2OGD3m 。
使用同一组引物,以 shh 根系基因组 DNA 和 cDNA 为模板再次开展 PCR 扩增,并结合Sm2OGD3m 全长基因组序列与编码区序列(附表 S12)分析发现:片段缺失破坏了原有剪接位点,使Sm2OGD3m 发生外显子跳跃型可变剪接 ,编码区仅保留第一、第三个外显子;同时阅读框偏移,导致翻译提前终止 。其第一个终止密码子出现在第 541--543 位核苷酸,最终仅编码 180 个氨基酸的截短蛋白,蛋白中关键的2 - 组氨酸 - 1 - 羧酸三联体保守基序 与 RXS 保守基序完全丢失 20。
Sm2OGD3 重组蛋白可催化丹参酮 15,16 - 位脱氢
为验证 Sm2OGD3 是否具备催化丹参酮 15,16 - 位脱氢的功能,本研究从 99--3 根系中扩增获得Sm2OGD3 全长 cDNA,并将其连接至大肠杆菌表达载体pET-30a (附图 S8a)。随后在大肠杆菌 BL21 (DE3) 菌株中诱导表达,获得 Sm2OGD3 重组蛋白(附图 S8b)。
开展体外酶活实验 ,以转入空 pET-30a 载体的大肠杆菌作为阴性对照。将粗酶液分别与 C15、C16 位为单键的隐丹参酮(CT)、1,2,15,16 - 四氢丹参酮 Ⅰ(THT)、15,16 - 二氢丹参酮 Ⅰ(15,16-DHT)共孵育,利用乙酸乙酯萃取反应产物,再通过 ** 液相色谱 - 质谱联用(LC-MS)** 检测,并将二级质谱(MS-MS)图谱与标准品比对。
结果显示:隐丹参酮、1,2,15,16 - 四氢丹参酮 Ⅰ、15,16 - 二氢丹参酮 Ⅰ 可分别被催化转化为丹参酮 ⅡA、1,2 - 二氢丹参酮 Ⅰ、丹参酮 Ⅰ(图 5);而转入空载体的对照组未检测到上述转化反应(图 5)。证实Sm2OGD3 重组蛋白可将丹参酮 C15、C16 位的单键催化生成双键 。
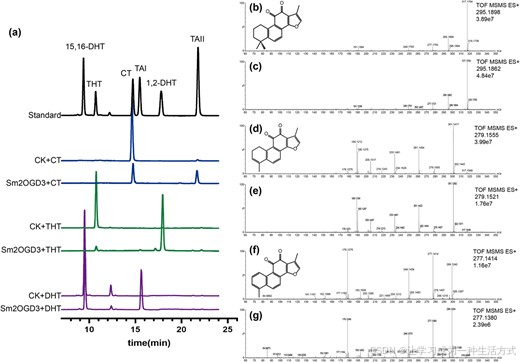
图 5 Sm2OGD3 重组蛋白的体外酶活检测
(a) 分别以隐丹参酮、1,2,15,16 - 四氢丹参酮 Ⅰ、15,16 - 二氢丹参酮 Ⅰ 为底物,采用超高效液相色谱分析 Sm2OGD3 催化的反应产物;以转入空 pET-30a 载体的大肠杆菌粗酶液作为对照组(CK)。反应辅因子为 160 μM 2 - 氧代戊二酸与 50 μM 硫酸亚铁。(b~g) 反应产物与标准品的二级质谱图比对。依次为标准品丹参酮 ⅡA (b)、1,2 - 二氢丹参酮 Ⅰ(d)、丹参酮 Ⅰ(f) 的质谱图;以及反应产物质谱图:Sm2OGD3 + 隐丹参酮(保留时间 21.69 min,c)、Sm2OGD3+1,2,15,16 - 四氢丹参酮 Ⅰ(保留时间 17.78 min,e)、Sm2OGD3+15,16 - 二氢丹参酮 Ⅰ(保留时间 15.46 min,g)。每张图谱右上角标注响应值与准分子离子分子量,同时附丹参酮 ⅡA、1,2 - 二氢丹参酮 Ⅰ、丹参酮 Ⅰ 的化学结构式。
缩写说明:CT = 隐丹参酮;TAII = 丹参酮 ⅡA;15,16-DHT=15,16 - 二氢丹参酮 Ⅰ;TAI = 丹参酮 Ⅰ;THT=1,2,15,16 - 四氢丹参酮 Ⅰ;1,2-DHT=1,2 - 二氢丹参酮 Ⅰ
本研究以 15,16 - 二氢丹参酮 Ⅰ 为底物,进一步探究反应体系各组分对酶活性的影响(附图 S9)。结果显示:反应体系中抗坏血酸 缺失时,单纯提高 2 - 氧代戊二酸与二价铁离子浓度,无法显著提升反应速率(实验组 1、2、6、7);仅去除二价铁离子,与仅去除抗坏血酸的反应速率相近(实验组 3);体系同时含有二价铁离子与抗坏血酸时,反应速率显著上升(实验组 4、5)。
以隐丹参酮为底物,设置不同温度(20℃、30℃、37℃)与 pH 值(5.8、6.5、7.3、8.0)筛选最优反应条件,确定最适温度为 30℃,最适 pH 为 8.0 (附图 S10)。
采用最优条件与实验组 5 的反应体系,测定不同底物浓度下的酶促反应速率。测得 Sm2OGD3 针对隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ 的米氏常数 (\(K_m\)) 分别为 32.15 μM、55.42 μM、20.92 μM,最大反应速率 (\(V_{max}\)) 依次为 0.3318 μM/min、1.228 μM/min、0.7303 μM/min(附图 S11)。结果表明,该酶对 1,2,15,16 - 四氢丹参酮 Ⅰ 的底物亲和力最高,其次为隐丹参酮。
结合丹参植株根系物质含量分析:天然根系中隐丹参酮含量高于 1,2,15,16 - 四氢丹参酮 Ⅰ,产物丹参酮 ⅡA 含量也高于 1,2 - 二氢丹参酮 Ⅰ(图 1c),底物与对应产物的积累水平整体相近。这说明 Sm2OGD3 的催化转化效率,很大程度上依赖于底物浓度。
完整 Sm2OGD3 可恢复橙根株系 shh 转基因毛状根中 C15、C16 位双键型丹参酮的合成
本研究利用携带Sm2OGD3 完整开放阅读框重组载体的发根农杆菌 ACCC10060 侵染橙根丹参 shh,获得转基因毛状根;以不含目的基因的 ACCC10060 菌株处理组作为空白对照。
超高效液相色谱检测结果显示:未转入完整Sm2OGD3 的 shh 毛状根中,检测不到丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ、丹参酮 ⅡA,与 shh 植株根系的物质特征一致(图 1)。
在转入完整Sm2OGD3 的转基因毛状根中(图 6a~d),C15、C16 位双键型丹参酮恢复积累(图 6e)。其中 4 号、5 号、8 号株系的丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ、丹参酮 ⅡA 平均含量分别为 0.045 mg/g、0.024 mg/g、0.037 mg/g(鲜重)。
与此同时,根系内 C15、C16 位单键型丹参酮含量显著下降:隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ 的含量,分别降至对照组的 1/1.28、1/5.25、1/1.52(图 6f)。
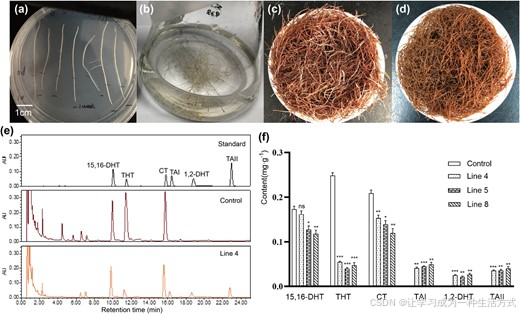
图 6 丹参转基因毛状根的超高效液相色谱分析
(a~d) 转基因毛状根生长状态:(a) 转基因毛状根在含 50 mg/L 潮霉素的筛选培养基上生长一周,潮霉素抗性植株长势正常;(b) 液体培养基中培养的转基因毛状根;(c) 8 号转基因株系成熟毛状根;(d) 对照组(shh)成熟毛状根。(e) 4 号转基因株系与对照组成熟毛状根的超高效液相色谱比对结果。(f) 转基因毛状根与对照组中隐丹参酮、丹参酮 ⅡA、15,16 - 二氢丹参酮 Ⅰ、丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ 的含量对比。误差线代表标准误 ;*P<0.05,**P<0.01,***P<0.001,ns 表示差异不显著。
鼠尾草属植物中 Sm2OGD3 的同源基因
本研究开展期间,另有报道鉴定出Sm2-ODD14 ,该基因被命名为丹参酮 ⅡA 合酶(SmTIIAS ),其编码蛋白可分别催化隐丹参酮、异隐丹参酮生成丹参酮 ⅡA、异丹参酮 ⅡA(图 7)18。序列比对显示,SmTIIAS 与Sm2OGD3 开放阅读框序列一致性达 98.6%,氨基酸序列一致性为 97.3%。二者均能催化隐丹参酮转化为丹参酮 ⅡA,但底物谱存在差异:SmTIIAS 底物特异性极强,仅识别隐丹参酮与异隐丹参酮;而Sm2OGD3 底物范围更广,可利用隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ 作为反应底物。
为厘清两个基因的关系,本研究在 2 份丹参株系(99--3、DSS3)及多个已有基因组数据的鼠尾草属物种(南丹参、一串红、药用鼠尾草)中,分别鉴定这两个基因。结果发现,在以上 5 种鼠尾草属植物中,Sm2OGD3 与SmTIIAS 的基因组定位完全一致(附表 S13)。这表明丹参中并非同时存在这两个独立基因,二者实为不同丹参株系中的等位基因 。
为进一步验证各等位基因及同源基因的催化功能,本研究人工合成SmTIIAS 及新鉴定的同源基因序列(附表 S12、附图 S12)。体外酶活实验结果表明:与Sm2OGD3 一致,SmTIIAS 、丹参 DSS3 的Sm2OGD3_DSS3 、南丹参的Sb2OGD3 均可催化隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ,分别生成丹参酮 ⅡA、丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ(附图 S13)。而一串红的Ss2OGD3_like 与药用鼠尾草的So2OGD3_like 无法催化该步 15,16 - 位脱氢反应(附图 S13)。
该结果与物种代谢表型相符:南丹参根部丹参酮含量较高,可作为丹参的药用替代品 34;而药用鼠尾草与一串红体内的隐丹参酮、丹参酮 ⅡA、丹参酮 Ⅰ 含量极低,甚至无法检出 35,36。
讨论
丹参兼具较高经济价值与药用价值,现已成为药用植物生物学研究的模式物种,受到学界广泛关注 1。目前已积累大量丹参不同组织、不同处理条件下的转录组与小 RNA 组数据,同时 4 份红根丹参株系的全基因组也已完成测序与组装 1,15,27-29。
本研究结合二代双端测序、10X Genomics、PacBio 长读长测序等多种技术,完成了新型橙根丹参株系 shh 的染色体水平基因组组装。该基因组总长 530.97 Mb,其中 93.51% 的序列锚定至 8 条假染色体;超级支架 N50 达 60.28 Mb,最长支架长度为 77.73 Mb,组装连续性与完整性优异,为解析丹参活性成分合成的功能基因组学研究奠定了重要基础。
由于 99--3 基因组组装质量欠佳,本研究选用组装至染色体水平的丹参 DSS3 基因组,利用 MCScanX 软件基于蛋白序列比对开展共线性分析。结果显示,shh 与 DSS3 基因组的编码基因在全基因组范围内共线性程度较高(附图 S14)。DSS3 的Sm2OGD3_DSS3 (编号:GWHGAOSJ020467)定位于 7 号假染色体,无对应共线性片段;shh 的Sm2OGD3m 位于 7 号假染色体(位置:311089--309911)。此外,DSS3 3 号、5 号假染色体上的部分片段,在 shh 假染色体中未找到对应共线性区块(附图 S14)。若要系统解析基因组结构变异,还需开展全基因组序列比对,并结合 DSS3 与 shh 的二代、三代测序数据,利用更完善的生物信息学方法深入分析。
与常规砖红色根系丹参不同,shh 株系根系呈橙色。代谢组与超高效液相色谱检测证实,该株系体内 C15、C16 位为单键的丹参酮含量上升,双键型丹参酮含量显著下降,这一物质积累特征与另一橙根丹参株系报道一致 25。
已有转录组研究显示,橙根丹参中 4 个内质网相关蛋白降解通路基因表达上调,而细胞色素 P450、烟酰胺辅酶依赖型脱氢酶与还原酶相关基因无明显下调 25。据此推测,催化 15,16 - 位脱氢的酶发生折叠异常,并经由内质网相关降解途径被降解,最终导致呋喃 D 环型丹参酮含量降低 25。
本研究明确 Sm2OGD3 是催化丹参酮 15,16 - 位脱氢的关键酶;shh 中的Sm2OGD3 因缺失第二个外显子,翻译产生截短蛋白Sm2OGD3m 。由此证实,shh 体内单键型丹参酮积累、双键型丹参酮减少,主要由 Sm2OGD3 功能丧失所致 。
参照前人研究 25,本研究在丹参 99--3 中鉴定出内质网相关降解通路基因(除c91931_g1 外,附表 S14)。其中SMil_00017121 在 shh 中显著上调,对数倍变化值为 2.6,校正后P 值为 0.0015;SMil_00006173 与SMil_00005538 在两株系根周皮中无显著表达差异。基因c80749_g2 注释为内质网腔结合蛋白(BIP)25;SMil_00017121 经数据库注释,属于热休克蛋白 HSP70 家族的内质网腔结合蛋白。
以上结果提示,shh 中截短型 Sm2OGD3 蛋白发生折叠错误,进而触发内质网相关蛋白降解过程。本研究证实橙根株系 shh 的Sm2OGD3 存在突变,而其他橙根丹参株系是否携带相同突变,仍有待进一步验证。本成果也为解析丹参橙根表型的形成机制提供了重要理论依据。
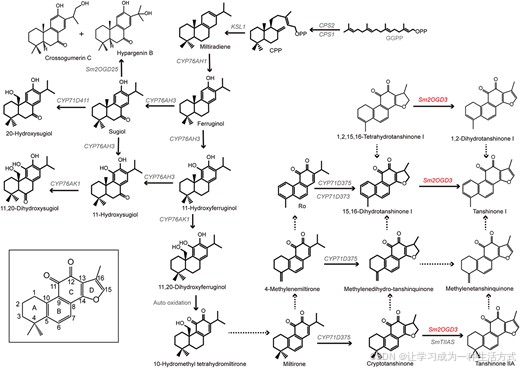
图 7 推测的丹参酮生物合成通路
实线箭头代表已验证的催化反应,虚线箭头代表推测的反应。
植物 2OGD 超家族分类与功能分析
植物 2 - 氧代戊二酸依赖型双加氧酶(2OGD)超家族主要分为DOXA、DOXB、DOXC 三大类 23。其中 DOXA 与 DOXB 家族成员主要参与 DNA 修复、组蛋白去甲基化、蛋白质翻译后修饰等初级代谢过程 23;DOXC 家族除参与植物激素保守代谢通路外,还负责合成酚酸、生物碱等特化次生代谢产物 21。
丹参株系 99--3 基因组共注释到 132 个Sm2OGD 基因,包括 3 个 DOXA 类、8 个 DOXB 类、118 个 DOXC 类,另有 3 个暂未分类 16。118 个 DOXC 家族成员可进一步划分为 13 个进化分支,分别为 ACO、AOP、CODM/NCS、D4H/GSLOH/BX6、DAO、F3H、FLS/ANS、GA2ox、GA3ox、GA20ox、H6H、S3H 及未知分支 16。本研究中的Sm2OGD3 归属于D4H/GSLOH/BX6 分支。
shh 株系中 12 个显著下调的Sm2OGD 基因,分属 DOXC 家族的 6 个不同分支。本研究结合基因组与转录组比对、体外酶活、体内回补实验证实,Sm2OGD3 是催化丹参酮发生 15,16 - 位脱氢的关键酶。来自其他丹参株系及南丹参的 Sm2OGD3 同源蛋白,同样可催化隐丹参酮、15,16 - 二氢丹参酮 Ⅰ、1,2,15,16 - 四氢丹参酮 Ⅰ,分别生成丹参酮 ⅡA、丹参酮 Ⅰ、1,2 - 二氢丹参酮 Ⅰ。
上述结果明确了 Sm2OGD3 在丹参酮合成关键步骤 ------15,16 - 位脱氢反应中的催化功能(图 7)。该酶的鉴定,对解析丹参酮合成通路与调控机制具有重要意义,也为这类高药用、经济价值活性成分的合成生物学研究提供了基础。
材料与方法
文库构建与测序
参照试剂盒说明书,采用十六烷基三甲基溴化铵(CTAB)法 提取 shh 叶片基因组 DNA(gDNA)37。
- Illumina 测序文库 :利用 Covaris 超声仪将基因组 DNA 随机打断,依次进行末端修复、加 A 尾、连接测序接头、模板纯化及 PCR 扩增,构建短片段文库,采用 Illumina 双端测序平台完成测序。
- PacBio 长读长文库 :向基因组 DNA 连接发夹型接头,构建 SMRTbell 文库,再加入测序引物与 DNA 聚合酶,使用 PacBio Sequel 平台开展单分子实时测序。
- 10× Genomics 文库 :将含条形码、测序引物的凝胶微球与随机引物结合,再与 DNA 片段混合并包裹于油相体系;经 PCR 扩增后连接 Illumina P7 接头,最终上机测序。
基因组组装与质量评估
使用 FALCON 软件基于 PacBio 长读长完成初步重叠群组装,再通过 FALCON-Unzip 进行分型;借助 Quiver 软件利用 PacBio 数据对重叠群进行校正 38,随后使用 Pilon 软件结合 Illumina 数据进一步提升组装质量 39。
由于丹参基因组杂合度较高,采用purge_haplotigs软件去除冗余单倍型序列 40;再利用 fragScaff 软件结合 10× Genomics Linked-reads 数据完成支架搭建 41。
将 Illumina 短读长序列比对至组装基因组,统计比对率、基因组覆盖率与测序深度,评估组装完整性与测序均一性;同时采用 CEGMA 33 和 BUSCO 32 软件评估基因组组装完整度。
Hi-C 文库构建与染色体挂载
Hi-C 文库构建
使用多聚甲醛对基因组 DNA 进行交联固定,再经酶切、生物素标记末端;利用 T4 DNA 连接酶使邻近染色质 DNA 片段发生连接,随后加入蛋白酶解除蛋白交联并纯化基因组 DNA。将 DNA 随机打断至 350 bp 左右,通过亲和磁珠富集带生物素标记的片段,依次完成末端修复、加 A 尾、接头连接、PCR 扩增与模板纯化,最终构建完成 Hi-C 文库,采用 Illumina HiSeq PE150 平台测序。
染色体挂载
将过滤后的 Hi-C 测序读段比对至基因组草图,利用 SAMtools 软件rmdup参数去除重复序列与未比对读段 42,筛选含连接位点的有效读段用于辅助组装。使用 LACHESIS 软件(版本 201701)完成重叠群的染色体定位、排序与方向校正。
基因组注释
本研究结合同源比对 与从头预测 两种方法完成重复序列注释 43。利用 RepeatMasker 软件(官网:http://www.repeatmasker.org/),将基因组序列与重复序列数据库 Repbase 比对,实现同源类重复序列注释;使用串联重复序列识别工具 TRF(官网:http://tandem.bu.edu/trf/trf.html)提取基因组中的串联重复序列。
通过 LTR_FINDER 44、RepeatScout、RepeatModeler 开展从头预测,构建物种特异性重复序列数据库。筛选长度大于 100 bp、空缺碱基(N)占比低于 5% 的序列,构建原始转座元件文库;再借助 UCLUST 软件 45 合并 Repbase 与自建转座元件文库,得到非冗余重复序列库,最终利用该文库结合 RepeatMasker 完成全基因组重复序列鉴定。
采用同源预测、从头预测、转录组辅助预测 联合策略进行基因结构注释。同源预测部分:下载拟南芥、番茄、人参、芝麻、一串红及丹参 99--3 的蛋白序列,通过 TblastN(v2.2.26,阈值\(E\text{-value} \le 10^{-5}\))46 与 shh 基因组比对;再利用 GeneWise(v2.4.1)47 根据匹配蛋白序列预测基因剪接位点。
从头预测使用 Augustus(v3.2.3)、Geneid 48、Genescan 49、GlimmerHMM 50、SNAP 51 多款软件。转录组辅助注释:使用 TopHat 52 将不同组织的转录组读段比对至 shh 基因组,比对结果导入 Cufflinks 53 进行转录本组装。利用 EvidenceModeler 54 整合三种预测结果,得到非冗余基因集;最后通过 PASA 软件进一步优化基因结构 55。
基因功能注释:采用 Blastp 分别比对瑞士蛋白库(Swiss-Prot)、非冗余蛋白库(NR)、京都基因与基因组百科全书(KEGG),\(E\text{-value}\)阈值设为\(10^{-5}\)。使用 InterProScan70(v5.31)56 检索 Pfam、InterPro 数据库,预测蛋白保守基序与结构域,并依据 InterPro 注释结果匹配获得各基因的基因本体(GO)编号。
比较基因组分析
下载丹参 99--3、未知品系丹参、一串红、沟酸浆、芝麻、狸藻、油橄榄、番茄、马铃薯、人参、胡萝卜、拟南芥、毛果杨的基因组及注释数据。通过全序列双向蛋白比对,分析 shh 与其余 13 个物种的直系同源基因;运用 OrthoMCL 软件(参数-mode 3 -inflation 1.5)57 完成基因家族聚类;借助 CAFE 软件 58 统计同源基因家族的扩张与收缩情况。
针对单拷贝基因家族,使用 Muscle 软件 59 进行序列比对,再通过 Gblocks 60 剔除比对结果中低可信度位点;利用 RAxML(v8.2.12)构建系统发育树。基于 PAML 软件包中的 mcmctree 程序(默认参数)61 估算物种分化时间。使用 MCScanX 62 鉴定 shh 基因组内共线性区块,用于全基因组复制分析;调用 PAML 包内 codeml 程序,计算所有旁系同源基因对的同义替换率(\(K_s\))。
代谢物检测
称取 0.1 g 新鲜样品粉末,加入 1 mL 甲醇,超声提取 20 min,8000 转 / 分钟离心 5 min;重复提取一次,合并两次上清液,经 0.22 μm 有机滤膜过滤。
采用超高效液相色谱(UPLC,美国沃特世) 结合 C18 色谱柱(粒径 1.7 μm,规格 2.1×100 mm)进行定量检测。检测波长 270 nm,柱温 25℃,流速 0.3 mL/min。流动相 A 为含 0.1%(体积分数)甲酸的纯水,流动相 B 为纯乙腈;梯度洗脱程序:0~5 min,B 相比例维持 40%;5~25 min,B 相比例由 40% 线性升至 60%。
代谢组分析采用赛默飞 Ultimate 3000 超高效液相色谱,搭配 Syncronis C18 色谱柱(2.1×100 mm,1.7 μm)。混合所有样品制备质控样,用于监测系统稳定性。色谱系统串联 Q Exactive 轨道阱质谱,配备电喷雾电离(ESI)源。质谱参数:正负离子同步扫描;喷雾电压 2.8 kV;鞘气流速 35 arb,辅助气流速 10 arb;毛细管温度 320℃。一级质谱分辨率 70000,扫描质荷比范围 70~1050;数据依赖型二级质谱分辨率 17500;阶梯式归一化碰撞能(NCE)设置为 20 V、40 V、60 V。
丹参酮合成相关基因分析
以拟南芥、丹参中参与甲羟戊酸途径(MVA)与甲基赤藓醇磷酸途径(MEP)的蛋白序列为查询序列,通过 BLASTP(\(E\text{-value} \le 10^{-5}\))在 shh 基因组中检索同源基因。从美国国家生物技术信息中心(NCBI)下载丹参柯巴基焦磷酸合酶(CPS)、贝壳杉烯合酶(KSL)、CYP76AH1、CYP76AH3、CYP76AK1、CYP71D411、CYP71D375、CYP71D373 的基因序列;从丹参 99--3 基因组注释文件获取 2OGD 家族基因序列。
以上述序列为诱饵筛选 shh 同源基因,筛选条件:\(E\text{-value} \le 10^{-50}\)、序列一致性≥80%、序列覆盖度≥80%。将候选基因提交至 Pfam、SMART 数据库开展结构域分析,含有相同保守结构域即判定为同源基因。使用无参转录组定量软件 Salmon 63 分析已发表转录组数据 22,获得丹参酮合成相关基因的表达量;采用 TBtools 64 绘制表达热图。
Sm2OGD3 体外酶活实验
从丹参 99--3 成熟根中 PCR 扩增Sm2OGD3 全长开放阅读框(ORF),并连接至 pET-30a 载体。将重组质粒转入大肠杆菌 BL21 (DE3) 菌株,置于 LB 液体培养基中 37℃培养,直至菌液\(OD_{600}\)达到 0.6;随后降温至 20℃,加入 0.5 mM 异丙基 -β-D - 硫代半乳糖苷(IPTG),20℃诱导表达 20 h。
收集 100 mL 菌液菌体,4℃条件下重悬于 15 mL 磷酸盐缓冲液(PBS,pH 7.2~7.4,含磷酸氢二钠、磷酸二氢钠、氯化钠)65。采用 187.5 W 功率超声破碎菌体(工作 3 s,间歇 10 s,总时长 30 min),离心后获取粗酶液。
反应体系总体积 0.5 mL,以 PBS 为缓冲液,依次加入 160 μM 2 - 氧代戊二酸、50 μM 硫酸亚铁、10~100 μM 底物,30℃孵育 0.5~1 h 65。以转入空 pET-30a 载体的大肠杆菌粗酶液作为阴性对照。反应结束后,用 0.5 mL 乙酸乙酯萃取产物两次,氮吹仪吹干有机相;残渣用 0.2 mL 甲醇复溶,过滤后采用沃特世液质联用仪(UPLC-ESI-MS)检测。使用 MssLynx V4.1 软件分析二级质谱数据。
Sm2OGD3 转基因功能验证
PCR 扩增Sm2OGD3 全长 ORF,先连接至 pTOPO-Blunt 载体,经桑格测序验证序列无误后,使用限制性内切酶 BstE Ⅱ 与 Nco Ⅰ 双酶切,将目的片段插入 pCAMBIA1391 载体。利用发根农杆菌 ACCC10060 侵染丹参,参照魏氏方法诱导获得转基因毛状根 66。
采用上游引物 35S-F、下游引物 Sm2OGD3-R 进行 PCR 阳性鉴定。将 PCR 鉴定阳性的毛状根转入 6,7-V 液体培养基,每 3 周继代培养一次。培养三个月后收获样品,液氮速冻;取 0.2 g 冻存样品研磨成粉末,加入 1 mL 甲醇提取,提取液吹干后用 0.2 mL 甲醇复溶,过滤后通过超高效液相色谱检测丹参酮含量。