Hadoop高可用架构------原理说明与集群搭建
文章目录
一、Hadoop高可用架构简述
高可用架构简介
高可用是为了保障重要的数据完整性,namenode宕机会导致集群不可用,如果节点数据丢失会导致整个集群数据丢失,namenode作为数据存储节点是HDFS核心而后者又是Hadoop的核心组件,所以namenode的高可用是Hadoop高可用的重要组成部分
Hadoop高可用主要分为两个部分:HDFS高可用和YARN高可用
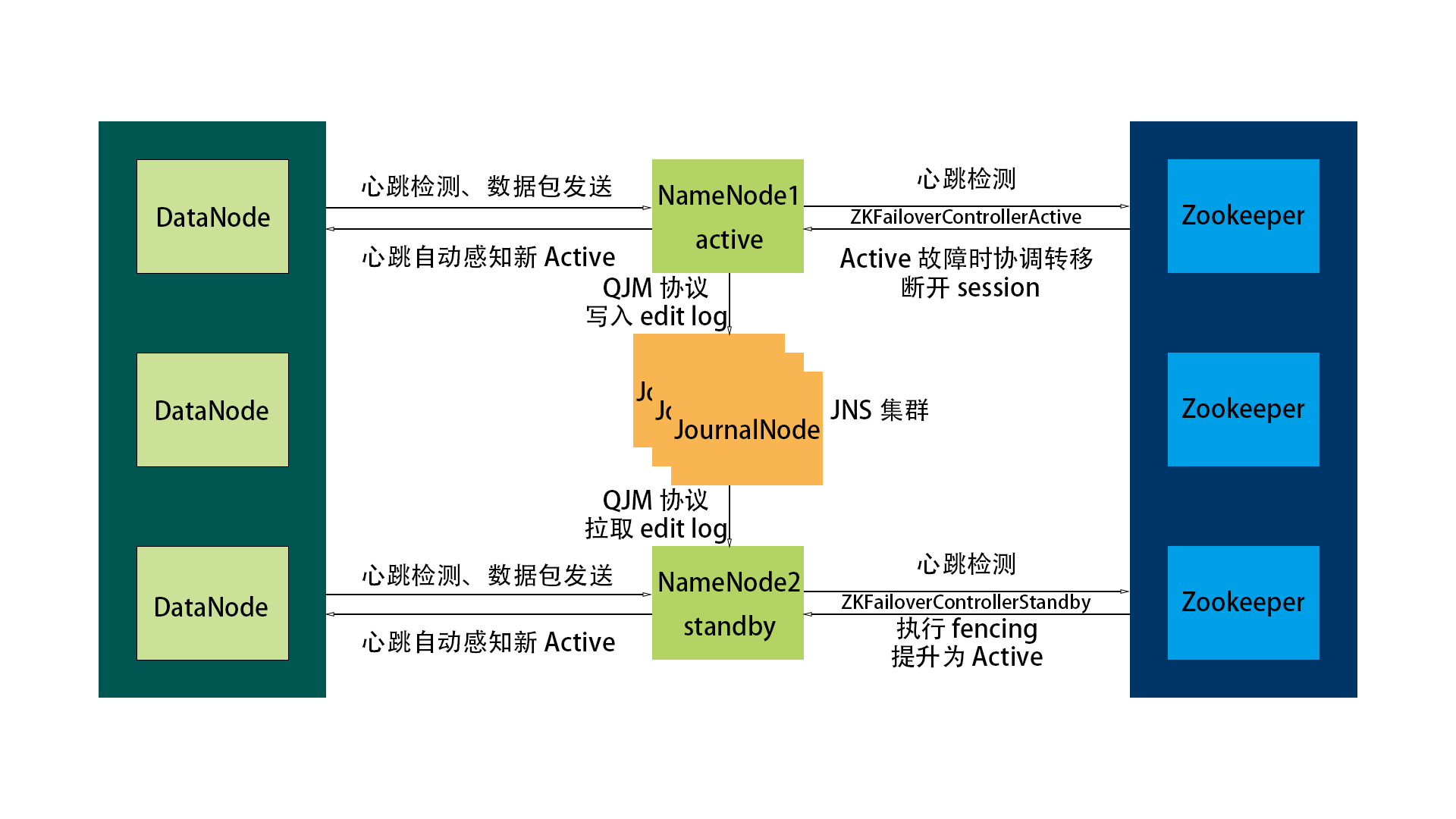
HDFS高可用由官方提供了两种方案,分别是NFS和QJM。两种方案都需要Zookeeper来实现事务的一致性,并且都需要使用Zookeeper的FailoverController高可用软件管理namenode节点,区别在NFS方案中数据存储方式依赖独立的NFS服务(NFS也需要高可用)而QJM方案的数据存储内建于Hadoop生态的journalnode节点上,所以NFS方案在故障链路排查的运维复杂度与依赖度都逊色于QJM方案
高可用方案模式
假设两台namenode节点一台是active状态另一台是standby状态,在高可用中需要每个datanode节点都知道所有namenode节点位置这是HDFS HA的通用机制
NFS方案中:两个namenode节点会在启动时挂载同一个共享NFS目录;当active nn节点宕机时Zookeeper的FailoverController(ZKFC)负责检测active NN故障、执行fencing、将standby nn的状态提升为active。为了更安全的架构NFS也得是高可用状态而这样架构具体实现变得非常高,由于该方案在故障链路排查的复杂度与依赖度过高的原因已经不被生产环境考虑
QJM方案中:user通过active nn执行创建操作,active nn将操作更新在命名空间写入 JNS的editlog文件(standby没有权限写入)并向user返回datanode地址,active nn负责写入editlog而standby nn实时拉取该文件,user向datanode实际写入数据后由datanode向两个nn节点同时发送块报告(实时增量、定期全量),所以两个nn节点会通过datanode块报告和读取JNS的editlog,最后在各自的内存中维护一致的命名空间状态;当active nn节点宕机后ZKFC会将standby nn节点状态提升为active,同时新的active nn主动向JNS集群申请写锁,JNS通过QJM的fencing机制将 写权限 (写锁)转移给新active nn节点
fsimage一致性机制:standby nn定期将命名空间序列化生成磁盘快照文件(fsimage),然后通知active nn重载新的fsimage替代旧的
fsedits同步:两台nn节点分别独立通过JNS集群(多台journalnode日志节点)交互保持通信。当active nn节点更新命名空间后写入JNS的editlog日志文件,而standby nn会持续向JNS拉取editlog日志文件将变更应用到内存中的命名空间
fencing写入机制:QJM使用fencing(一种写入机制)保障JNS中editlog日志文件的 写权限 被锁定也就是所谓的写锁,JNS只接受当前持有写锁的nn节点写入editlog文件;即只有当active nn通过QJM协议向JNS获取写锁后才能写入editlog文件而standby nn是没有 写权限 的。文档用写锁类比但实际实现基于epoch递增机制
误区:在高可用模式的QJM方案中,NN节点启动后读取初始化的fsimage进入默认standby状态,不链接 JN,不写editlog,只是standby,所以standby不是被ZKFC选出来的
案例中高可用架构集群的搭建会跳过NFS方案,实操QJM方案
二、系统规划与前置准备
系统规划
| 主机名 | 硬件性能 | 部署角色 | 组件服务 |
|---|---|---|---|
| 192.168.8.20 hadoop-master1 | 4C4G 20G | Namenode1, ResourceManager1 | HDFS,Yarn,ZKFC |
| 192.168.8.26 hadoop-master2 | 4C4G 20G | Namenode2, ResourceManager2 | HDFS,Yarn,ZKFC |
| 192.168.8.21 hadoop-node1 | 2C4G 20G | Datanode, NodeManager, JournalNode, Zookeeper | HDFS,Yarn,ZK |
| 192.168.8.22 hadoop-node2 | 2C4G 20G | Datanode, NodeManager, JournalNode, Zookeeper | HDFS,Yarn,ZK |
| 192.168.8.23 hadoop-node3 | 2C4G 20G | Datanode, NodeManager, JournalNode, Zookeeper | HDFS,Yarn,ZK |
初始化虚拟机环境
案例复用上篇中hadoop集群master节点和node1-3节点,node1-3已经部署过ZK集群,只需要从原集群克隆一台hadoop-master2节点,系统仍然使用Rocky Linux 10镜像资源最简化安装,试验机密码默认123456,更改ip地址与系统规划表格内对应
注意新增节点作为master节点与8.20机器一样都需要配置hosts和ssh免密,建议先clone master1机器再做配置,或者再跑一边上篇中的初始化环境脚本
新master2节点更新ip地址
bash
# 设置ip地址
nmcli connection modify ens160 ipv4.addresses 192.168.8.26/24
# 重启网卡
nmcli connection up ens160更新ansible节点环境补充新节点
bash
## 修改inventory文件
cat >> inventory << 'EOF'
[master]
master1 ansible_host=192.168.8.20
master2 ansible_host=192.168.8.26
[slave]
node1 ansible_host=192.168.8.21
node2 ansible_host=192.168.8.22
node3 ansible_host=192.168.8.23
[cluster:children]
master
slave
EOF
## 修改hosts模板文件
cat >> templates/hosts.j2 << 'EOF'
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.20 hadoop-master1 master1
192.168.8.26 hadoop-master2 master2
192.168.8.21 hadoop-node1 node1
192.168.8.22 hadoop-node2 node2
192.168.8.23 hadoop-node3 node3
EOF
## 修改初始化剧本
cat >> playbook/init_hosts.yml << 'EOF'
---
- name: set hostname and update hosts
hosts: cluster
become: yes
vars:
hostname_mapping:
master1: hadoop-master1
master2: hadoop-master2
node1: hadoop-node1
node2: hadoop-node2
node3: hadoop-node3
tasks:
# 1. set hostname
- name: set hostname
hostname:
name: "{{ hostname_mapping[inventory_hostname] }}"
# replace hosts file
- name: deploy unified hosts file
template:
src: /ansible/templates/hosts.j2
dest: /etc/hosts
backup: yes
owner: root
group: root
mode: '0644'
EOF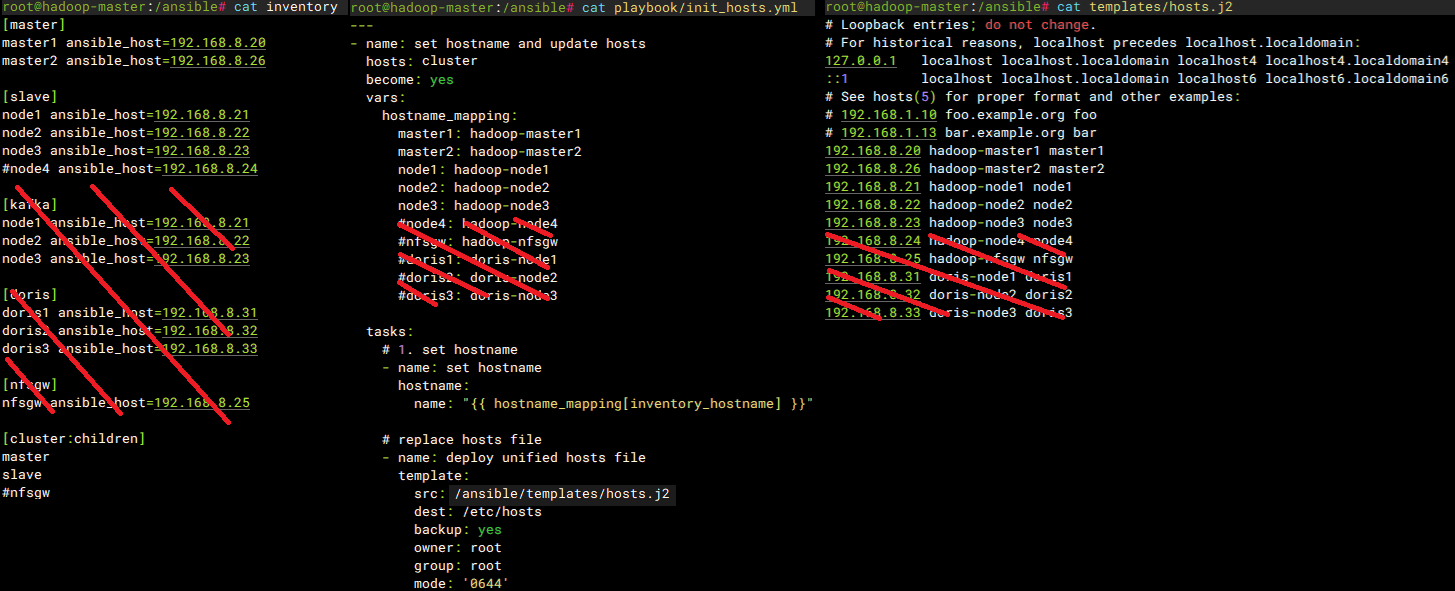
初始化hosts解析与主机名
bash
# 执行剧本初始化各个节点的hosts解析文件并更改主机名
ansible-playbook playbook/init_hosts.yml
# 查看结果
ansible cluster -m shell -a "cat /etc/hosts | wc -l"
ansible cluster -m shell -a "hostname"
ansible cluster -m shell -a "java --version"
新master节点配置免密
注意:新节点需要与老master1节点能够互通,所以master1节点也需要配置
bash
# 在master2节点上操作
ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
for i in 20 21 22 23 26; do sshpass -p "123456" ssh-copy-id -o StrictHostKeyChecking=no root@192.168.8.$i; done
三、配置集群高可用
停止服务
停止之前运行的所有服务;集群节点中配置文件必须相同,案例先在master1节点中修改,再同步给master2与node1-3节点
bash
# 停止hadoop服务
ansible cluster -m shell -a "/usr/local/hadoop/sbin/stop-all.sh"
# 停止kafka服务
ansible cluster -m shell -a "/usr/local/kafka/bin/kafka-server-stop.sh"
# 停止zookeeper服务
ansible cluster -m shell -a "/usr/local/zookeeper/bin/zkServer.sh stop"
# 查看结果
ansible cluster -m shell -a "jps"配置NN与RM高可用参数
hadoop-env.sh配置
JAVA_HOME:指定系统java环境路径,根据实际java环境变量配置
HADOOP_CONF_DIR:指定hadoop的配置环境路径,案例配置地址为:/usr/local/hadoop/etc/hadoop
注意:2.x系列的hadoop环境路径会有改变
如果需要root用户执行,要在该文件头定义运行用户,具体添加内容参考第四节的启动高可用集群。实验可以使用root,但非实验环境建议用普通用户,后续出现异常便于定位问题原因
bash
# 验证结果
grep -E "^[[:space:]]*[^#].*(JAVA_HOME|HADOOP_CONF_DIR)" /usr/local/hadoop/etc/hadoop/hadoop-env.shworkers(slaves)配置
声明datanode节点,一行一个,默认是localhost全部改为node1-3
注意:2.x系列的配置文件名是slaves,3.x系列的配置文件名是workers
bash
# 验证结果
cat /usr/local/hadoop/etc/hadoop/workerscore-site.xml配置
fs.defaultFS:指定namenode的地址,文件系统配置参数,但在集群中多个节点不使用具体的地址而使用自定义的服务名
hadoop.tmp.dir:指定hadoop所有数据根目录,默认/var/hadoop,非常重要,单独分区或者单独一块硬盘
ha.zookeeper.quorum:指定zookeeper集群地址,多个节点地址使用逗号分隔
xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://myhdfscluster</value>
<description>specify the nameservices of cluster</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
<description>the root dir for all hadoop data</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
<description>specify the zookeeper address</description>
</property>hdfs-site.xml配置
dfs.namenode.http-address:删掉 !声明在哪台机器启动namenode,多节点不需要
dfs.namenode.secondary.http-address:删掉 !声明在哪台机器启动secondarynamenode,但高可用模式不需要因为该角色会被standby nn节点取代
dfs.nameservices:指定nameservices集群名称,多节点使用服务名在此声明,必须 与core-site.xml中的fs.defaultFS服务名一致
dfs.ha.namenodes.{服务名}:定义服务中的名称,注意案例服务名是myhdfscluster所以参数名是dfs.ha.namenodes.myhdfscluster,其他服务名按实际需求更改;一个服务分别对应两个角色
dfs.namenode.rpc-address.{服务名}.{名称}:定义namenode的rpc地址及端口号,多个节点定义多行也就是说每个节点都要说明rpc,名称是nn1和nn2,所以参数名是dfs.namenode.rpc-address.myhdfscluster.nn1和dfs.namenode.rpc-address.myhdfscluster.nn2;两个角色分别对应两个主机
dfs.namenode.http-address.{服务名}.{名称}:定义namenode的http地址及端口号,多个节点定义多行也就是说每个节点都要说明http,名称是nn1和nn2,所以参数名是dfs.namenode.http-address.myhdfscluster.nn1和dfs.namenode.http-address.myhdfscluster.nn2;两个角色对应的两个主机分别对应两个地址
dfs.namenode.shared.edits.dir:定义journalnode的地址及端口号,8485是 journalnode的RPC通信端口,参数名是qjournal://node1:8485;node2:8485;node3:8485/{服务名}
dfs.journalnode.edits.dir:指定journalnode的editslog日志文件存储路径,默认/var/hadoop/journal
dfs.client.failover.proxy.provider.{服务名}:指定故障转移代理类failover服务名,参数名是dfs.client.failover.proxy.provider.{服务名},所以参数名是dfs.client.failover.proxy.provider.myhdfscluster,默认值是org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.method:指定远程管理方式sshfence,shell命令是sshfence,sshfence命令需要配置免密
dfs.ha.fencing.ssh.private-key-files:指定sshfence命令的私钥文件路径,默认是~/.ssh/id_rsa,案例是/root/.ssh/id_rsa
dfs.ha.automatic-failover.enabled:指定自动故障转移,默认是false,案例是true
dfs.replication:指定每个文件的副本数,不编写默认3,案例使用2
dfs.hosts.exclude:指定主机黑名单文件路径,默认是配置中/etc/hadoop/exclude,案例是/usr/local/hadoop/etc/hadoop/exclude
xml
<!-- ===================== HDFS HA 核心配置 ===================== -->
<property>
<name>dfs.nameservices</name>
<value>myhdfscluster</value>
<description>
指定HDFS集群的逻辑名称,在高可用模式下,客户端通过该名称访问集群,而非直接指定某个NameNode地址
</description>
</property>
<property>
<name>dfs.ha.namenodes.myhdfscluster</name>
<value>nn1,nn2</value>
<description>
指定NameService下包含的NameNode逻辑标识列表,多个标识用逗号分隔,每个标识对应一个独立的NameNode实例
标识名称仅用于配置引用,不能包含空格或特殊字符且至少需要配置两个NameNode,一个作为Active NameNode,另一个作为Standby NameNode
</description>
</property>
<property>
<name>dfs.namenode.rpc-address.myhdfscluster.nn1</name>
<value>master1:8020</value>
<description>
指定 namenode1 的 RPC 服务地址和端口
客户端(如 CLI、MapReduce、Spark)通过此地址与NameNode进行RPC通信,执行文件系统元数据操作
</description>
</property>
<property>
<name>dfs.namenode.rpc-address.myhdfscluster.nn2</name>
<value>master2:8020</value>
<description>
指定namenode2的RPC服务地址和端口
</description>
</property>
<property>
<name>dfs.namenode.http-address.myhdfscluster.nn1</name>
<value>master1:9870</value>
<description>
指定namenode1的Web HTTP服务地址和端口,用户和管理员通过此地址访问Web UI
Hadoop 3.x默认端口为 9870(Hadoop 2.x为50070)
</description>
</property>
<property>
<name>dfs.namenode.http-address.myhdfscluster.nn2</name>
<value>master2:9870</value>
<description>
指定namenode2的Web HTTP服务地址和端口
</description>
</property>
<!-- ===================== JournalNode 配置 ===================== -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/myhdfscluster</value>
<description>
指定一组JournalNode的URI地址,用于Active NameNode和Standby NameNode之间的共享编辑日志(EditLog)同步
JournalNode至少需要3个节点以容忍1个节点故障
格式为 qjournal://host1:port1;host2:port2;.../nameserviceId
</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/journal</value>
<description>
指定JournalNode本地存储EditLog数据段(edits segments)的文件系统路径
</description>
</property>
<!-- ===================== 故障转移配置 ===================== -->
<property>
<name>dfs.client.failover.proxy.provider.myhdfscluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>
指定HDFS客户端用于实现NameNode故障转移的代理提供者类
ConfiguredFailoverProxyProvider是Hadoop HA的默认实现,当客户端连接的NameNode不可用时,自动尝试连接另一个NameNode
该类会维护NameNode列表并根据活跃状态选择正确的代理
</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>
指定HA故障转移时的Fencing(隔离)方法
当发生主备切换时,sshfence通过SSH连接到旧Active节点并执行kill命令强制终止NameNode进程,防止出现"脑裂"(Split-Brain)问题
</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>
当上个参数的值设置为sshfence时,需要指定SSH私钥文件的路径
Standby NameNode通过此私钥SSH登录到Active NameNode所在主机执行fencing操作
需确保此私钥文件对运行NameNode进程的用户可读,且两个NameNode主机之间已配置SSH免密登录(双向)
</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>
是否启用高可用的自动故障转移功能
启用时Hadoop使用ZooKeeper集群来监控NameNode的健康状态,当Active NameNode故障时自动将Standby NameNode提升为Active
该功能需要事先正确部署并配置ZooKeeper集群,并在core-site.xml中设置ha.zookeeper.quorum参数
</description>
</property>
<!-- ===================== 数据副本与节点管理 ===================== -->
<property>
<name>dfs.replication</name>
<value>2</value>
<description>
指定HDFS文件块的默认副本数量。
表示每个数据块在集群中保存几份副本,分布存储在不同的DataNode上,若不编写默认是3
</description>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
<description>
指定主机黑名单,文件中列出将被下线的DataNode主机名
NameNode 读取此文件后,会将列出的DataNode上的副本迁移到其他健康节点,完成数据均衡后安全下线
</description>
</property>mapreduce-site.xml配置
mapreduce.framework.name:指定资源管理类,案例是yarn
xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>yarn-site.xml配置
yarn.nodemanager.aux-services:分布式框架指定的框架类,案例是mapreduce_shuffle
yarn.resourcemanager.hostname:删掉 !指定resourcemanager所在的主机,多节点对应的地址在高可用模式中由其他参数配置
yarn.resourcemanager.ha.enabled:指定resourcemanager是否启用高可用,选择true激活HA配置
yarn.resourcemanager.recovery.enabled:管理节点状态自动回复配置,选择true
yarn.resourcemanager.storage.class:指定resourcemanager数据存储介质,案例是内存存储,默认值是org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk-address:指定zookeeper集群地址,案例复用了上篇部署集群中的node1-3节点所以是:node1:2181,node2:2181,node3:2181
yarn.resourcemanager.cluster-id:指定yarn集群id,支持自定义,案例是myyarncluster
yarn.resourcemanager.ha.rm-ids:指定resourcemanager角色,有几个节点就写几个,案例是rm1和rm2
yarn.resourcemanager.hostname.{主机名}:指定角色对应的主机地址,案例master1和master2,同样根据节点数量决定
yarn.resourcemanager.webapp.address.{角色名}:指定web代理的主机地址和端口号
注意:最后一个参数
yarn.resourcemanager.webapp.address.{角色名}只在3.x系列中需要配置,这是整个3系列在高可用环境下的兼容性问题原因是:yarn服务的访问控制的过滤器方法在初始化web代理过滤器时需要获取yarn web代理的主机地址列表,当相关配置(如
yarn.web-proxy.principal、yarn.web-proxy.address、或RM的web地址配置也就是最后一个参数)缺失或不完整 时,获取到的代理主机列表为null,在传入字符串集合拼接方法中触发空指针异常NullPointerException。由于注册失败web应用未启动成功,获取端口的方法返回null,导致RM工具类的注册方法无法向RM注册也抛出空指针异常NullPointerException。最终MRAppMaster进程会异常退出
xml
<!-- ===================== NodeManager 基础配置 ===================== -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
指定NodeManager需要运行的辅助服务,MapReduce框架要求NodeManager启动Shuffle服务(mapreduce_shuffle)
用于在Map任务完成后、Reduce任务启动前,将Map的中间输出数据通过HTTP方式提供给Reduce任务拉取
不配置此项会导致MapReduce作业无法运行,Hadoop 3.x 中值为 mapreduce_shuffle(2.x 中为 mapreduce.shuffle)
</description>
</property>
<!-- ===================== ResourceManager HA 配置 ===================== -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>
是否启用YARN ResourceManager高可用(HA)模式
启用时集群可配置多个ResourceManager实例,其中一个为Active状态对外服务,其余为Standby状态热备
当Active ResourceManager故障时,Standby自动或手动接替保证集群资源调度不中断
</description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>
是否启用ResourceManager的状态恢复功能,若上个参数启用高可用时此项必须设为true
启用时ResourceManager会将应用状态和凭证信息持久化到外部存储,这样在ResourceManager重启或主备切换后已提交的Application,无需重新提交即可从断点恢复运行
</description>
</property>
<property>
<name>yarn.resourcemanager.storage.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>
指定ResourceManager状态持久化的存储实现类,ZKRMStateStore表示将ResourceManager状态存储到ZooKeeper中
</description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
<description>
指定ResourceManager用于高可用协调和状态存储的ZooKeeper集群地址列表
多个地址用逗号分隔,ResourceManager会连接这些ZooKeeper节点进行Leader选举(决定哪个节点为Active)和状态数据读写
格式为host1:port,host2:port,...,ZooKeeper默认客户端端口为2181
</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>myyarncluster</value>
<description>
指定YARN集群的唯一标识符,用于多个Hadoop集群共享同一套ZooKeeper集群时,区分不同YARN集群的选举数据和状态数据
ResourceManager启动时会在ZooKeeper中以cluster-id为路径注册自身信息,NodeManager也通过此ID发现并连接到正确的ResourceManager
如果仅有一个Hadoop集群,使用默认值即可
</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>
指定高可用模式下所有ResourceManager实例的逻辑标识列表,多个标识用逗号分隔
每个标识用于在后续配置中引用对应的ResourceManager实例,标识名称可自定义,但需保持全局一致,不能包含空格或特殊字符
</description>
</property>
<!-- hostname 仅主机名,用于 start/stop 脚本的 SSH 连接 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
<description>
指定逻辑标识为resourcemanager1的ResourceManager节点所在主机的主机名
ResourceManager会根据此主机名自动推导出各服务的默认地址:
- RPC 地址:hostname:8032
- Scheduler 地址:hostname:8030
- Tracker 地址:hostname:8031
- Admin 地址:hostname:8033
- Web UI 地址:hostname:8088
如果需要自定义端口,可单独配置各服务的地址参数覆盖默认值
</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
<description>
指定逻辑标识为resourcemanager2的ResourceManager所在主机的主机名,与rm1配置结构对称
</description>
</property>
<!-- RM1和RM2的显式地址配置,用于MRAppMaster的Web代理初始化 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>同步配置文件
bash
# 在修改后与所有节点同步配置文件
for node in node1 node2 node3 master2
do
rsync -axSH --delete /usr/local/hadoop $node:/usr/local/
done更新JAR包
在hadoop根目录下share子目录存储大量的jar包,其中JSch包是java实现ssh协议的一个库,在Hadoop高可用架构正常运行下没有直接关系,但故障切换的fencing环节中是关键依赖,Hadoop内部是通过 JSch库来建立SSH连接到旧Active节点并kill进程。所以哪怕在新版本中包体老旧无法实现节点切换仍能正常启动集群但节点故障后无法实现切换
在案例中的3.4.3版本默认安装的是 JSch-0.1.55,而这个版本太老对于密钥仅支持ssh-rsa算法,新系统默认采用OpenSSH9已经废弃了老算法采用256或512,如果不更新会导致集群启动后节点宕机时无法实现SSH连接节点也就无法完成主备切换,所以案例将改jar包更新到 Jsch-2.27.7支持256和512密钥算法
bash
# 下载依赖包后替换原jar包
find /usr/local/hadoop/share/hadoop/common/lib -name "jsch*.jar"
rm -rf /usr/local/hadoop/share/hadoop/common/lib/jsch-0.1.55.jar
cp jsch-2.27.7.jar /usr/local/hadoop/share/hadoop/common/lib/四、启动集群服务
分析依赖关系
先分析整体架构依赖关系,理解个节点之间的依赖关系后再谈启动顺序
zookeeper(选主仲裁)
└── journalnode(namenode之间共享edit log)
└── namenode(元数据管理,需要选主)
└── ZKFC(namenode故障切换控制器,绑定namenode)
└── datanode(向namenode注册)
└── nodemanager(向resourcemanager注册)
└── resourcemanager(资源调度,依赖nodemanager存活)
时间轴如下:
NN1、2启动并进入安全模式
├── 读取fsimage到内存(本地磁盘上已有初始化阶段format生成的fsimage)
├── 发现自己是高可用模式 → 进入standby
└── 连接 JN,但不写editlog而是拉取editlog
此时NN1、2节点都是standby状态,集群不可用,但安全无脑裂风险
JN1、2、3启动
└── 三个 JN节点开始监听端口,等待NN连接,但NN还是standby状态所以没有连接
ZKFC(NN1、2)启动
├── NN1、2连接zookeeper
├── 尝试在ZK中创建锁节点(抢锁)
└── NN1成功抢锁 → 调用NN1.transitionToActive()
NN2抢锁失败 → 调用NN2.transitionToStandby()
└── NN1变为active,NN2保持standby
├── NN1开始接受客户端请求
├── NN1连接 JN,开始写入editlog,NN2连接JN,读取NN1写入的editlog保持元数据同步
└── 集群开始工作阶段一:初始化节点
| 步骤 | 操作 | 执行原因 |
|---|---|---|
| 1 | 清理旧数据 | 确保集群环境处于干净状态,避免残留元数据干扰格式化 |
| 2 | 启动zookeeper | ZFKC和 JN节点之间的通信都依赖ZK集群,作为基石先启动 |
| 3 | 格式化 ZKFC | 记录NN节点的状态选主,启动后才能被写入选主 |
| 4 | 启动 journalnode | NN节点格式化时需要写入editlog文件,JN节点需要先启动 |
| 5 | 格式化 namenode | 生成fsimage和editlog,并将后者推送至 JN集群 |
| 6 | 同步 namenode1 数据到 namenode2 | NN2节点只能同步NN1数据不能格式化,否则会导致集群ID和名称空间ID不一致 |
| 7 | 初始化 JNS | 将editlog写入 JN共享存储,使NN2后续同步日志 |
| 8 | 停止 journalnode | 初始化完成,JN工作内容完成,等待集群正式启动时统一拉起 |
阶段二:启动集群
| 步骤 | 操作 | 执行内容 | 执行原因 |
|---|---|---|---|
| 1 | 启动 zookeeper集群 | zkServer.sh start | ZK是高可用选主的仲裁者,ZKFC启动后通过连接ZK实现active/standby选举 |
| 2 | 执行Hadoop启动所有服务脚本,先启动hdfs服务 | start-all.sh | 脚本中按照封装的正确依赖顺序来执行以下命令 |
| 2.1 | 启动 namenode(master1、2节点) | hdfs --daemon start namenode | 所有NN节点启动后默认进入Standby状态等待ZKFC选主 |
| 2.2 | 启动 journalnode | hdfs --daemon start journalnode | JN开始监听端口,等待NN抢锁后连接 |
| 2.3 | 启动 ZKFC(当前节点) | hdfs --daemon start zkfc | ZKFC被启动后连接ZK集群,参与NN节点的active/standby选举,开始抢锁 |
| 2.4 | 启动 datanode(所有slave节点) | hdfs --daemon start datanode | 等待NN节点抢锁后,DN向晋升的active NN注册并汇报块信息 |
| 2.5 | 启动 yarn服务 | ||
| 2.6 | 启动 resourcemanager1(当前节点) | yarn --daemon start resourcemanager | yarn的RM作为资源调度依赖HDFS,所以在HDFS后启动 |
| 2.7 | 启动 nodemanager(所有slave节点) | yarn --daemon start nodemanager | NM向RM注册并领取container资源 |
| 3 | 启动 resourcemanager2(master2节点) | yarn --daemon start resourcemanager | 2.x系列的脚本只启动master1的RM,master2的RM2需要单独启动,再通过 ZK 与 RM1 选举,3.x系列忽略该步骤 |
注意:最后一步启动RM2节点针对新系列可以不执行,3.x系列中启动脚本start-all.sh内就是执行两个命令,分别是启动HDFS的start-hdfs.sh和启动yarn的start-yarn.sh,而RM的启动在后者中有明显标出:
51行标出了检测是否高可用状态,走else分支在60行获取了所有RM逻辑ID也就是在yarn-site.xml文件中配置的
yarn.resourcemanager.ha.rm-ids(rm1,rm2),从62行的for循环内逐个解析每台 RM 的主机名,在同样的配置文件内声明了yarn.resourcemanager.hostname,最终在68行执行所有的NN节点启动RM。所以在3.x系列中脚本启动过RM2,是可以跳过单独执行master2节点的RM启动 而在2.x系列的脚本没有HA判断和RM遍历ID,所以需要单独执行master2节点启动RM
bashvim +50 /usr/local/hadoop/sbin/start-yarn.sh # start resourceManager HARM=$("${HADOOP_HDFS_HOME}/bin/hdfs" getconf -confKey yarn.resourcemanager.ha.enabled 2>&-) if [[ ${HARM} = "false" ]]; then echo "Starting resourcemanager" hadoop_uservar_su yarn resourcemanager "${HADOOP_YARN_HOME}/bin/yarn" \ --config "${HADOOP_CONF_DIR}" \ --daemon start \ resourcemanager (( HADOOP_JUMBO_RETCOUNTER=HADOOP_JUMBO_RETCOUNTER + $? )) else logicals=$("${HADOOP_HDFS_HOME}/bin/hdfs" getconf -confKey yarn.resourcemanager.ha.rm-ids 2>&-) logicals=${logicals//,/ } for id in ${logicals} do rmhost=$("${HADOOP_HDFS_HOME}/bin/hdfs" getconf -confKey "yarn.resourcemanager.hostname.${id}" 2>&-) RMHOSTS="${RMHOSTS} ${rmhost}" done echo "Starting resourcemanagers on [${RMHOSTS}]" hadoop_uservar_su yarn resourcemanager "${HADOOP_YARN_HOME}/bin/yarn" \ --config "${HADOOP_CONF_DIR}" \ --daemon start \ --workers \ --hostnames "${RMHOSTS}" \ resourcemanager (( HADOOP_JUMBO_RETCOUNTER=HADOOP_JUMBO_RETCOUNTER + $? )) fi可以看到图片中没有单独驱动master2节点的RM服务,但 jps已经可以看到了
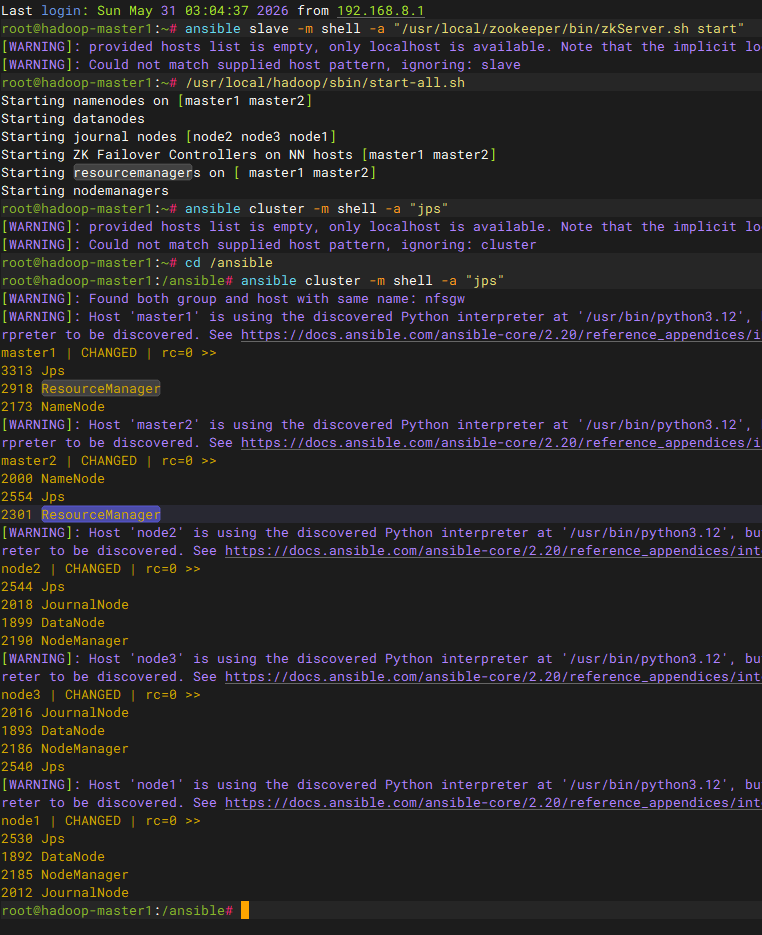
初始化集群
步骤一:清理旧数据。启动集群前,确保之前日志与实验数据被清空
bash
rm -rf /var/hadoop/*
rm -rf /usr/local/hadoop/logs/*步骤二:启动zookeeper。在所有slave节点上启动zookeeper服务
bash
ansible slave -m shell -a "/usr/local/zookeeper/bin/zkServer.sh start"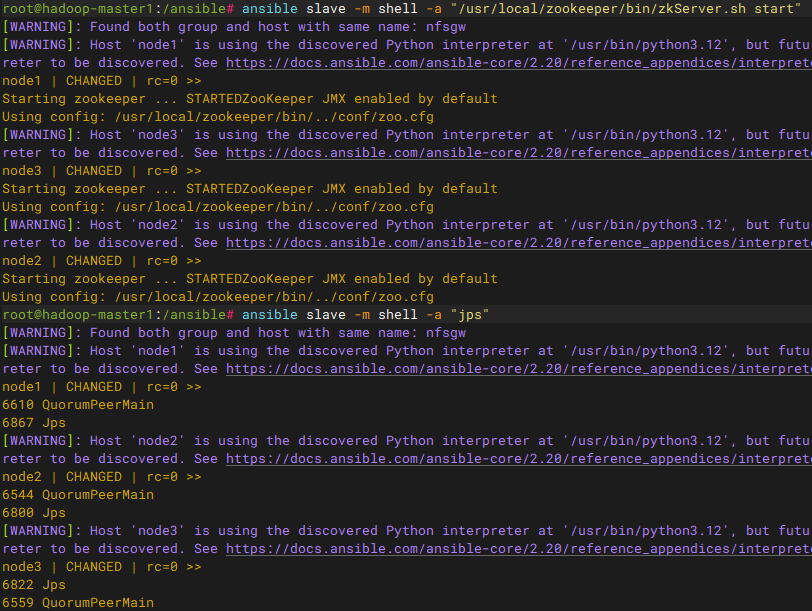
步骤三:格式化ZKFC。在master1节点上执行初始化zookeeper集群
bash
# 只能执行一次,该命令会在zookeeper中创建高可用的选举znode路径,如果多次执行会重建该路径,可能导致当前选举状态丢失
/usr/local/hadoop/bin/hdfs zkfc -formatZK
步骤四:启动 JN。在所有slave节点上,启动journalnode服务
bash
ansible slave -m shell -a "nohup /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode"注意:ansible执行完毕、ssh连接关闭时,内核向该shell会话中的进程组发送sighup信号可能导致journalnode被终止,添加nohup防止sighup信号传递
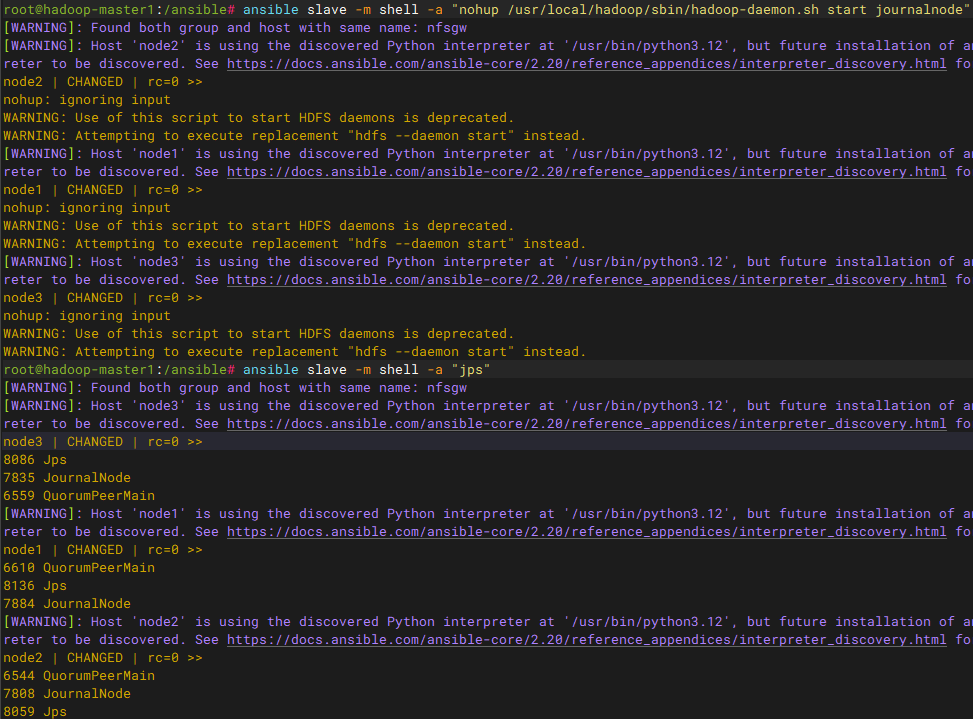
步骤五:格式化NN。在master1节点上格式化namenode
bash
/usr/local/hadoop/bin/hdfs namenode -format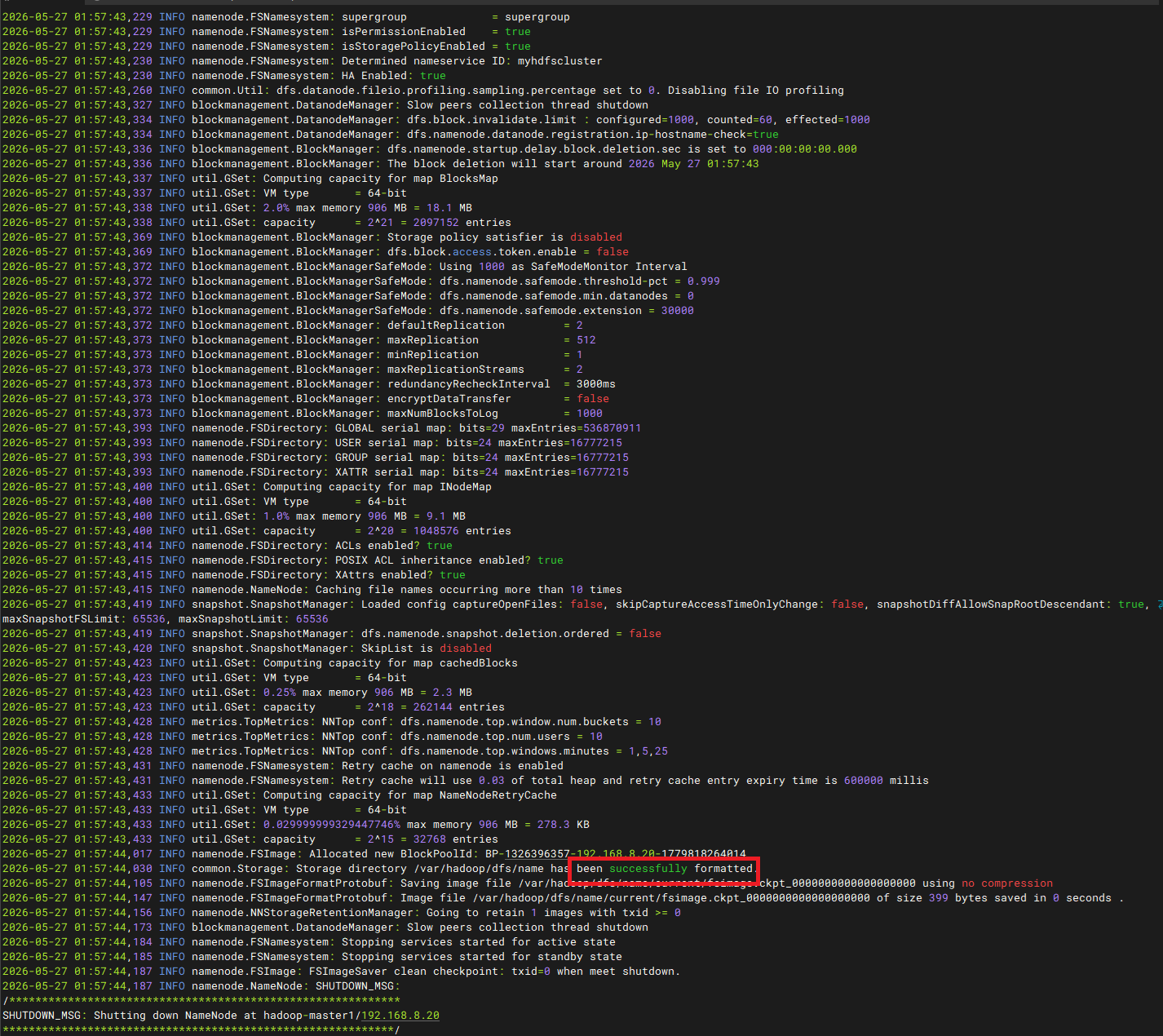
步骤六:同步数据。将master1的NN数据同步到master2节点的NN
bash
# 在master2上执行,会从active NN拉取最新的fsimage和相关元数据,并自动完成存储目录的初始化,比手动rsync更安全且能确保一致性
/usr/local/hadoop/bin/hdfs namenode -bootstrapStandby
# 手动同步
rsync -axSH --delete /var/hadoop/dfs master2:/var/hadoop/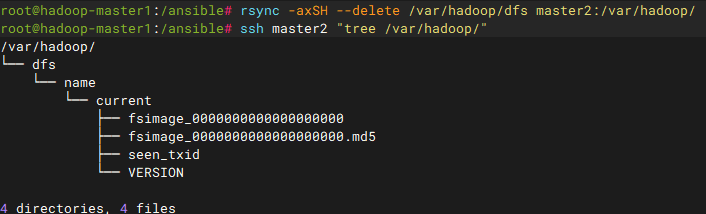
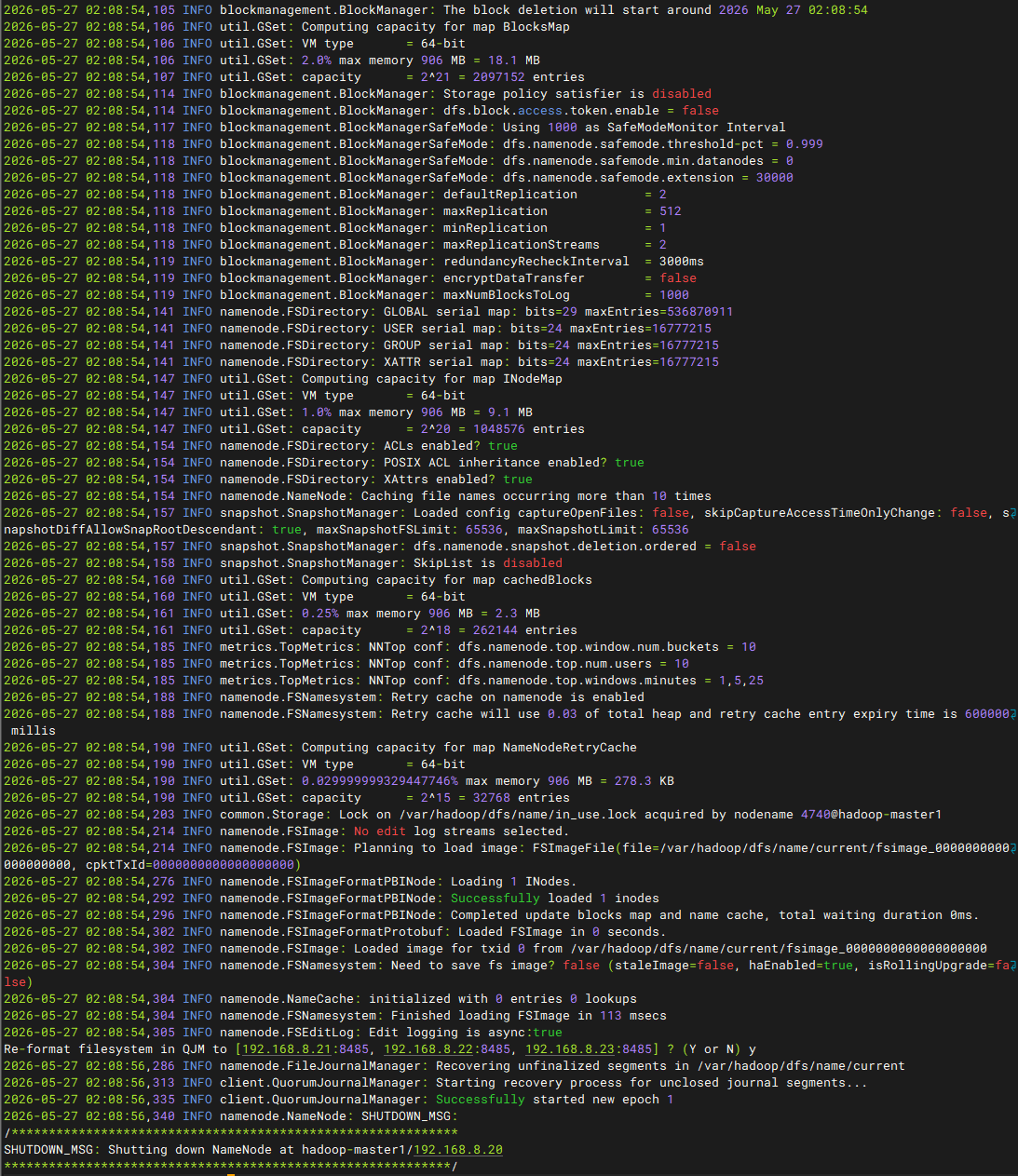
步骤七:初始化 JN。在namenode1节点上初始化 JNS服务
bash
/usr/local/hadoop/bin/hdfs namenode -initializeSharedEdits注意:如果初始化失败,报错原因是"Can't format the storage directory because the current directory is not empty",删除所有datanode节点在/var/hadoop目录下的journal目录
步骤八:停止 JN。在所有slave节点上,停止journalnode服务
bash
ansible slave -m shell -a "/usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode"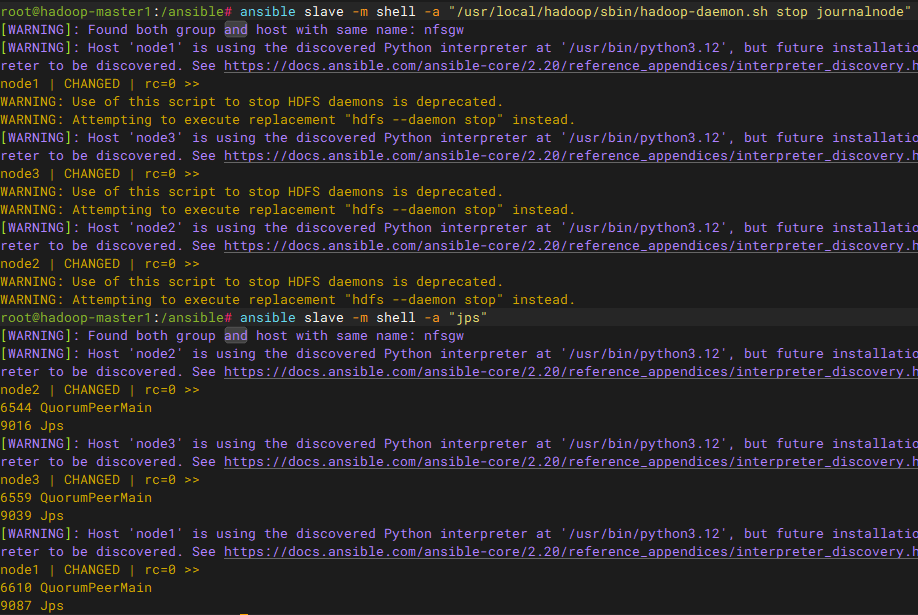
启动高可用集群
步骤一:启动ZK集群
bash
# 启动所有slave节点的zookeeper
ansible slave -m shell -a "/usr/local/zookeeper/bin/zkServer.sh start"步骤二:启动脚本。在namenode1节点中启动HDFS和YARN服务
bash
/usr/local/hadoop/sbin/start-all.sh注意:若ZFKC启动失败,并且报错ZKFC启动被拒绝,这是因为在3.x系列以root身份运行启动脚本时,要求通过环境变量显式指定各组件的运行用户,否则会直接拒绝操作;这需要在配置文件中定义运行用户
在环境脚本开头添加下列内容
ansible cluster -m shell -a "echo '
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_NICENESS=0' >> /usr/local/hadoop/etc/hadoop/hadoop-env.sh"
权限问题导致启动失败如下图
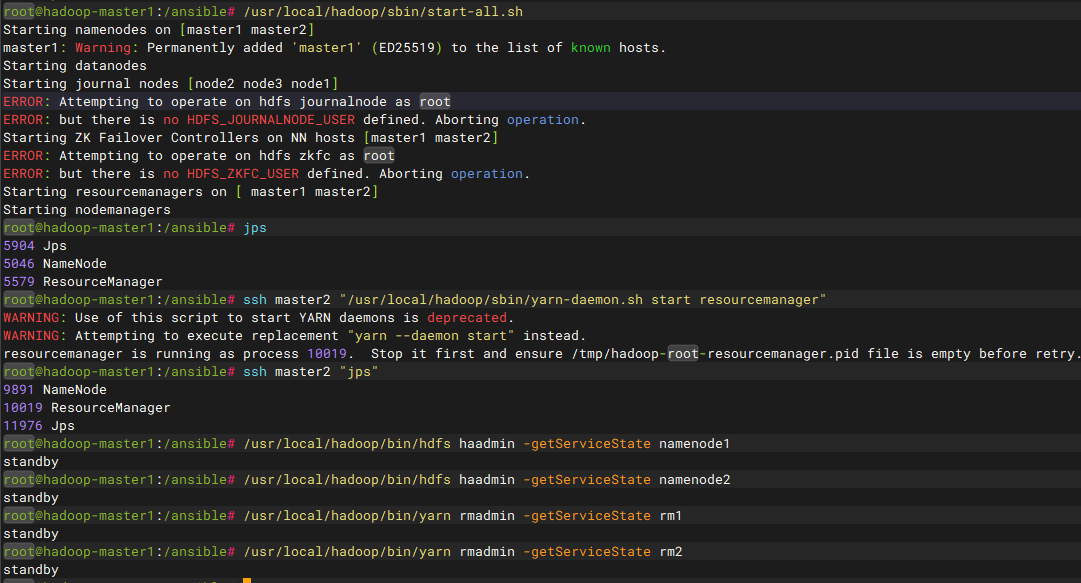
步骤三:启动RM2。在namenode2节点中启动resourcemanager服务
bash
ssh master2 "/usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager"注意:3.x系列版本可以跳过这一步
验证节点服务
bash
ansible cluster -m shell -a "jps"注意:安全模式是NN启动后的默认初始状态,安全模式下集群只读不接受任何文件修改操作,在分析依赖关系中NN节点启动后进入standby状态、不连接 JN、不写editlog、防止脑裂进入安全模式,在达到安全阈值后自动退出,但集群数据量大、DN未启动、有损坏的块、fsimage损坏、edits损坏等原因无法退出安全模式,查看日志原因,正常也可以手动退出安全模式
bash# 查看集群安装模式状态 /usr/local/hadoop/bin/hdfs dfsadmin -safemode get # 退出安全模式 /usr/local/hadoop/bin/hdfs dfsadmin -safemode leave 输出为 xxx OFF in xx节点表示退出安全模式
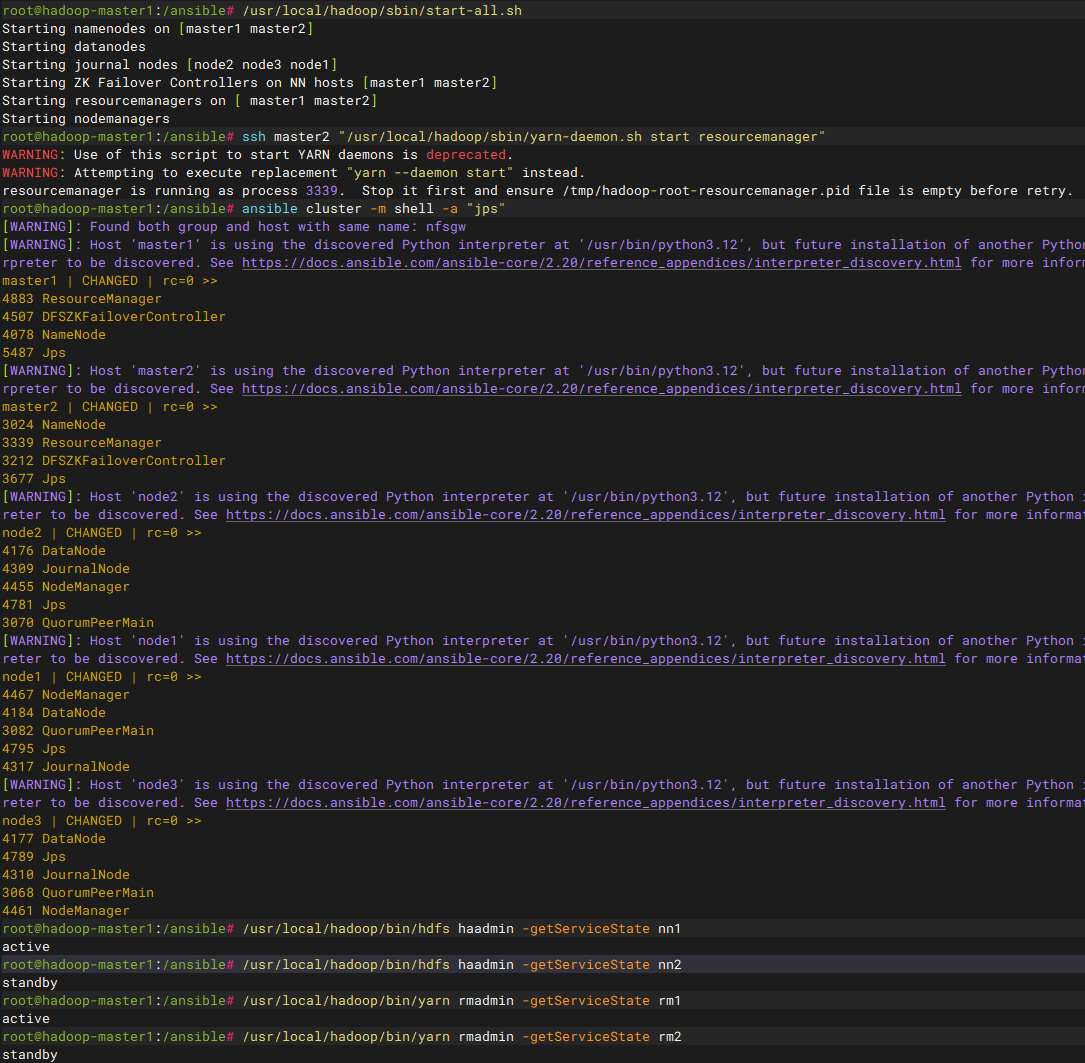
查看集群节点信息
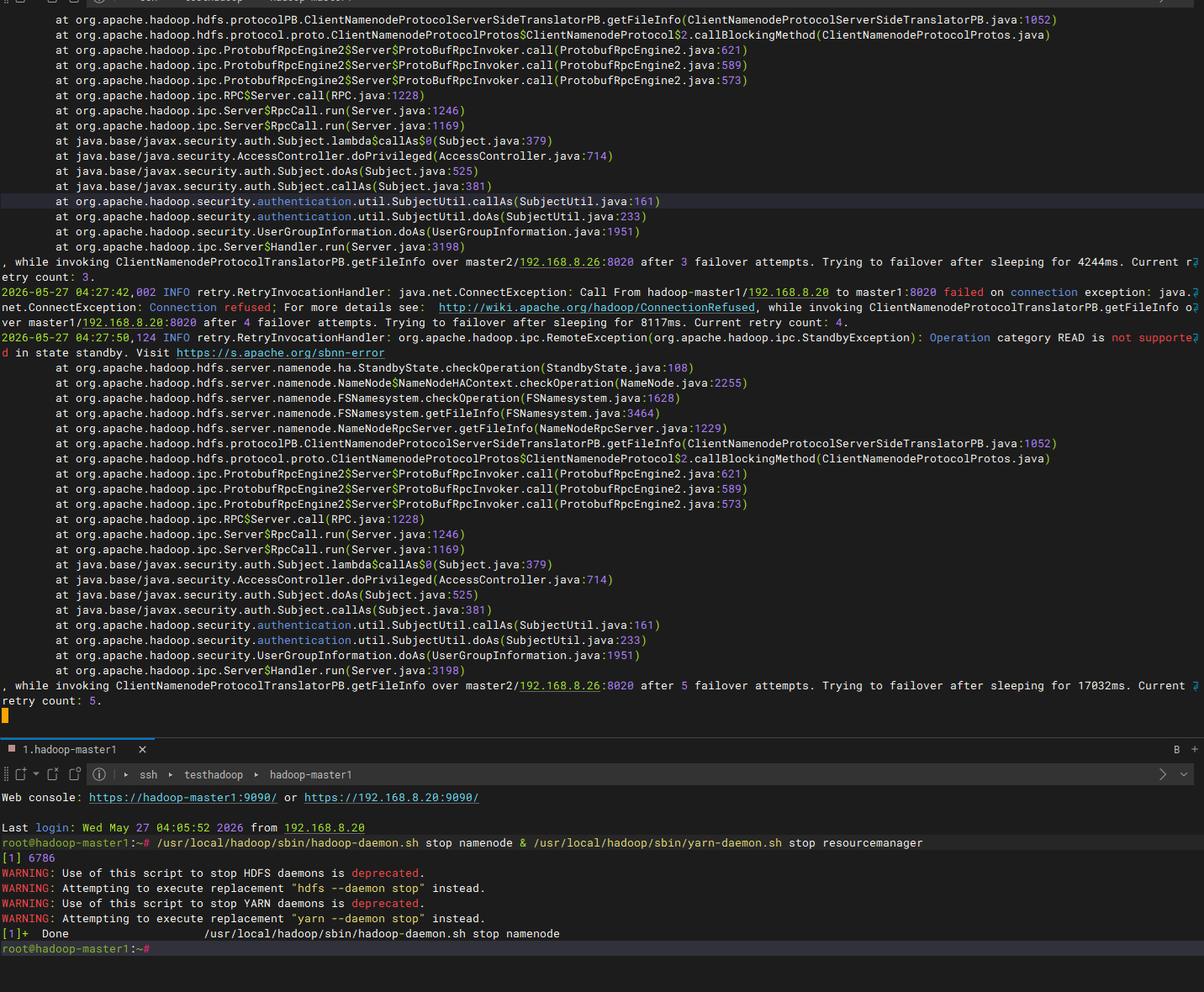
手动关闭active节点的NN和RM服务模拟节点宕机
停止高可用集群
停止高可用集群步骤
bash
## 与启动一样,3.x系列版本跳过第一步,源码中只是将start换成了stop
# 停止NN2的resourcemanager(最后启动的,最先停)2.x系列执行
ssh master2 "/usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager"
# 停止NN1上的HDFS+YARN(在master1执行)
/usr/local/hadoop/sbin/stop-all.sh
# stop-all.sh内部顺序(逆序):
# stop-yarn.sh:先停nodemanager,再停resourcemanager
# stop-dfs.sh :先停ZKFC,再停namenode,再停datanode,最后停journalnode
# 停止zookeeper(在所有slave节点执行)
ansible slave -m shell -a "/usr/local/zookeeper/bin/zkServer.sh stop"五、验证高可用集群
集群常用命令
获取namenode状态
bash
# 查看所有节点NN状态
/usr/local/hadoop/bin/hdfs haadmin -getAllServiceState
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2获取resourcemanager状态
bash
# 查看所有节点RM状态
/usr/local/hadoop/bin/yarn rmadmin -getAllServiceState
/usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
/usr/local/hadoop/bin/yarn rmadmin -getServiceState rm2获取节点信息,确保节点可用
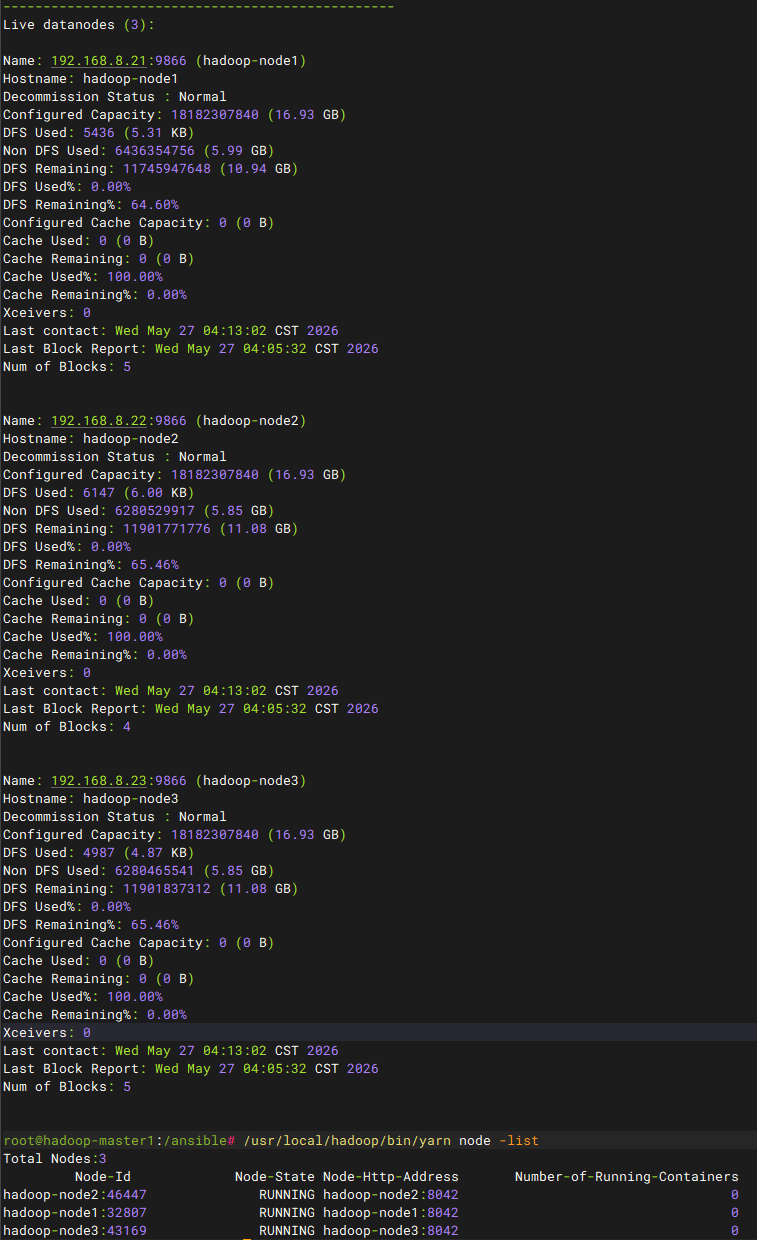
bash
/usr/local/hadoop/bin/hdfs dfsadmin -report
/usr/local/hadoop/bin/yarn node -list访问集群测试文件增删查
bash
/usr/local/hadoop/bin/hdfs dfs -mkdir /azur_lane
/usr/local/hadoop/bin/hdfs dfs -ls hdfs://myhdfscluster/
/usr/local/hadoop/bin/hdfs dfs -put /root/test.txt /azur_lane
/usr/local/hadoop/bin/hdfs dfs -rm -r /analysis强制切换namenode1节点角色
bash
# 手动切换节点的active状态
/usr/local/hadoop/bin/hdfs haadmin -transitionToActive --forcemanual nn1
/usr/local/hadoop/bin/yarn rmadmin -transitionToStandby --forcemanual rm1模拟故障转移
bash
### 模拟时开三个端口,两个连接activeNN,一个连接standbyNN,分别验证节点宕机后执行作业不中断、ZKFC高可用节点成功切换、新任activeNN节点能够查看到宕机节点中断任务后成功执行接收并输出的txt测试分析词频结果
## B端口在activeNN执行NN和RM的状态检验,并上传测试文件
# 查看NN和RM状态
/usr/local/hadoop/bin/hdfs haadmin -getAllServiceState
/usr/local/hadoop/bin/yarn rmadmin -getAllServiceState
# 在namenode1节点中上传一个测试文件,测试词频所以案例使用txt文件
/usr/local/hadoop/bin/hdfs dfs -mkdir /azur_lane
/usr/local/hadoop/bin/hdfs dfs -put /root/test.txt /azur_lane
/usr/local/hadoop/bin/hdfs dfs -ls hdfs://myhdfscluster/azur_lane
## A端口在activeNN执行txt测试分析词频作业调度任务,不要关闭窗口一直持续查看终端的输出过程
# 解析作业执行前确保最后的输出文件参数一定是空
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.3.jar wordcount /azur_lane/test.txt /analysis
## B端口停止activeNN的NN和RM服务模拟节点宕机
/usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode & /usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager
## C端口所在的standbyNN查看NN和RM状态,此时晋升为新activeNN节点
# 对比NN和RM的状态验证ZKFC工作
/usr/local/hadoop/bin/hdfs haadmin -getAllServiceState
/usr/local/hadoop/bin/yarn rmadmin -getAllServiceState
# 在新activeNN节点中查看结果
/usr/local/hadoop/bin/hdfs dfs -ls hdfs://myhdfscluster/analysis
## B端口复原NN和RM服务返岗,恢复集群健康
/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode & /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager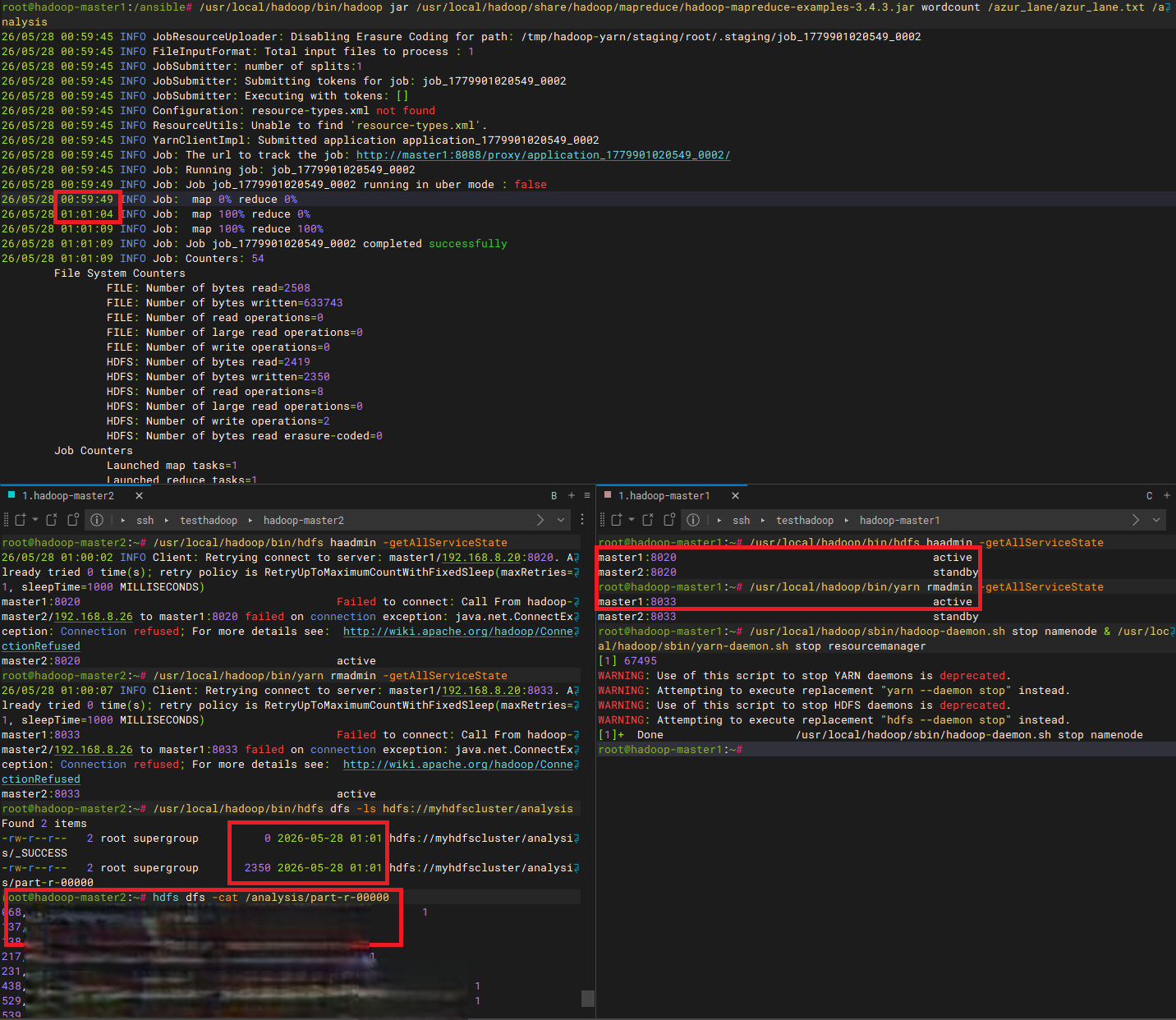
在顶部的终端开始执行解析任务。右下角的终端开始查看当前master1节点的NN和RM服务状态,暂停服务模拟宕机,同时顶部的调度任务也在59分49秒由于宕机而停止。左下角的终端查看节点变动情况,master1节点的activeNN和RM已经无法连接,master2节点的standbyNN和RM服务接替active状态,根据电脑性能不同顶部终端的调度任务在1点01分04秒也就是两分钟后继续输出日志,等待任务结束后左下角的终端可以看到输出结果。这就说明在高可用架构中工作流不会因为节点宕机而中断任务同时数据也会保留