强烈推荐的更好的阅读体验
Non-linear Separators
对于我们上一个Note提及到的binary classification,Perceptron可以学习一个线性分类边界。但是如果数据本身不是线性可分的,如下图所示,那么单纯的线性模型无论怎么调整权重,都无法找到一个正确的分界线。也即是说线性感知机表达能力不够。

我们就想到了一种办法,人为添加新特征。比如把原来的一纬空间变成二维空间
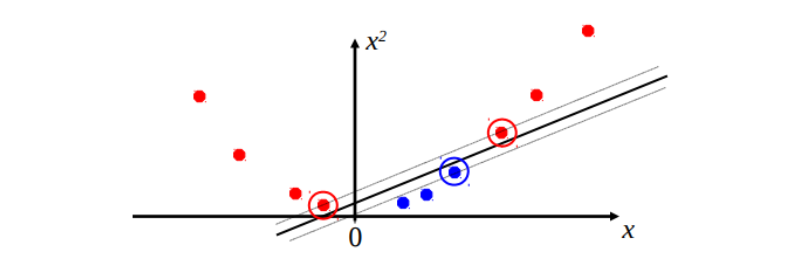
这样原本不可分的数据就可以被一条直线分开了。
Multi-layer Perceptron
我们在上一讲中提及到的普通perceptron的结构大概是从input到weighted sum到activation再到output,这是单层感知机。
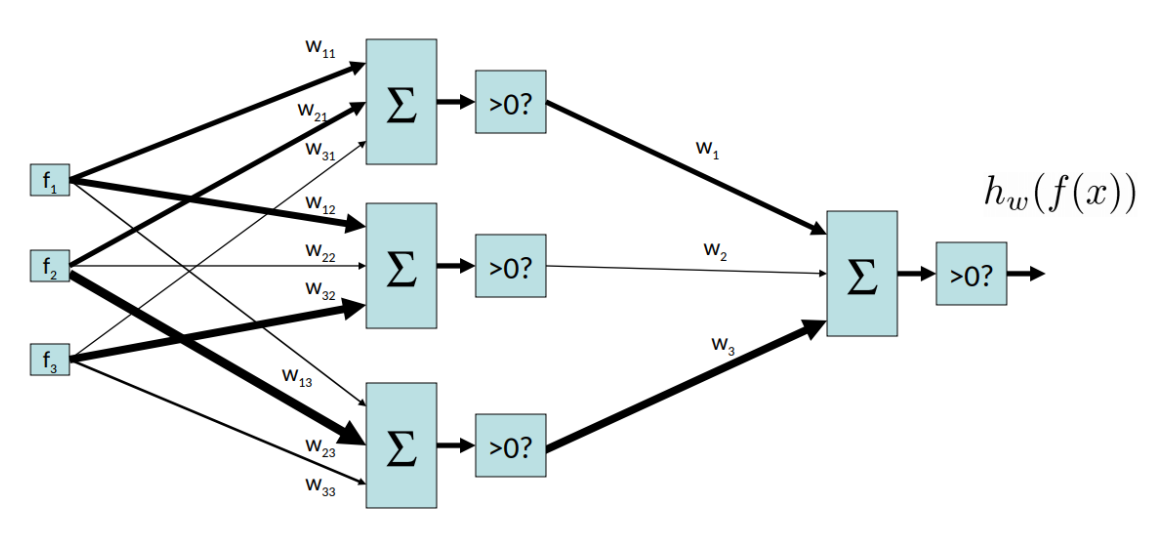
多层感知机的重要思想就是它让一个感知机的输出作为另一个感知机的输入,不再只做一次线性组合,而是做很多层,中间的层叫做hidden layer
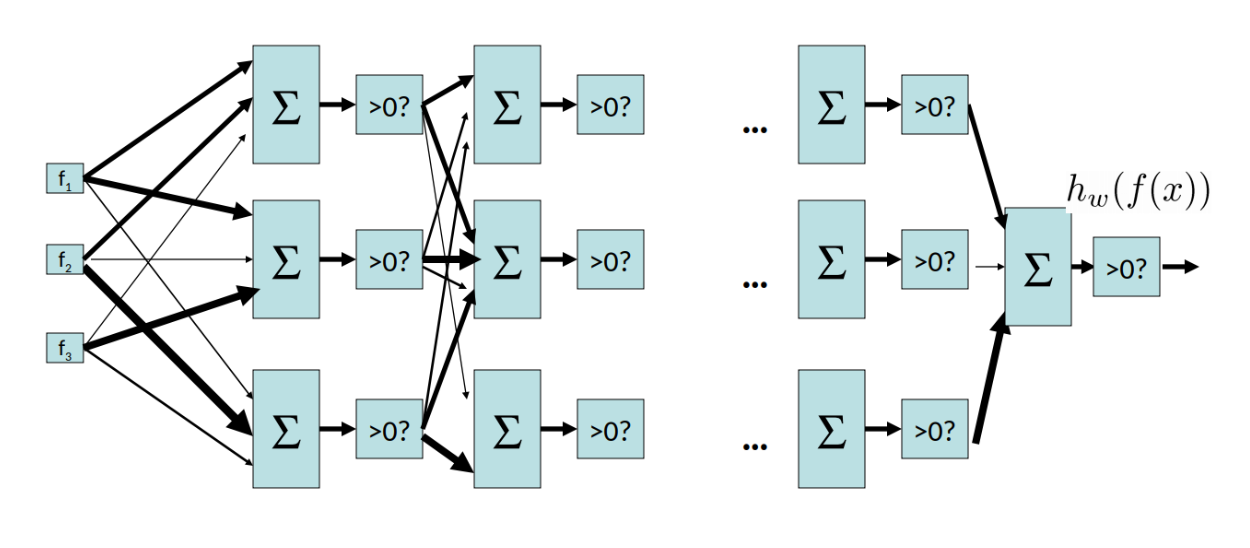
Hidden Layer的作用
隐藏层的本质作用是Learn intermediate representations,就是学习中间特征。例如在图像分类中,网络可能会逐层学到:
text
像素 → 边缘 → 局部纹理 → 局部形状 → 物体部件 → 整体类别这就是deep learning的核心思想,越往深走越是抽象的特征。
同时我们要记住一个特点,多层感知机是universal function approximator,理论上可以逼近任何连续函数。注意这里说的是表达能力不是训练难度。也就是下面这段话 :
text
Universal Function Approximation Theorem:
A neural network with enough hidden units can approximate any continuous function arbitrarily well.Measuring Accuracy
这里原Note的内容和上一讲的内容很多都是重复的,只挑重点来说了。
- 对于
binary perceptron,我们想要计算它的accuracy,我们的公式是
l a c c ( w ) = 1 n ∑ i = 1 n ( sgn ( w ⋅ f ( x i ) ) = = y i ) \begin{align*} l_{\mathrm{acc}}(w) &= \frac{1}{n}\sum_{i=1}^{n}\big(\operatorname{sgn}(w\cdot f(x_i))==y_i\big) \end{align*} lacc(w)=n1i=1∑n(sgn(w⋅f(xi))==yi)
其中符号函数:
sgn ( x ) = { 1 , x ≥ 0 − 1 , x < 0 \begin{align*} \operatorname{sgn}(x) &= \begin{cases} 1, & x \ge 0\\4pt -1, & x < 0 \end{cases} \end{align*} sgn(x)={1,−1,x≥0x<0
所以表达式:
sgn ( w ⋅ f ( x i ) ) \begin{align*} \operatorname{sgn}\big(w \cdot f(x_i)\big) \end{align*} sgn(w⋅f(xi))
就是模型对于第 i i i个样本的预测类别。
下面的表达式:
( sgn ( w ⋅ f ( x i ) ) = = y i ) \begin{align*} (\operatorname{sgn}(w \cdot f(x_i)) == y_i) \end{align*} (sgn(w⋅f(xi))==yi)
实际上就是预测对了就是1,预测不对就是0。总共进行求和除于总样本数n就是准确率 - 如果我们想要对N个类别进行判断确信程度,我们用的就是上一讲的Softmax
- 如果我们用Likelihood来表示在当前权重下模型把所有训练样本都预测成真实标签的概率有多大。
Multi-layer Feedforward Neural Networks
首先明白什么叫做Feedforward,它指的是信息只从输入层向输出层,中间没有循环结构,也就是只向前传递。
Activation Function
我们先辨别一下,Activation Function和我们上一讲提到的activation不是一回事。激活函数接受激活前的输入值之后输出一个激活值。
我们之前用到的激活函数有step function,在最原始的perceptron中使用的:
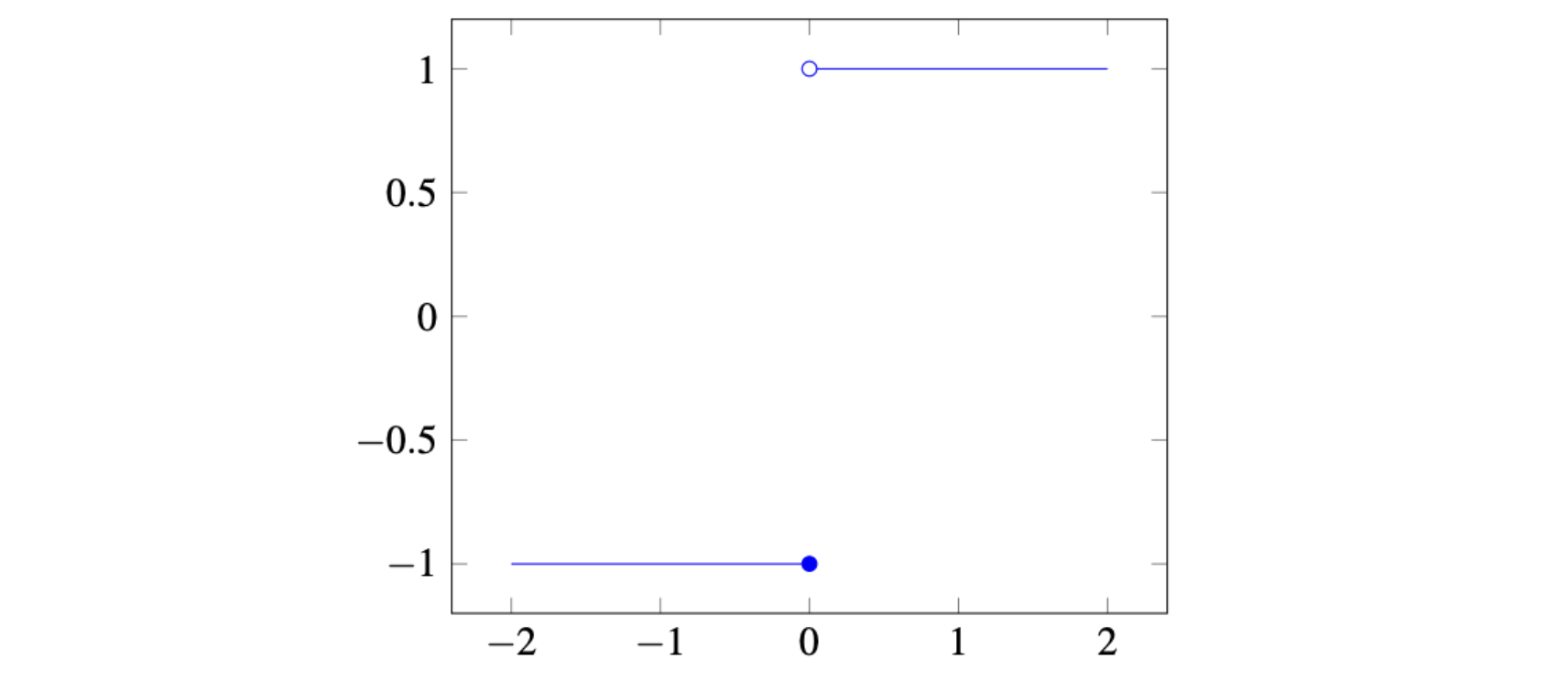
f ( x ) = { 1 , x ≥ 0 , − 1 , otherwise. \begin{align*} f(x) &= \begin{cases} 1, & x \ge 0,\\4pt -1, & \text{otherwise.} \end{cases} \end{align*} f(x)={1,−1,x≥0,otherwise.
这是一个激活函数,但是问题很大,因为它不连续而且几乎处处导数为0。
然后我们又用到了sigmoid Function
g ( z ) = 1 1 + e − z \large \begin{align*} g(z) &= \frac{1}{1+e^{-z}} \end{align*} g(z)=1+e−z1
即下图
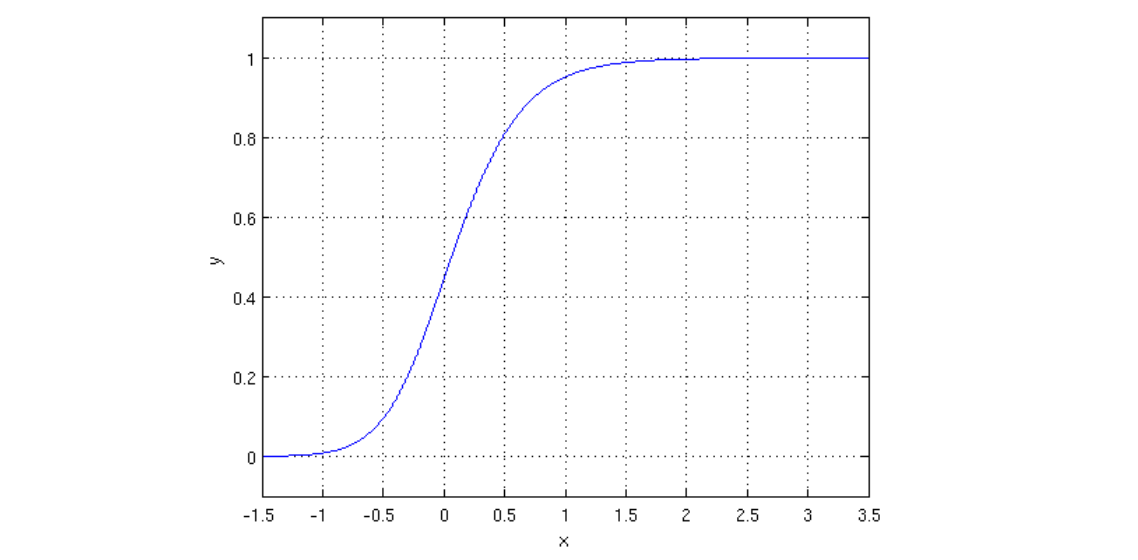
问题也很明显,当x很大或者很小的时候梯度会非常小
然后我们又提到了ReLU函数,全称为Rectified Linear Unit,定义为:
ReLU ( x ) = { 0 , x < 0 x , x ≥ 0 \large \begin{align*} \operatorname{ReLU}(x) &= \begin{cases} 0, & x < 0\\6pt x, & x \ge 0 \end{cases} \end{align*} ReLU(x)=⎩ ⎨ ⎧0,x,x<0x≥0
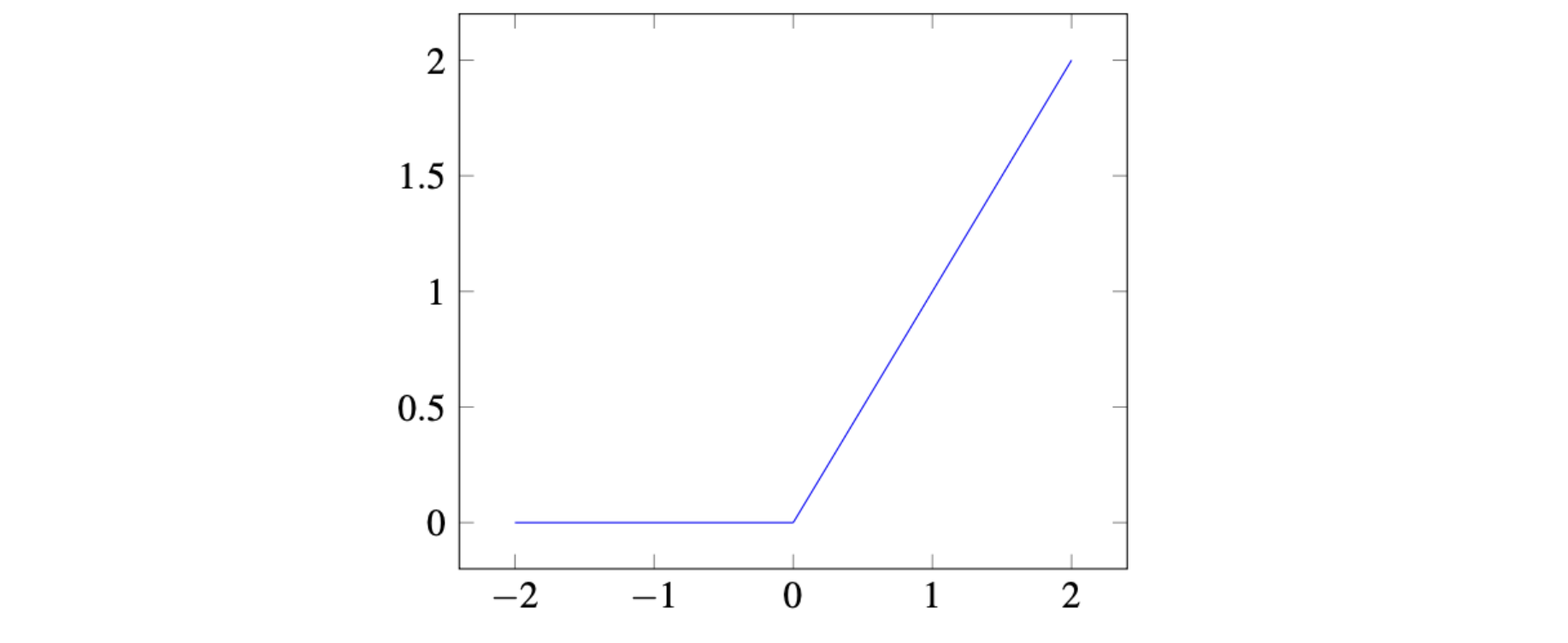
缺点是负数区域梯度为0
可以在Tensorflow网站查看不同的Activation Function对于训练的影响。
Backpropagation
首先我们明确一个目标,神经网络训练的核心就是找一个权重让损失最小,从概率角度来说就是找到一个权重让log-likelihood最小。这一段和Backpropagation没关系
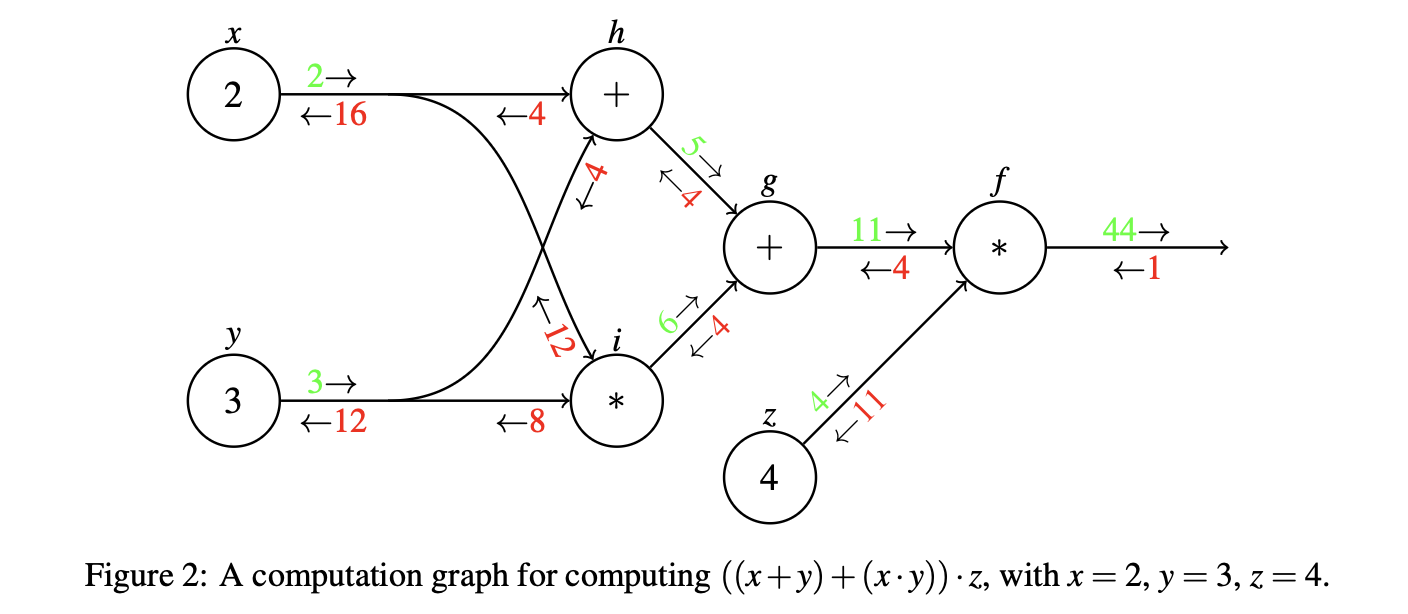
神经网络中的参数非常多,如果直接手动对着每个参数求导会非常麻烦也不现实。Backpropagation就是一种能让你高效求梯度的算法。计算图把复杂函数拆成很多简单操作,这里和高数内容基本一致,不再过多赘述,只给几个图片和简单介绍
Backpropagation包括前向传播和反向传播两个过程:
- 前向传播就是图片中的绿色部分,这一块就是正常进行算数运算。
- 反向传播就是从最终输出开始,反向计算每个节点对最终输出的影响。
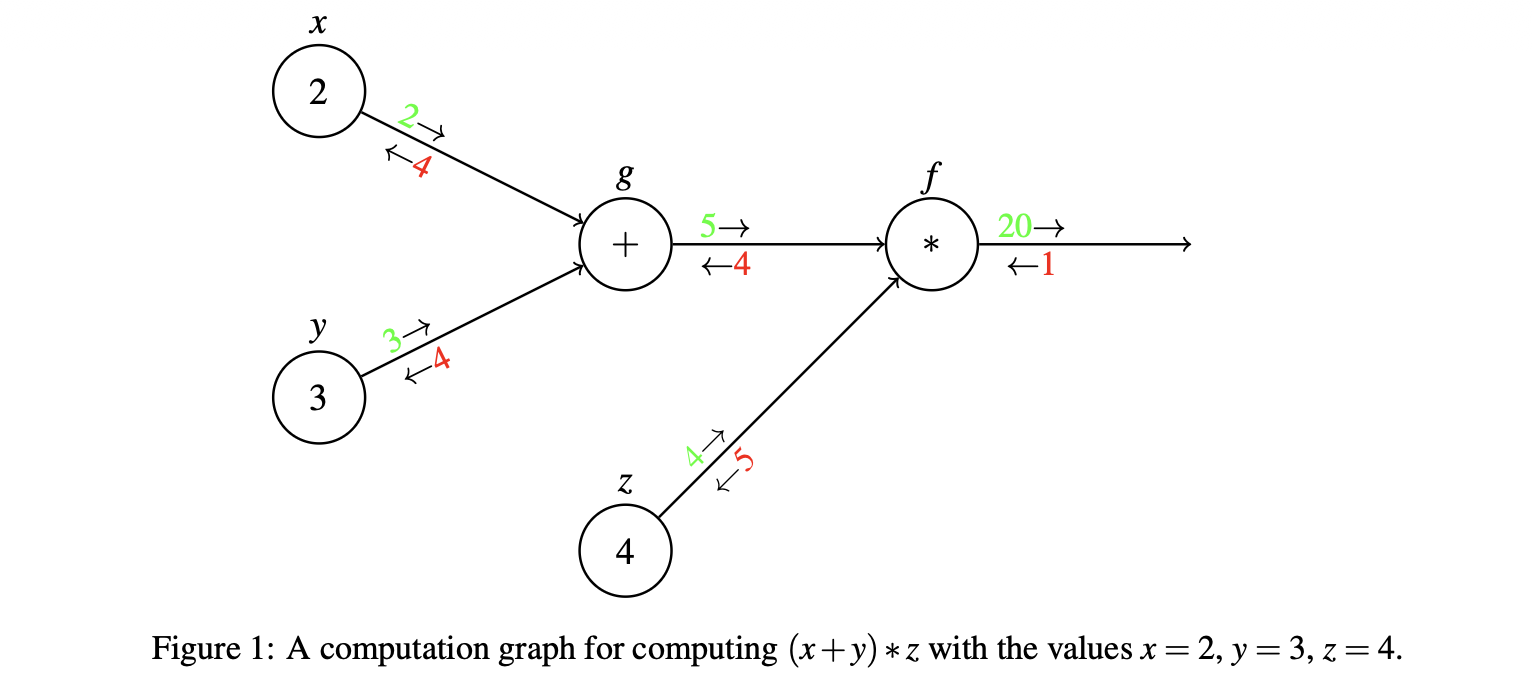
说明一下图2中梯度为什么要想加,其实就是求偏导,x通过两条路径影响最终输出f:
text
x → h → g → f
x → i → g → f∂ f ∂ x = ∂ f ∂ h ∂ h ∂ x + ∂ f ∂ i ∂ i ∂ x = 4 + 12 = 16 \large \begin{align*} \frac{\partial f}{\partial x} &= \frac{\partial f}{\partial h}\frac{\partial h}{\partial x} + \frac{\partial f}{\partial i}\frac{\partial i}{\partial x} = 4 + 12 = 16 \end{align*} ∂x∂f=∂h∂f∂x∂h+∂i∂f∂x∂i=4+12=16