本篇目标:
1.学会单链表的基础概念
2.掌握单链表的增删查改
一.认识单链表
1.概念
通过对顺序表的学习,我们知道当我们进行头删/头插时,往往需要移动数据,那么这就会造成
O(N)的时间复杂度,并且空间满了,需要扩容,但是扩容也是有⼀ 定的代价的,所以大佬就⼜发
明了链式结构来存储线性表。
链式存储:逻辑上相邻的数据元素存储在任意的⼀组物理存储单元中,数据元素之间的逻辑关系用
指针来表示。
优势:
<1>.按需申请空间,当我们需要存储⼀个数据时,就申请⼀块空间,然后用指针链接起来,将存储
数据和指针的这块空间我们⼀般叫做结点。
<2>.在某个结点位置 插⼊和删除数据不再需要挪动数据,而是直接改结点之间的指针链接关系即可。
当然光听语言的描述比较难理解,下面我们通过一张图来理解一下吧:
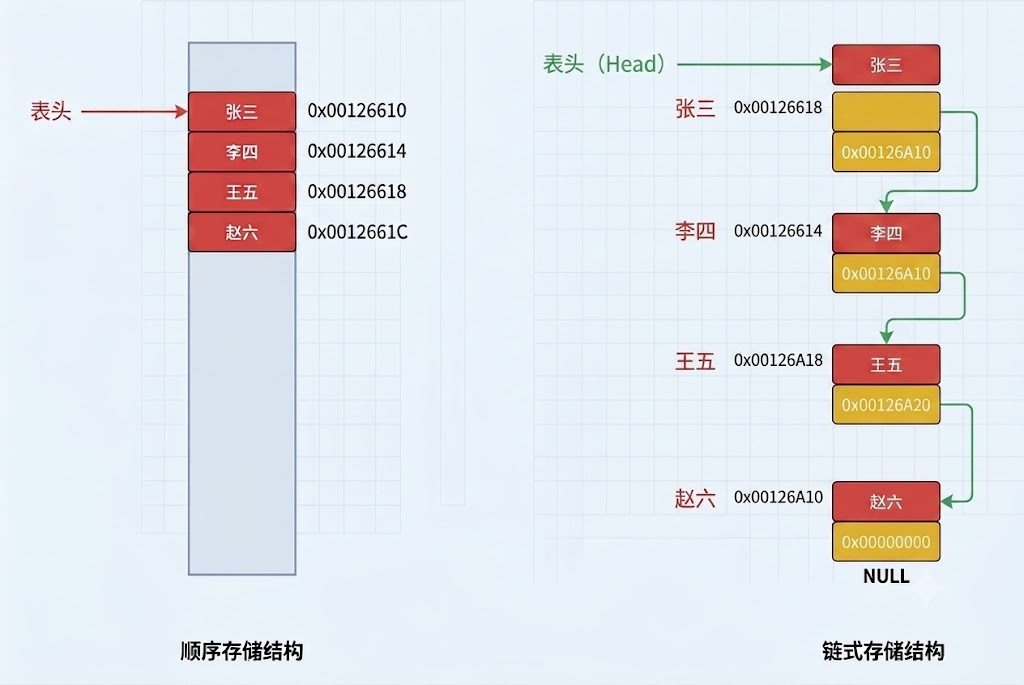
可以看出:顺序表的存储数据的地址是连续的,但是链表的存储地址是不连续的,通过某种
结构找到下一个节点的地址。
2.单链表的定义
单链表的结点中既要存储链表的值,⼜要存储后继元素结点的指针(地址),其定义如下:
cpp
typedef int LDataType;
// 链表结点结构
typedef struct ListNode
{
LDataType data; // 存储数据
struct ListNode* next;// 指向下个结点
} LNode;我们通过struct ListNode* next;存储下一个节点的地址,当我们头插等操作时,就可以很好的找到
下一个位置,然后循环遍历了。
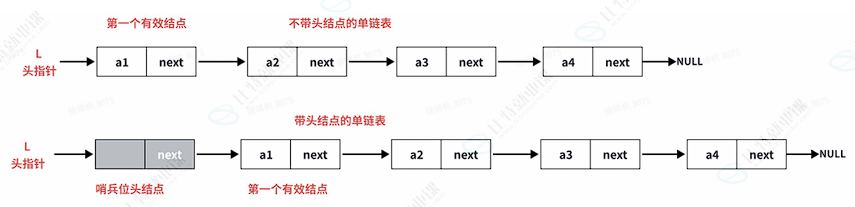
我们⼀般将指向第⼀个结点的指针叫做头指针 ,然后尾结点的指针指向空,
单链表还分为带头结点和不带头结点两种结构,头结点是⼀个哨兵位,不存储有效数据,今天我们
主要以带头链表为主 ,通过下图理解**:**
二.链表的实现
1.接口函数定义
在List.h头文件中,
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>
typedef int LDataType;
// 链表结点结构
typedef struct ListNode
{
LDataType data; // 存储数据
struct ListNode* next;// 指向下个结点
} LNode;
// 创建一个新结点
LNode* BuyListNode(int data);
// 初始化链表(带头结点)
LNode* ListInit();
// 打印链表
void ListPrint(LNode* L);
// 等价写法
// void ListPrint(LinkList L);
// 获取链表有效元素个数
int ListSize(LNode* L);
// 查找第一个值为 x 的结点,不存在返回 NULL
LNode* ListLocateElem(LNode* L, LDataType x);
// 获取下标为 i 的结点
LNode* ListGetElem(LNode* L, int i);
// 在下标 i 处插入元素 x
void ListInsert(LNode* L, int i, LDataType x);
// 删除下标 i 的结点,并返回其值
LDataType ListDelete(LNode* L, int i);
// 判断链表是否为空
bool ListEmpty(LNode* L);
// 头插
void ListPushFront(LNode* L, LDataType x);
// 尾插
void ListPushBack(LNode* L, LDataType x);
// 头删
LDataType ListPopFront(LNode* L);
// 尾删
LDataType ListPopBack(LNode* L);
// 销毁链表
void ListDestroy(LNode* L);我们为什么要头节点?
答案:为了防止二级指针的出现 ,如果没有头节点,我们就需要传**&头指针** ,因为头指针也是个指针,在接口函数中传一级指针是无法对链表进行修改的 ,但是如果有了头节点,我们只需传入头节点的地址(即头指针的值,一个一级指针)就可以安全地修改链表,因为修改的永远是头节点或后续节点的 next 域,而不是头指针本身。头指针始终指向这个固定的头节点,其值不会改变,因此不再需要二级指针,可以下图和下面的代码操作来理解:

2.代码操作
2.1.初始化与打印
LNode* ListInit() 初始化函数使用了返回哨兵位头结点的原因是我们需要在函数内部要创建⼀个头
结点,返回头结点指针。
cpp
LNode* BuyListNode(int data)
{
LNode* newnode = (LNode*)malloc(sizeof(LNode));
if (newnode == NULL)
{
perror("Create newnode failed");
exit(1);
}
newnode->data = data;
newnode->next = NULL;
return newnode;
}
cpp
// 初始化链表(返回头结点)
LNode* ListInit()
{
LNode* head = BuyListNode(-1);
return head;
}打印链表的本质就是先取当前节点的值,然后在当前结点中next成员拿到下⼀个结点的地址进行迭代即可,如图理解:
cpp
// 打印链表
void ListPrint(LNode* L)
{
assert(L);
printf("链表的表示:");
LNode* cur = L->next;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}还要要注意的一点就是防止传入的L为NULL。
2.2.查找操作
链表的查找操作主要分为两种:按值查找和按索引查找。
• 按值查找:遍历链表,返回第一个与目标值x匹配的节点;若未找到则返回NULL。
代码:
cpp
// 查找第一个值为 x 的结点,不存在返回 NULL
LNode* ListLocateElem(LNode* L, LDataType x)
{
assert(L);
LNode* cur = L;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}• 按索引查找:需要维护一个计数器j,通过遍历定位到指定位置的节点。
代码:
cpp
// 获取下标为 i 的结点
LNode* ListGetElem(LNode* L, int i)
{
assert(L);
assert(i >= 0);
int j = 0;
LNode* cur = L->next;
while (cur && j < i)
{
cur = cur->next;
j++;
}
if (j != i)
{
printf("不存在下标为 i 的结点\n");
return NULL;
}
return cur;
}2.3.插入操作
链表的插入不再需要像顺序表那样挪动数据,只需要改动结点间的链接关系,但是要在第i个结点
之 前插入,需要先找到第i-1个结点,如图理解:
代码:
cpp
// 在下标 i 处插入元素 x
void ListInsert(LNode* L, int i, LDataType x)
{
assert(L);
assert(i >= 0);
int j = -1;
LNode* cur = L;
while (cur && j < i-1)
{
cur = cur->next;
j++;
}
assert(j + 1 == i);
LNode* newnode = BuyListNode(x);
newnode->next = cur->next;
cur->next = newnode;
}思考问题:
<1>.这里有人会将结尾低的插入操作写成这样:
cpp
cur->next = newnode;
newnode->next = cur->next;请思考一下这样写对吗?
答案:是错误的 。如果我们先执行cur->next = newnode,就会丢失原来cur的下一个节点地址。接着执行newnode->next = cur->next时,newnode->next就会指向自身。正确的做法是先用next保存cur->next的值,再执行newnode->next = next。
<2>.有人可能会问:为什么j等于-1呢?
答案:
让我们通过一个具体的例子来详细说明这个设计思路:
假设我们有一个已排序数组 nums = [1,3,5,7],需要在其中插入数字 4。按照这个算法设计:
-
初始化时设置
j = -1,表示尚未找到任何比目标值小的元素。 -
开始遍历数组:
- 第一次比较
nums[0]=1 < 4,j更新为 0 - 第二次比较
nums[1]=3 < 4,j更新为 1 - 第三次比较
nums[2]=5 > 4,循环终止
- 第一次比较
-
此时
i=2(当前比较的位置),j=1(最后满足条件的索引) 根据i - j = 1的关系,可以确定插入位置为j + 1 = 2
这种设计的关键优势在于:
j始终记录着最后一个小于目标值的元素索引- 当
nums[i] > target时,i - j = 1正好表示需要将目标值插入到j之后的位置 - 初始
j = -1可以正确处理目标值最小的情况(此时i=0,i - j = 1表示插入位置为 0)
理解了在任意位置插入节点的操作后,剩下头插和尾插的操作就比较简单了,代码:
cpp
// 头插
void ListPushFront(LNode* L, LDataType x)
{
ListInsert(L, 0, x);
}
cpp
// 尾插
void ListPushBack(LNode* L, LDataType x)
{
assert(L);
//用j来寻找末尾节点的位置
LNode* cur = L;
while (cur->next)
{
cur = cur->next;
}
LNode* newnode = BuyListNode(x);
cur->next = newnode;
newnode->next = NULL;
}我们的头插可以直接复用在任意位置插入节点的,但是尾插却不同,我们需要找到最后节点的位
置,要找到cur的下一个为NULL的位置,此时cur就为末尾节点了。
2.4.删除操作
相比顺序表,链表删除操作无需移动数据 ,只需调整节点间的链接关系。不过要删除第i个节点时,需先定位到其前驱节点(第i-1个节点)。具体操作步骤如下:
- 通过临时指针iNode保存要删除的节点:
iNode = i_1Node->next - 将前驱节点的next指针指向后继节点:
i_1Node->next = iNode->next
注意操作顺序不能颠倒 ,否则会导致被删除节点丢失引用,无法正确释放内存。
代码:
cpp
// 删除下标 i 的结点,用 x 返回其值
LDataType ListDelete(LNode* L, int i)
{
assert(L&&L->next);
assert(i >= 0);
int j = -1;
//为什么不是j=0?
//因为当i=0时,就无法尾删了
LNode* cur = L;
while (cur && j < i-1)
{
cur = cur->next;
j++;
}
assert(j+1 == i);
LNode* old_node = cur->next;
LDataType val = old_node->data;
LNode* next = old_node->next;
cur->next = next;
free(old_node);
old_node = NULL;
return val;
}流程图:
当我们理解了删除下标 i 的结点的操作后,那么尾删和头删就比较简单了,代码如图:
cpp
// 头删
LDataType ListPopFront(LNode* L)
{
return ListDelete(L, 0);
}
cpp
// 尾删
LDataType ListPopBack(LNode* L)
{
assert(L&&L->next);
LNode* cur = L->next, * prev = L;
while (cur->next)
{
prev = cur;
cur = cur->next;
}
prev->next = NULL;
LDataType x = cur->data;
free(cur);
cur = NULL;
return x;
}对于头部删除可以直接复用操作,但尾部删除则不行,因为我们无法直接获取尾节点的下标。这时有两种处理方式:
- 先遍历链表找到尾节点的下标,然后复用删除指定下标节点的操作;
- 定义
cur和prev两个指针同时遍历,cur最终指向尾节点,prev指向其前驱节点,这种方式效率更高。
2.5.销毁操作
销毁链表时需要逐个遍历并释放节点,但是释放当前节点前,我们要先用next保存下一个节点的地
址,否则释放后将无法访问后续节点。
代码:
cpp
// 销毁链表
void ListDestroy(LNode* L)
{
assert(L);
LNode* cur = L->next;
while (cur)
{
LNode* next = cur->next;
free(cur);
cur = NULL;
cur = next;
}
free(L);
}注意:我们不可以直接将L=NULL;因为我们这是一级指针。
2.6.其他操作
cpp
// 判断链表是否为空
bool ListEmpty(LNode* L)
{
assert(L);
return L->next==NULL;
}
cpp
// 获取链表有效结点个数
int ListSize(LNode* L)
{
assert(L);
int size = 0;
LNode* cur = L->next;
while (cur)
{
size++;
cur = cur->next;
}
return size;
}2.7.测试代码
我们需要先手动创建一个链表,如代码:
cpp
#include "List.h"
LNode* CreateList()
{
// 创建头结点
LNode* L = BuyListNode(-1);
// 快速构造 5 个结点
LNode* node1 = BuyListNode(1);
LNode* node2 = BuyListNode(2);
LNode* node3 = BuyListNode(3);
LNode* node4 = BuyListNode(4);
LNode* node5 = BuyListNode(5);
// 手动链接
L->next = node1;
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = node5;
return L;
}接下来就是测试代码的操作是否可行了,如代码:
cpp
void TestList1()
{
LNode* LT = NULL;
LT = CreateList();
// 测试打印和结点个数
printf("链表 LT 中共有 %d 个结点\n", ListSize(LT));
ListPrint(LT);
// 测试按值查找
printf("链表中值 %d 的结点为 %p\n", 1, ListLocateElem(LT, 1));
printf("链表中值 %d 的结点为 %p\n", 3, ListLocateElem(LT, 2));
printf("链表中值 %d 的结点为 %p\n", 100, ListLocateElem(LT, 100));
// 测试按下标查找
printf("链表中下标 %d 的结点值为 %d\n", 0, ListGetElem(LT, 0)->data);
printf("链表中下标 %d 的结点值为 %d\n", 2, ListGetElem(LT, 2)->data);
printf("链表中下标 %d 的结点值为 %d\n", 4, ListGetElem(LT, 4)->data);
printf("链表中下标 %d 的结点为 %p\n", 100, ListGetElem(LT, 100));
// 销毁
ListDestroy(LT);
}
void TestList2()
{
LNode* LT = NULL;
LT = CreateList();
ListPrint(LT);
ListInsert(LT, 5, 10); // 尾插
ListPrint(LT);
ListInsert(LT, 2, 30); // 中间插入
ListPrint(LT);
ListInsert(LT, 0, 0); // 头插
ListPrint(LT);
//// 非法下标测试
//// ListInsert(LT, 100, 100);
printf("\n\n");
//ListDelete(LT, 0); // 头删
ListPopFront(LT);
ListPrint(LT);
ListDelete(LT, 2); // 中间删
ListPrint(LT);
//ListDelete(LT, 5); // 尾删
ListPopBack(LT);
ListPrint(LT);
//// 非法下标删除
//// ListDelete(LT, 100);
ListDestroy(LT);
}
int main()
{
// TestList1();
TestList2();
return 0;
}相关代码仓库已全部上传至以下Gitee地址:
下一篇为双链表。