目录
[四、梯度下降(Gradient Descent)](#四、梯度下降(Gradient Descent))
[七、Mini-Batch SGD](#七、Mini-Batch SGD)
一、前言
在学习神经网络时,我们经常会看到这样的代码:
python
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.001
)或者:
python
optimizer = torch.optim.SGD(
model.parameters(),
lr=0.01
)很多初学者会疑惑:
为什么训练神经网络需要优化器?
优化器到底在优化什么?
SGD和Adam有什么区别?
为什么现在大家都在用Adam?事实上:
神经网络训练的本质
就是不断优化参数而优化器的作用就是:
找到一组最优权重
让模型误差最小从最早的梯度下降(GD),到随机梯度下降(SGD),再到 Momentum、RMSProp 和 Adam,神经网络优化算法经历了数十年的发展。
本文将系统讲解:
什么是梯度下降
梯度是什么
SGD原理
Momentum原理
RMSProp原理
Adam原理
PyTorch实战帮助你彻底理解神经网络训练的核心机制。
二、神经网络训练的本质
神经网络本质上是在寻找:
最优参数W例如:
输入图片
↓
神经网络
↓
预测结果
↓
真实结果如果预测错误:
产生损失(Loss)例如:
真实值:1
预测值:0.7
误差:0.3训练目标:
让Loss越来越小整个过程如下:

三、什么是梯度
梯度(Gradient)可以理解为:
函数增长最快的方向例如:
假设损失函数:
Loss = x²当:
x = 3时:
Loss = 9如果想让Loss变小:
x必须向0靠近而梯度正好告诉我们:
应该朝哪个方向移动可以理解为:
梯度
=
下山时坡度最大的方向四、梯度下降(Gradient Descent)
假设你站在山顶:
目标:
走到山谷最低点过程:
神经网络训练也是如此。
参数更新公式:
W = W - 学习率 × 梯度其中:
W
模型参数
Learning Rate
学习率
Gradient
梯度代码实现:
python
w = 10
lr = 0.1
for i in range(10):
grad = 2 * w
w = w - lr * grad
print(w)输出:
8.0
6.4
5.12
...逐渐逼近最优解。
五、梯度下降的缺陷
假设:
训练集有100万条数据传统梯度下降每次都需要:
计算全部样本
然后更新一次参数流程:

缺点:
速度慢
内存消耗大
训练效率低因此出现:
SGD六、随机梯度下降(SGD)
SGD:
Stochastic Gradient Descent思想:
每次只用一个样本更新参数例如:
样本1
更新参数
↓
样本2
更新参数
↓
样本3
更新参数代码:
python
for x, y in dataset:
grad = compute_gradient(x, y)
w = w - lr * grad优点:
速度快
内存占用低缺点:
更新方向波动大
容易震荡七、Mini-Batch SGD
现代深度学习几乎都采用:
Mini Batch例如:
一次训练32条
一次训练64条
一次训练128条代码:
train_loader = DataLoader(
dataset,
batch_size=32
)优点:
稳定
训练效率高
GPU利用率高八、Momentum优化器
SGD的问题:
容易左右摇摆如下图:
左
右
左
右
左
右收敛很慢。
于是提出:
Momentum思想:
增加惯性类似:
滚雪球下山速度越来越快。
参数更新:
当前梯度
+
历史梯度PyTorch代码:
python
optimizer = torch.optim.SGD(
model.parameters(),
lr=0.01,
momentum=0.9
)优点:
收敛更快
减少震荡九、RMSProp优化器
研究人员发现:
不同参数
梯度大小不同例如:
参数A梯度很大
参数B梯度很小统一学习率效果不好。
于是提出:
RMSProp思想:
不同参数
使用不同学习率特点:
梯度大
学习率变小
梯度小
学习率变大PyTorch实现:
python
optimizer = torch.optim.RMSprop(
model.parameters(),
lr=0.001
)优点:
收敛更稳定十、Adam优化器
Adam:
Adaptive Moment Estimation目前最流行的优化器之一。
核心思想:
Momentum
+
RMSProp同时拥有:
历史梯度记忆
自适应学习率工作流程:
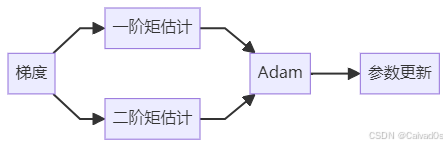
因此:
Adam
=
Momentum
+
RMSProp十一、为什么Adam这么强
Adam同时解决:
梯度震荡
学习率固定
收敛慢等问题。
优点:
收敛快
训练稳定
参数调节简单
适合大多数任务因此:
Transformer
BERT
GPT
LLaMA
DeepSeek等模型大量使用Adam变种。
十二、PyTorch使用Adam
创建优化器:
python
import torch
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.001
)训练代码:
python
for epoch in range(100):
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()执行流程:
前向传播
↓
计算损失
↓
反向传播
↓
Adam更新参数十三、实战案例
训练一个简单线性回归:
python
import torch
import torch.nn as nn
x = torch.tensor([[1.0],[2.0],[3.0]])
y = torch.tensor([[2.0],[4.0],[6.0]])
model = nn.Linear(1,1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.1
)
for epoch in range(200):
pred = model(x)
loss = criterion(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print(epoch, loss.item())输出:
0 12.56
20 0.63
40 0.08
60 0.01
...Loss不断下降。
说明:
Adam成功找到最优参数十四、常见优化器对比
| 优化器 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| GD | 全量梯度 | 稳定 | 非常慢 |
| SGD | 单样本更新 | 快 | 震荡大 |
| MiniBatch | 小批量更新 | 常用 | 需要调Batch |
| Momentum | 加入惯性 | 收敛快 | 参数更多 |
| RMSProp | 自适应学习率 | 稳定 | 较复杂 |
| Adam | Momentum+RMSProp | 综合最强 | 占用内存更多 |
十五、面试高频问题
什么是梯度?
损失函数增长最快的方向梯度下降的目的是什么?
最小化LossSGD和GD区别?
GD使用全部样本
SGD使用单个样本Momentum解决什么问题?
减少震荡
加快收敛Adam为什么效果好?
结合Momentum
和RMSProp优点当前大模型常用什么优化器?
Adam
AdamW十六、总结
神经网络训练的本质就是:
不断寻找更优参数优化算法的发展路线:
梯度下降 GD
↓
随机梯度下降 SGD
↓
Momentum
↓
RMSProp
↓
Adam每一次优化器的升级,都是为了解决:
收敛速度慢
震荡严重
学习率难调整等问题。
如今,Adam及其改进版 AdamW 已成为深度学习领域的事实标准。
可以说:
神经网络决定模型的上限,而优化器决定模型能否真正达到这个上限。从梯度下降到 Adam 的演进史,本质上就是深度学习训练效率不断提升的发展史。