
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. 传输层的基石:端口号详解](#一. 传输层的基石:端口号详解)
-
- [1.1 端口号的本质作用](#1.1 端口号的本质作用)
- [1.2 通信的唯一标识:五元组](#1.2 通信的唯一标识:五元组)
- [1.3 端口号范围划分](#1.3 端口号范围划分)
- [1.4 两个经典问题解答](#1.4 两个经典问题解答)
- [二. UDP 协议核心原理](#二. UDP 协议核心原理)
-
- [2.1 UDP 协议格式与报头结构体](#2.1 UDP 协议格式与报头结构体)
- [2.2 UDP 的封装与解包过程](#2.2 UDP 的封装与解包过程)
- [2.3 UDP 的三大核心特点](#2.3 UDP 的三大核心特点)
- [2.4 UDP 的缓冲区机制](#2.4 UDP 的缓冲区机制)
- [2.5 UDP 使用的关键注意事项](#2.5 UDP 使用的关键注意事项)
- [三. 基于 UDP 的应用层协议](#三. 基于 UDP 的应用层协议)
- [四. 内核源码解读](#四. 内核源码解读)
-
- [4.1 UDP 报头与套接字缓冲区](#4.1 UDP 报头与套接字缓冲区)
- [4.2 端口绑定的内核逻辑](#4.2 端口绑定的内核逻辑)
- 结尾:
前言:
传输层是 TCP/IP 协议栈的核心枢纽,承担着端到端数据传输的关键职责,解决了 "数据从哪个应用来,到哪个应用去" 的根本问题。在传输层两大核心协议中,TCP 以其复杂的可靠传输机制闻名,而 UDP 则以极致的简单性和高效性独树一帜。很多开发者认为 UDP"简单到没什么可学的",但正是这种简单性赋予了它极高的灵活性 ------DNS、DHCP、视频直播、游戏联机等场景都离不开 UDP 的支撑。本文将从端口号基础开始,深入解析 UDP 的协议格式、内核封装过程、核心特性与缓冲区机制,结合 Linux 内核源码片段和实战测试,带你全面掌握 UDP 协议的底层逻辑。
一. 传输层的基石:端口号详解
1.1 端口号的本质作用
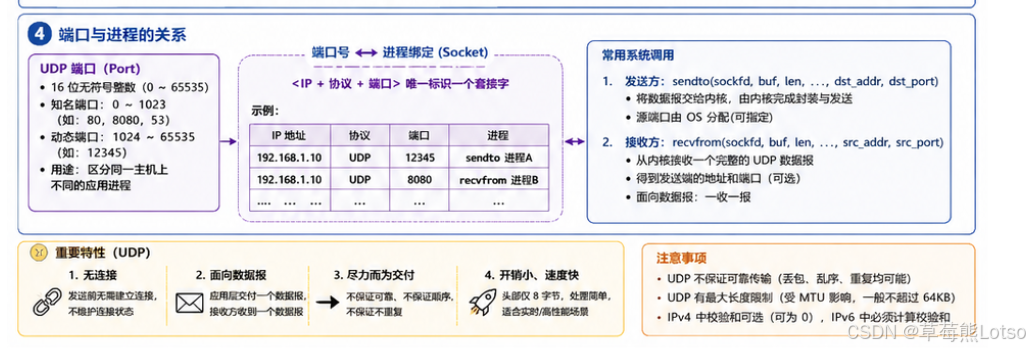
IP 地址只能标识互联网中的一台主机,但一台主机上同时运行着成百上千个应用进程。端口号 (Port) 正是用来标识主机上不同的通信应用程序的 16 位整数,它就像主机内部的 "房间号",让操作系统能够准确地将网络数据交付给对应的进程。
1.2 通信的唯一标识:五元组
在 TCP/IP 协议中,一个完整的通信连接由以下五个元素唯一确定,称为五元组:
bash
源IP地址 + 源端口号 + 目的IP地址 + 目的端口号 + 协议号例如,客户端 A (172.20.100.34:2001) 访问服务器 (172.20.100.32:80) 的 TCP 连接,其五元组为:
172.20.100.34:2001 -> 172.20.100.32:80 (TCP, 协议号6)
即使同一台主机上的不同浏览器标签页访问同一个网站,操作系统也会为每个标签页分配不同的源端口号,从而通过五元组区分不同的通信流。
1.3 端口号范围划分
16 位端口号的取值范围是 0~65535,操作系统将其划分为两类:
- 知名端口号 (0-1023) :由 IANA 统一分配,与标准应用层协议一一绑定,普通用户进程无权直接绑定。常见的知名端口号包括:
- SSH:22 端口
- FTP:21 端口
- HTTP:80 端口
- HTTPS:443 端口
- DNS:53 端口
- 动态端口号 (1024-65535):由操作系统动态分配给客户端程序,也是我们自定义服务器程序时推荐使用的端口范围。
可以通过以下命令查看系统中所有知名端口号的映射关系:
bash
cat /etc/services1.4 两个经典问题解答
在网络编程中,这两个问题几乎是面试必考点:
-
一个进程是否可以 bind 多个端口号?
- 可以。一个进程可以创建多个套接字 (socket),每个套接字绑定不同的端口号,从而同时监听多个端口的请求。
-
一个端口号是否可以被多个进程 bind?
- 不可以 (不考虑 SO_REUSEPORT 等特殊选项)。端口号是进程的唯一标识,如果多个进程绑定同一个端口,操作系统将无法确定数据应该交付给哪个进程。
实战验证 :我们尝试绑定 0-1023 范围内的端口,会直接失败;而绑定 1024 及以上端口则成
功:
bash
# 绑定80端口(知名端口)失败
whb@iv-ye4ege8iyo5i3z3clix9:~/code$ ./ssh_server 80
[FATAL][1665682][Tcperver.pp][105]-bind error:
# 绑定1023端口(知名端口上限)失败
whb@iv-ye4ege8iyo5i3z3clix9:~/code$ ./ssh_server 1023
[FATAL][1665699][TcpServer.pp][105]-bind error:3
# 绑定1024端口(动态端口起始)成功
whb@iv-ye4ege8iyo5i3z3clix9:~/code$ ./ssh_server 1024
[INFO][1665700][TcServer.pp][93]-socket success:3
[INFO][1665700][TcpServer.hpp][108]-bind success: 3
[INFO][1665700][Tcperver.pp][117]-listen success:3
二. UDP 协议核心原理
2.1 UDP 协议格式与报头结构体
UDP 协议的设计极其简洁,其报文格式只有固定的 8 字节报头,后面紧跟应用层数据:
| 字段 | 长度(位) | 描述 |
|---|---|---|
| 源端口号 | 16 | 发送端的端口号 |
| 目的端口号 | 16 | 接收端的端口号 |
| UDP 长度 | 16 | UDP 数据报总长度(首部 + 数据) |
| UDP 检验和 | 16 | 覆盖 UDP 首部和数据的检验和 |
| 应用层数据 | 可变 | 实际传输的应用层数据 |
在 Linux 内核中,UDP 报头被定义为一个 C 语言结构体,这体现了 "协议本质是双方约定的结构体类型" 的核心思想:
cpp
// Linux内核中UDP报头的定义(简化版)
struct udphdr {
__be16 source; // 源端口号(16位)
__be16 dest; // 目的端口号(16位)
__be16 len; // UDP报文总长度(报头+数据,16位)
__sum16 check; // 校验和(16位)
};各字段详解:
- 源端口号:发送端应用进程的端口号,可选字段,若不使用则填 0
- 目的端口号:接收端应用进程的端口号,必填字段
- UDP 长度:整个 UDP 报文的总长度 (包括 8 字节报头),最大值为 65535 字节 (64KB)
- 校验和:用于检测报文在传输过程中是否出错,若校验和错误,接收端会直接丢弃该报文,且不通知发送端
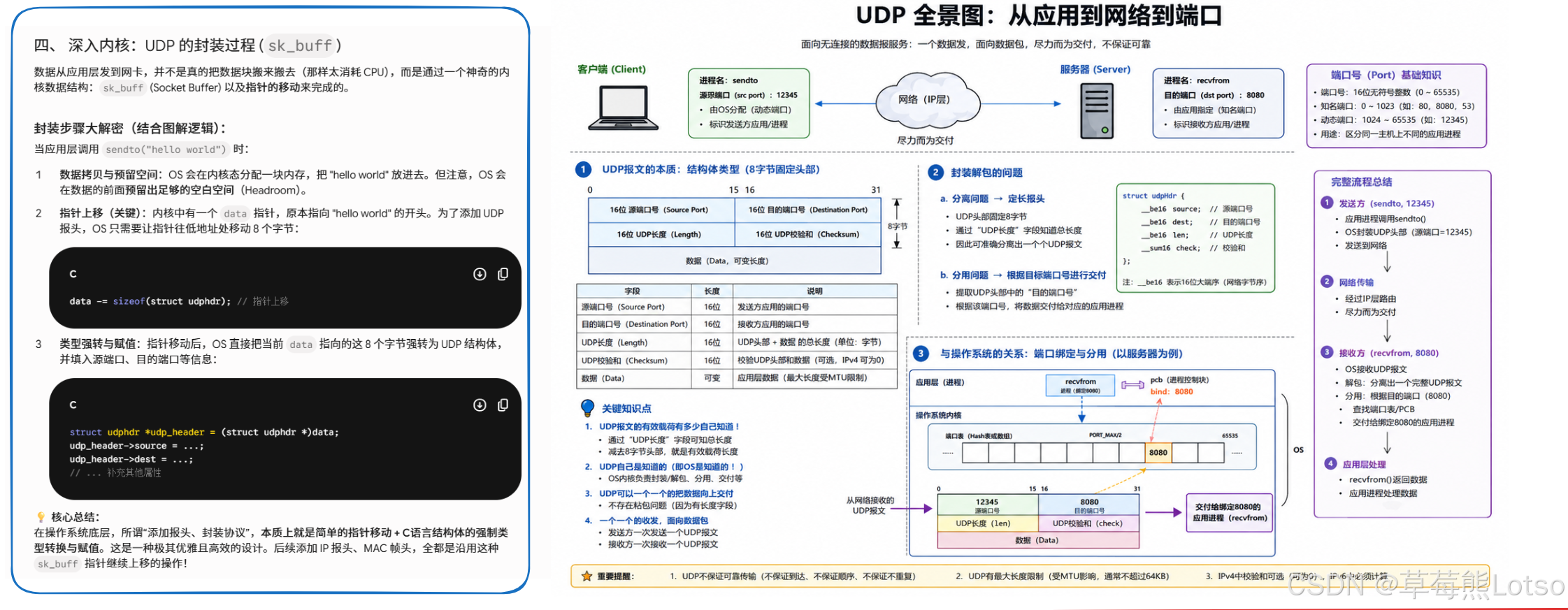
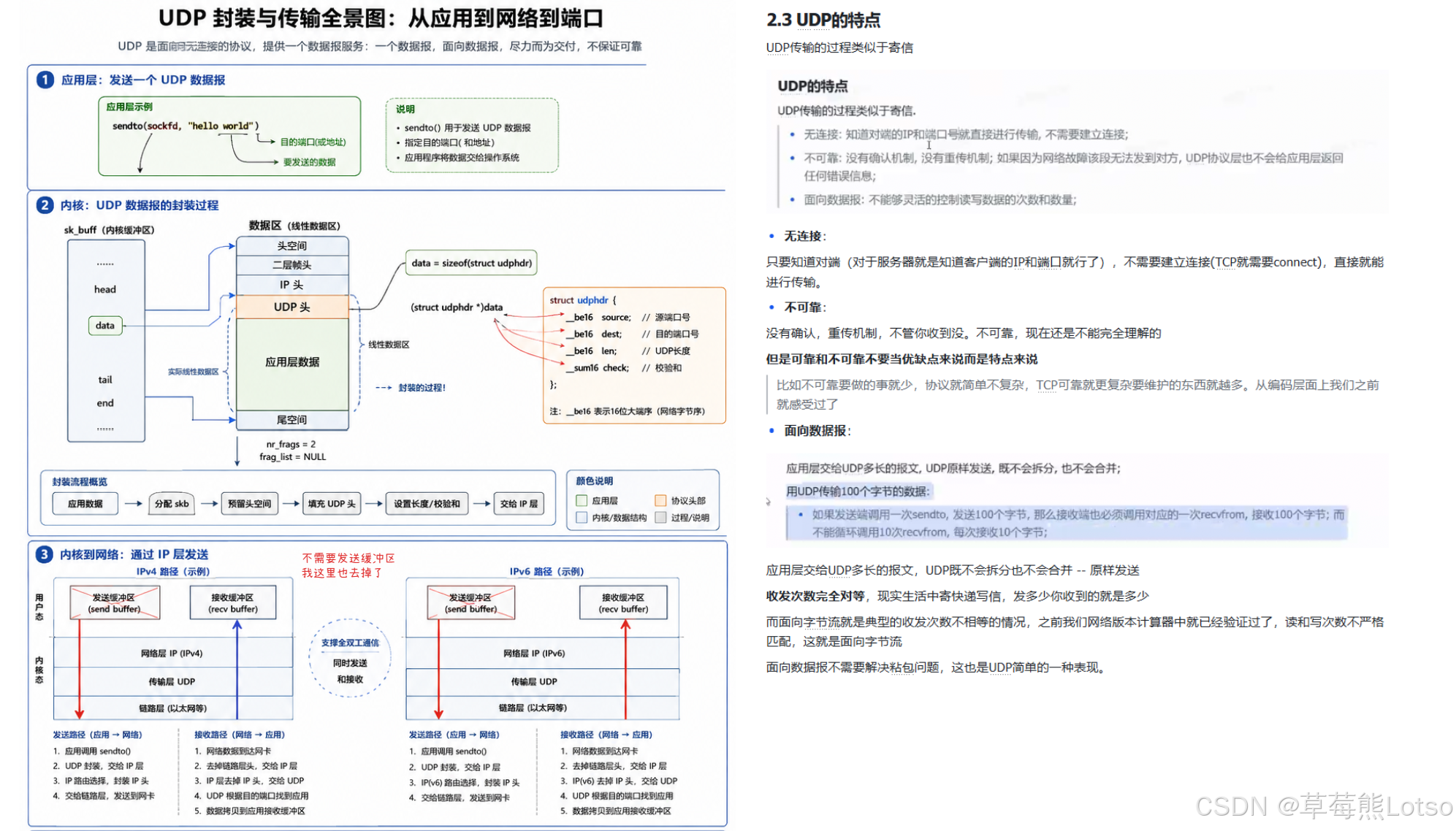
2.2 UDP 的封装与解包过程
封装过程 (发送端)
当应用层调用sendto函数发送数据时,内核会执行以下步骤:
- 在内核中创建一个
sk_buff结构体 (套接字缓冲区),用于管理网络报文 - 将应用层数据拷贝到
sk_buff的数据区 - 将
sk_buff的data指针向上移动sizeof(struct udphdr)字节,预留出 UDP 报头空间 - 填充
udphdr结构体的各个字段 (源端口、目的端口、长度、校验和) - 将封装好的 UDP 报文传递给网络层,添加 IP 报头后继续向下传递
这个过程本质上就是C 语言的指针操作 + 结构体填充,没有任何复杂的逻辑,这也是 UDP 高效的原因之一。
解包过程 (接收端)
当网络层将 IP 报文上传给传输层时,UDP 协议执行以下步骤:
- 分离报头与数据 :由于 UDP 报头是固定长度 (8 字节),直接提取前 8 字节作为
udphdr,剩余部分即为应用层数据 - 校验和验证:计算报文的校验和,若与报头中的校验和不一致,直接丢弃报文
- 分用交付 :根据目的端口号,在内核的哈希表中查找对应的套接字,将数据放入该套接字的接收缓冲区,等待应用层调用
recvfrom读取

2.3 UDP 的三大核心特点
UDP 的传输过程类似于寄信:写好信、写上地址,直接投入邮筒,不需要提前建立联系,也不保证对方一定能收到。
- 无连接UDP
不需要像 TCP 那样通过三次握手建立连接,只要知道对端的 IP 地址和端口号,就可以直接发送数据。这使得 UDP 的通信延迟极低,适合对实时性要求高的场景。 - 不可靠UDP
没有确认机制、重传机制和拥塞控制。如果报文在传输过程中丢失、损坏或乱序,UDP 协议层不会向应用层返回任何错误信息,发送端也不会知道报文没有送达。
注意:"不可靠" 不是 UDP 的缺点,而是它的特点。正是因为放弃了可靠性保证,UDP 才变得简单、高效,协议头只有 8 字节,而 TCP 的协议头至少有 20 字节。
- 面向数据报
应用层交给 UDP 多长的报文,UDP 就原样发送,既不会拆分,也不会合并 。这意味着:- 如果发送端调用一次sendto发送 100 字节,接收端必须调用一次recvfrom接收 100 字节,不能分 10 次每次接收 10 字节
- UDP 不存在 TCP 那样的 "粘包问题",因为每个 UDP 报文都是独立的边界
2.4 UDP 的缓冲区机制
UDP 的缓冲区设计与 TCP 有很大不同:
- 没有真正意义上的发送缓冲区:调用sendto后,数据会直接交给内核,由内核立即传递给网络层进行传输。UDP 不需要缓存数据用于重传,因此发送缓冲区没有存在的意义。
- 有接收缓冲区 :内核会为每个 UDP 套接字维护一个接收缓冲区,用于存放到达的报文。但这个缓冲区有两个重要限制:
- 不保证报文的顺序与发送顺序一致
- 如果缓冲区满了,后续到达的 UDP 报文会被直接丢弃
- 全双工:UDP 的套接字同时支持读和写操作,即可以在同一个套接字上发送和接收数据。
2.5 UDP 使用的关键注意事项
UDP 协议首部的 16 位长度字段决定了单个 UDP 报文的最大长度为 64KB (包括 8 字节报头)。在当今的互联网环境下,64KB 是一个非常小的数值。
如果需要传输超过 64KB 的数据,必须在应用层手动实现分包和拼装:
- 发送端:将大数据拆分成多个小于 64KB 的 UDP 报文,每个报文添加序号标识
- 接收端:根据序号将多个报文重新拼装成完整的数据
三. 基于 UDP 的应用层协议
虽然 UDP 本身不可靠,但它的简单性和高效性使其成为许多应用层协议的首选:
- DNS (域名解析协议):每次域名解析只需要发送一个小查询报文,接收一个小响应报文,UDP 的低延迟优势明显
- DHCP (动态主机配置协议):用于自动分配 IP 地址,采用广播方式通信,UDP 支持广播而 TCP 不支持
- TFTP (简单文件传输协议):用于小文件传输,设计简单,适合嵌入式设备
- NFS (网络文件系统):用于局域网内的文件共享,对传输速度要求高
- BOOTP (启动协议):用于无盘设备的网络启动
此外,视频直播、实时游戏、VoIP 电话等对实时性要求高的应用,也都基于 UDP 协议开发,并在应用层实现了自己的可靠性保证机制。

四. 内核源码解读
4.1 UDP 报头与套接字缓冲区
Linux 内核中,所有网络报文都通过sk_buff结构体管理,UDP 的封装过程本质上就是操作sk_buff的data指针:
c
// 简化的sk_buff结构体关键字段
struct sk_buff {
unsigned char *head; // 数据区起始地址
unsigned char *data; // 当前数据指针
unsigned char *tail; // 数据区结束地址
unsigned char *end; // 缓冲区结束地址
// ... 其他字段
};
// UDP封装的核心逻辑
struct udphdr *uh;
// 预留UDP报头空间
skb->data -= sizeof(struct udphdr);
// 填充UDP报头
uh = (struct udphdr *)skb->data;
uh->source = htons(source_port);
uh->dest = htons(dest_port);
uh->len = htons(skb->len);
uh->check = 0; // 先置0,后续计算校验和
// 计算校验和(省略)4.2 端口绑定的内核逻辑
当我们调用bind函数绑定端口时,内核会检查该端口是否已被占用:
- 在内核的哈希表中查找是否有套接字已经绑定了该端口
- 如果已存在且没有设置
SO_REUSEADDR或SO_REUSEPORT选项,返回错误 - 如果不存在,将当前套接字添加到哈希表中,绑定成功
这就是为什么一个端口不能被多个进程同时绑定的底层原因。
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:UDP 协议的设计哲学是 "简单即美",它将复杂性从协议本身转移到了应用层。虽然它没有 TCP 那样完善的可靠传输机制,但正是这种极简设计让它在实时性要求高、对少量丢包不敏感的场景中不可替代。在实际开发中,我们需要根据业务场景选择合适的传输协议:如果需要可靠的文件传输、网页访问,TCP 是更好的选择;如果需要低延迟的实时通信、广播或多播,UDP 则是不二之选。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
