目录
[三、监督学习(Supervised Learning)](#三、监督学习(Supervised Learning))
[四、无监督学习(Unsupervised Learning)](#四、无监督学习(Unsupervised Learning))
[五、半监督学习(Semi-Supervised Learning)](#五、半监督学习(Semi-Supervised Learning))
[六、强化学习(Reinforcement Learning)](#六、强化学习(Reinforcement Learning))
[八、树模型(Tree-Based Model)](#八、树模型(Tree-Based Model))
[XGBoost 属于什么类别?](#XGBoost 属于什么类别?)
[GPT 属于什么模型?](#GPT 属于什么模型?)
[K-Means 属于什么模型?](#K-Means 属于什么模型?)
一、前言
在学习人工智能和机器学习时,很多初学者都会遇到一个问题:
机器学习算法那么多
到底该如何分类?
线性回归是什么类型?
随机森林属于什么模型?
神经网络又属于什么模型?当我们接触越来越多的算法时:
线性回归
逻辑回归
决策树
随机森林
KNN
SVM
XGBoost
神经网络
深度学习很容易陷入混乱。
事实上,大部分机器学习算法都可以按照一定规则进行分类。
掌握这些分类方法后,我们不仅能够快速理解各种算法之间的关系,还能在实际项目中快速选择合适的模型。
本文将系统讲解:
机器学习模型的主要分类方式
监督学习与非监督学习
参数模型与非参数模型
生成式模型与判别式模型
树模型与线性模型
集成学习模型
深度学习模型帮助大家建立完整的机器学习知识体系。
二、机器学习模型总体分类
机器学习模型可以从多个维度进行划分。
整体结构如下:
mindmap
root((机器学习模型))
按学习方式分类
监督学习
无监督学习
半监督学习
强化学习
按模型结构分类
线性模型
树模型
概率模型
神经网络
按训练方式分类
参数模型
非参数模型
按建模目标分类
判别式模型
生成式模型三、监督学习(Supervised Learning)
监督学习是最常见的机器学习方式。
特点:
训练数据有标签例如:
| 年龄 | 工资 | 是否买房 |
|---|---|---|
| 25 | 8000 | 否 |
| 35 | 20000 | 是 |
| 40 | 30000 | 是 |
其中:
是否买房就是标签。
训练过程:

常见监督学习模型:
| 模型 | 类型 |
|---|---|
| 线性回归 | 回归 |
| 逻辑回归 | 分类 |
| KNN | 分类/回归 |
| 决策树 | 分类/回归 |
| 随机森林 | 分类/回归 |
| XGBoost | 分类/回归 |
| SVM | 分类 |
| 神经网络 | 分类/回归 |
四、无监督学习(Unsupervised Learning)
无监督学习:
训练数据没有标签例如:
用户年龄
消费金额
购买次数没有告诉模型:
哪些是VIP用户模型需要自己发现规律。
流程:

常见算法:
| 算法 | 作用 |
|---|---|
| K-Means | 聚类 |
| DBSCAN | 聚类 |
| PCA | 降维 |
| t-SNE | 可视化 |
| AutoEncoder | 特征提取 |
应用场景:
用户画像
客户分群
异常检测
推荐系统五、半监督学习(Semi-Supervised Learning)
现实中:
有标签数据很少
无标签数据很多例如:
100张标注图片
10000张未标注图片此时:
半监督学习能够利用少量标签和大量无标签数据共同训练。
应用:
医学影像
自动驾驶
目标识别六、强化学习(Reinforcement Learning)
强化学习关注:
如何通过不断试错获得最大收益核心思想:
奖励机制架构:

典型案例:
AlphaGo
自动驾驶
机器人控制
游戏AI七、线性模型
线性模型是机器学习最基础的模型。
特点:
假设数据之间存在线性关系常见公式:
y = w1x1 + w2x2 + ... + wnxn + by=w_1x_1+w_2x_2+\cdots+w_nx_n+b
常见模型:
线性回归
逻辑回归
岭回归
Lasso回归Python示例:
python
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)优点:
简单
训练快
可解释性强八、树模型(Tree-Based Model)
树模型是工业界应用最广泛的模型之一。
结构:
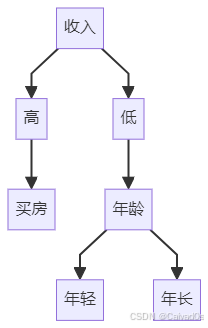
常见模型:
决策树
随机森林
GBDT
XGBoost
LightGBM
CatBoost特点:
无需特征归一化
适合非线性问题
可解释性较强九、概率模型
概率模型关注:
事件发生概率典型算法:
朴素贝叶斯
高斯混合模型
隐马尔可夫模型贝叶斯公式:
P(A|B)=P(B|A)P(A)/P(B)Python示例:
python
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)十、支持向量机(SVM)
SVM:
寻找最佳分类超平面目标:
最大化分类间隔示意:

特点:
适合小样本
高维数据效果好代码:
python
from sklearn.svm import SVC
model = SVC(kernel="rbf")
model.fit(X_train, y_train)十一、集成学习模型
集成学习:
多个模型共同决策思想:
三个臭皮匠
顶个诸葛亮分类:
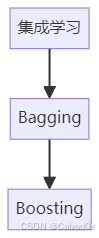
Bagging
代表:
随机森林原理:
多个决策树投票Boosting
代表:
GBDT
XGBoost
LightGBM原理:
前一个模型修正后一个模型十二、神经网络模型
神经网络模拟:
人脑神经元结构:

特点:
能够学习复杂非线性关系代码:
python
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(
hidden_layer_sizes=(128,64)
)
model.fit(X_train, y_train)十三、深度学习模型
深度学习:
多层神经网络常见模型:
| 模型 | 应用 |
|---|---|
| CNN | 图像识别 |
| RNN | 时序预测 |
| LSTM | NLP |
| Transformer | 大模型 |
| BERT | 文本理解 |
| GPT | 文本生成 |
架构:
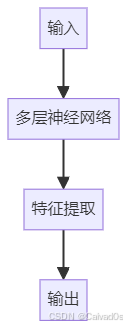
十四、生成式模型与判别式模型
这是面试高频问题。
判别式模型:
学习:
X → Y例如:
给定特征
预测标签模型:
逻辑回归
SVM
随机森林
XGBoost生成式模型:
学习:
数据分布能够:
生成新数据代表:
GAN
VAE
GPT
Diffusion十五、参数模型与非参数模型
参数模型
参数数量固定。
例如:
线性回归
逻辑回归特点:
训练快
占用资源少非参数模型
参数数量随数据增长。
例如:
KNN
决策树
随机森林特点:
灵活
表达能力强十六、实际项目如何选模型
数据量较小:
逻辑回归
SVM结构化数据:
随机森林
XGBoost
LightGBM图像识别:
CNN文本处理:
BERT
GPT
Transformer聚类分析:
K-Means推荐系统:
协同过滤
深度学习推荐模型十七、模型分类总结表
| 分类维度 | 模型 |
|---|---|
| 监督学习 | 线性回归、逻辑回归、随机森林 |
| 无监督学习 | K-Means、PCA |
| 强化学习 | Q-Learning、DQN |
| 树模型 | 决策树、随机森林、XGBoost |
| 概率模型 | 贝叶斯、高斯混合模型 |
| 神经网络 | MLP、CNN、RNN |
| 深度学习 | Transformer、GPT、BERT |
| 集成学习 | RandomForest、GBDT、LightGBM |
十八、面试高频问题
监督学习和无监督学习区别是什么?
监督学习有标签
无监督学习没有标签随机森林属于什么模型?
树模型
集成学习模型
监督学习模型XGBoost 属于什么类别?
Boosting
集成学习
树模型GPT 属于什么模型?
Transformer
生成式模型
深度学习模型K-Means 属于什么模型?
无监督学习
聚类算法十九、总结
机器学习模型种类繁多,但核心分类并不复杂。
整体体系可以理解为:
机器学习
│
├── 监督学习
│ ├── 线性模型
│ ├── 树模型
│ ├── SVM
│ └── 神经网络
│
├── 无监督学习
│ ├── 聚类
│ └── 降维
│
├── 强化学习
│
└── 深度学习
├── CNN
├── RNN
├── Transformer
└── GPT对于初学者来说,可以按照以下顺序学习:
线性回归
↓
逻辑回归
↓
决策树
↓
随机森林
↓
XGBoost
↓
神经网络
↓
Transformer
↓
大语言模型(LLM)这样能够逐步建立完整的机器学习知识体系,为后续学习深度学习、推荐系统、计算机视觉和大模型打下坚实基础。