
🔥个人主页: Ryan
在 AI 圈子里,一直流传着一个心照不宣的秘密:用 LangChain 或 LlamaIndex 几行代码搭一个 RAG(检索增强生成)系统,只需要一个下午;但要让它达到生产环境的落地上线标准,往往需要大半年。
大部分人在做 Demo 时,觉得 RAG 极其简单:把 PDF 切碎 -> 塞进向量数据库 -> 丢给大模型 -> 搞定。然而,一旦把这样的系统推向真实的业务场景,面对复杂的企业用户和各种奇葩的非结构化文档时,系统往往会演变成一个"幻觉放大器"。
1. 建立RAG概念
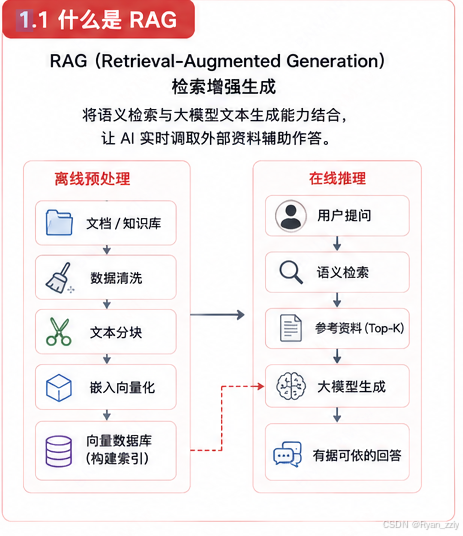
1.1 什么是RAG
RAG Retrieval-Augmented Generation 检索增强生成
它跳出了传统大模型 "仅凭自身预训练参数完成生成" 的单一模式,将语义检索 与大模型文本生成两大能力深度结合,让 AI 不再局限于训练阶段习得的固有知识,而是可以实时调取外部资料辅助作答。
一套完整的 RAG 系统分为离线预处理 与在线推理两大环节:
离线阶段,系统会对各类文档、知识库、业务资料做清洗、文本分块,再通过嵌入模型把文字转化为向量,存入向量数据库建立索引;
在线推理阶段,当用户发起提问时,系统先将问题转为向量,在向量库中精准匹配语义相近的文档片段,随后把检索到的参考资料、用户问题整合为规范提示词输入大模型。最终大模型结合自身理解与真实参考内容,输出完整、有据可依的回答。
1.2 它解决了什么问题
原生大模型受训练机制、数据边界、技术架构所限,在真实业务场景中存在诸多先天短板,RAG 架构正是针对性化解这些痛点而生,核心价值体现在三大方面:
知识幻觉
大模型本质是基于自回归的文本生成模型,一旦面对训练数据未覆盖、细节模糊的内容,很容易凭空编造事实、虚构数据与结论,这就是行业内所说的 "幻觉"。RAG 以检索到的真实文档作为作答基准,强制模型依托原始资料进行输出,从根源上减少虚构内容,让每一句回答都有迹可循,同时增强可解释性。
知识过期
所有主流大模型的预训练数据集都存在固定时间截止点,对于训练完成后诞生的新政策、行业动态、产品迭代信息、实时业务数据等,模型完全无法感知。RAG 的外部知识库支持动态增删改查,只需更新文档就能让系统掌握最新信息,无需重新训练模型,完美适配知识持续迭代的场景。
知识壁垒
企业内部手册、涉密资料、客户档案、专属业务文档等私有数据,体量庞大且具备私密性,既无法全部纳入大模型公开训练集,也不能随意对外共享。RAG 将私有数据独立部署在本地或专属向量库中,仅在问答环节按需调用片段,让大模型安全服务于企业内部专属场景。

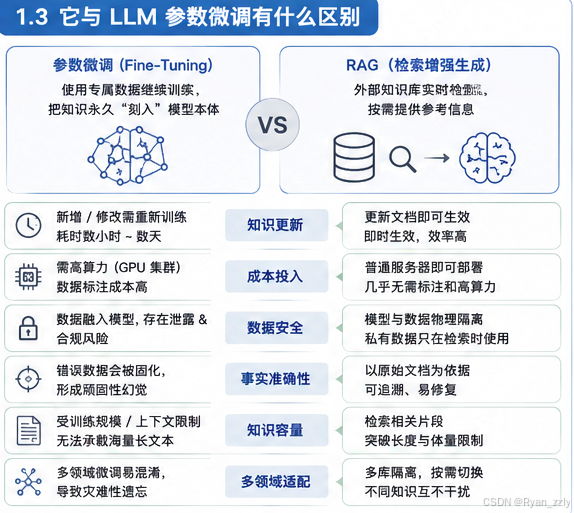
1.3 它与LLM参数微调有什么区别
随着主流大模型的上下文窗口(Context Window)从 4K、32K 一路飙升到 1M 甚至 2M(百万级别 Token),技术圈开始出现一种声音:"既然模型能一次性读完几百本书,那 RAG 是不是该被淘汰了?"或者是"要让大模型学习企业私有知识,是不是直接上 Fine-Tuning(微调)更高级?"
这其实是典型的技术选型误区,首先一句话明确:两者解决的不是同一层的问题,不是替代关系
参数微调
参数微调是在预训练大模型的基础上,使用专属数据集继续迭代训练模型权重,相当于把知识、话术、风格永久 "刻入模型本体"。
相较于LLM参数微调,RAG解决了什么问题?
1. 知识更新困难、算力成本高,迭代效率极低
微调想要新增、修改、删除知识,必须重新整理标注数据集、启动训练、验证效果,整个流程从数小时到数天不等,完全无法适配频繁变动的内容(如新政策、产品迭代文档、实时资讯、动态业务数据)。并且微调对硬件要求高:尤其是大参数量模型,需要高性能 GPU 集群支撑训练;同时还要投入人力做数据清洗、标注、调参、模型评估,中小团队很难负担。
RAG 只需要对外部知识库做文档增删改查,向量库同步后即时生效 ,知识迭代效率提升几个量级。RAG 技术链路轻量化,核心工作是文档处理、文本分块、向量化、检索配置,普通服务器即可部署,几乎无需大规模标注和高端算力,落地成本大幅降低。
2. 私有 / 涉密数据的合规与安全风险
微调必须将原始数据灌入训练流程,企业内部资料、客户隐私、涉密文档会被模型权重 "记忆",存在数据泄露、违反合规要求的巨大风险。
RAG 实现了模型与数据物理隔离:私有数据始终存放在独立向量库中,仅在问答时临时调取片段辅助生成,全程不参与模型训练,从架构上保障数据安全。
3. 错误知识永久固化,加剧幻觉
如果微调使用的训练数据本身存在错误、片面信息,这些错误会被写入模型权重,变成模型的 "固有认知",后续会反复输出错误内容,形成顽固性幻觉,且很难修复。
RAG 以原始文档为回答依据,事实源头可控;若某篇文档有误,直接替换 / 删除文档即可修复,不会影响整个系统。
4. 海量长文本、超大知识库无法承载
微调受训练数据规模、模型上下文窗口双重限制,不可能将几十万、上百万字的文档库、历史文献、全量业务手册全部纳入训练集。
RAG 通过文本分块 + 语义检索,只抽取和问题强相关的片段送入模型,突破了上下文长度和知识库体量的限制,天生适配海量文档问答。
5. 多领域知识相互干扰、模型能力退化
如果用多领域、碎片化数据反复微调模型,容易出现灾难性遗忘(模型丢失原有能力)、知识混淆、输出混乱等问题。
RAG 可搭建多个独立向量库,不同业务、不同领域的知识库相互隔离,按需切换调用,不会互相干扰。
1.4 为什么你的 RAG 在生产环境成了"幻觉放大器"?
当用户开始抱怨"AI 在胡说八道"时,很多工程师的第一反应是调优 Prompt,或者怪罪大模型(LLM)不够聪明。但事实上,真实生产环境中的 Bad Case,有 80% 发生在检索和数据工程阶段。
我们可以把生产环境中最容易翻车的典型场景归纳为以下三种:
"未卜先知"与局部失真(Garbage in, Garbage out):直接拿传统的固定 Token 长度去硬切文档,极容易把一句完整的话、一个核心的表格数据从中间切断。当 LLM 拿到一个被腰斩的 Context(上下文)时,它只能被迫开启"脑补"模式,产生严重的逻辑幻想。
"Lost in the Middle"(大海捞针失败):当你的知识库召回了前 10 个最相关的文本片段丢给大模型时,大模型往往只能记住开头和结尾的信息。这种"长文本中间信息丢失"的现象,直接导致用户问到核心细节时,大模型明明"看"过,却依然回答"不知道"。
时间与空间的错位:向量检索只管"语义相似度",它没有"时效性"概念。如果你的知识库里同时存在《2024年第一季度财报》和《2025年第一季度财报》,当用户问"最新一季度的利润是多少"时,纯向量检索极大概率会因为语义高度相似,把 2024 年的数据召回出来,导致严重的业务灾难。

1.5 链路拆分
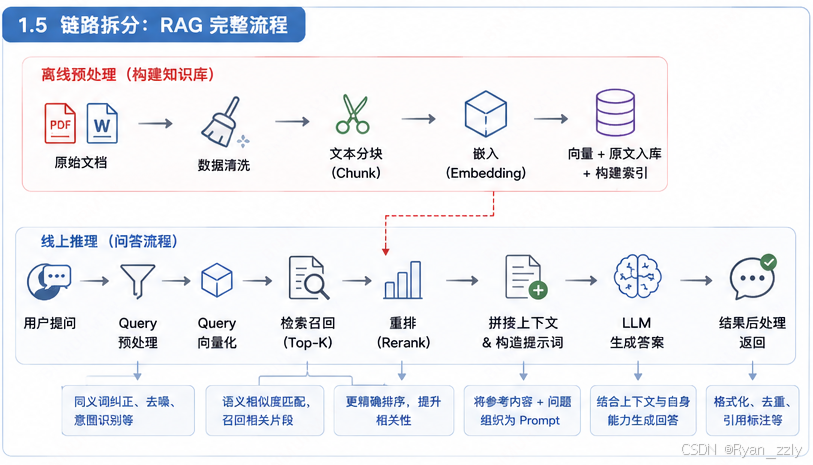
离线预处理:原始文档 → 数据清洗 → 文本分块 (Chunk) → 嵌入 (Embedding) → 向量 + 原文入库 + 构建索引
**线上推理:**用户提问 → Query 预处理 → Query 向量化 → 检索召回 → 重排 (Rerank) → 拼接上下文 & 构造提示词 → LLM 生成答案 → 结果后处理返回
后续的实战代码是基于 Spring-Boot-AI-Alibaba
2. 离线预处理
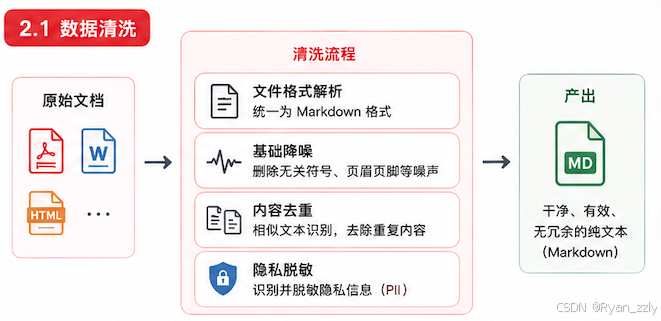
2.1 数据清洗
统一文本格式、剔除无效噪声、去除隐私信息,产出干净、有效、无冗余的纯文本。
在实际的企业开发中,会有专门的RAG知识库管理员去完成这一块工作,去沉淀,整理、产出风格统一,有效的文本(这里拿md文档举例)
这部分的主要工作,主要有 文件格式解析、基础降噪(删除无关符号内容信息)、内容去重、数据脱敏等等
文件格式解析(以 Markdown 为黄金标准) :企业原始文档(PDF/Word/HTML)必须统一向 Markdown 格式对齐。因为 Markdown 的 #、## 等层级标签,能天然地为接下来的文本分块提供完美的语义边界信号。
基础降噪与内容去重 :利用正则清洗掉高频噪音(如无意义的特殊符号、乱码、重复的页眉页脚)。针对相同知识点在多份文档中重复出现的场景(例如:不同版本的员工手册),清洗阶段必须做文本去重(如 SimHash 或 MinHash 算法),防止线上检索到大量重复、冗余的 Chunk,白白浪费 LLM 的上下文窗口。
隐私脱敏(Data Masking):生产环境下,安全是不可触碰的红线。在入库前,必须通过命名实体识别(NER)或正则,对身份证号、手机号、薪资等敏感隐私信息(PII)进行掩码或替换脱敏。
java
@Service
public class DataCleaningService {
private final ChatClient chatClient;
// 注入 ChatClient 用于 LLM 语义清洗
public DataCleaningService(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
/**
* 执行完整的前置数据清洗管道
* @param pdfResource 原始非结构化文件资源
* @return 清洗并切片完成的、可直接用于 Embedding 的 Document 列表
*/
public List<Document> processAndCleanData(Resource pdfResource) {
// Step 1: 代码处理 - 原始文档解析提取
TikaDocumentReader reader = new TikaDocumentReader(pdfResource);
List<Document> rawDocuments = reader.read();
// Step 2: 代码处理 - 基于正则与规则的硬清洗 (去噪、去广告、去页眉页脚)
List<Document> ruleCleanedDocs = rawDocuments.stream()
.map(this::cleanNoiseByRegex)
.filter(doc -> doc.getContent() != null && !doc.getContent().isBlank())
.collect(Collectors.toList());
// Step 3: LLM 处理 - 语义级别提纯(可选,耗时,通常用于极度离线的核心文档)
List<Document> llmPurifiedDocs = ruleCleanedDocs.stream()
.map(this::purifyContentWithLLM)
.collect(Collectors.toList());
// Step 4: 代码处理 - 结构化切片 (Chunking)
// 使用针对 Token 优化的切片器(Spring AI 内置)
DocumentTransformer splitter = new TokenTextSplitter(
800, // chunk size
200, // chunk overlap
10, // max chunks per doc
true // keep separator
);
// 返回最终可以直接存入 Milvus/PGVector 的高质量 Chunk 集合
return splitter.transform(llmPurifiedDocs);
}
/**
* 【纯代码/正则清洗】
* 极快、零成本。秒杀顽固的无用空白字符、HTML标签、特定广告语和页脚规则。
*/
private Document cleanNoiseByRegex(Document doc) {
String content = doc.getContent();
// 1. 去除多余的空行和连续空格
content = content.replaceAll("\\s+", " ");
// 2. 正则剔除页眉页脚模板(例如:模拟去除 "Page X of Y" 或 "内部资料,禁止外传")
content = content.replaceAll("(?i)page \\d+ of \\d+", "");
content = content.replaceAll("内部资料,禁止外传", "");
// 3. 剔除常见的无用网页链接或特殊乱码
content = content.replaceAll("https?://\\S+\\s?", "");
// 保持 Metadata 原样,只更新清洗后的文本内容
return new Document(content.trim(), doc.getMetadata());
}
/**
* 【LLM 语义清洗与增强】
* 依靠大模型对经过初筛的文本进行"脱水"与"纠错"
*/
private Document purifyContentWithLLM(Document doc) {
String systemPrompt = """
你是一个严格的数据清洗专家。请对输入的文本进行预处理,要求:
1. 修正由于 PDF 或者是 OCR 解析带来的文本断句错误、错别字。
2. 去除文本中与核心主题无关的口语化垫字、社交推广语。
3. 严禁篡改原意,严禁补充任何外部知识,仅做去噪和修正。
4. 直接输出清洗后的纯文本,不要带有任何解释或 Markdown 格式包裹。
""";
// 让 LLM 介入清洗
String purifiedContent = this.chatClient.prompt()
.system(systemPrompt)
.user(doc.getContent())
.call()
.content();
// 还可以顺便利用 LLM 做数据增强 (Data Enrichment),比如把处理的元数据顺手挂在 Document 上
Map<String, Object> metadata = doc.getMetadata();
metadata.put("is_llm_purified", true);
return new Document(purifiedContent, metadata);
}
}
2.2 文本分块
Chunking
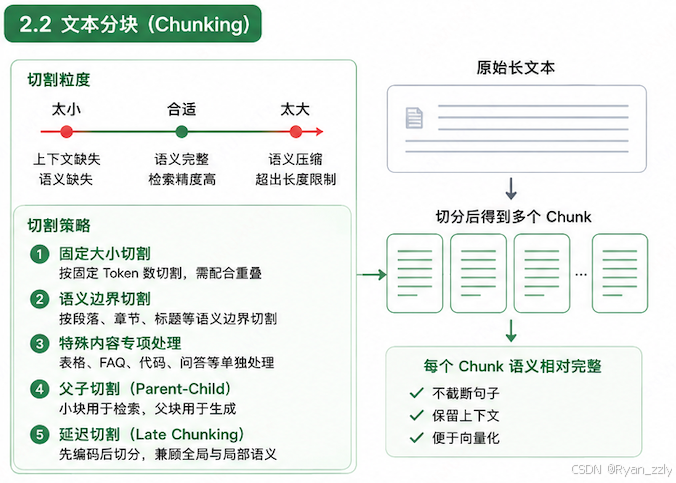
大模型、嵌入模型都有单次可处理字符 / Token 上限,几十万字的长文档无法直接向量化和检索。分块就是把长文本切分成一段段短小、语义相对完整的文本片段(Chunk),是决定检索精度的核心环节之一。
切割粒度
chunk既不能太大也不能太小
太大,语义会压缩在一起,变得笼统,且容易超出Embeding模型的输入长度限制
太小,可能会上下文缺失,语义缺失
因此切割的粒度与我们原始文本息息相关
切割策略
1. 固定大小切割 (Fixed Size Chunking)
思路:按固定字符 / Token 数量强行切割,例如每 800 Token 切一块;
纯 固定大小切割 在实际中根本不使用,一般会加上 重叠 Overlap解决边界的截断问题
适用场景:纯文本,无明显结构的文档,这是玩具 Demo 的做法,生产环境极不推荐。因为它无法从根本上解决句子、代码段或表格在中间被拦腰折断的惨剧。
2. 语义边界切割 (Semantic Based Chunking)
思路:按文档的自然语义边界来切割,比如段落,章节,标题层级,不在语义中间截断,找到文字的天然分割点
操作:一般会先维护一个分隔符优先级,然后尝试按段落切,切出来太大,再按标点进一步切分,依次类推,直至满足chunkSize
适用场景:有着清晰标题结构的md或者html
3. 特殊内容专项处理
思想:针对表格、FAQ、代码、问答对、层级目录单独定制切分规则,不破坏原有结构。
4. 父子切割 (Parent-Child-Chunking)
精髓 :分离"检索"与"生成"的职能。
操作 :把长文档切成 1024 词的父块(存入关系/全文数据库供 LLM 阅读),再把父块细切成 256 词的子块(存入向量库用于高精度匹配)。通过 parent_id 建立两者的映射。用更小的特征去勾勒检索线索,用更完整的上下文去赋能 LLM 生成。
java
@Component
public class ParentChildDocumentSplitter {
// 定义父分块和子分块的大小
private static final int PARENT_CHUNK_SIZE = 800;
private static final int PARENT_CHUNKS_OVERLAP = 100;
private static final int CHILD_CHUNK_SIZE = 150;
private static final int CHILD_CHUNKS_OVERLAP = 30;
/**
* 将输入的高质量清洗后文档,切分为建立了父子引用关系的 Chunk 集合
* * @param cleanedDocuments 经过前置清洗后的核心文档列表
* @return 最终返回【子分块列表】(子分块元数据中会挂载父分块的全量文本和父ID)
*/
public List<Document> splitWithParentChildStrategy(List<Document> cleanedDocuments) {
// 1. 初始化父、子切片器
TokenTextSplitter parentSplitter = new TokenTextSplitter(
PARENT_CHUNK_SIZE, PARENT_CHUNKS_OVERLAP, 10, true
);
TokenTextSplitter childSplitter = new TokenTextSplitter(
CHILD_CHUNK_SIZE, CHILD_CHUNKS_OVERLAP, 10, true
);
List<Document> allChildChunksToEmbed = new ArrayList<>();
for (Document originalDoc : cleanedDocuments) {
// 2. 第一层切分:切出父分块 (Parent Chunks)
List<Document> parentChunks = parentSplitter.apply(List.of(originalDoc));
for (Document parentDoc : parentChunks) {
// 为当前父分块生成一个唯一 ID
String parentId = UUID.randomUUID().toString();
String parentText = parentDoc.getContent();
// 3. 第二层切分:把当前的父分块,进一步细切成子分块 (Child Chunks)
List<Document> childChunks = childSplitter.apply(List.of(parentDoc));
for (Document childDoc : childChunks) {
// 获取并继承原有的元数据,避免丢失来源信息
Map<String, Object> childMetadata = childDoc.getMetadata();
// 4. 核心纽带:在子分块的元数据中,绑定父分块的特征
childMetadata.put("parent_id", parentId);
// 策略选择:
// 选择 A:只存 parent_id,检索命中后通过数据库二次查询 Parent 文本(适合商业数据库)
// 选择 B:直接把父文本塞进子分块元数据,随子分块一同持久化(适合快速落地的轻量系统)
childMetadata.put("parent_content", parentText);
childMetadata.put("doc_type", "child_chunk");
// 重新构建子分块 Document 对象
Document standardChildDoc = new Document(
childDoc.getContent(),
childMetadata
);
allChildChunksToEmbed.add(standardChildDoc);
}
}
}
// 最终返回所有的子分块。这批子分块会被送进 EmbeddingClient 并存入向量数据库
return allChildChunksToEmbed;
}
}5. 延迟切割 Late Chunking
思想:前面提到的这几种策略都是先分块后编码 的处理方式,Late Chunking 就是先编码后分块
关键操作:
-
a. 全局前向传播 :直接把整篇长文档(如 8K 长度)塞进长文本 Embedding 模型(如
jina-embeddings-v2)。模型在计算时,通过全局自注意力机制(Self-Attention),让每一个 Token 向量都吸收了整篇文章的上下文信息。此时,后半句里的"它"在向量层面上已经和"苹果公司"深度绑定了。 -
b. 向量层面切分:保持这个有序的 Token 向量序列不动,根据语义边界或固定大小,在向量序列上"切刀"。
-
c. 块平均池化(Mean Pooling) :对切好的子块内部的所有 Token 向量做平均池化(Mean Pooling),合并成一个能代表这个子块语义的唯一向量。这样得到的子块向量,既有本地高精度,又自带全局上帝视角。
2.3 嵌入 Embedding
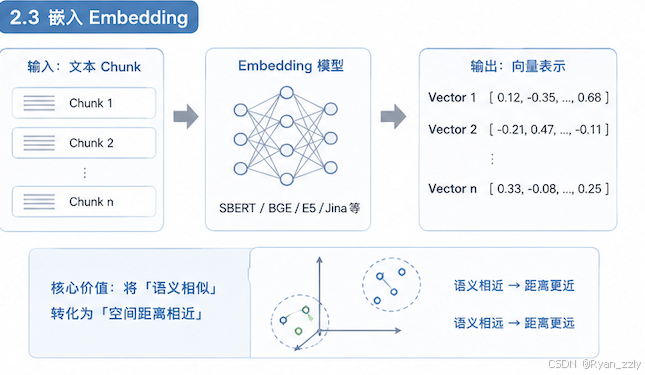
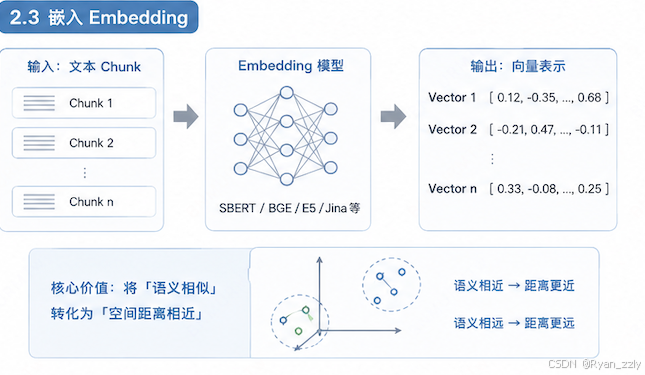
这一步是实际做嵌入即向量化的过程,把一段自然语义文本映射为一个固定长度的浮点数向量
**核心价值:**把「语义相似」转化为「空间距离相近」(RAG 的灵魂)
语义越接近的两段文本,它们对应的向量,在高维空间中的距离就越近、夹角就越小。
java
/**
* 生成向量嵌入
* 调用阿里云 DashScope Text Embedding API
*
* @param content 文本内容
* @return 向量嵌入(浮点数列表)
*/
public List<Float> generateEmbedding(String content) {
try {
if (content == null || content.trim().isEmpty()) {
logger.warn("内容为空,无法生成向量");
throw new IllegalArgumentException("内容不能为空");
}
logger.debug("开始生成向量嵌入, 内容长度: {} 字符", content.length());
// 确保 API Key 已设置(防止被其他地方覆盖)
if (Constants.apiKey == null || Constants.apiKey.isEmpty()) {
logger.warn("检测到 Constants.apiKey 为空,重新设置");
Constants.apiKey = apiKey;
}
logger.debug("调用 API 前 Constants.apiKey: {}",
Constants.apiKey != null ? Constants.apiKey.substring(0, Math.min(8, Constants.apiKey.length())) + "..." : "null");
// 构建请求参数
TextEmbeddingParam param = TextEmbeddingParam
.builder()
.model(model)
.texts(Collections.singletonList(content))
.build();
// 调用 API
TextEmbeddingResult result = textEmbedding.call(param);
// 检查结果
List<Float> floatEmbedding = getFloats(result);
logger.info("成功生成向量嵌入, 内容长度: {} 字符, 向量维度: {}",
content.length(), floatEmbedding.size());
return floatEmbedding;
} catch (NoApiKeyException e) {
logger.error("API Key 未设置或无效", e);
throw new RuntimeException("API Key 未设置,请配置 dashscope.api.key", e);
} catch (Exception e) {
logger.error("生成向量嵌入失败, 内容长度: {}", content != null ? content.length() : 0, e);
throw new RuntimeException("生成向量嵌入失败: " + e.getMessage(), e);
}
}Embedding算法
算法是通过迭代的
从初代的静态词向量(Word2Vec、FastText)-> 上下文相关向量(BERT)-> 句子级对比学习 (SBERT)
SBERT 用共享权重的孪生网络(Siamese Network)改造 BERT:
- 传统 BERT(交叉编码器 Cross-Encoder):两个句子一起输入,输出相似度分数(无法复用)
- SBERT(双编码器 Bi-Encoder):两个句子分别独立通过同一个 BERT,各自生成句向量,再用余弦相似度比较
2.4 存储数据+构建索引
离线预处理的最后一步,是将清洗出的数据真正持久化。在工业界,一个标准的知识库条目包含"三位一体"的数据流:
-
向量(Vector) :高维浮点数数组,存入向量数据库的向量索引区(如 HNSW、IVF_FLAT 结构),用于线上的高并发 ANN(近似最近邻)语义检索。
-
文本块原文(Chunk Text):用于在线检索命中后,直接提取出来拼接进 Prompt 喂给大模型。
-
元数据(Metadata) :包含
file_name(文件名)、category(业务分类)、created_at(创建时间)、parent_id(父块ID)
java
/**
* 插入向量到 Milvus
*/
private void insertToMilvus(String content, List<Float> vector,
Map<String, Object> metadata, int chunkIndex) throws Exception {
try {
// 确保 collection 已加载
R<RpcStatus> loadResponse = milvusClient.loadCollection(
LoadCollectionParam.newBuilder()
.withCollectionName(MilvusConstants.MILVUS_COLLECTION_NAME)
.build()
);
if (loadResponse.getStatus() != 0 && loadResponse.getStatus() != 65535) {
throw new RuntimeException("加载 collection 失败: " + loadResponse.getMessage());
}
// 生成唯一 ID(使用 _source + 分片索引)
String source = (String) metadata.get("_source");
String id = UUID.nameUUIDFromBytes((source + "_" + chunkIndex).getBytes()).toString();
// 构建字段数据
List<InsertParam.Field> fields = new ArrayList<>();
// ID 字段
fields.add(new InsertParam.Field("id", Collections.singletonList(id)));
// content 字段
fields.add(new InsertParam.Field("content", Collections.singletonList(content)));
// vector 字段
fields.add(new InsertParam.Field("vector", Collections.singletonList(vector)));
// metadata 字段(JSON 对象)
com.google.gson.Gson gson = new com.google.gson.Gson();
com.google.gson.JsonObject metadataJson = gson.toJsonTree(metadata).getAsJsonObject();
fields.add(new InsertParam.Field("metadata", Collections.singletonList(metadataJson)));
// 构建插入参数
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(MilvusConstants.MILVUS_COLLECTION_NAME)
.withFields(fields)
.build();
// 执行插入
R<MutationResult> insertResponse = milvusClient.insert(insertParam);
if (insertResponse.getStatus() != 0) {
throw new RuntimeException("插入向量失败: " + insertResponse.getMessage());
}
logger.debug("向量插入成功: id={}, source={}, chunk={}", id, source, chunkIndex);
} catch (Exception e) {
logger.error("插入向量到 Milvus 失败", e);
throw e;
}
}3. 在线推理
3.1 意图识别+前置预处理
作为用户请求的 "第一道闸门",从源头过滤无效请求,同时把用户的问题优化成适合检索的标准格式,避免后续环节做无用功
意图识别
用户的问题千奇百怪(例如闲聊"你是谁"、"今天天气怎么样")。在线推理的第一步,是利用轻量级分类器或关键词规则进行语义路由:
-
如果是闲聊或通用常识,直接路由给基座 LLM,不触发 RAG 检索。
-
如果涉及敏感词或违规提问,直接触发安全护栏(Guardrails)拦截并返回标准拒绝语。
-
只有当判断问题属于私有知识库领域时,才放行进入下一步。
前置预处理
对用户的原始 Query 做标准化处理,解决口语化、噪声、歧义问题,本质是一个 Query Rewrite 的环节
本质:在最初阶段优化用户的原始查询,以实现:少漏召、少误召、意图匹配更准,从源头提升检索和问答的整体质量。
Query Rewrite 策略
1. 直接改写
- 基础清洗:去除无效空格、特殊符号、错别字修正(如 "登陆"→"登录")、敏感信息脱敏
- 口语化转标准:如 "咋弄啊"→"如何进行 XX 操作?",精简冗余表述,保留核心意图
- 指代消解:补充用户省略的上下文,如用户问 "它的参数是多少?",结合对话历史补全为 "XX 功能的参数是多少?"
Prompt 模版
SYSTEM: 你是一个 RAG 检索优化器。请分析多轮对话历史和当前用户问题,消除指代不明(如它、那个、该配置),补全省略主语,弃口语化表达,输出一个最适合知识库检索的标准陈述化问题。
---
对话历史: {chat_history}
用户当前问题: {user_query}
---
要求:仅输出改写后的标准检索词,不做任何解释。**不足:**我们在之前已经了解到,检索过程实际做的事语义匹配,因此问题与文档还有一个天然语义鸿沟,问题是疑问句,文档是陈述句,这两类文本在向量维度天生有距离,因此引入了下面的策略 HyDE
2. 假设文档嵌入 HyDE (Hypothetical Document Embedding)
核心思想:用 LLM 把短查询 "脑补" 成一篇完整回答(假文档),再用这篇假文档的向量去匹配真实文档------ 假文档与真实文档长度、风格、语义密度一致,向量空间更接近。
Prompt 模版
根据用户提出的问题,凭你的常识生成一段可能的答案段落。
注意:不要求事实完全准确,只需模拟专业技术文档/知识库的陈述叙述风格,用于辅助后续的 RAG 语义检索。
用户提问: {user_query}
输出要求:仅输出生成的模拟答案段落,不做任何解释。存在问题:还存在一种情况,当用户的提出的问题过于具体,具体到这一块的内容确实在知识库里没有针对这一部分的知识,但是有与之相关的背景知识的补充,这种情况改写会失效,因此引入了Step-back Prompting 后退提问
3. Step-back Prompting 后退提问
Step-Back Prompting 由 Zheng 等人于 2023 年在论文《Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models》中正式提出,是一种基于抽象思维的提示工程技术,专门解决 LLM 在复杂推理中 "只见树木不见森林" 的问题。
它的灵感来自人类解决难题的方式:当遇到复杂问题时,我们会先退一步思考核心原理,再用这些原理指导具体解题步骤。
Prompt 模版
# Step 1: 后退思考
请先思考这个问题背后的核心原理/基本概念/通用原则是什么?
具体问题:[你的原始问题]
后退问题:[引导模型生成的抽象问题]
请先回答后退问题:
# Step 2: 基于原理解决问题
现在,请基于你对上述核心原理的理解,详细解答原始问题:
[你的原始问题]举例:
具体问题:线上 SpringBoot 应用频繁 Full GC,老年代回收后内存占用依然很高,该怎么排查?
后退问题:请先说明 JVM 老年代的核心作用、Full GC 的触发条件,以及老年代内存无法释放的根本原理是什么?
4. 多Query扩展
核心思想:用 AI 帮你 "换位思考",生成多个可能的查询方式,覆盖更多检索维度,避免 "一叶障目"。
基本的流程: 原始查询 → 生成变体 → 并行检索 → 结果融合
a. 输入原始查询
用户提出核心问题,如:"如何排查 JVM 频繁 Full GC 且老年代内存不释放?"(这是我们之前 JVM 示例的问题)
b. LLM 生成查询变体(关键步骤)
LLM 分析核心意图,生成 3-5 个不同角度的查询,例如:
- 变体 1:"JVM 老年代内存无法释放的排查方法"(聚焦内存释放问题)
- 变体 2:"SpringBoot 应用频繁 Full GC 原因及解决方案"(结合应用场景)
- 变体 3:"JVM 内存泄漏如何通过堆 dump 分析?"(聚焦工具使用)
- 变体 4:"JVM GC Roots 引用链分析步骤"(深入底层原理)
c. 并行检索
所有查询变体同时在知识库 / 向量库中检索,获取各自的相关文档集合。
d. 结果融合(去重 + 排序)
常用 RRF(Reciprocal Rank Fusion,倒数排名融合)算法:
大概思路是
- 对每个文档计算所有查询结果中的排名倒数和
- 按总分排序,去重后返回 Top-N 结果
3.2 Query 向量化
把预处理后的用户 Query,转换成和离线知识库同空间的向量,是语义检索的 "基础介质"。
**注意:**调用统一 Embedding 模型,必须使用和离线环节分块时完全一致的模型(含版本、tokenizer、参数),否则向量空间不匹配,检索会彻底失效。
3.3 语义检索
快速召回和用户 Query 语义最相关的一批候选文档块,是 RAG 检索阶段的 "粗召回" 环节.
用 Query 向量在向量库中做相似度检索,召回Top-K个结果(K 一般设为 10~30,平衡召回率和后续环节压力)
在实际的企业工程开发中,经常会在这一步采取 多路召回的策略
多路召回
顾名思义,多路召回即采用不同多种的检索方式,召回内容然后进行合并排序
单一检索存在天生缺陷,工业级必须采用「向量语义检索 + 关键词精准检索」的多路召回架构,通过互补规避短板:
- 纯向量检索:擅长语义模糊匹配,比如用户问 "如何扩容节点",可以召回 "节点垂直扩容""集群水平扩容" 等相关文档,但对专有名词、数字、编号的召回效果差,无法精准匹配技术文档中的 API 接口、错误码、专属配置项;
- 关键词检索(BM25 算法):擅长精准匹配,比如用户输入 "API 接口返回错误码 403",可以精准召回包含该字符串的文档,但对语义理解能力弱,无法识别同义词、转述表述;
- 多路召回融合:结合两者优势,用 Reciprocal Rank Fusion(RRF)算法合并两类检索结果,同时兼顾准召率。
java
import io.milvus.param.R;
import io.milvus.param.dml.HybridSearchParam;
import io.milvus.param.dml.AnnSearchParam;
import io.milvus.param.dml.ranker.RRFRanker;
import io.milvus.response.SearchResultsWrapper;
import io.milvus.grpc.SearchResults;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public List<SearchResult> searchSimilarDocuments(String query, int topK) {
try {
logger.info("开始多路召回搜索 (稠密向量 + BM25全文检索), 查询: {}, topK: {}", query, topK);
// 1. 准备第一路:稠密向量检索 (Dense Search)
List<Float> queryVector = embeddingService.generateQueryVector(query);
logger.debug("稠密查询向量生成成功, 维度: {}", queryVector.size());
AnnSearchParam denseSearchParam = AnnSearchParam.newBuilder()
.withVectorFieldName("vector") // 稠密向量字段名
.withVectors(Collections.singletonList(queryVector))
.withMetricType(io.milvus.param.MetricType.L2) // 向量相似度度量
.withTopK(topK)
.withParams("{\"nprobe\":10}")
.build();
// 2. 准备第二路:BM25 全文检索 (Sparse Search)
// Milvus 2.5+ 支持直接传入原始文本查询,内部通过 BM25 函数处理
AnnSearchParam bm25SearchParam = AnnSearchParam.newBuilder()
.withVectorFieldName("sparse_vector") // 存储 BM25 稀疏向量的字段名
.withVectors(Collections.singletonList(query)) // 直接传入原始文本 Query
.withMetricType(io.milvus.param.MetricType.BM25) // 指定度量类型为 BM25
.withTopK(topK)
.build();
// 3. 构建多路召回核心参数 (HybridSearchParam) 与 RRF 重排器
// RRF (Reciprocal Rank Fusion) 算法通过排名来融合多路结果,不需要归一化不同路的分数
// k=60 是 RRF 的标准常数
RRFRanker rrfRanker = RRFRanker.newBuilder()
.withK(60)
.build();
HybridSearchParam hybridSearchParam = HybridSearchParam.newBuilder()
.withCollectionName(MilvusConstants.MILVUS_COLLECTION_NAME)
.addSearchParam(denseSearchParam) // 压入第一路:向量语义
.addSearchParam(bm25SearchParam) // 压入第二路:文本关键词(BM25)
.withRanker(rrfRanker) // 设置服务端 RRF 融合重排
.withTopK(topK) // 融合后最终保留的 TopK 条数
.withOutFields(List.of("id", "content", "metadata"))
.build();
// 4. 执行混合搜索
R<SearchResults> searchResponse = milvusClient.hybridSearch(hybridSearchParam);
if (searchResponse.getStatus() != 0) {
throw new RuntimeException("Milvus多路混合检索失败: " + searchResponse.getMessage());
}
// 5. 解析混合搜索结果
SearchResultsWrapper wrapper = new SearchResultsWrapper(searchResponse.getData().getResults());
List<SearchResult> results = new ArrayList<>();
for (int i = 0; i < wrapper.getRowRecords(0).size(); i++) {
SearchResult result = new SearchResult();
result.setId((String) wrapper.getIDScore(0).get(i).get("id"));
result.setContent((String) wrapper.getFieldData("content", 0).get(i));
// 注意:经由 RRF 重新算分后,分数越接近 1 代表综合两路后的相关性越高(与原 L2 的越小越好相反)
result.setScore(wrapper.getIDScore(0).get(i).getScore());
// 解析 metadata
Object metadataObj = wrapper.getFieldData("metadata", 0).get(i);
if (metadataObj != null) {
result.setMetadata(metadataObj.toString());
}
results.add(result);
}
logger.info("多路召回搜索完成, 服务端融合后返回 {} 个最优文档", results.size());
return results;
} catch (Exception e) {
logger.error("多路召回相似文档失败", e);
throw new RuntimeException("搜索失败: " + e.getMessage(), e);
}
}BM25
BM25 全称 Okapi BM25(Best Matching 25),是经典概率式词袋检索模型,诞生于传统信息检索领域,也是目前工业界关键词检索的事实标准。
核心能力:基于关键词词频、文档频率、文档长度计算「查询语句」与「文档」的相关性分数,分数越高代表匹配度越强
核心特性:不理解语序、不理解上下文、不理解深层语义,只统计词汇出现规律(纯词袋模型)
为什么 BM25 会取代 TF-IDF?
在关键词检索(Sparse Retrieval)路径中,Okapi BM25 是目前工业界的事实标准(也是 Elasticsearch 底层的默认相关性算法)。它是对传统 TF-IDF 的一次革命性升级:
-
TF(词频)的饱和压制:在 TF-IDF 中,某个词在文档中出现的次数越多,权重就呈线性无限飙升。这就导致某些恶意堆砌关键词的"灌水长文档"排名靠前。BM25 引入了参数 k_1(通常设为 1.2~2.0),对词频做饱和曲线压制。当一个词出现的次数超过一定阈值后,再增加次数,相关性得分也几乎不再增长。
-
文档长度归一化(Document Length Normalization):长文档由于词汇量大,天然容易匹配到关键词。BM25 引入了参数 b(通常设为 0.75),动态惩罚那些又长又臭的文档。如果一篇文章很短且精准命中了冷门关键词,它的得分会远高于一篇包含大量废话的长文档。
BM25 的核心优化方向:
-
对 TF 做饱和压制:词频增长到一定程度后,不再额外加分;
-
引入文档长度归一化因子:动态抵消文档长短带来的偏差;
-
基于概率模型重新拟合相关性,整体打分更符合人类检索直觉。
RRF
RRF 全称 Reciprocal Rank Fusion(倒数排名融合),是 Cormack 等人在 2009 年提出的多排序列表融合算法,现已成为工业界混合检索(Hybrid Search)的事实标准。
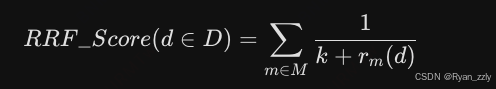
核心能力:仅基于文档在多个检索列表中的排名,计算综合相关性得分,无需关注原始检索分数的量级与分布;
3.4 重排 Rerank
粗召回环节需要兼顾速度,无法做到精准排序,重排是用少量计算成本大幅提升结果相关性的性价比最优手段。
粗召回用 Bi-Encoder:独立编码 Query 和文档,速度快但交互语义理解弱;
重排用 Cross-Encoder:将 Query 与候选文档块拼接成一对,同时输入模型进行交互语义计算,输出两者的相关性得分(一般是 0~1 分),虽然计算量更大、延迟更高,但排序精度比 Bi-Encoder 提升 15%~25%,足以抵消延迟增加的成本。用重排模型精选出最终的 Top-5 文档,是克服大模型"Lost in the Middle(长文本中间信息丢失)"缺陷的核心胜负手。
java
/**
* 对多路召回后的结果进行深度语义重排
* @param query 原始用户问题
* @param candidateResults 多路召回(Hybrid Search)返回的候选集
* @param finalTopK 最终喂给大模型的内容数量 (通常比多路召回的 topK 小,例如粗筛取 15-20,精筛 Rerank 取 3-5)
* @return 经由重排模型打分、重新降序排序、且截断后的高质量结果
*/
public List<SearchResult> rerankDocuments(String query, List<SearchResult> candidateResults, int finalTopK) {
if (candidateResults == null || candidateResults.isEmpty()) {
return Collections.emptyList();
}
try {
logger.info("开始执行深度语义重排, 候选文档数: {}, 最终保留 topK: {}", candidateResults.size(), finalTopK);
// 1. 提取候选文档的纯文本内容,保持索引顺序一致
List<String> documentsText = candidateResults.stream()
.map(SearchResult::getContent)
.collect(Collectors.toList());
// 2. 组装请求 Payload (标准的 Rerank API 协议)
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", "gte-rerank"); // 或 bge-reranker-large 等生产模型
requestBody.put("query", query);
requestBody.put("documents", documentsText);
requestBody.put("top_n", finalTopK); // 让算法侧直接返回前 N 个
// 3. 设置请求头
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.set("Authorization", "Bearer " + apiKey);
HttpEntity<Map<String, Object>> entity = new HttpEntity<>(requestBody, headers);
// 4. 发起同步 RPC 调用
ResponseEntity<RerankApiResponse> responseEntity = restTemplate.postForEntity(rerankUrl, entity, RerankApiResponse.class);
if (!responseEntity.getStatusCode().is2xxSuccessful() || responseEntity.getBody() == null) {
logger.warn("Rerank API 调用失败,状态码: {}, 触发降级机制:直接返回粗筛结果", responseEntity.getStatusCode());
return candidateResults.stream().limit(finalTopK).collect(Collectors.toList());
}
// 5. 解析重排打分结果并映射回原 SearchResult
RerankApiResponse response = responseEntity.getBody();
List<SearchResult> rerankedResults = new ArrayList<>();
if (response.getOutput() != null && response.getOutput().getResults() != null) {
for (RerankResultItem item : response.getOutput().getResults()) {
// item.getIndex() 代表当前这一条精筛结果对应原 candidateResults 列表中的哪个下标
int originalIndex = item.getIndex();
if (originalIndex >= 0 && originalIndex < candidateResults.size()) {
SearchResult originalDoc = candidateResults.get(originalIndex);
// 组装全新的精筛结果
SearchResult finalResult = new SearchResult();
finalResult.setId(originalDoc.getId());
finalResult.setContent(originalDoc.getContent());
finalResult.setMetadata(originalDoc.getMetadata());
// 覆盖分数为重排模型的绝对置信度得分 (通常在 0~1 之间,越大越相关)
finalResult.setScore((double) item.getRelevanceScore());
rerankedResults.add(finalResult);
}
}
}
logger.info("重排阶段完美结束,最终筛选出 {} 条绝对高价值文档输入给 LLM", rerankedResults.size());
return rerankedResults;
} catch (Exception e) {
logger.error("重排服务遭遇致命异常, 触发安全降级", e);
// 生产防御性编程:如果重排网络抖动或超限,绝不能让 RAG 挂掉,降级直接返回粗筛前 finalTopK 条
return candidateResults.stream().limit(finalTopK).collect(Collectors.toList());
}
}3.5 上下文拼接
核心做到以下几点
1. 结构化组织上下文
利用明确、不易被污染的分隔符(如 XML 标签)划分系统指令、参考文档、用户 Query,防止大模型发生提示词注入或语意混淆。
2. "考点"动态排序
按照重排相关性得分从高到低的顺序进行拼接。最相关的文档放在最前面(或最后面) ,契合大模型的"首因效应"与"近因效应"。每块文档必须强制附带溯源元数据(如 [来源: 2025年Q4财报.md | 内部ID: 1024]),供前端渲染"查看出处",实现确定性追溯。
3.Token 精准校验
线上拼接 Prompt 时,绝不能用传统的字符串 length() 估算长度。
-
避坑落地 :必须使用大模型官方对应的分词工具(如 OpenAI 体系的 TikToken ,开源体系的 HuggingFace Transformers Tokenizer)线上精准计算总 Token 长度。
-
防爆机制:为大模型的最大上下文窗口预留 15%~20% 的"余量预算"(给大模型生成答案留足空间)。一旦 TikToken 检测到当前拼接的文本即将爆仓,立即从相关性最低的尾部文档块开始进行动态拦截或截断剔除。
java
@Service
public class PromptSynthesisService {
private static final Logger logger = LoggerFactory.getLogger(PromptSynthesisService.class);
/**
* 将精排后的文档与用户原始问题拼接,生成最终可直接用于大模型演练的 Prompt 对象
*
* @param query 用户原始提问
* @param rerankedResults 重排(Rerank)后留下的最高质量知识分块
* @return 完美的、带有明确隔离边界的 Spring AI Prompt 对象
*/
public Prompt buildCombinedPrompt(String query, List<SearchResult> rerankedResults) {
logger.info("开始拼接 RAG 上下文,当前参考素材数量: {}", rerankedResults.size());
// 1. 格式化拼接上下文文本 (Context Processing)
// 生产实践中,建议为每个 Chunk 带上清晰的编号与边界标识(如 <doc_x>),防止大模型产生幻觉或被文档内容带偏
StringBuilder contextBuilder = new StringBuilder();
for (int i = 0; i < rerankedResults.size(); i++) {
SearchResult doc = rerankedResults.get(i);
contextBuilder.append(String.format("【文献资料 %d】:\n", i + 1));
contextBuilder.append(doc.getContent().trim());
contextBuilder.append("\n----------------------------------------\n");
}
String finalContextString = contextBuilder.toString();
logger.debug("上下文拼接完成,总字符长度: {}", finalContextString.length());
// 2. 编写严格的 System Prompt 设定 AI 行为准则(防幻觉的关键)
String systemPromptText = """
你是一个专业、严谨的智能知识库助手。
请严格基于下面提供给你的 [参考资料] 来回答用户的问题。
行为守则:
1. 如果用户的问题在 [参考资料] 中找不到明确的答案,请直接回答:"抱歉,根据已知资料无法回答该问题。",严禁胡编乱造或凭借自身过往知识补充。
2. 回答时应当事实求是,保持中立客观,条理清晰。
3. 如果答案引用了某段资料,可以在句末标明引用的文献编号(例如:[文献资料 1])。
""";
// 3. 编写 User Prompt 模板,动态植入上下文与用户 Query
// {context} 和 {query} 是占位符,由 Spring AI 的 PromptTemplate 动态注入
String userPromptTemplateText = """
[参考资料]
{context}
[用户问题]
{query}
请基于上述参考资料,回答该问题:
""";
// 4. 利用 Spring AI 渲染用户消息
PromptTemplate userPromptTemplate = new PromptTemplate(userPromptTemplateText);
// 动态传递参数映射
Message userMessage = userPromptTemplate.createMessage(Map.of(
"context", finalContextString,
"query", query
));
// 5. 组合 System Message 和 User Message
Message systemMessage = new SystemMessage(systemPromptText);
// 组装成最终的多角色提示词对象(Multi-Message Prompt)
// 这样分角色传入是目前工业界大模型(如 GPT-4, DeepSeek)最推荐、最稳定的 Prompt 交互形态
Prompt finalPrompt = new Prompt(List.of(systemMessage, userMessage));
logger.info("最终 RAG Prompt 组装完毕,准备呼叫大模型。");
return finalPrompt;
}
}4. 评估RAG效果
当你按照前两节的架构,把离线的"父子双层存储"和线上的"多路召回+Rerank"全部撸出来之后,你一定会被业务方或者老板追问两个灵魂拷问:
-
"你做了这么多重构,系统的回答准确率到底提升了多少?"
-
"加了这么多改写和重排模型,线上接口的延迟(Latency)撑得住高并发吗?"
如果回答不上来,系统就永远只是个实验室里的玩具。第四节我们就来死磕 RAG 的量化评估 与高并发工程落地。
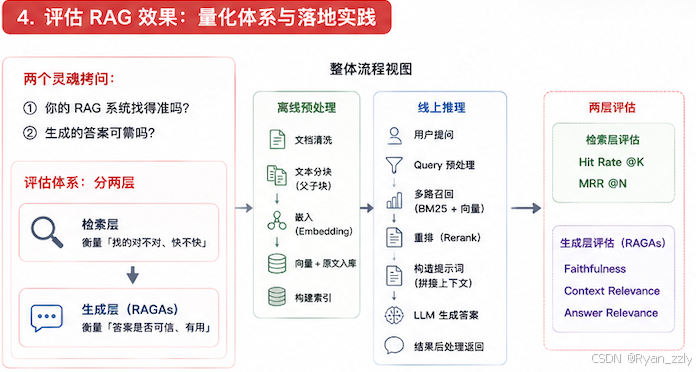
我们把整个评估过程拆成两层:检索层 和生成层
4.1 检索层评估
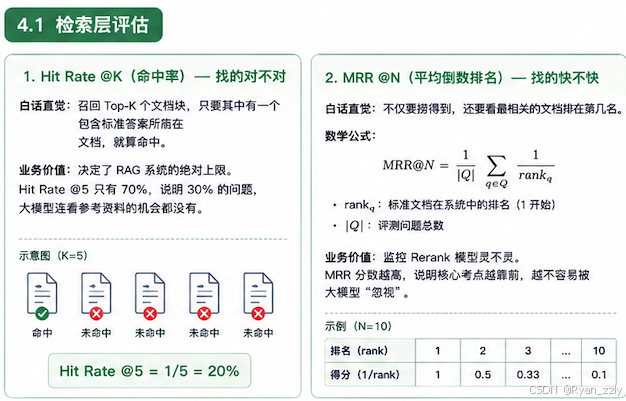
这一层主要关注两个指标
1. Hit Rate @K 命中率 --找的对不对
白话直觉 :我让系统召回 Top-K 个文档块,这 K 个块里只要有一个包含了标准答案所在的文档,就算命中。
业务价值:Hit Rate 决定了 RAG 系统的绝对上限。如果 Hit Rate @5 只有 70%,说明有 30% 的用户提问,大模型连看参考资料的机会都没有。如果这个指标低,说明你的离线数据清洗、父子块切分(Chunking)或者多路召回(BM25 权重)出了大问题。
2. MRR @N (Mean Reciprocal Rank,平均倒数排名) --找的快不快
考核 Rerank 的核心靶向
白话直觉 :不仅要捞得到,还要看最相关的文档排在第几名。
数学公式:
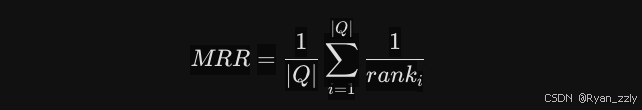
如果标准文档在系统里排第1名,得分就是 1;排在第2名,得分就是 0.5;排在第十名,得分就是 0.1 。
业务价值 :大模型有严重的"Lost in the Middle"缺陷(只爱看上下文的开头和结尾)。MRR 就是用来监控 Rerank 模型 灵不灵的。MRR 分数越高,说明重排模型越成功地把"核心考点"顶到了大模型的眼皮子底下。
4.2 生成层评估 RAGAs
评估 RAG 绝对不能靠人工抽样瞎猜,目前工业界公认的黄金标准是基于 RAGAs(RAG Assessment) 的 "LLM-as-a-Judge(大模型作为裁判)" 自动化评估框架。
RAGAS 的核心思想是不需要昂贵的真实标准答案(Ground Truth),而是紧扣 用户提问(Query) 、检索出的上下文(Context) 、模型生成的回答(Answer) 这三者组成的核心三元组,拆解出三大硬性量化指标:
1. 忠实度(Faithfulness)------ 拦截"参数化幻觉"
定义 :检查 LLM 生成的 Answer 中,到底有百分之多少的内容完全源自检索出来的 Context。
痛点:有时候大模型很聪明,会用自己原本语料库里的常识去回答问题,但企业知识库要的是"依据本地文档回答"。如果模型瞎编或者动用了外来知识,Faithfulness 分数就会暴跌。
计算逻辑:让裁判大模型将 Answer 拆解为多个原子断言,逐一去 Context 中核对是否能推导出来。得分在 0~1 之间,生产环境一般要求 > 0.95。
对策:
- 【Prompt 强约束与思维阻断】 :在 System Prompt 中加入极端强烈的结构化人设约束。例如:"你是一个严格的文档阅读助手。请仅根据给定的
<context>标签内的内容回答问题。如果内容中没有提及,请直接回答'知识库未收录该内容',绝对不允许动用你自身的常识或进行任何逻辑外推。" - 【降低模型温度(Temperature)】 :直接将 LLM 的推理温度 Temperature 压低至
0.0或0.1。高温度会鼓励模型的创造力和发散性,而 RAG 生产环境需要的是绝对的严谨与确定性。 - 【负样本微调(Negative Sample FT)】 :如果改 Prompt 依然压不住某些长文本大模型的"倾诉欲",需要针对性地构建一批
[无答案Context + 问题 $\rightarrow$ 拒绝回答]的微调数据集,对基座模型进行微调,强行固化模型的"认错"本能。
2. 检索相关性(Context Relevance)------ 榨干"召回纯度"
定义 :评估召回出来的 Context 里面,到底有多少是真正有用的干货,有多少是废话(噪声)这一部分包括 Context Precision 精确率 和 Context Recall 召回率。
痛点 :如果你线上为了保险,一口气召回了 20 个 Chunk 丢给 LLM,虽然包含答案的概率变高了,但噪声也变大了,Context Relevance 得分就会降低。这个指标能倒逼你在线上调优 BM25 与向量检索的融合比例(RRF 参数)。
对策:
A. 如果 Context Precision(精确率)过低(废话太多):
-
工业级对策(调优药方):
-
【Rerank 动态阈值截断(Threshold Filtering)】:多路召回可能捞上来了 20 个块,但重排模型(Reranker)打分后,不要一股脑全喂给大模型。必须在线上设置一个硬性置信度阈值(如 Score \> 0.6),低于这个分数的块直接动态剔除,精简上下文。
-
【优化分块(Chunking)粒度】 :说明你的 Chunk 切得太大了(比如 1024 Tokens 里只有 50 Tokens 是有用的)。引入父子块(Parent-Child)架构,将用于检索的子块缩小到 128~256 Tokens,提升向量的几何聚焦度。
-
B. 如果 Context Recall(召回率)过低(漏掉要点):
-
工业级对策(调优药方):
-
【微调 Embedding / 扩充多路召回】 :说明纯向量检索发生了严重的语义漏召。此时必须加大 BM25 关键词检索的权重 ,或者引入多 Query 扩展(Query Expansion),换 4 个不同的角度去并发捞数据,扩大网眼。
-
【长文本延迟切割(Late Chunking)】:检查是否因为在离线切块时切断了代词(如"它"、"该配置"),导致关键信息没有被赋予正确的全局向量,从而被检索漏掉。改用先编码后切分的 Late Chunking 方案。
-
3. 答案相关性(Answer Relevance)------ 拒绝"答非所问"
定义:评估生成的 Answer 与用户的原始 Query 是否契合。
痛点:有时候检索很准,模型也没有胡说八道(忠实度很高),但由于 Prompt 没有调好,模型"绕圈子"或者漏掉了用户提问里的核心诉求。
落地实践:通过计算生成答案与原始提问在 Embedding 空间中的语义相似度来量化。
对策:
- 【优化输出格式与思维链(CoT)触发】 :说明提示词(Prompt)在引导模型组织语言时失控了。在 Prompt 中明确规定输出结构。例如要求模型使用 "总-分-总" 结构,或者引入 Few-Shot(少样本提示),给大模型喂 2-3 个标准的"好回答样本",约束其拟合标准业务风格。
- 【Query 预处理中的意图对齐】 :有时候是因为用户的提问本身就是反问句或复合复杂句,LLM 在拼接时被搞晕了。必须回溯到 3.1 节的 Query Rewrite 阶段,确保消除了用户的口语化和指代歧义后,再把干净利落的 Query 连同 Context 复合提交。
如果你想造一艘船,不要抓人来收集木头,也不要指派任务和发号施令。相反,你要教会他们向往渴望那辽阔、无垠的大海 ------圣埃克苏佩里