摘要
VGGT(Visual Geometry Grounded Transformer)是Meta Research提出的1.2B参数前馈Transformer,能在1秒内从1~100+张图像中同时推断相机参数、点云图、深度图和3D点轨迹。通过Alternating Attention机制(帧内与全局自注意力交替)替代传统Cross-Attention,在相机估计、多视图深度、稠密重建和3D跟踪四项任务上均达到SOTA,且无需迭代优化。论文发表于CVPR 2025。
一、问题背景
传统3D重建管线(SfM/MVS)依赖多阶段流水线:特征匹配 → \rightarrow → 相机标定 → \rightarrow → 稠密重建 → \rightarrow → 后处理。每个阶段独立优化,误差层层累积。近期DUSt3R/MASt3R等方法虽用神经网络替代部分模块,但仍需后端全局对齐(BA),且无法同时输出跟踪信息。
VGGT的核心动机:能否用一个前馈网络,一次性输出所有3D几何属性?
关键挑战:
- 相机位姿需要全局一致性(跨帧信息)
- 深度/点云需要局部精细度(帧内信息)
- 3D跟踪需要时序对应关系
- 这三类输出的supervision信号来源不同,联合训练可能冲突
二、核心方法
2.1 整体框架
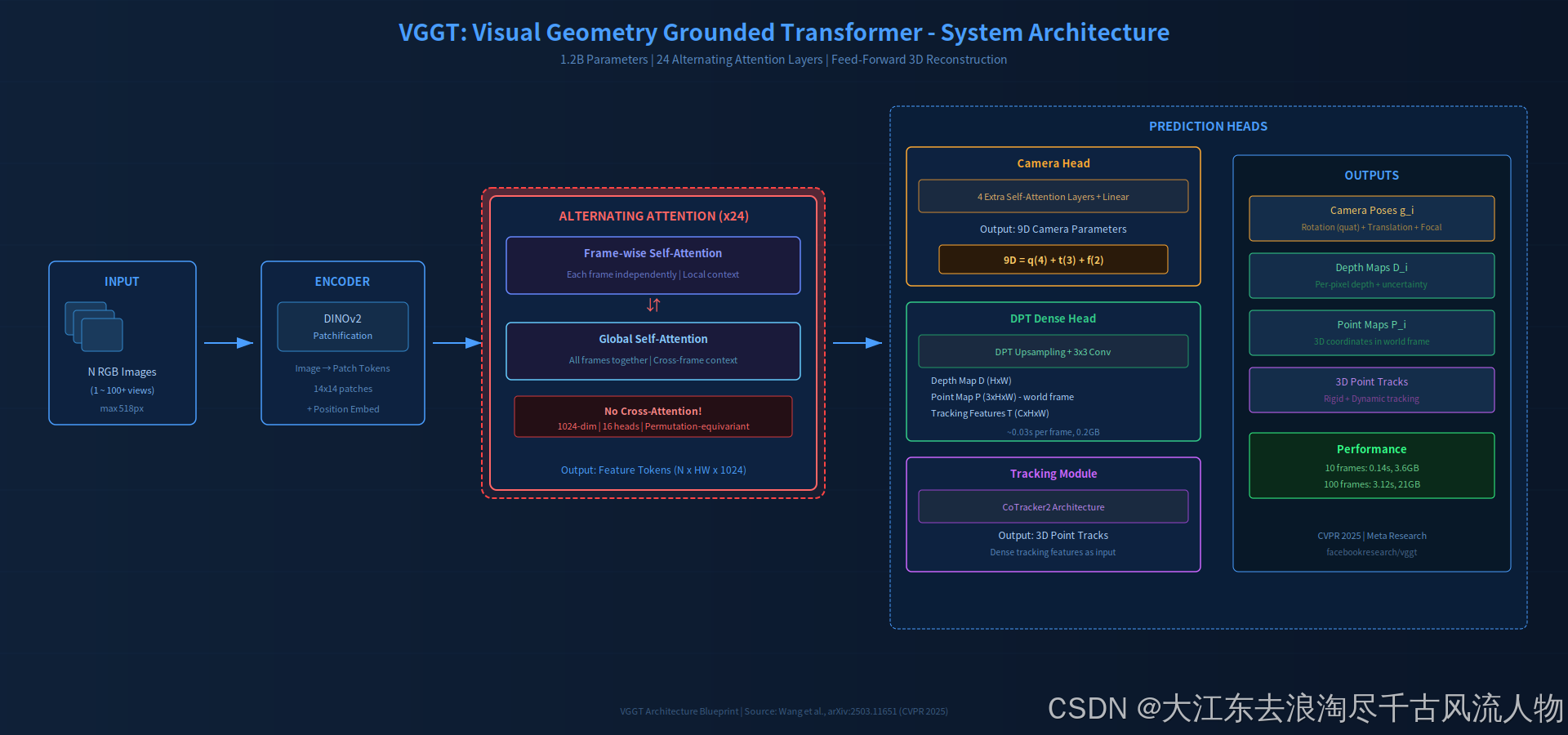
图 1:VGGT系统架构。重点看中间的Alternating Attention模块(红色高亮)------帧内与全局自注意力交替24层,不使用Cross-Attention。来源:重绘自 design skill
输入N张RGB图像,经DINOv2 Patchification编码为token序列后,送入24层Alternating Attention Block提取特征,最终由三个并行预测头分别输出相机参数、稠密几何和3D轨迹。
#mermaid-svg-xDf141ILFEEVvtCZ{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-xDf141ILFEEVvtCZ .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-xDf141ILFEEVvtCZ .error-icon{fill:#552222;}#mermaid-svg-xDf141ILFEEVvtCZ .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-xDf141ILFEEVvtCZ .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-xDf141ILFEEVvtCZ .marker{fill:#333333;stroke:#333333;}#mermaid-svg-xDf141ILFEEVvtCZ .marker.cross{stroke:#333333;}#mermaid-svg-xDf141ILFEEVvtCZ svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-xDf141ILFEEVvtCZ p{margin:0;}#mermaid-svg-xDf141ILFEEVvtCZ .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-xDf141ILFEEVvtCZ .cluster-label text{fill:#333;}#mermaid-svg-xDf141ILFEEVvtCZ .cluster-label span{color:#333;}#mermaid-svg-xDf141ILFEEVvtCZ .cluster-label span p{background-color:transparent;}#mermaid-svg-xDf141ILFEEVvtCZ .label text,#mermaid-svg-xDf141ILFEEVvtCZ span{fill:#333;color:#333;}#mermaid-svg-xDf141ILFEEVvtCZ .node rect,#mermaid-svg-xDf141ILFEEVvtCZ .node circle,#mermaid-svg-xDf141ILFEEVvtCZ .node ellipse,#mermaid-svg-xDf141ILFEEVvtCZ .node polygon,#mermaid-svg-xDf141ILFEEVvtCZ .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-xDf141ILFEEVvtCZ .rough-node .label text,#mermaid-svg-xDf141ILFEEVvtCZ .node .label text,#mermaid-svg-xDf141ILFEEVvtCZ .image-shape .label,#mermaid-svg-xDf141ILFEEVvtCZ .icon-shape .label{text-anchor:middle;}#mermaid-svg-xDf141ILFEEVvtCZ .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-xDf141ILFEEVvtCZ .rough-node .label,#mermaid-svg-xDf141ILFEEVvtCZ .node .label,#mermaid-svg-xDf141ILFEEVvtCZ .image-shape .label,#mermaid-svg-xDf141ILFEEVvtCZ .icon-shape .label{text-align:center;}#mermaid-svg-xDf141ILFEEVvtCZ .node.clickable{cursor:pointer;}#mermaid-svg-xDf141ILFEEVvtCZ .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-xDf141ILFEEVvtCZ .arrowheadPath{fill:#333333;}#mermaid-svg-xDf141ILFEEVvtCZ .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-xDf141ILFEEVvtCZ .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-xDf141ILFEEVvtCZ .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-xDf141ILFEEVvtCZ .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-xDf141ILFEEVvtCZ .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-xDf141ILFEEVvtCZ .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-xDf141ILFEEVvtCZ .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-xDf141ILFEEVvtCZ .cluster text{fill:#333;}#mermaid-svg-xDf141ILFEEVvtCZ .cluster span{color:#333;}#mermaid-svg-xDf141ILFEEVvtCZ div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-xDf141ILFEEVvtCZ .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-xDf141ILFEEVvtCZ rect.text{fill:none;stroke-width:0;}#mermaid-svg-xDf141ILFEEVvtCZ .icon-shape,#mermaid-svg-xDf141ILFEEVvtCZ .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-xDf141ILFEEVvtCZ .icon-shape p,#mermaid-svg-xDf141ILFEEVvtCZ .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-xDf141ILFEEVvtCZ .icon-shape .label rect,#mermaid-svg-xDf141ILFEEVvtCZ .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-xDf141ILFEEVvtCZ .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-xDf141ILFEEVvtCZ .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-xDf141ILFEEVvtCZ :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} N RGB Images
DINOv2 Patchify
24x AA Blocks
Camera Head
DPT Dense Head
Tracking Module
9D Pose
Depth + Points
3D Tracks
2.2 Alternating Attention(AA)机制
AA是VGGT区别于DUSt3R系列的核心设计。每一层交替执行:
- Frame-wise Self-Attention:每帧token独立做自注意力,建立帧内空间关系
- Global Self-Attention:所有帧的token拼在一起做自注意力,建立跨帧对应关系
Layer 2 k : X = SA frame ( X ) (帧内) \text{Layer}{2k}: \quad \mathbf{X} = \text{SA}{\text{frame}}(\mathbf{X}) \quad \text{(帧内)} Layer2k:X=SAframe(X)(帧内)
Layer 2 k + 1 : X = SA global ( X ) (全局) \text{Layer}{2k+1}: \quad \mathbf{X} = \text{SA}{\text{global}}(\mathbf{X}) \quad \text{(全局)} Layer2k+1:X=SAglobal(X)(全局)
网络配置:1024维特征、16个注意力头、24层。
为什么不用Cross-Attention? 消融实验(ETH3D Overall Error):
- Alternating Attention: 0.709
- Global SA only: 0.827
- Cross-Attention: 1.061
AA的优势在于:帧内层维护局部精度(深度细节),全局层建立对应关系(相机一致性),两者交替互补。Cross-Attention则在帧对过多时计算量爆炸,且缺乏帧内自身结构建模。
2.3 预测头设计
Camera Head:在AA输出上追加4层自注意力 + 线性层,输出9D参数:
g i = q i ∈ R 4 , t i ∈ R 3 , f i ∈ R 2 \mathbf{g}_i = \left\\mathbf{q}_i \\in \\mathbb{R}\^4,\\; \\mathbf{t}_i \\in \\mathbb{R}\^3,\\; \\mathbf{f}_i \\in \\mathbb{R}\^2\\right gi=qi∈R4,ti∈R3,fi∈R2
其中 q \mathbf{q} q 为四元数旋转、 t \mathbf{t} t 为平移、 f \mathbf{f} f 为2D焦距。第一帧强制为单位变换(世界坐标系参考)。
DPT Dense Head :DPT上采样将patch-level token恢复到像素级分辨率,3x3卷积输出深度图 D i D_i Di、点云图 P i ∈ R 3 × H × W P_i \in \mathbb{R}^{3 \times H \times W} Pi∈R3×H×W(世界坐标系)、跟踪特征 T i T_i Ti。
Tracking Module :基于CoTracker2架构,以跟踪特征 T i T_i Ti 为输入,预测稠密3D点轨迹。
2.4 多任务联合训练
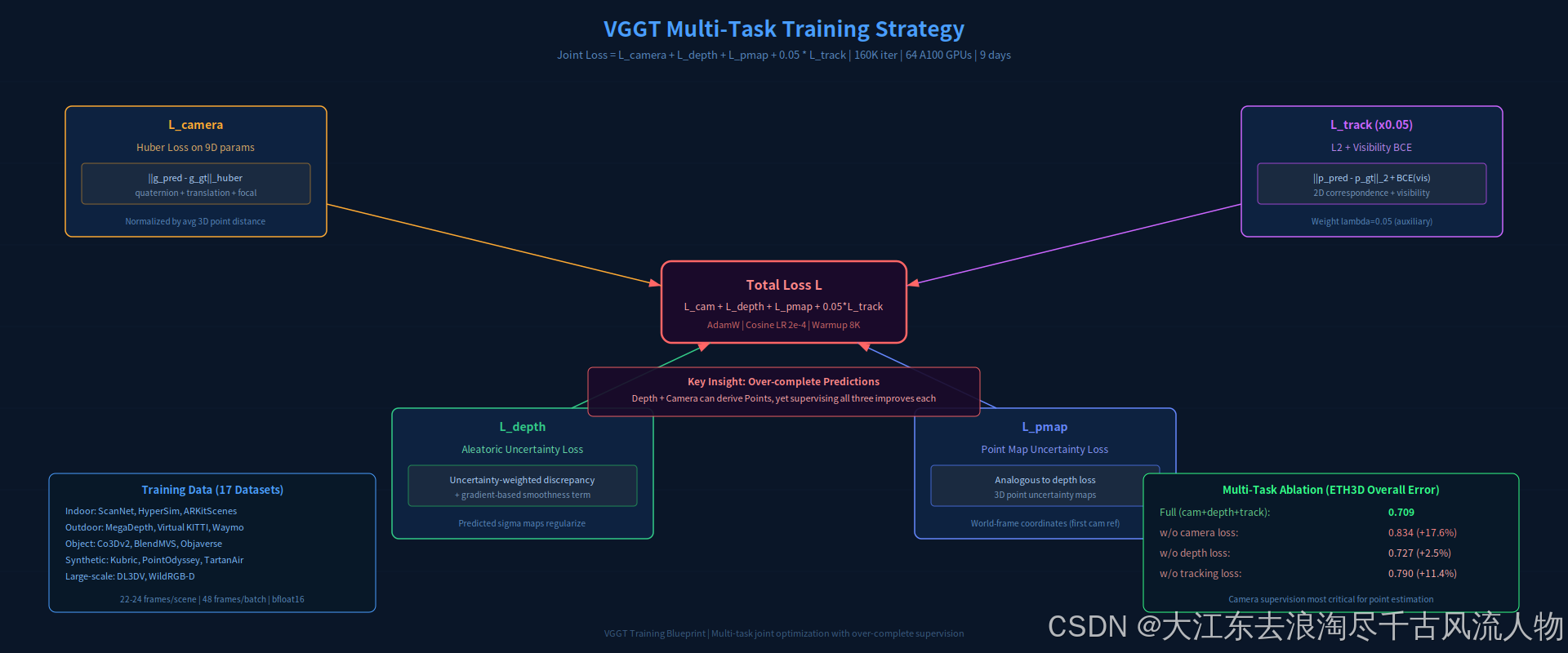
图 2:多任务训练策略。重点看消融结果------camera loss对点云估计贡献最大(去掉后error从0.709升到0.834)。来源:重绘自 design skill
总Loss:
L = L camera + L depth + L pmap + 0.05 ⋅ L track \mathcal{L} = \mathcal{L}{\text{camera}} + \mathcal{L}{\text{depth}} + \mathcal{L}{\text{pmap}} + 0.05 \cdot \mathcal{L}{\text{track}} L=Lcamera+Ldepth+Lpmap+0.05⋅Ltrack
各分项:
- L camera \mathcal{L}_{\text{camera}} Lcamera:Huber范数,预测与GT相机参数距离
- L depth \mathcal{L}_{\text{depth}} Ldepth:不确定性加权差异 + 梯度平滑项
- L pmap \mathcal{L}_{\text{pmap}} Lpmap:类似depth的不确定性损失,作用于3D点坐标
- L track \mathcal{L}_{\text{track}} Ltrack:L2对应距离 + 可见性BCE
Over-complete Supervision的哲学:深度+相机位姿数学上已能推导点云,但同时监督三者反而提升所有输出质量。这打破了"去掉冗余supervision"的直觉。
训练配置:160K迭代、64张A100、9天、bfloat16精度、梯度裁剪阈值1.0。
三、实验分析
3.1 相机位姿估计
| 方法 | Re10K AUC@30 | CO3Dv2 AUC@30 | 时间 |
|---|---|---|---|
| DUSt3R | 67.7 | 76.7 | ~9s |
| MASt3R | 76.4 | 81.8 | ~7s |
| VGGSfM | 78.9 | 83.4 | ~10s |
| VGGT (FF) | 85.3 | 88.2 | ~0.2s |
| VGGT + BA | 93.5 | 91.8 | ~1.8s |
前馈VGGT无需BA已超越所有需要后端优化的方法,加BA后进一步拉开差距。
3.2 多视图深度估计(DTU)
| 方法 | Chamfer距离 | 相机来源 |
|---|---|---|
| GeoMVSNet | 0.295 | GT cameras |
| DUSt3R | 1.741 | 自估计 |
| VGGT | 0.382 | 自估计 |
VGGT用自估计相机即接近使用GT相机的传统MVS方法。
3.3 点云重建(ETH3D)
| 方法 | Overall Error | 时间 |
|---|---|---|
| DUSt3R | 1.005 | ~9s |
| MASt3R | 0.826 | ~7s |
| VGGT | 0.677 | ~0.2s |
3.4 3D点跟踪(TAP-Vid)
作为特征骨干,VGGT提取的tracking features显著提升CoTracker基线:
| 骨干 | Kinetics AJ | DAVIS OA |
|---|---|---|
| CoTracker baseline | 49.6 | 88.3 |
| CoTracker + VGGT | 57.2 | 91.4 |
3.5 运行时性能
| 帧数 | 推理时间 | 显存 |
|---|---|---|
| 10 | 0.14s | 3.63GB |
| 50 | 1.08s | 10.90GB |
| 100 | 3.12s | 21.15GB |
| 200 | 8.75s | 40.63GB |
四、关键设计决策分析
4.1 为什么选择Alternating Attention而非Cross-Attention?
Cross-Attention的问题:
- 计算复杂度 O ( N 2 ⋅ L 2 ) O(N^2 \cdot L^2) O(N2⋅L2)(N帧、L token/帧),帧数多时爆炸
- 需要显式定义query来源,隐含假设帧间关系方向
- 无法同时建模帧内空间结构
AA的设计哲学:让网络自己学习何时关注局部、何时关注全局。帧内层 O ( N ⋅ L 2 ) O(N \cdot L^2) O(N⋅L2),全局层 O ( ( N L ) 2 ) O((NL)^2) O((NL)2) 但可通过flash attention优化。
4.2 数据归一化策略
GT点云按平均欧氏距离归一化后再监督。模型学习预测归一化后的坐标,推理时需要尺度恢复。这避免了不同场景尺度差异导致的梯度不平衡。
4.3 Permutation Equivariance
除第一帧(参考帧)外,架构对其余帧排列等变。这意味着打乱输入帧顺序不影响输出(除了点云坐标系定义)。
小结
VGGT的核心贡献是证明了单个前馈网络可以同时高质量解决多个3D视觉任务,且速度比优化方法快1~2个数量级。
创新点:
- Alternating Attention替代Cross-Attention,兼顾帧内精度和跨帧一致性
- Over-complete supervision------冗余监督反而提升所有输出
- 统一架构处理1~100+帧,无需区分双视图和多视图场景
局限性:
- 不支持鱼眼/全景相机
- 极端旋转(>90度)性能下降
- 大幅非刚性形变场景失效
- 显存随帧数线性增长,200帧需40GB
个人判断:VGGT代表了3D视觉从"流水线组合"向"端到端统一"的范式转变。AA机制的成功暗示Cross-Attention在多视图几何中可能被高估------简单的"看自己→看全部"交替就足够。但40GB@200帧的显存需求限制了实际部署,工程化落地仍需蒸馏或分块推理。对VIO系统的启示:VGGT的tracking feature可直接作为前端特征提取器,其跨帧attention可能替代传统光流匹配。