目录
[Batch Normalization优化训练](#Batch Normalization优化训练)
[Early Stopping](#Early Stopping)
在前面的文章中,我们已经学习了:
Tensor数据处理
神经网络搭建
损失函数与优化器
模型训练流程
模型权重保存与加载但是在实际项目中,很多同学都会遇到一个问题:
模型能训练
但是效果不好例如:
准确率上不去
训练速度慢
过拟合严重
数据量不足
模型泛化能力差事实上,深度学习项目中:
网络结构只占成功因素的一部分
训练策略和优化技巧同样重要很多工业级项目并不会从零开始训练模型,而是采用:
迁移学习
数据增强
预训练模型
微调训练
学习率调优
集成学习等方式来提升模型效果。
本文将系统讲解:
迁移学习原理
预训练模型使用
模型微调
数据增强
类别不平衡处理
训练技巧优化
模型效果提升方案什么是迁移学习
迁移学习(Transfer Learning)是深度学习领域最重要的技术之一。
核心思想:
利用已有模型学到的知识
解决新的任务举个例子:
ImageNet拥有1000万级图片
训练得到ResNet模型
已经学会识别:
边缘
纹理
形状
物体特征那么:
猫狗识别
水果分类
工业缺陷检测这些任务完全没必要重新学习基础特征。
直接利用已有知识即可。
这就是迁移学习。
为什么迁移学习效果好
传统训练方式:
随机初始化参数
从0开始学习存在问题:
训练慢
需要大量数据
容易过拟合迁移学习:
加载预训练模型
继承已有特征提取能力优势:
收敛更快
准确率更高
数据需求更少特别适用于:
中小规模数据集迁移学习训练流程
整体流程如下:
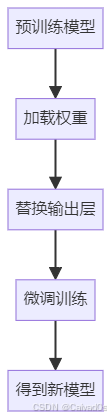
例如:
ResNet50
原本识别1000类
↓
修改最后一层
↓
识别5类水果使用PyTorch加载预训练模型
PyTorch提供了大量预训练模型。
导入:
python
import torchvision.models as models加载ResNet50:
python
model = models.resnet50(
weights=models.ResNet50_Weights.DEFAULT
)此时:
模型参数已经训练完成无需重新训练。
查看模型结构
查看网络:
print(model)输出:
Conv
BatchNorm
Residual Block
FC其中最后一层:
model.fc类似:
Linear(
in_features=2048,
out_features=1000
)替换分类层
假设:
原任务1000分类
新任务5分类修改:
python
import torch.nn as nn
model.fc = nn.Linear(
2048,
5
)这样:
特征提取能力保留
分类能力重新学习冻结特征提取层
小数据集训练时:
不需要训练全部参数冻结:
python
for param in model.parameters():
param.requires_grad = False然后:
python
for param in model.fc.parameters():
param.requires_grad = True结果:
只训练最后分类层优势:
训练快
避免过拟合微调训练(Fine-Tuning)
如果数据量较大:
可以训练部分卷积层例如:
python
for param in model.layer4.parameters():
param.requires_grad = True这样:
高级特征重新学习
低级特征保留效果通常优于完全冻结。
迁移学习训练示例
定义优化器:
python
optimizer = torch.optim.Adam(
model.parameters(),
lr=0.0001
)定义损失函数:
criterion = nn.CrossEntropyLoss()训练:
python
for epoch in range(20):
output = model(images)
loss = criterion(
output,
labels
)
optimizer.zero_grad()
loss.backward()
optimizer.step()数据增强的重要性
深度学习有一句经典名言:
Garbage In
Garbage Out数据质量决定模型上限。
数据增强可以:
扩充训练样本
提高泛化能力
减少过拟合常见数据增强方法
图像增强:
随机翻转
随机旋转
随机裁剪
颜色扰动
随机缩放示意:

PyTorch实现数据增强
python
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.RandomResizedCrop(224),
transforms.ToTensor()
])作用:
每轮生成不同训练样本Batch Normalization优化训练
BN层作用:
稳定数据分布
加速训练网络中:
nn.BatchNorm2d(64)优势:
提高收敛速度
缓解梯度消失现代CNN基本标配。
Dropout防止过拟合
原理:
随机关闭神经元代码:
nn.Dropout(0.5)表示:
50%概率失活效果:
提高泛化能力类别不平衡处理
实际数据:
正常样本 9500
异常样本 500训练后:
模型倾向预测正常解决方案:
类别权重
过采样
欠采样
Focal Loss类别权重训练
例如:
python
weights = torch.tensor([1,5])
criterion = nn.CrossEntropyLoss(
weight=weights
)作用:
增加少数类别重要性学习率调度器
固定学习率通常不是最佳方案。
PyTorch:
python
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer,
step_size=10,
gamma=0.1
)训练:
scheduler.step()效果:
后期训练更加稳定Early Stopping
训练过程中:
验证集准确率长期不提升则停止训练。
逻辑:
连续10轮无提升
↓
停止训练优势:
节约资源
防止过拟合混合精度训练
现代GPU支持:
FP16训练PyTorch:
from torch.cuda.amp import autocast使用:
python
with autocast():
output = model(x)
loss = criterion(
output,
y
)优势:
显存降低
训练加速集成学习提升效果
多个模型共同预测:
ResNet
DenseNet
EfficientNet投票:
模型A
模型B
模型C
↓
综合结果通常:
准确率更高模型训练效果提升路线图
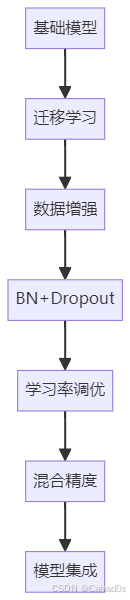
可视化训练过程
记录Loss:
python
loss_list.append(
loss.item()
)记录Accuracy:
python
acc_list.append(
acc.item()
)绘图:
python
import matplotlib.pyplot as plt
plt.plot(loss_list)
plt.show()观察:
Loss下降
Accuracy上升判断训练是否正常。
项目实战推荐策略
小数据集:
迁移学习
冻结卷积层
数据增强中型数据集:
迁移学习
部分微调
学习率衰减大数据集:
全量训练
混合精度
多GPU训练常见面试题
什么是迁移学习?
利用已有模型知识
解决新任务为什么迁移学习效果好?
减少随机学习过程
保留通用特征什么是Fine-Tuning?
在预训练模型基础上继续训练Dropout作用是什么?
防止过拟合BatchNorm作用是什么?
稳定训练
加速收敛为什么要使用数据增强?
扩大数据规模
提高泛化能力总结
在工业级深度学习项目中:
网络结构 ≠ 最终效果真正决定模型性能的往往是:
迁移学习
数据增强
微调训练
正则化
学习率策略
训练技巧其中:
迁移学习
是提升模型效果性价比最高的方法完整优化路线:
预训练模型
↓
迁移学习
↓
微调训练
↓
数据增强
↓
正则化
↓
学习率调优
↓
模型集成掌握这些方法之后,你将能够把一个普通模型训练到更高的准确率和更好的泛化能力,为后续学习:
目标检测
语义分割
Transformer
大模型微调
多模态模型打下坚实基础。
可以说:
深度学习项目的竞争力,很多时候并不来自于更复杂的网络结构,而来自于更合理的训练策略和更成熟的模型优化经验。