目录
[三、什么是计算图(Computation Graph)](#三、什么是计算图(Computation Graph))
[五、前向传播(Forward Propagation)](#五、前向传播(Forward Propagation))
[十、PyTorch 自动微分示例](#十、PyTorch 自动微分示例)
在学习深度学习框架时,无论是 PyTorch 还是 TensorFlow,我们都会接触到一个非常重要的概念:
Automatic Differentiation
自动微分很多初学者会认为:
自动微分
=
求导公式实际上并不是这样。
自动微分并不是简单地套用数学公式,而是通过:
计算图
+
前向传播
+
反向传播自动计算复杂神经网络中的梯度。
可以说:
自动微分是现代深度学习框架的核心基础。
没有自动微分,就不会有今天的 PyTorch、TensorFlow 和各种大模型训练框架。
本文将重点讲解:
-
什么是自动微分
-
什么是计算图
-
前向传播如何工作
-
自动微分为什么依赖计算图
一、什么是自动微分
假设有一个函数:
如果要求导:
dy/dx传统方法有两种。
数值微分
利用导数定义:
f'(x)\approx\frac{f(x+h)-f(x)}{h}
例如:
python
def numerical_grad(f, x):
h = 1e-5
return (f(x + h) - f(x)) / h优点:
简单缺点:
存在误差
计算速度慢符号微分
例如:
y = x² + 3x + 2直接推导:
dy/dx = 2x + 3优点:
结果精确缺点:
复杂表达式容易爆炸例如:
深度神经网络拥有上亿参数。
符号推导几乎不可行。
于是出现了:
自动微分二、自动微分的本质
自动微分并不是直接对整个函数求导。
而是:
将复杂函数拆解成多个简单运算例如:
加法
减法
乘法
除法
指数
对数然后利用链式法则逐步计算。
例如:
z = (x + y) * t可以拆成:
a = x + y
z = a * t此时复杂函数被分解成多个简单步骤。
而这些步骤连接起来:
就是计算图三、什么是计算图(Computation Graph)
计算图本质上是:
数据流图用于描述:
数据如何流动
运算如何执行例如:
z = (x + y) * t对应计算图:
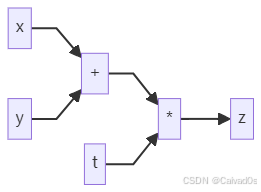
从图中可以清晰看到:
输入变量
运算节点
输出结果之间的关系。
在深度学习框架内部:
每一个Tensor
每一次运算都会形成这样的图结构。
四、为什么需要计算图
假设函数:
y = (a+b)*(c+d)如果没有计算图。
程序只会得到:
最终结果却不知道:
中间过程而自动微分需要:
记录每一步运算例如:
e = a+b
f = c+d
y = e*f这样后续才能计算:
dy/da
dy/db
dy/dc
dy/dd因此:
计算图
=
自动微分的数据基础五、前向传播(Forward Propagation)
计算图建立之后。
首先执行:
Forward Pass
前向传播很多人以为:
前向传播
=
神经网络专属实际上不是。
任何计算图都会执行前向传播。
例如:
x = 2
y = 3
z = x*y + 5拆分:
a = x*y
z = a+5对应计算图:
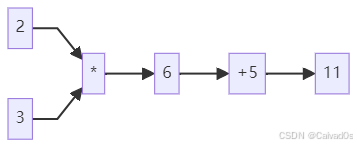
前向传播过程:
第一步:
x = 2
y = 3第二步:
a = x*y
a = 6第三步:
z = a+5
z = 11最终输出:
z = 11这就是前向传播。
六、前向传播保存了什么
自动微分不仅计算结果。
还会记录:
运算类型
输入节点
输出节点
中间结果例如:
a = x*y框架会记录:
Operation:
Multiply
Input:
x,y
Output:
a在 PyTorch 中:
python
import torch
x = torch.tensor(
2.0,
requires_grad=True
)
y = torch.tensor(
3.0,
requires_grad=True
)
z = x * y此时:
python
print(z.grad_fn)输出:
<MulBackward0>说明:
乘法节点
已经被记录七、计算图是如何构建的
在 PyTorch 中:
python
x = torch.tensor(
2.0,
requires_grad=True
)开启:
梯度跟踪执行:
y = x * 3框架自动创建:
乘法节点继续:
z = y + 2自动创建:
加法节点最终形成:

整个过程完全自动。
开发者无需手工构建。
八、前向传播在神经网络中的作用
假设一个简单神经元:
z=w_1x_1+w_2x_2+b
输入:
x1 = 2
x2 = 3参数:
w1 = 0.5
w2 = 0.8
b = 1前向传播:
0.5 × 2 = 10.8 × 3 = 2.41 + 2.4 + 1
=
4.4输出:
z = 4.4如果再经过激活函数:
a=\sigma(z)
就得到神经元最终输出。
整个神经网络训练过程:
输入数据
↓
前向传播
↓
计算损失
↓
反向传播
↓
更新参数前向传播负责:
计算预测结果九、自动微分为什么如此高效
假设一个神经网络:
100层包含:
上百万次运算如果采用:
数值微分需要反复计算函数。
效率极低。
而自动微分:
只记录计算图前向传播时:
顺便保存中间结果后续反向传播直接复用。
因此:
计算速度快
内存利用合理
梯度精确这也是现代深度学习框架全部采用自动微分的原因。
十、PyTorch 自动微分示例
完整代码:
python
import torch
x = torch.tensor(
2.0,
requires_grad=True
)
y = x ** 2 + 3 * x + 2
print(y)输出:
tensor(12.)查看计算图:
python
print(y.grad_fn)输出:
<AddBackward0>说明:
PyTorch已经构建好计算图此时:
python
y.backward()
print(x.grad)输出:
tensor(7.)因为:
dy/dx
=
2x+3
=
7而这一切:
无需手工求导完全由自动微分完成。
总结
自动微分是现代深度学习框架最重要的基础技术之一。
其核心思想并不复杂:
复杂函数
↓
拆解成简单运算
↓
构建计算图
↓
执行前向传播
↓
保存中间结果
↓
后续计算梯度其中:
计算图
负责记录计算过程
前向传播
负责计算最终结果二者共同构成了自动微分系统的基础。
理解了计算图和前向传播之后,我们就已经掌握了自动微分的第一块拼图。下一步便是深入学习:
反向传播(Backpropagation)
链式法则(Chain Rule)
梯度下降(Gradient Descent)
PyTorch Autograd源码机制这些内容共同组成了现代深度学习训练框架的核心原理。