循环是平凡的
循环是 agent 区别于 chatbot 的形式特征,但循环本身没有任何含量:
python
while not done:
ctx = assemble_context(state)
action = policy(ctx) # LLM call
state = execute(action) # environment step这几行代码很容易。2023 年的 AutoGPT 它有当时最华丽的循环。但那一代 scaffold 集体退场,退场不是循环写得不好,而是循环里跑的东西在发散。
真正的命题是:循环什么时候收敛,什么时候发散
没有反馈修正的循环 = 误差复利。假设单步正确率 95%,20 步之后整条轨迹成功率只剩 0.95²⁰ ≈ 36%。这就是 AutoGPT在愚蠢中打转的数学解释。反过来,有高质量环境反馈的循环 = 推理时搜索(inference-time search):每次迭代消耗算力换取修正,成功率随步数上升而不是衰减。
同一个 while 循环,可以是误差放大器,也可以是搜索算法,区别完全在循环之外。
所以:agent 是让循环收敛的那套闭环控制系统。 循环只是载体。
一个有用的形式化
把这个想法形式化:LLM 是 POMDP 里的 policy π(action | state),循环只是 env.step()。
ReAct 其实相当于是 policy 的一种参数化------在 action token 前先生成 thought token。这在过去是必要的 prompting 技巧,当时模型没有原生推理;今天的 reasoning model 已经把Reason这一步内化进模型,我们手写的 Thought: 前缀基本是阑尾。
这里藏着一个会反复出现的模式:scaffold 里的能力会被吸进模型。BabyAGI 的 task queue、优先级排序、外挂反思链,全部被更强的模型内化或证伪------这是 bitter lesson 的 agent 版。
如果 LLM = policy,循环 = step(),设计空间就自动展开成四条正交的轴。工程含量全在这四条轴上,而不在循环里。
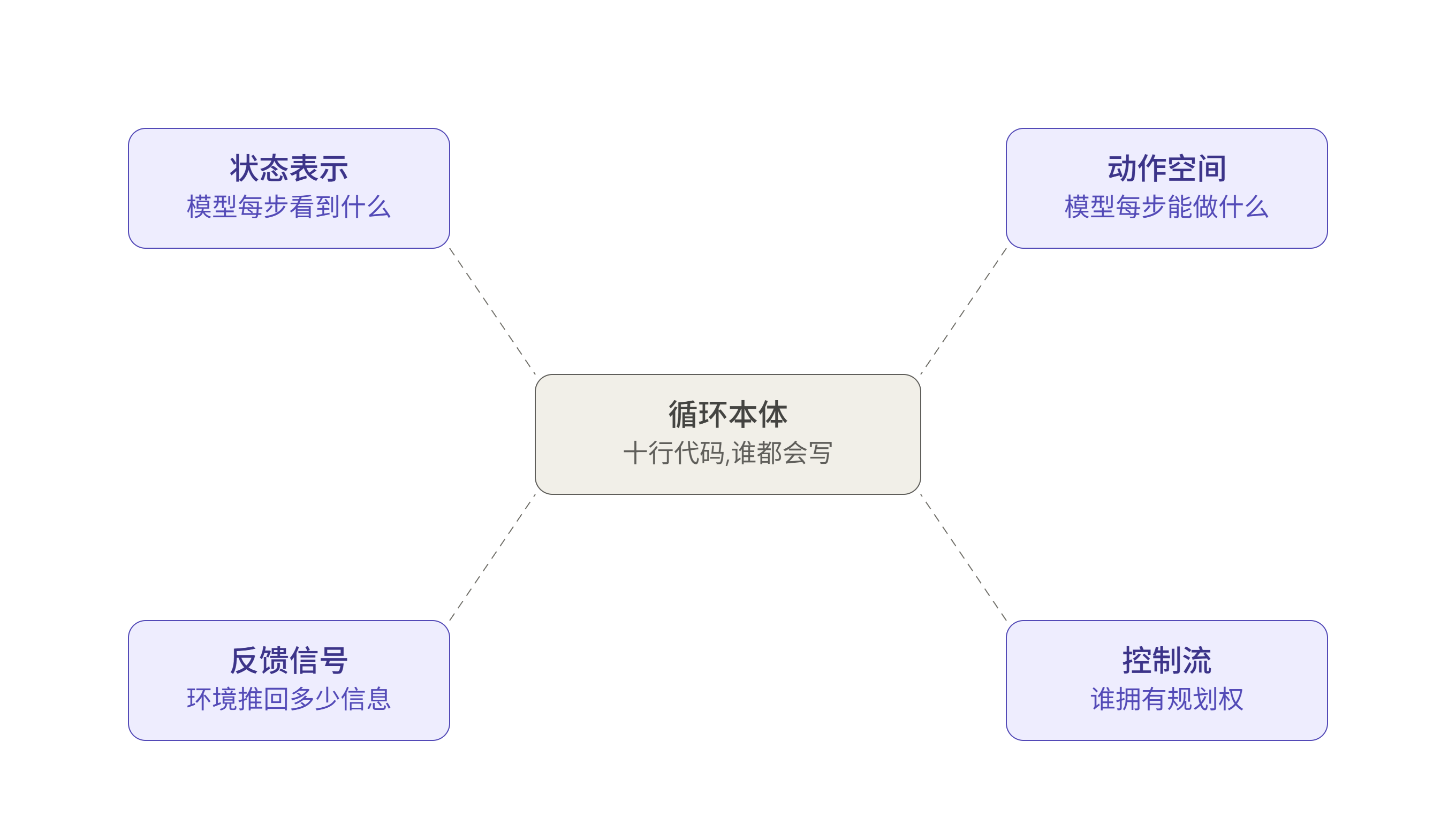
状态表示 ------ context engineering 才是真正的主业
每次迭代模型看到什么,这个问题占了 agent 工程主要的工作量。
Context window 是工作记忆(RAM),全部历史塞进去在长任务上不切实际(context rot + 成本爆炸)。标准动作可以看成四个:
- 压缩(compaction)
- 摘要(summarization)
- 外置(externalization,文件系统或数据库)
- 隔离(isolation,sub-agent 拿干净窗口)
pgvector 这类记忆层就是外置;markdown skills 则是程序性记忆,可以追到 Voyager 的 skill library------把成功轨迹蒸馏成可复用过程,本质是 amortized planning。
还有个技巧:Claude Code 采用不断重写 todo list 的行为,目的不是给人看,是把目标反复抄写到 context 末尾去操纵注意力,对抗 lost-in-the-middle。
还有生产上面:agent 的 input:output token 比约 100:1, KV-cache 命中率是第一性能指标 这就是 context 尽量 append-only,不要回头改历史(会击穿 cache)。要临时禁用工具,用 logit mask 而不是从 tool list 里删。
轴动作空间 ------ function calling 只是表达力最弱的那种
Function calling 一次只能发射一个原子动作,中间结果还得绕一圈回到 context。
CodeAct 的洞察是让代码本身成为动作空间:一个 action 内部就自带组合、循环、条件,变量还是免费的短期记忆。Claude Code 工具集极简(bash + 文件读写)却极强,原因就是 bash 是完备的动作空间。
工具设计不是一件简单的事,SWE-agent 给它起了名字叫 ACI(agent-computer interface):人体工学的对象是模型------错误信息要能指导恢复(error 本身就是反馈),输出要有 token 预算,少量正交工具远胜大量重叠工具。
顺带讲一下 MCP:它解决的是工具的分发与接入,不是设计;接 50 个 server 通常让 agent 变笨,因为 context 被工具定义污染、选择难度上升。
反馈信号 ------ 决定成败的关键
coding agent 基本可以认为是目前唯一大规模 work 的 agent 形态,不是模型特别懂代码,而是代码环境的反馈又快、又便宜、又可靠:编译器、类型检查、测试、linter。
这背后是验证不对称性原理:agent 在验证远易于生成的领域才有经济性;反馈稀疏、缓慢、模糊的领域(比如帮我规划营销战略),循环只会漂移。
structured output 那套 retry-with-feedback(pydantic + Instructor)其实就是这条原理的最小实现:validator 是 verifier,ValidationError 文本是反馈信号,重试是内循环------把这个模式放大就是 coding agent。
设计推论很直接:与其卷 prompt,不如卷环境的可验证性,给任务配 schema、测试、断言。
评估同理:pass@k (k 次至少成一次)是 demo 指标,pass^k(k 次全成)才是生产指标,τ-bench 把这个区分立了起来------0.95²⁰ 那笔账就是 pass^k 。
控制流 ------ 谁拥有规划权
Anthropic 的《Building Effective Agents》划了一条最有用的线:workflow 是开发者拥有控制流、LLM 填空;agent 是 LLM 拥有控制流。
中间是一条光谱:
prompt chaining → routing → orchestrator-workers → evaluator-optimizer → 全自治大多数生产系统靠近 workflow 端,只在路径不可预测且反馈存在时才交出控制权。12-Factor Agents 的口号own your control flow说的就是确定性管道里嵌微型 agent,而不是反过来。
Multi-agent 也要祛魅:sub-agent 的主要价值不是协作,是 context 隔离 ;代价是十几倍 token 和经由自然语言摘要的有损通信。只并行化读和探索(research 类),串行化写和决策。 Cognition 的《Don't Build Multi-Agents》和 Anthropic 的 multi-agent research 系统表面打架,其实是同一条法则的两面。
元原则:为模型变强而设计
给每个 scaffold 组件都可能衰败:
精巧的推理结构、手写计划模板、prompt DAG,衰败或许就在下一个模型周期,下一代模型一发布就贬值比如BabyAGI 整套 task queue。
但是工具、环境、反馈信号、外置记忆、eval 集是模型无关资产,模型越强它们增值越多。
Bitter lesson 的工程我觉得就说得很好:做给模型加杠杆的 harness,不做替模型思考的 scaffold。
所以ReAct 循环写得好不好是个低杠杆问题;高杠杆的问题是:
- context 装配策略是什么?
- 动作空间表达力够不够?
- 环境每步推回多少比特的可靠反馈?
- 控制权的边界画在哪?