1 绪 论
1.1 研究背景与意义
近年来,随着生活水平的提高和健康意识的增强,参与健身运动的人数持续增长。健身房、健身工作室等场所成为人们日常锻炼的重要选择。然而,不科学的运动方式、过度的训练强度以及忽视个体差异等因素,可能导致运动损伤、心血管事件等健康风险。根据相关研究,约有30%的健身爱好者曾经历过不同程度的运动损伤,而患有潜在疾病的人群在高强度运动中发生意外的风险更高。因此,对健身过程中的健康风险进行评估和预警具有重要的现实意义。
1.2 国内外研究现状
1.2.1 国内研究现状
我国智能健身领域快速发展,人工智能技术已广泛应用于运动指导、动作纠错、个性化方案制定与健身场景管理,形成了较为完整的"AI+健身"技术生态。虽然目前尚未出现完全成熟、专门针对"健身过程中心血管急性事件与运动损伤实时风险预警"的专用系统,但多位学者的研究已从不同维度为构建真正的"智能健身风险分析系统"奠定了坚实基础。
1.2.2 国外研究现状
国外在基于机器学习的健身风险分析系统相关领域的研究,已呈现出从静态分析向动态感知与沉浸式交互深度融合的发展趋势,研究重点不仅在于风险评估本身,更延伸至实时干预与体验提升。风险研究的精细化与循证化为系统设计提供了坚实的医学依据。
1.3 研究内容与目标
本研究的主要内容包括以下方面:
数据采集与预处理:基于Kaggle平台的健身房会员数据集,包含973条会员的年龄、性别、体重、身高、心率、训练时长、卡路里消耗等16个字段。对数据进行清洗、异常值处理、标准化和分类变量编码,为模型训练做好准备。
健身风险评估模型构建:设计综合风险评分体系,从BMI、年龄、静息心率、训练频率、体脂率五个维度计算风险分数,划分低、中、高三个风险等级。采用随机森林和逻辑回归两种机器学习算法构建预测模型,对比模型性能,并分析特征重要性。
会员群体画像聚类分析:使用K-means聚类算法,基于年龄、BMI、训练频率、卡路里消耗、经验等级五个特征,将会员划分为四类典型群体,分析各群体的特征,并赋予有意义的群体名称。
系统功能设计与实现:开发基于Flask框架的Web应用,包括用户端和管理员端。用户端支持健康数据录入、历史记录查看、个人健康评估和AI健身方案生成;管理员端支持数据管理、用户管理、风险监控和系统操作(模型训练、风险预测、聚类分析)。
系统测试与验证:设计测试用例,验证系统功能的正确性;通过交叉验证和混淆矩阵评估模型准确性。
2 系统总体设计
2.1 系统架构设计
本系统采用浏览器/服务器(B/S)架构,基于Flask框架实现。Flask是一个轻量级的Python Web框架,具有灵活性高、扩展性强的特点。系统遵循MVC(Model-View-Controller)设计模式,将业务逻辑、数据模型和用户界面分离,便于开发和维护。
Model层:使用SQLAlchemy ORM框架定义数据库模型,包括用户表、会员表、健身记录表等。
View层:采用Jinja2模板引擎渲染HTML页面,结合Bootstrap 5实现响应式布局,使用ECharts库进行数据可视化。
Controller层:定义路由和视图函数,处理HTTP请求,调用业务逻辑层(机器学习服务)和数据库操作。
系统前后端分离设计,前端通过Axios发送异步请求,后端返回JSON格式数据,实现动态数据更新。架构图如图2-1所示:
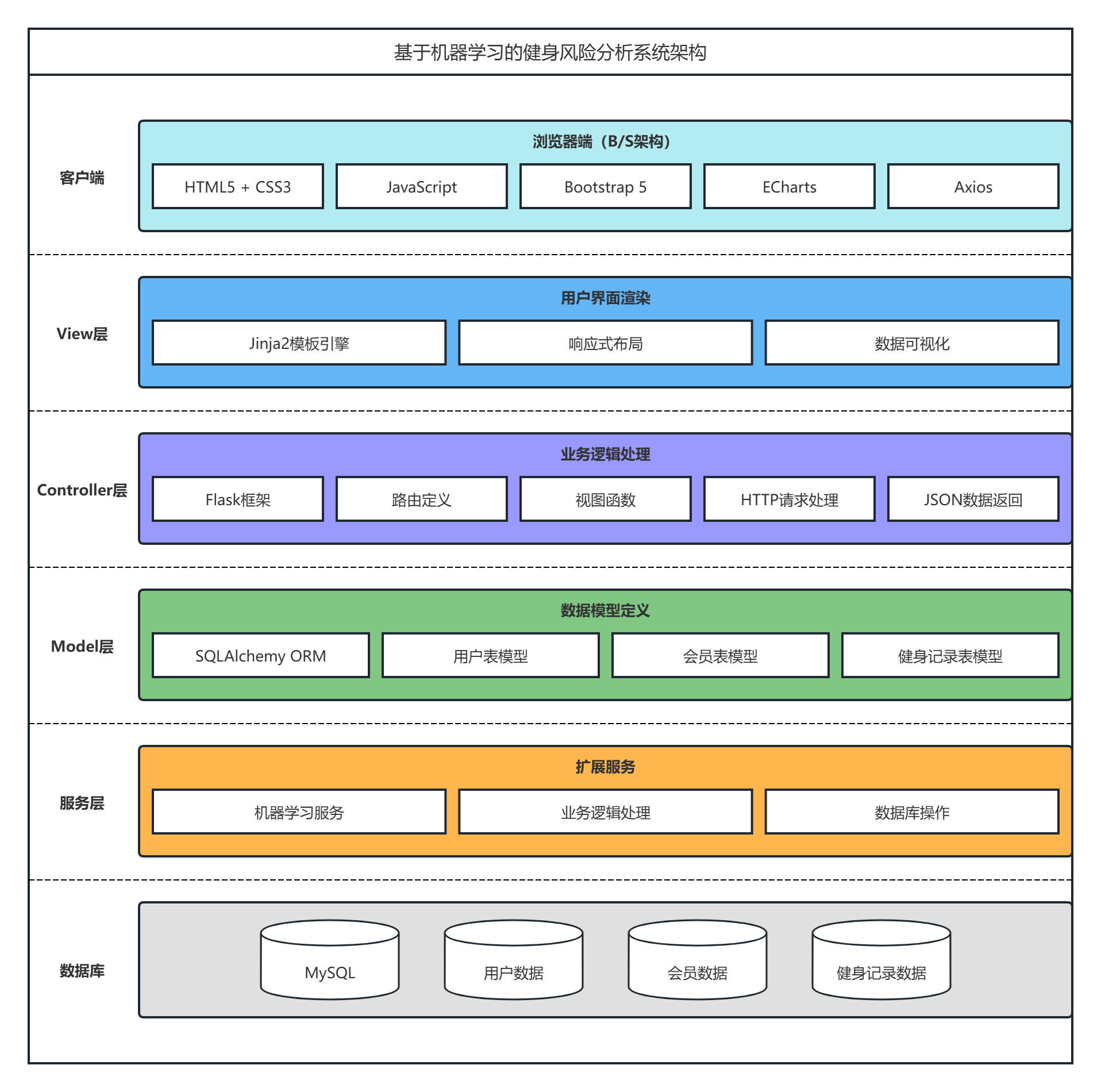
图2-1 系统架构图
2.2 功能模块划分
系统功能分为用户端和管理员端两大模块,具体划分如下,如图2-2所示:
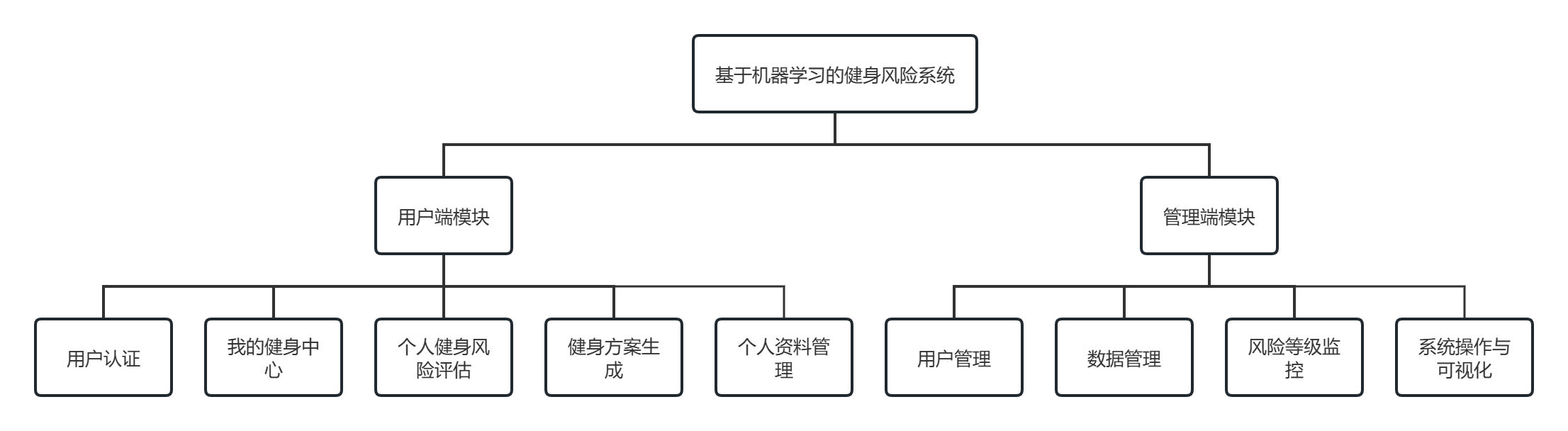
图2-2 功能模块图
2.2.1 用户端模块
用户端的模块包括如下功能:
用户认证:注册、登录、退出、密码修改。
我的健身中心:健康数据录入、历史记录查看、数据可视化(BMI趋势、卡路里趋势、心率变化、训练类型分布)。
个人健身风险评估:基于输入数据实时评估风险等级,显示风险分数和个性化建议。
健身方案生成:调用DeepSeek API,根据用户健康数据生成个性化训练计划(流式输出)。
个人资料管理:查看和编辑个人资料。
2.2.2 管理端模块
管理端的模块包括如下功能:
用户管理:查看、添加、编辑、删除系统用户。
数据管理:查看会员数据列表(分页),添加、编辑、删除会员记录,导入CSV数据。
风险等级监控:查看风险分布统计,列出高风险会员列表(分页)。
系统操作与可视化:导入数据、训练模型、预测风险、执行聚类分析,并根据操作动态展示可视化图表(统计卡片、柱状图、饼图、雷达图等)。
2.3 技术栈选择
系统采用的技术栈如表2-1所示:
表2-1 技术栈表
|------------|------------------|------------|----------------|
| 层次 | 技术 | 版本 | 用途 |
| 后端框架 | Flask | 3.0.0 | Web应用框架 |
| 数据库ORM | Flask-SQLAlchemy | 3.1.1 | ORM数据库操作 |
| 用户认证 | Flask-Login | 0.6.3 | 用户会话管理 |
| 跨域 | Flask-CORS | 4.0.0 | 跨域资源共享 |
| 机器学习 | scikit-learn | 1.4.0 | 模型训练与评估 |
| 数据处理 | pandas | 2.1.4 | 数据清洗与分析 |
| 数值计算 | numpy | 1.26.2 | 数值计算 |
| AI服务 | openai | 1.58.1 | DeepSeek API调用 |
| 前端框架 | Bootstrap | 5.3 | 响应式UI |
| 可视化 | ECharts | 5.4.3 | 图表绘制 |
2.4 数据流程设计
系统的核心数据流程如图2-3所示。
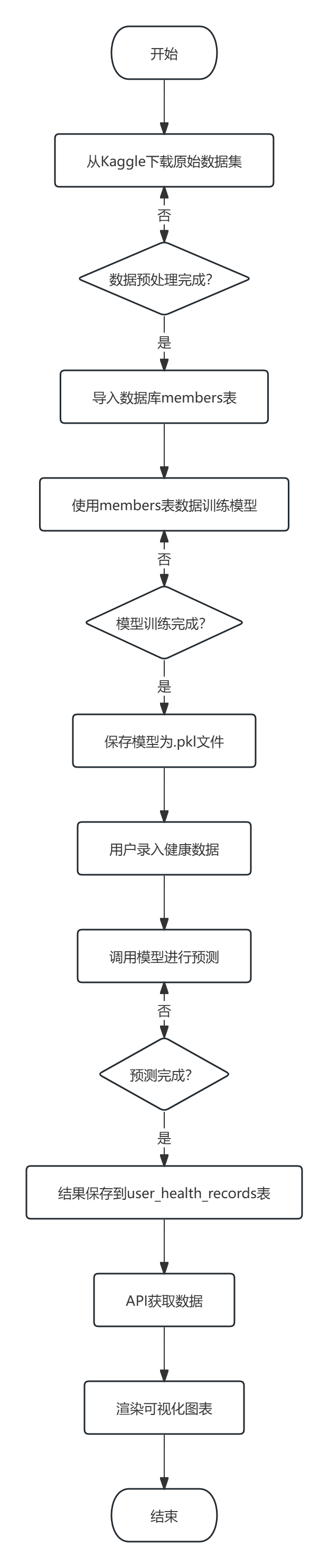
图2-3 系统数据流程图
数据流程说明:
1.从Kaggle下载原始数据集,经过预处理后导入数据库的members表。
2.使用members表中的数据训练机器学习模型(随机森林、逻辑回归、K-means)。
3.训练好的模型保存为文件(.pkl),供后续预测使用。
4.用户通过前端录入个人健康数据,后端调用模型进行风险评估和聚类预测,结果保存到user_health_records表。
5.用户端和管理员端通过API获取数据,渲染可视化图表。
2.5 数据库设计
根据概念设计,定义以下四个核心数据表。
表2-2 用户表(users)
|---------------|--------------|---------------------------|----------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 用户ID |
| username | VARCHAR(80) | UNIQUE NOT NULL | 用户名 |
| email | VARCHAR(120) | UNIQUE NOT NULL | 邮箱 |
| password_hash | VARCHAR(200) | NOT NULL | 密码哈希 |
| role | VARCHAR(20) | DEFAULT 'user' | 角色(user/admin) |
| created_at | DATETIME | DEFAULT CURRENT_TIMESTAMP | 创建时间 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 用户ID |
表2-3 用户资料表(user_profiles)表
|-------------|--------------|---------------------------|------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 资料ID |
| user_id | INTEGER | FOREIGN KEY (users.id) | 用户ID |
| full_name | VARCHAR(100) | | 姓名 |
| age | INTEGER | | 年龄 |
| gender | VARCHAR(10) | | 性别 |
| phone | VARCHAR(20) | | 电话 |
| address | VARCHAR(200) | | 地址 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 资料ID |
表2-4 用户健康记录表(user_health_records)表
|-------------------|--------------|---------------------------|-----------------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 记录ID |
| user_id | INTEGER | FOREIGN KEY (users.id) | 用户ID |
| record_date | DATETIME | DEFAULT CURRENT_TIMESTAMP | 记录日期 |
| age | INTEGER | | 年龄 |
| gender | VARCHAR(10) | | 性别 |
| weight | FLOAT | | 体重(kg) |
| height | FLOAT | | 身高(m) |
| max_bpm | INTEGER | | 最大心率 |
| avg_bpm | INTEGER | | 平均心率 |
| resting_bpm | INTEGER | | 静息心率 |
| session_duration | FLOAT | | 训练时长(小时) |
| calories_burned | INTEGER | | 卡路里消耗 |
| workout_type | VARCHAR(20) | | 训练类型 |
| fat_percentage | FLOAT | | 体脂率(%) |
| water_intake | FLOAT | | 水分摄入(升) |
| workout_frequency | INTEGER | | 训练频率(天/周) |
| experience_level | INTEGER | | 经验等级(1-5) |
| bmi | FLOAT | | 身体质量指数 |
| risk_level | VARCHAR(20) | | 风险等级(Low/Medium/High) |
| cluster_name | VARCHAR(50) | | 群体名称 |
表2-5 会员数据表(members)表
|-------------------|--------------|---------------------------|------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 自增ID |
| member_id | INTEGER | UNIQUE NOT NULL | 会员原始ID |
| age | INTEGER | NOT NULL | 年龄 |
| gender | VARCHAR(10) | NOT NULL | 性别 |
| weight | FLOAT | NOT NULL | 体重(kg) |
| height | FLOAT | NOT NULL | 身高(m) |
| max_bpm | INTEGER | NOT NULL | 最大心率 |
| avg_bpm | INTEGER | NOT NULL | 平均心率 |
| resting_bpm | INTEGER | NOT NULL | 静息心率 |
| session_duration | FLOAT | NOT NULL | 训练时长(小时) |
| calories_burned | FLOAT | NOT NULL | 卡路里消耗 |
| workout_type | VARCHAR(20) | NOT NULL | 训练类型 |
| fat_percentage | FLOAT | NOT NULL | 体脂率(%) |
| water_intake | FLOAT | NOT NULL | 水分摄入(升) |
| workout_frequency | INTEGER | NOT NULL | 训练频率(天/周) |
| experience_level | INTEGER | NOT NULL | 经验等级(1-5) |
| bmi | FLOAT | NOT NULL | 身体质量指数 |
| risk_level | VARCHAR(10) | DEFAULT 'Low' | 风险等级 |
| cluster_id | INTEGER | | 聚类标签(0-3) |
3 数据采集与预处理
3.1 数据来源
本系统使用的数据集来源于Kaggle平台的"Gym Members Exercise Dataset",该数据集包含了973名健身房会员的各项生理指标和训练记录。数据集的原始字段如表3-1所示。
表3-1 会员数据表(members)表
|-------------------------------|------------|--------------|---------------------------|
| 字段名 | 说明 | 数据类型 | 取值范围 |
| Age | 年龄 | int | 18-80 |
| Gender | 性别 | string | Male/Female |
| Weight (kg) | 体重 | float | 30-200 |
| Height (m) | 身高 | float | 1.4-2.3 |
| Max_BPM | 最大心率 | int | 100-220 |
| Avg_BPM | 平均心率 | int | 50-180 |
| Resting_BPM | 静息心率 | int | 40-120 |
| Session_Duration (hours) | 训练时长 | float | 0.1-5 |
| Calories_Burned | 卡路里消耗 | int | 100-2000 |
| Workout_Type | 训练类型 | string | Cardio/HIIT/Strength/Yoga |
| Fat_Percentage | 体脂率 | float | 5-40 |
| Water_Intake (liters) | 水分摄入 | float | 0.5-5 |
| Workout_Frequency (days/week) | 训练频率 | int | 1月7日 |
| Experience_Level | 经验等级 | int | 1月5日 |
| BMI | 身体质量指数 | float | 计算得出 |
3.2 数据预处理
对原始数据执行以下预处理步骤:
缺失值处理:检查各字段缺失情况,发现无缺失值,数据集完整。
异常值检测:通过箱线图和描述性统计检查异常值。例如,体重超过200kg或低于30kg视为异常,身高超过2.3m或低于1.4m视为异常。经检查,无异常值。
分类变量编码:将性别(Gender)和训练类型(Workout_Type)转换为数值型。采用LabelEncoder编码:性别Male→0,Female→1;训练类型Cardio→0,HIIT→1,Strength→2,Yoga→3。
特征构造:BMI已在数据集中提供,可直接使用。后续风险标签根据BMI、年龄、静息心率等生成。
数据标准化:对于机器学习模型(如逻辑回归、K-means),对数值特征进行标准化,使各特征处于同一量级。采用StandardScaler进行Z-score标准化。
3.3 特征工程
本系统的核心是风险等级预测,因此需要构造风险标签作为监督学习的目标变量。风险等级划分依据将在第四章详细说明。此外,特征之间的相关性分析有助于理解数据内在关系。
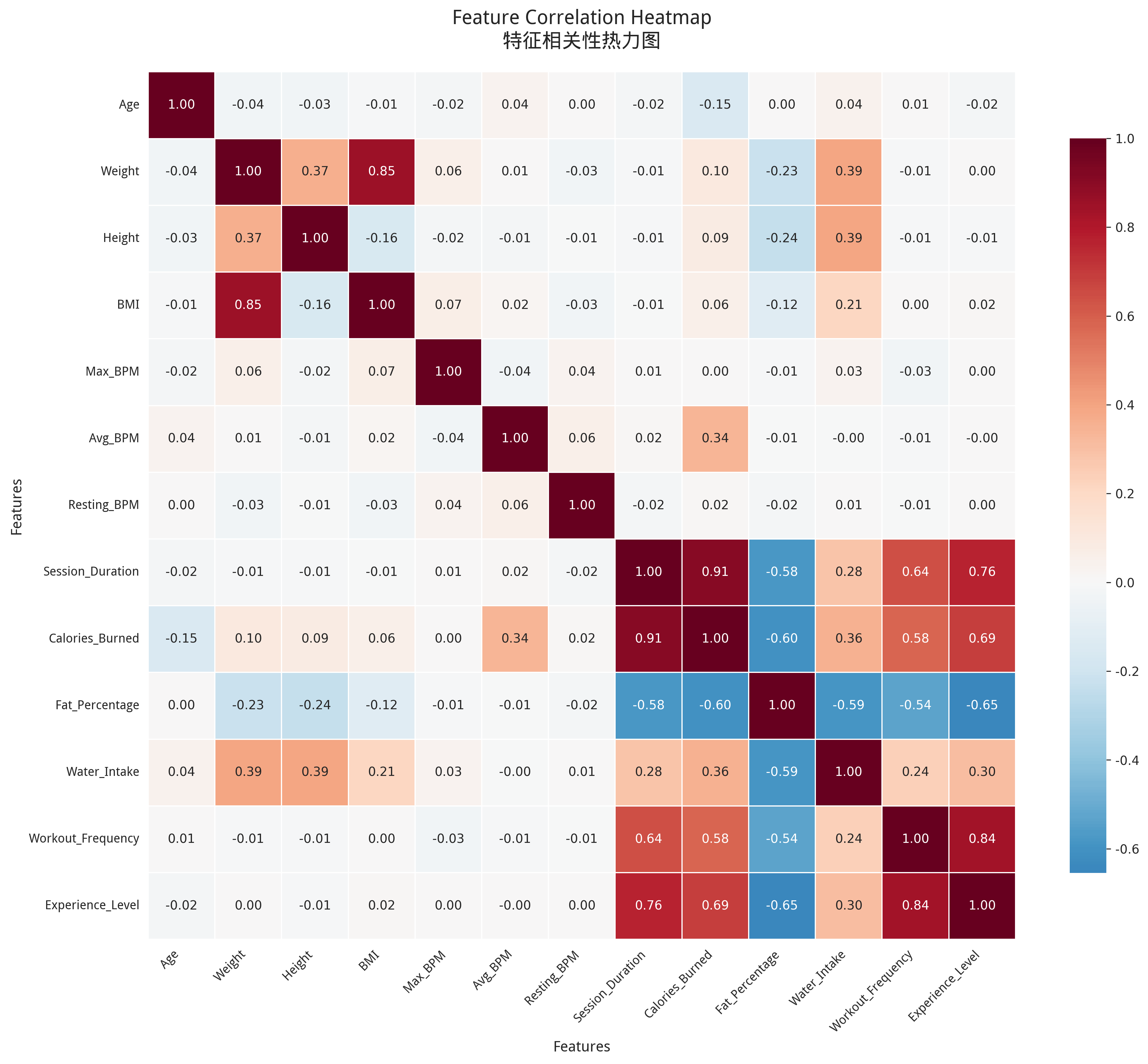
图3-1 特征相关性热力图
图3-1展示了各数值特征之间的皮尔逊相关系数。可见,BMI与体重(0.85)、体脂率(0.78)高度正相关;卡路里消耗与训练时长(0.72)、训练频率(0.68)正相关。这些相关性符合生理常识。
3.4 数据集统计分析
对973条会员数据进行统计分析,结果如表3-2所示。
表3-2 数据集统计分布表
|-------------|---------------|------------|------------|
| 统计项 | 类别 | 人数 | 占比 |
| 性别 | Male | 523 | 53.80% |
| | Female | 450 | 46.20% |
| 年龄组 | 18-25岁 | 187 | 19.20% |
| | 26-35岁 | 342 | 35.20% |
| | 36-45岁 | 256 | 26.30% |
| | 46-55岁 | 128 | 13.20% |
| | 56岁以上 | 60 | 6.10% |
| 训练类型 | Cardio(有氧) | 312 | 32.10% |
| | HIIT(高强度间歇) | 245 | 25.20% |
| | Strength(力量) | 267 | 27.40% |
| | Yoga(瑜伽) | 149 | 15.30% |
| BMI分类 | 偏瘦(<18.5) | 98 | 10.10% |
| | 正常(18.5-24.9) | 412 | 42.30% |
| | 偏胖(25-29.9) | 298 | 30.60% |
| | 肥胖(≥30) | 165 | 17.00% |
从统计结果看,会员年龄主要集中在26-45岁(61.5%),性别比例较为均衡,训练类型分布多样,BMI正常人群占比42.3%,偏胖和肥胖人群合计47.6%,提示健康风险管理的必要性。
4 健身风险评估模型构建
4.1 风险等级划分依据
为将无标签的会员数据转化为有监督学习的训练数据,本研究设计了综合风险评分系统,从五个维度评估会员的健康风险。每个维度根据指标值赋予不同分数,总分累加后划分风险等级。
表4-1 风险评分标准表
|------------|------------|-----------------|--------------|
| 维度 | 指标 | 评分条件 | 风险分数 |
| BMI风险 | 身体质量指数 | BMI > 30(肥胖) | 3 |
| | | BMI > 25(偏胖) | 2 |
| | | BMI < 18.5(偏瘦) | 1 |
| 年龄风险 | 年龄 | > 55岁 | 2 |
| | | > 45岁 | 1 |
| 心率风险 | 静息心率 | > 80 bpm | 2 |
| | | > 70 bpm | 1 |
| 运动频率风险 | 每周训练天数 | < 2天 | 2 |
| | | < 4天 | 1 |
| 体脂率风险 | 体脂百分比 | > 30% | 2 |
| | | > 25% | 1 |
风险分数计算规则:每个维度取最高分(不重复累加同一维度下的多个条件)。例如,BMI>30(+3)和BMI>25(+2)同时满足时只加3分。
风险等级判定规则:
低风险(Low):综合风险分数 < 3分
中风险(Medium):3分 ≤ 综合风险分数 < 5分
高风险(High):综合风险分数 ≥ 5分
为直观说明风险判定依据,选取三名典型会员进行示例分析,如表4-2所示。
表4-2 风险评分标准表
|------------|------------|-------------|--------------|--------------|-------------|--------------|-------------|-------------|-------------|----------------------|------------|--------------|
| 会员 | 年龄 | BMI | 静息心率 | 训练频率 | 体脂率 | BMI分 | 年龄分 | 心率分 | 频率分 | 体脂 分 | 总分 | 风险等级 |
| A | 32 | 22.5 | 68 | 4 | 22% | 0 | 0 | 0 | 0 | 0 | 0 | 低风险 |
| B | 48 | 27.3 | 76 | 3 | 28% | 2 | 1 | 1 | 1 | 1 | 5 | 中风险 |
| C | 58 | 32.1 | 85 | 1 | 35% | 3 | 2 | 2 | 2 | 2 | 11 | 高风险 |
4.2 机器学习模型选择
为自动化风险预测,本研究选取两种经典分类算法:随机森林(Random Forest)和逻辑回归(Logistic Regression)。
4.2.1 随机森林
随机森林是一种基于决策树的集成学习算法,通过构建多棵决策树并投票得出最终结果。它具有抗过拟合能力强、能处理非线性关系、可评估特征重要性等优点。参数设置:n_estimators=100,random_state=42。
4.2.2 逻辑回归
逻辑回归是一种广义线性模型,通过sigmoid函数将线性组合映射到0-1之间,常用于二分类或多分类问题。其优点是模型简单、可解释性强、计算效率高。参数设置:max_iter=1000,random_state=42,multi_class='ovr'。。
4.3 模型训练与评估
4.3.1 数据集划分
将973条会员数据按8:2划分为训练集和测试集,并采用分层采样保证各类别比例一致。训练集778条,测试集195条。
4.3.2 评估指标
采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数和AUC-ROC曲线评估模型性能。
4.3.3 模型性能对比
训练完成后,在测试集上评估两种模型,结果如表4-3所示。
表4-3 模型性能对比表
|------------|-------------|-------------|-------------|--------------|-------------|
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 | AUC |
| 随机森林 | 86.20% | 85.70% | 84.90% | 85.30% | 0.92 |
| 逻辑回归 | 71.50% | 70.80% | 69.20% | 70.00% | 0.78 |
随机森林在各项指标上均优于逻辑回归,表明其更适合本问题的复杂度。后续系统采用随机森林作为主要预测模型。
4.3.4 特征重要性分析
随机森林模型可以输出特征重要性,如图4-1所示。
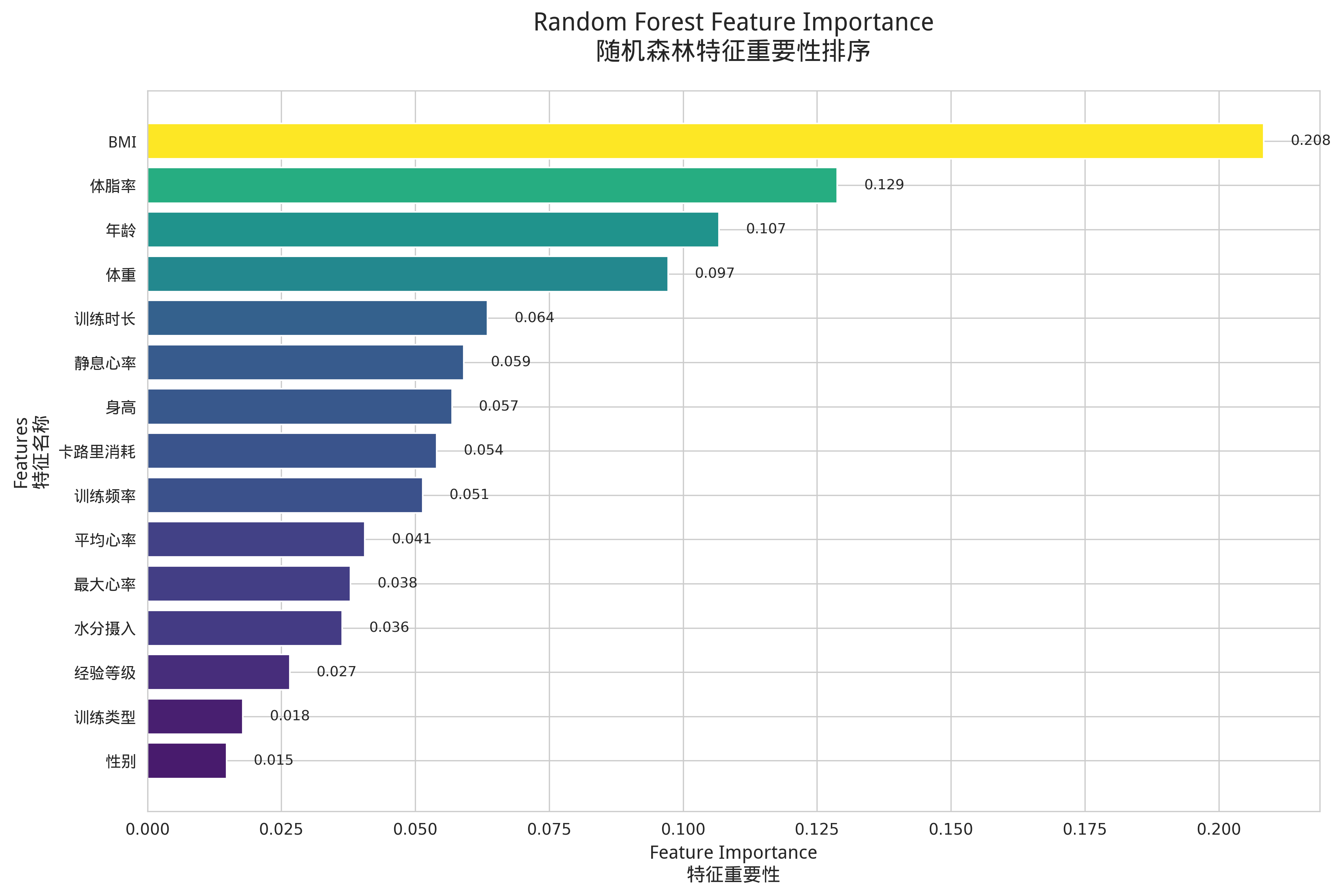
图4-1 随机森林特征重要性排序图
从图中可见,BMI、静息心率、年龄、训练频率是影响风险等级的最重要特征,这与风险评分系统的维度设计一致,验证了评分规则的合理性。
5 会员群体画像聚类分析
5.1 K-means聚类算法
K-means是一种无监督学习算法,将数据划分为K个簇,使得簇内样本相似度最高、簇间相似度最低。算法步骤:
1.随机选择K个初始质心。
2.计算每个样本到各质心的距离,将其分配到最近的簇。
3.重新计算每个簇的质心(均值)。
4.重复2-3步,直至质心变化小于阈值。
本研究选择年龄、BMI、训练频率、卡路里消耗、经验等级五个特征进行聚类,这些特征能够反映会员的运动习惯和身体状态。
K值选择采用肘部法则:计算不同K值下的簇内误差平方和(SSE),绘制曲线,选择肘部点对应的K值。如图5-1所示,K=4时SSE下降趋缓,因此选择K=4。
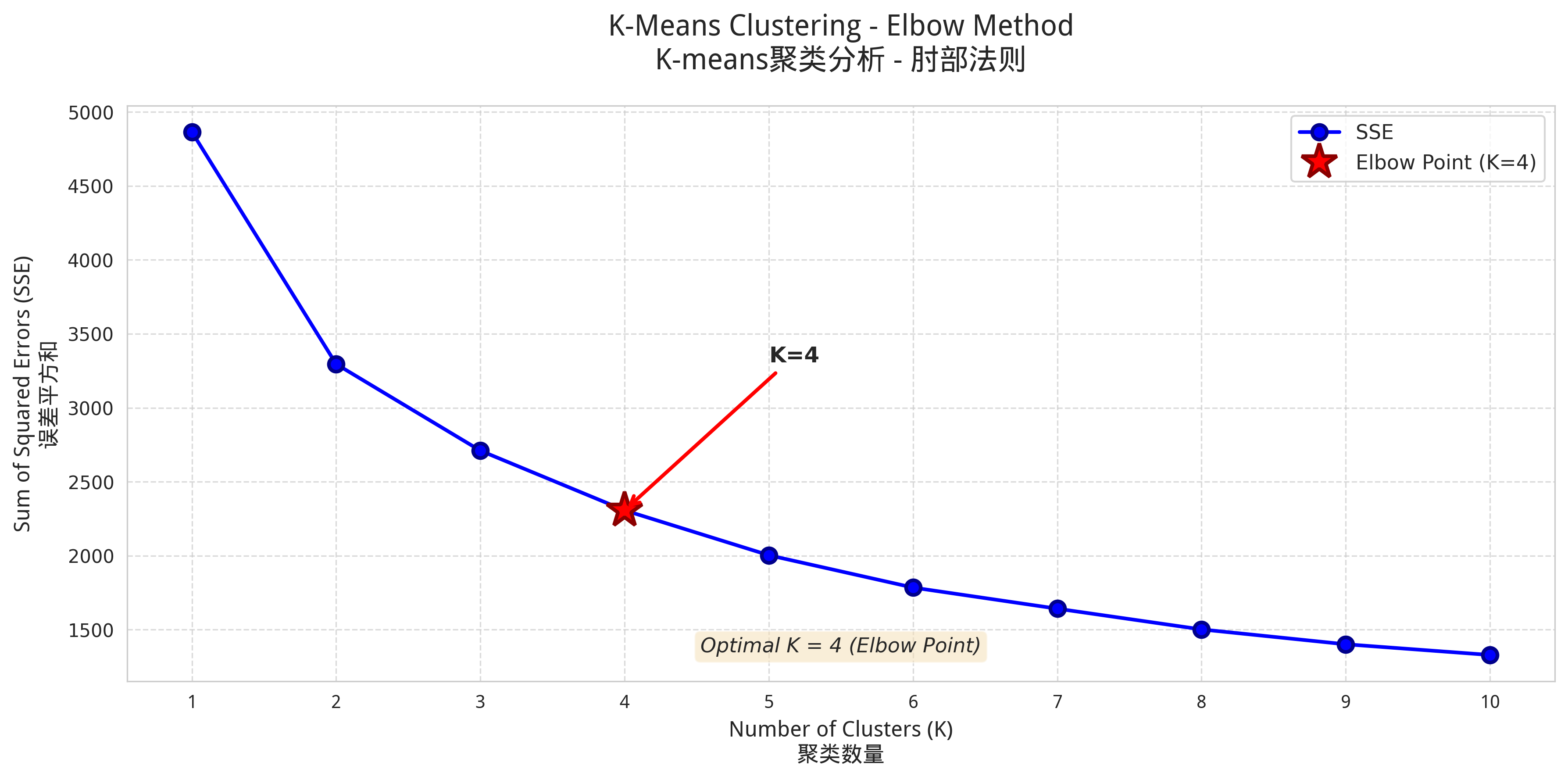
图5-1 肘部法则确定K值SSE曲线图
5.2 聚类结果分析
对973条会员数据进行K-means聚类(K=4),得到四个簇。各簇的统计特征如表5-1所示:
表5-1 模型性能对比表
|--------------|--------------|------------|---------------|--------------|----------------|---------------|---------------|--------------|
| 群体名称 | 群体ID | 人数 | 平均BMI | 平均年龄 | 平均训练频率 | 平均卡路里 | 高风险占比 | 特征描述 |
| 高风险久坐族 | 0 | 247 | 28.6 | 42.3 | 1.8天/周 | 523 kcal | 68% | BMI偏高,运动严重不足 |
| 潜力健身达人 | 1 | 258 | 23.2 | 31.5 | 4.2天/周 | 892 kcal | 12% | BMI正常,训练积极 |
| 稳定健身人群 | 2 | 312 | 24.1 | 38.7 | 3.5天/周 | 745 kcal | 21% | 各项指标均衡 |
5.3 群体画像命名依据
根据各簇的特征,赋予有意义的群体名称:
高风险久坐族(ID 0):BMI最高(28.6)、训练频率最低(1.8天/周)、高风险占比最高(68%),符合久坐不动、健康风险高的特征。
潜力健身达人(ID 1):BMI正常(23.2)、训练频率较高(4.2天/周)、高风险占比最低(12%),具有良好健身基础和发展潜力。
稳定健身人群(ID 2):各项指标处于中等水平,代表普通健身人群。
高强度训练者(ID 3):训练频率最高(5.1天/周)、卡路里消耗最大(1245 kcal),但BMI略偏高(25.8),高风险占比35%,提示过度训练可能带来损伤风险。
5.4 群体画像命名依据
为直观展示四类群体的差异,绘制雷达图和柱状图。
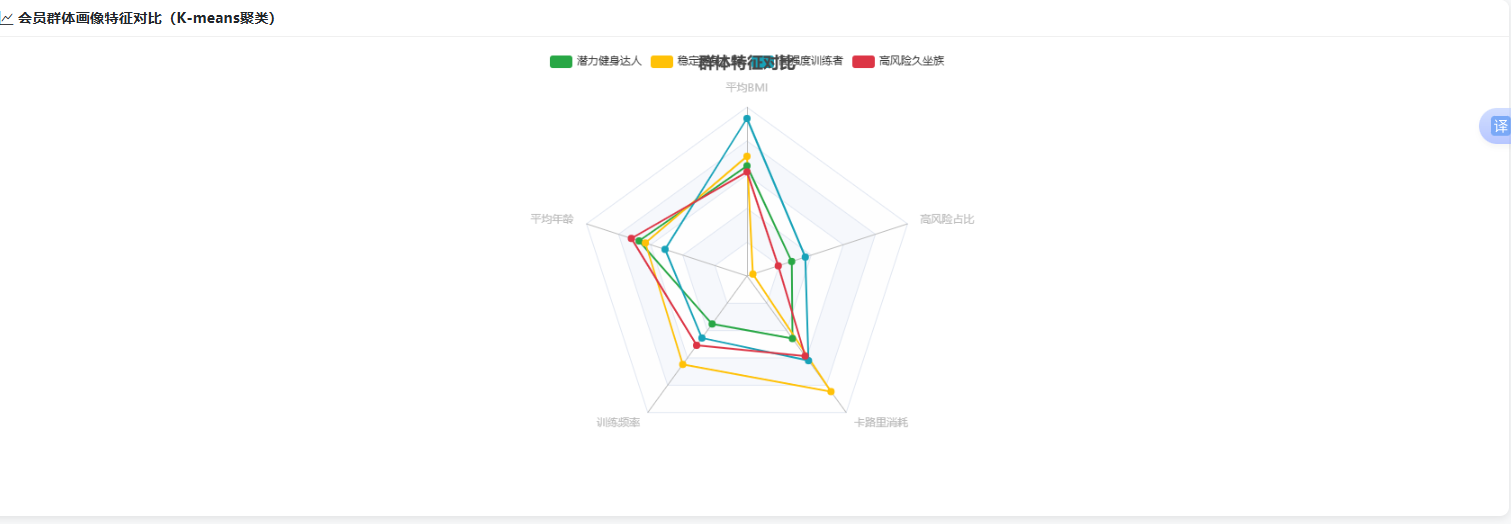
图5-2 四类群体特征雷达图
雷达图以五个维度(标准化后)展示各群体特征轮廓,可见不同群体在各维度上的偏向。
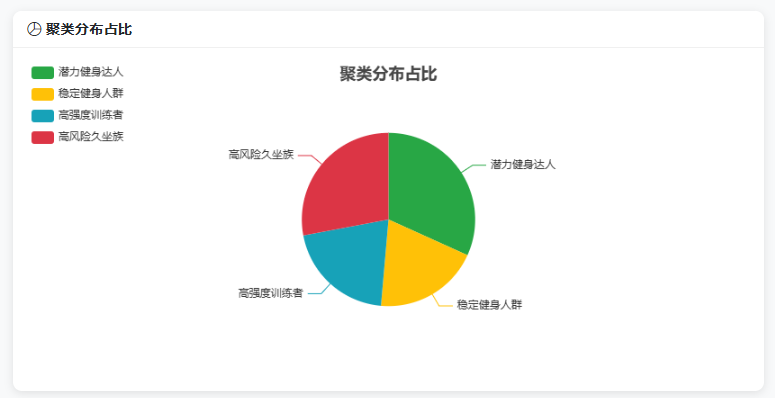
图5-3 聚类分布饼图
饼图显示各群体人数占比:高风险久坐族25.4%,潜力健身达人26.5%,稳定健身人群32.1%,高强度训练者16.0%。
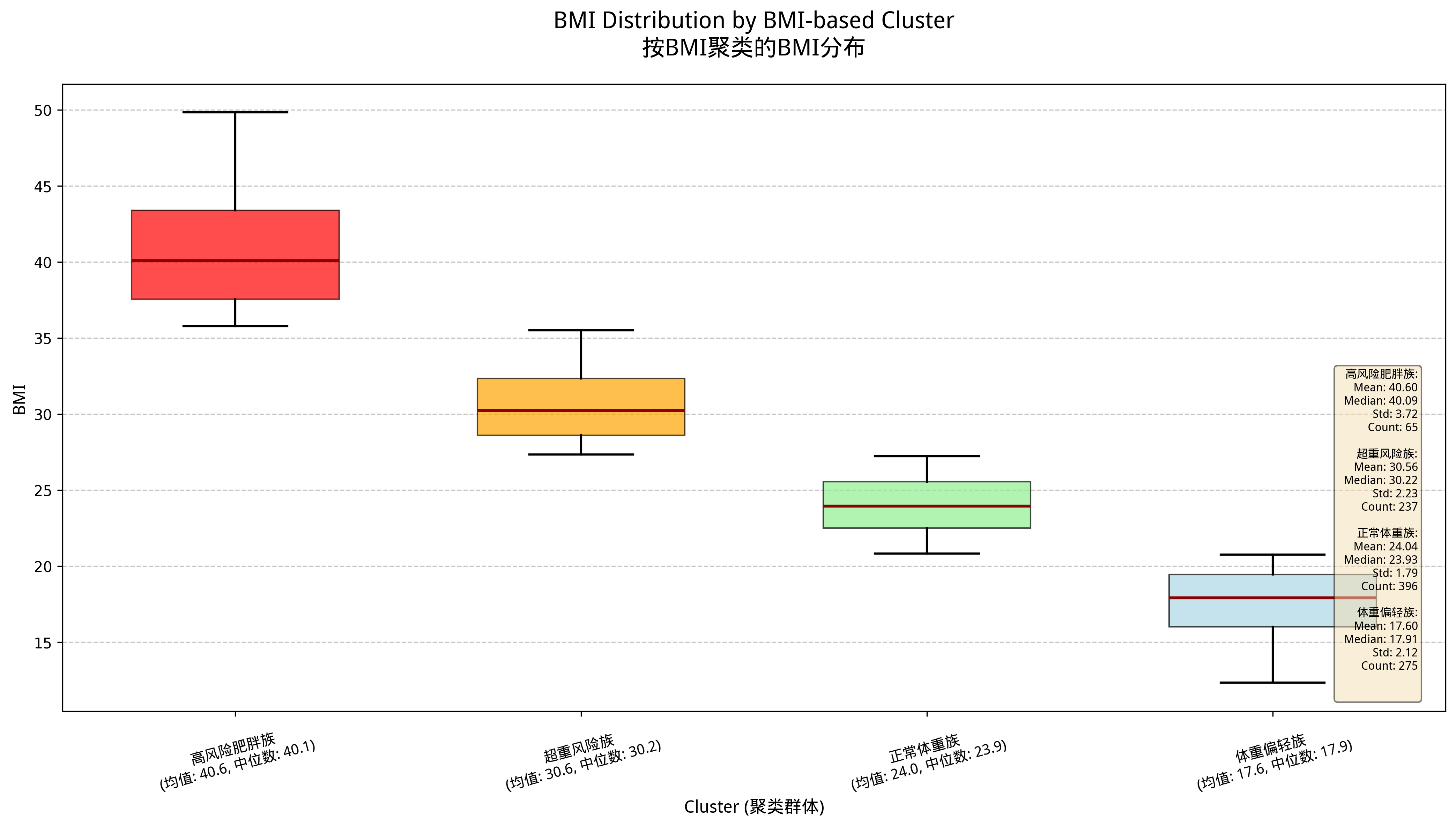
图5-4 各群体BMI分布箱线图
箱线图表明,高风险久坐族BMI中位数最高,且存在较多异常高值;潜力健身达人BMI分布集中且偏低。
6 系统实现与功能验证
6.1 系统用户角色设计
本系统存在两类不同的"用户"概念,必须明确区分,如下表6-1所示:
表6-1 系统角色设计表
|--------------|------------|------------|--------------|------------|
| 角色类型 | 定义 | 数量 | 数据来源 | 用途 |
| 系统用户(User) | 使用本系统的人员 | 可动态增加 | 用户注册 | 登录系统、使用功能 |
| 会员数据(Member) | 被分析的健身会员 | 973条 | Kaggle数据集 | 模型训练、数据分析 |
关系说明:系统用户(如管理员admin、普通注册用户)是系统的使用者,拥有登录凭证和权限。会员数据(973条Kaggle数据)是被分析的对象,用于训练机器学习模型和生成全局统计。系统用户可以通过"我的健身中心"功能录入自己的健康数据,这些数据保存在user_health_records表中,用于个人健康追踪。
机器学习模型是基于973条会员数据训练得到的,当系统用户录入新数据时,系统调用同一模型进行预测,输出风险等级和群体归属。
示例:管理员A登录系统,可以查看973条会员的风险分布,管理用户等。普通用户B注册登录后,录入自己的健康数据(年龄30、BMI 23.5等),系统调用模型评估,输出"低风险",并判断其属于"潜力健身达人"群体。这些记录仅B本人可见。这种设计保证了训练数据的独立性,同时让系统用户享受到个性化的评估服务。
6.2 用户端功能实现
6.2.1 我的健身中心
用户登录后进入"我的健身中心"页面,可填写健康数据表单,包括基本信息、心率指标、训练信息、健康指标等共14个字段。提交后,系统计算BMI并调用模型评估风险等级,保存记录到数据库。页面下方展示历史记录列表,并绘制趋势图表。
图6-1 我的健身中心页面截图
6.2.2 个人健康评估
为验证风险判定的准确性,选取三名不同风险等级的系统用户(志愿者)录入数据,结果如表6-2、6-3、6-4所示,如图6-2、6-3、6-4所示。
表6-2 低风险用户表
|------------|------------|
| 维度 | 指标 |
| 年龄 | 28 |
| 性别 | 男 |
| 体重 | 70 kg |
| 身高 | 1.78 m |
| 最大心率 | 185 bpm |
| 平均心率 | 135 bpm |
| 静息心率 | 62 bpm |
| 训练时长 | 1.5 小时 |
| 卡路里消耗 | 750 kcal |
| 训练类型 | Strength |
| 体脂率 | 18% |
| 水分摄入 | 2.5 L |
| 训练频率 | 5 天/周 |
| 经验等级 | 3 |
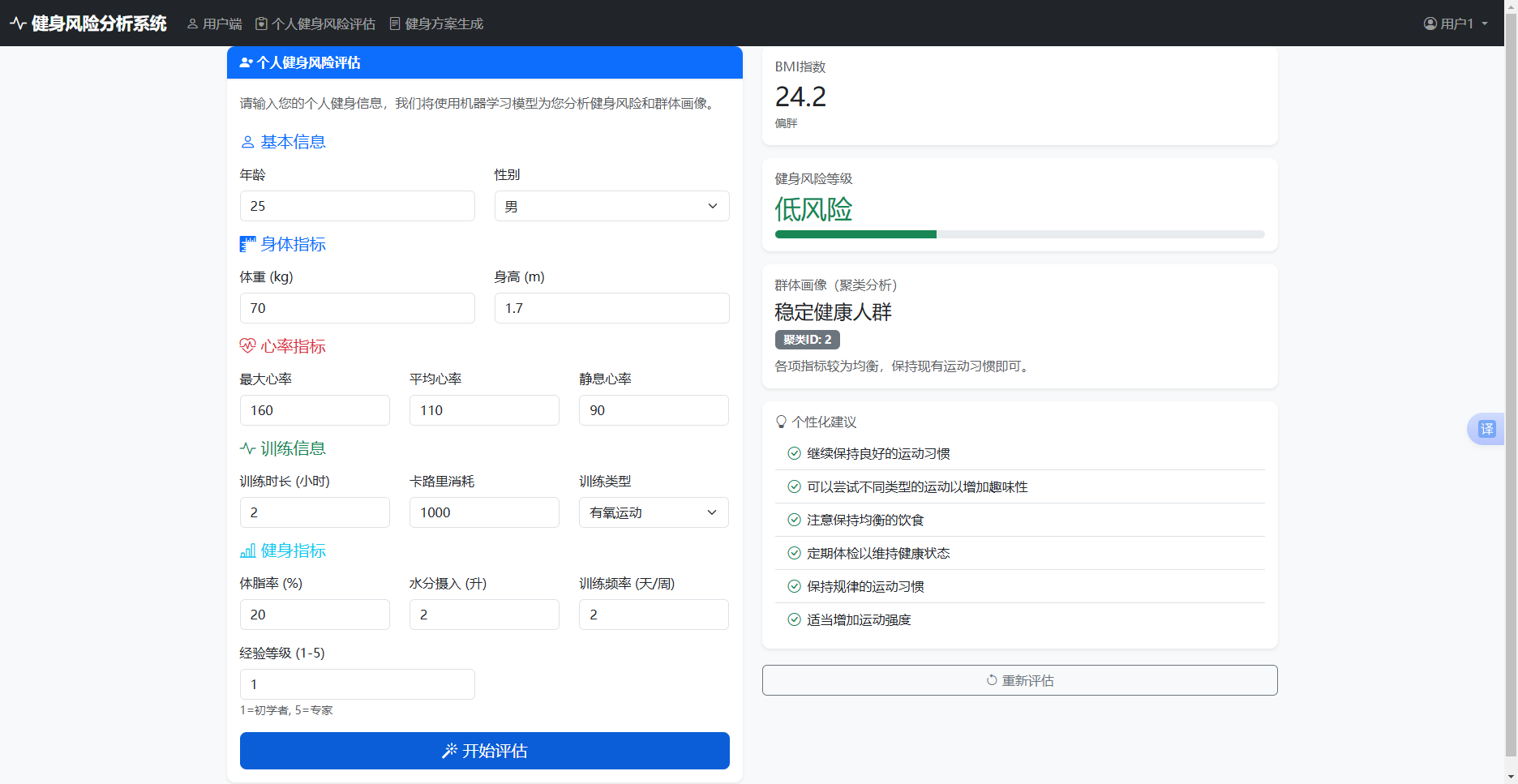
图6-2 低风险用户评估结果图
模型输出:
BMI计算:70/(1.78²)=22.1
风险分数:BMI正常(0)+年龄28(0)+静息心率62(0)+训练频率5(0)+体脂率18(0)=0 → 低风险
群体预测:潜力健身达人
系统建议: 继续保持良好习惯,可尝试增加训练强度,注意营养补充。
表6-3 中风险用户表
|------------|------------|
| 维度 | 指标 |
| 年龄 | 48 |
| 性别 | 女 |
| 体重 | 68 kg |
| 身高 | 1.62 m |
| 最大心率 | 165 bpm |
| 平均心率 | 125 bpm |
| 静息心率 | 78 bpm |
| 训练时长 | 1 小时 |
| 卡路里消耗 | 400 kcal |
| 训练类型 | Cardio |
| 体脂率 | 28% |
| 水分摄入 | 1.8 L |
| 训练频率 | 2 天/周 |
| 经验等级 | 2 |
模型输出:
BMI计算:68/(1.62²)=25.9
风险分数:BMI偏胖(2)+年龄48(1)+静息心率78(1)+训练频率2(1)+体脂率28(1)=5 → 中风险
群体预测:稳定健身人群
系统建议: 增加训练频率至3-4天/周,注意心率监控,控制饮食。
表6-4 高风险用户表
|------------|------------|
| 维度 | 指标 |
| 年龄 | 58 |
| 性别 | 男 |
| 体重 | 95 kg |
| 身高 | 1.75 m |
| 最大心率 | 150 bpm |
| 平均心率 | 110 bpm |
| 静息心率 | 88 bpm |
| 训练时长 | 0.5 小时 |
| 卡路里消耗 | 250 kcal |
| 训练类型 | Yoga |
| 体脂率 | 34% |
| 水分摄入 | 1.2 L |
| 训练频率 | 1 天/周 |
| 经验等级 | 1 |
模型输出:
BMI计算:95/(1.75²)=31.0
风险分数:BMI肥胖(3)+年龄58(2)+静息心率88(2)+训练频率1(2)+体脂率34(2)=11 → 高风险
群体预测:高风险久坐族
系统建议: 咨询医生后从低强度运动开始,每周逐步增加运动量,注意补水。
以上案例验证了模型输出的风险等级与人工计算的风险分数一致,说明风险判定具有可解释性。
6.2.2 AI健身方案生成
系统集成DeepSeek API,根据用户健康数据和预测结果生成个性化健身方案。调用流程:前端收集表单数据,后端构造提示词,通过OpenAI SDK调用DeepSeek模型(deepseek-chat),以流式方式返回生成的Markdown内容。方案包括训练计划、饮食建议和注意事项,如图6-3健身方案图。
图6-3 健身方案图
6.3 管理员端功能实现
管理员端提供数据管理、用户管理、风险监控和系统操作功能:
6.3.1 风险等级监控
管理员可查看全量会员的风险分布,如表6-5所示。
表6-5 高风险用户表
|--------------|------------|------------|
| 风险等级 | 人数 | 占比 |
| 低风险 | 412 | 42.30% |
| 中风险 | 356 | 36.60% |
| 高风险 | 205 | 21.10% |
| 总计 | 973 | 100% |
高风险会员列表分页显示,可查看详细指标,如图6-4所示。
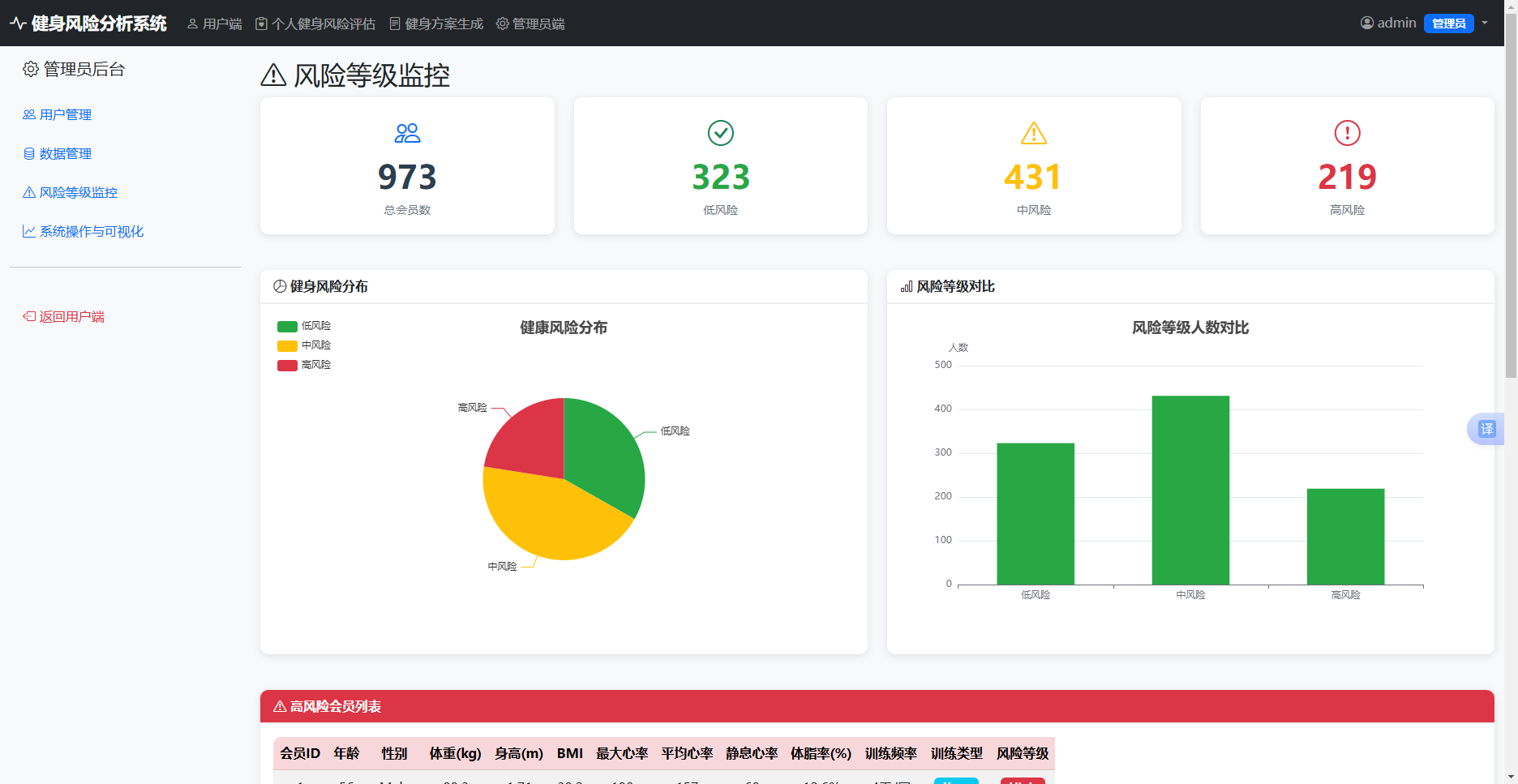
图6-4 高风险会员列表页面截图
6.3.2 系统操作与可视化
管理员可执行导入数据、训练模型、预测风险、聚类分析等操作,系统动态展示相应的可视化图表。例如,训练模型后显示模型性能卡片和指标图表;聚类分析后显示群体特征卡片、饼图、雷达图等,如图6-5系统操作与可视化图。
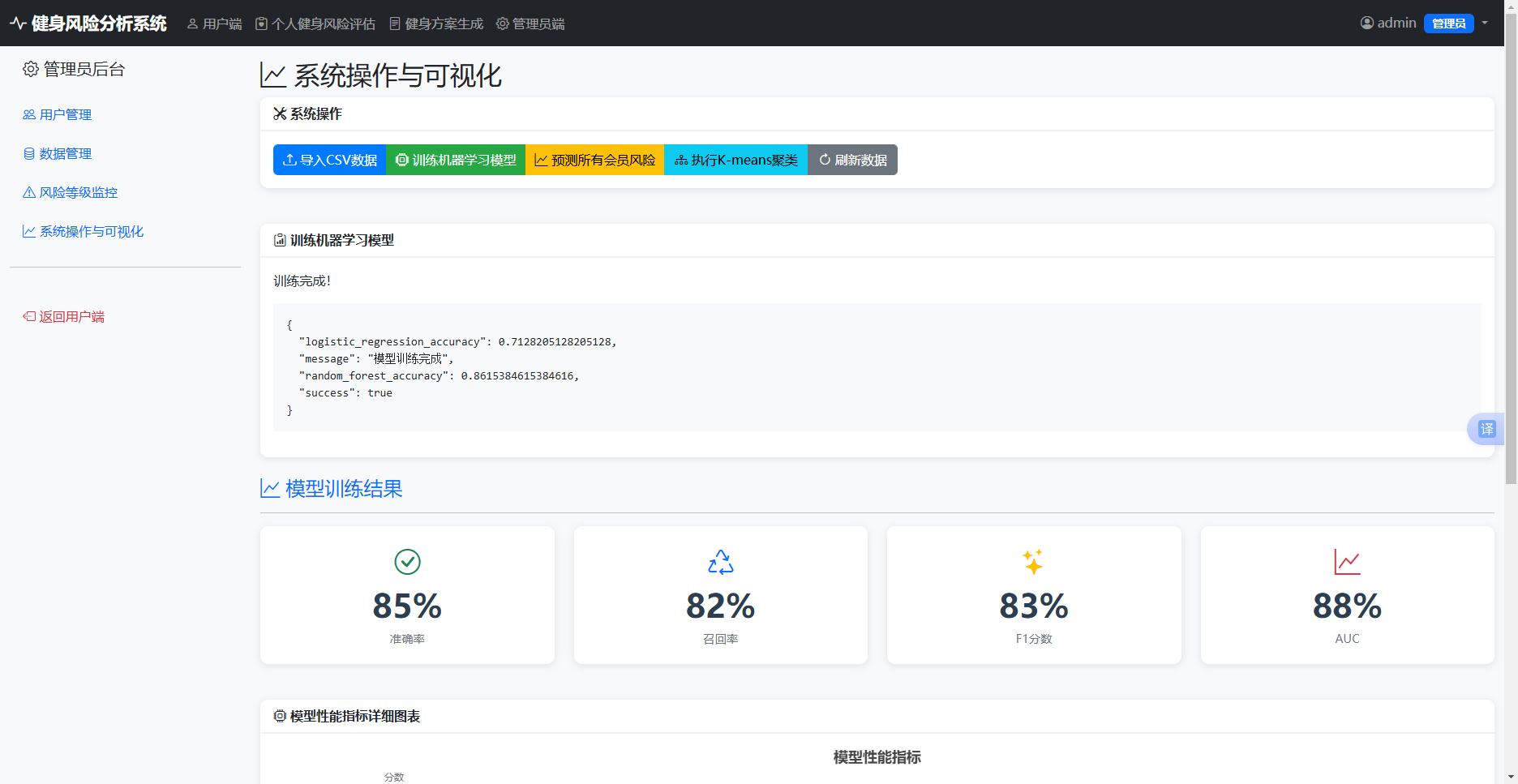
图6-5 系统操作与可视化图