什么是大模型
概述
大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。
LLM 通常指包含数百亿(或更多)参数的语言模型,
它们在海量的文本数据上进行训练,从而获得对语言深层次的理解。
目前,国外的知名 LLM 有 GPT、LLaMA、Gemini、Claude 和 Grok 等,
国内的有 DeepSeek、通义千问、豆包、Kimi、文心一言、GLM 等。
功能
LLM在训练Transformer时会尝试输入一些文本、音频、图片等信息,
然后让Transformer推理接下来跟着的应该是什么内容。
推理的结果会以概率分布的形式出现
根据前文推测出接下来的一个词语后,把这个词语加入前文,
再次交给大模型处理,推测下一个字,然后不断重复前面的过程,就可以生成大段的内容了
特点
- 巨大的规模: LLM 通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
- 预训练和微调: LLM 采用了预训练和微调的学习方法。首先在大规模文本数据上进行预训练(无标签数据),学习通用的语言表示和知识。然后通过微调(有标签数据)适应特定任务,从而在各种 NLP 任务中表现出色。
- 上下文感知: LLM 在处理文本时具有强大的上下文感知能力,能够理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。
- 多语言支持: LLM 可以用于多种语言,不仅限于英语。它们的多语言能力使得跨文化和跨语言的应用变得更加容易。
- 多模态支持: 一些 LLM 已经扩展到支持多模态数据,包括文本、图像和声音。使得它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
- 伦理和风险问题: 尽管 LLM 具有出色的能力,但它们也引发了伦理和风险问题,包括生成有害内容、隐私问题、认知偏差等。因此,研究和应用 LLM 需要谨慎。
- 高计算资源需求: LLM 参数规模庞大,需要大量的计算资源进行训练和推理。通常需要使用高性能的 GPU 或 TPU 集群来实现。
涌现能力
"涌现(Emergence)能力"通常是指:
当模型规模、数据量、参数量达到某个阈值后,
模型突然表现出的、并非被显式单独训练出来的高级能力。
在大模型领域,"涌现能力"是衡量模型是否真正具备复杂智能的重要概念。
典型涌现能力:
- 上下文学习:上下文学习能力是由 GPT-3 首次引入的。这种能力允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
- 指令遵循 :通过使用自然语言描述的多任务数据进行微调,也就是所谓的
指令微调。LLM 被证明在使用指令形式化描述的未见过的任务上表现良好。这意味着 LLM 能够根据任务指令执行任务,而无需事先见过具体示例,展示了其强大的泛化能力。 - 逐步推理 :小型语言模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然而,LLM 通过采用
思维链(CoT, Chain of Thought)推理策略,利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。据推测,这种能力可能是通过对代码的训练获得的。
基座模型
基座模型:
是通过海量数据预训练得到的、具备通用能力的大型AI模型,能够作为各种AI应用和行业模型的底层基础。
类似:
- 操作系统是软件的基础
- 地基是楼房的基础
- JVM 是 Java 程序的基础
多个应用可以只依赖于一个或少数几个大模型进行统一建设,可以极大地提高研发效率。
大模型工作原理
注意力
有选择地更多地关注突出细节,忽略当下不太重要的细节的能力。
可以访问所有 信息,但仅关注最相关的信息,有助于确保不会丢失任何有意义的细节,
同时能够有效地利用有限的内存和时间。
注意力本质上是一种"信息筛选机制"
核心思想为不是平均看所有信息,而是重点关注更重要的信息。
类似人类阅读:看到关键词会重点关注,忽略无关内容。
注意力机制
是实现"注意力"的特定算法,通过动态计算当前应该重点关注哪些信息
从数学角度讲,注意力机制计算的注意力权重反映了输入序列中每个部分对当前任务的相对重要性。然后,它应用这些注意力权重,根据输入每个部分各自的重要性来增加(或减少)输入每个部分的影响力。
注意力模型:
注意力模型(即采用注意力机制的人工智能模型)经过训练,可以通过对大型示例数据集进行监督学习或自监督学习来分配准确的注意力权重。
自注意力
自注意力机制是一种让序列中的每个元素都能动态关注其他元素,并根据相关性聚合上下文信息的机制。
为了解决RNN或LSTM存在的问题,由transformer提出实现
作用:
让模型能够直接关注全局上下文,
解决长距离依赖、信息丢失、
无法并行、语义理解弱等问题。
实现:
会使用三个向量
| 名称 | 含义 |
|---|---|
| Query(Q) | 我要找什么 |
| Key(K) | 我是什么特征 |
| Value(V) | 我的真实信息 |
通过公式计算出权重,实现注意力判断
基于 Transformer 的语言模型
Transformer 是一类基于注意力机制(Attention)的模块化构建的神经网络结 构。
给定一个序列,Transformer 将一定数量的历史状态和当前状态同时输入,然 后进行加权相加。
对历史状态和当前状态进行"通盘考虑",然后对未来状态进行 预测。
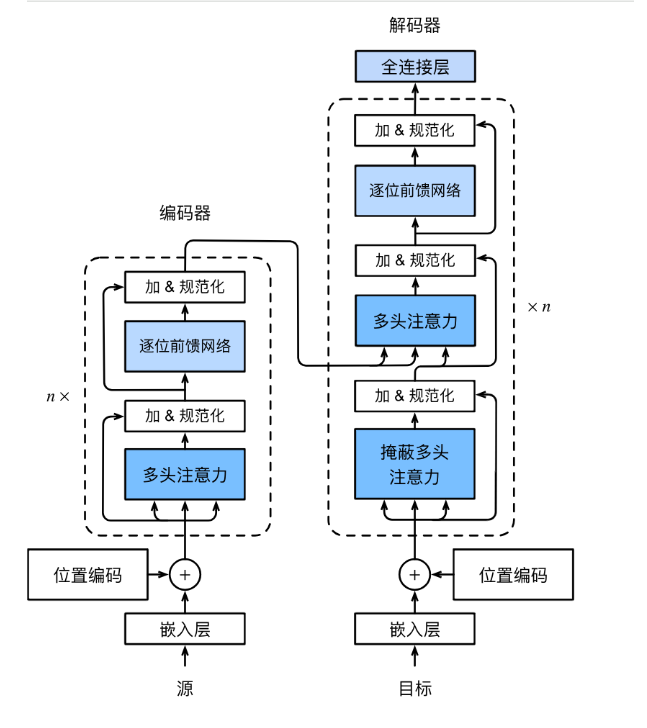
流程:
一、前置准备:输入处理
- 词嵌入(Embedding):把输入文本里的每个词,转换成固定维度的向量表示。
- 位置编码(Positional Encoding):给词向量加上位置信息,弥补纯注意力机制无法感知词语顺序的缺陷。
二、编码器(Encoder)流程
编码器由 N 个完全相同的 Encoder 层堆叠 而成,每层内部执行 2 个核心步骤:
-
多头自注意力层(Multi-Head Self-Attention)
让输入序列里的每个词,都能同时关注到序列里的所有其他词,
计算词与词之间的关联权重,捕捉全局语义关系。
后续接「残差连接 + 层归一化」,保证训练稳定。
-
前馈神经网络层(Feed-Forward Network, FFN)
对每个词的向量进行独立的非线性变换,做深度特征提取,同样接「残差连接 + 层归一化」。
编码器最终输出的,是包含全局语义信息的「上下文向量」,会作为后续解码器的输入。
三、解码器(Decoder)流程
解码器同样由 N 个完全相同的 Decoder 层堆叠 而成,每层内部执行 3 个核心步骤:
-
带掩码的多头自注意力层(Masked Multi-Head Self-Attention)
只能让当前词关注到它之前已经生成的词
,防止模型 "提前看到" 还未生成的内容,保证生成过程符合逻辑。
后续接「残差连接 + 层归一化」。
-
编码器 - 解码器注意力层(Encoder-Decoder Attention)
让解码过程中的每个词,都能关注到编码器输出的「输入序列的全局上下文信息」,
建立输入和输出的语义关联(比如翻译时,让目标语言词对应到源语言词)。
后续接「残差连接 + 层归一化」。
-
前馈神经网络层(FFN)
和解码器结构一致,对特征做深度变换,接「残差连接 + 层归一化」。
四、最终输出层
解码器的最终输出,经过线性层 + Softmax 激活函数,转换成「词表中每个词的概率」,概率最高的词就是当前步骤的输出词。
这个过程循环执行,直到生成结束符,最终得到完整的输出序列。
优势:
Transformer = 同时看所有词 + 疯狂计算词与词之间的关系(自注意力) + 多层深入理解。
- 并行计算能力强:因为它同时处理所有词,不像 RNN 那样必须按顺序,所以计算速度快很多,特别适合用强大的 GPU 来训练。
- 处理长距离依赖无敌:自注意力机制让模型能直接关注到句子中任意距离的两个词之间的关系,不管它们隔得多远。解决了 RNN 记不住开头的问题。
- 效果好:在各种自然语言处理任务(翻译、问答、摘要、文本生成等)上,效果都大幅超越了之前的模型。
- 成为大模型基石:GPT 系列、BERT、T5 等几乎所有现代顶尖的 AI 语言模型,都是基于 Transformer 架构或其变体构建的。ChatGPT 的核心就是 Transformer 的解码器部分。
大模型局限性
擅长领域
- 文本理解与生成类
- 文本理解:可完成阅读理解、文章总结、深度分析、问答系统等任务,精准捕捉文本的核心语义与逻辑。
- 文本生成:可撰写高质量文章、小说、新闻、法律合同、商业文案等内容,实现从创意到正式文稿的全流程输出。
- 长文档总结:支持会议纪要、学术论文、行业报告等长文本的信息提炼,快速生成结构化摘要。
- 结构化信息转换:可将非结构化的自然语言文本,自动转换为表格、JSON 等标准化数据格式,适配下游数据处理需求。
- 语言与信息处理类
- 机器翻译:支持多语种互译,翻译质量接近专业译员水平,代表应用包括 DeepL、Google Translate 等。
- 信息提取:可从法律文书、医学文献、财务报告等专业文档中,精准提取关键信息与核心数据,大幅降低人工梳理成本。
- 广泛知识问答:覆盖百科知识、历史、科技、医学、经济等多领域信息,可提供知识科普、专业问题解答等服务。
- 代码开发类
- 代码生成:支持 Python、JavaScript、C++ 等主流编程语言的自动编写,辅助开发者快速实现功能,代表应用包括 GitHub Copilot、Cursor 等。
- 代码调试:可自动定位代码中的 Bug、提供修复方案,同时优化代码性能与运行效率。
- 代码解释:可拆解复杂代码的运行逻辑,帮助开发者快速学习、维护遗留项目代码。
- 多模态内容生成类
- 图像识别与生成:支持生成艺术作品、设计海报、创意插画等内容,代表模型包括 DALL・E、Stable Diffusion 等。
- 语音识别与合成:可实现语音转文字(ASR)、AI 语音播报等功能,代表模型包括 Whisper、VALL-E 等。
- 视频生成:支持基于文本描述生成高质量视频,代表模型包括 Sora 等,实现从文字到动态画面的创作闭环。
这些能力的核心底层,正是因为Transformer 架构:
- 自注意力机制让 LLM 能精准捕捉文本的长距离语义关联,实现深度的文本理解;
- 并行计算能力让 LLM 可以在海量数据中高效学习,积累跨领域的知识;
- 多层堆叠的网络结构,让模型能从基础语义到复杂逻辑,实现层层递进的深度理解。
局限性
- 模型幻觉(最典型问题)
- 表现:编造事实、人名、数据、文献、逻辑,看似通顺实则完全错误;一本正经地输出虚假内容。
- 成因 :LLM 是概率生成模型,只学习语言搭配规律,不具备 "真假判断" 能力,优先保证语句流畅,而非事实准确。
- 不擅长精确计算
-
表现:复杂四则运算、大数运算、公式推导、数学推理、逻辑计算题容易出错;
简单加减尚可,多步运算、解方程、统计计算失误率高。
-
成因 :模型靠文本模式拟合,没有专门的算术运算单元,不像计算器 / 程序具备严格逻辑运算能力。
- 缺少实时性
- 表现 :知识库有时间截止点,无法获取截止日期之后的新闻、热点、实时数据、动态变化信息。
- 成因:模型训练数据是静态离线数据集,训练完成后不再自动更新。
- 知识局限性
- 表现:冷门专业知识、小众领域、深度行业细节、私人 / 内部信息、低频次知识容易答错或一无所知。
- 成因 :训练数据覆盖有限,数据越少的领域,模型能力越弱;也无法学习未公开、小众、个性化信息。
解决
幻觉:启用 RAG 检索权威资料,搭配提示词约束、结果校验,专业场景可做领域微调。
计算弱:调用计算器、Python、数理引擎等工具,模型仅做理解与解读。
无实时:对接动态知识库 + 联网搜索,获取最新信息。
知识局限:搭建私有知识库,辅以领域微调或专业模型协作。
这套流程本质就是 LLM Agent 核心开发逻辑。