本文需要读者对 ARMv8 架构、虚拟化相关技术有一定了解。
1、QEMU 的起源
QEMU 最早由 Fabrice Bellard 在 2003 年左右发起。它的名字来自 Quick Emulator,早期目标是提供一个高性能、可移植的处理器模拟器。QEMU 的核心基础是动态二进制翻译:将 guest 架构的指令翻译成 host 架构可以执行的代码,从而在一种处理器架构上运行另一种处理器架构的程序或系统。
在 QEMU 中,这套动态翻译框架后来被称为 TCG(Tiny Code Generator)。借助 TCG,QEMU 可以在 x86 主机上模拟 ARM、MIPS、PowerPC 等架构,也可以在 ARM 主机上模拟其他架构。也就是说,QEMU 首先是一个跨架构模拟器,它的价值并不依赖于某一种特定的硬件虚拟化扩展。
在纯 QEMU 模式下,guest CPU 指令由 TCG 翻译并执行,设备和整机平台也由 QEMU 自身模拟。这种纯软件模拟方式通用性很强 ,尤其适合跨架构运行和早期系统 bring-up,但 CPU 执行性能通常难以接近原生运行。
QEMU 有两种典型使用形态:一种是 user mode emulation,只模拟用户态程序运行环境,用于在不同架构之间运行单个应用程序;另一种是 system emulation,模拟一整台机器,包括 CPU、内存、中断控制器、定时器、串口、磁盘、网卡、PCI 总线等硬件资源。本文讨论的 QEMU + KVM 属于 system emulation 这一类。
由于 system emulation 需要模拟完整机器,QEMU 逐渐积累了大量设备模型和平台模型,例如 UART、磁盘控制器、网卡、PCI/PCIe 总线、中断控制器以及不同架构下的开发板或虚拟平台。这些能力使 QEMU 不只是一个 CPU 指令模拟器,也成为一个成熟的机器模拟框架。
2、KVM 的起源与设计目标
KVM(Kernel-based Virtual Machine)最早由 Qumranet 的 Avi Kivity 等人开发,并在 2007 年合入 Linux 2.6.20 主线。它出现的背景 是 Intel VT-x、AMD-V 等硬件虚拟化扩展 开始普及,通用操作系统可以借助硬件能力更高效地运行 guest OS,而不必完全依赖软件二进制翻译。
需要先明确的是,KVM 的加速能力建立在硬件辅助虚拟化 之上,而不是像 QEMU TCG 那样做跨架构指令翻译。因此,使用 KVM 时,guest 架构通常必须与 host 物理 CPU 架构相同或兼容。例如,x86 主机可以运行 x86/x86_64 guest,Arm64 主机可以运行 Arm64 guest;但 x86 主机不能通过 KVM 直接运行 Arm guest,这类跨架构场景仍然需要依赖 QEMU TCG。
KVM 的设计目标不是重新实现一个独立的 hypervisor 操作系统,而是让 Linux kernel 本身具备 hypervisor 能力。也就是说,KVM 把 Linux 内核扩展成一个可以创建 VM、创建 vCPU、进入 guest 执行、处理 VM exit、维护 guest 内存映射和虚拟化 CPU 状态的内核基础设施。
这种设计的关键价值在于复用 Linux 已有能力。虚拟机在 host 上可以被抽象为普通进程,vCPU 可以被抽象为线程;调度、内存管理、NUMA、文件系统、网络栈、设备驱动等能力都可以继续由 Linux 提供。KVM 则专注在硬件虚拟化相关的核心路径上,例如 vCPU 执行、异常陷入、二阶段地址转换、中断虚拟化等。
需要注意的是,KVM 本身并不是完整的虚拟机管理器。它通过 /dev/kvm 向用户态暴露 ioctl 接口,提供创建和运行虚拟机所需的底层能力;但虚拟主板、BIOS/firmware、磁盘、网卡、串口、显示、设备模型、镜像格式和 I/O 后端等内容,仍然需要由用户态 VMM(Virtual Machine Monitor) 实现。QEMU 正是最常见、最完整的这个用户态 VMM。
3、QEMU + KVM 架构
前两章分别介绍了 QEMU 的机器模拟能力和 KVM 的硬件辅助虚拟化能力。把二者放到 ARMv8 架构下观察,最容易混淆的不是"谁负责什么",而是 host、guest、QEMU、KVM 和 EL0/EL1/EL2 之间的关系。下面这张图先给出一个简化视角:
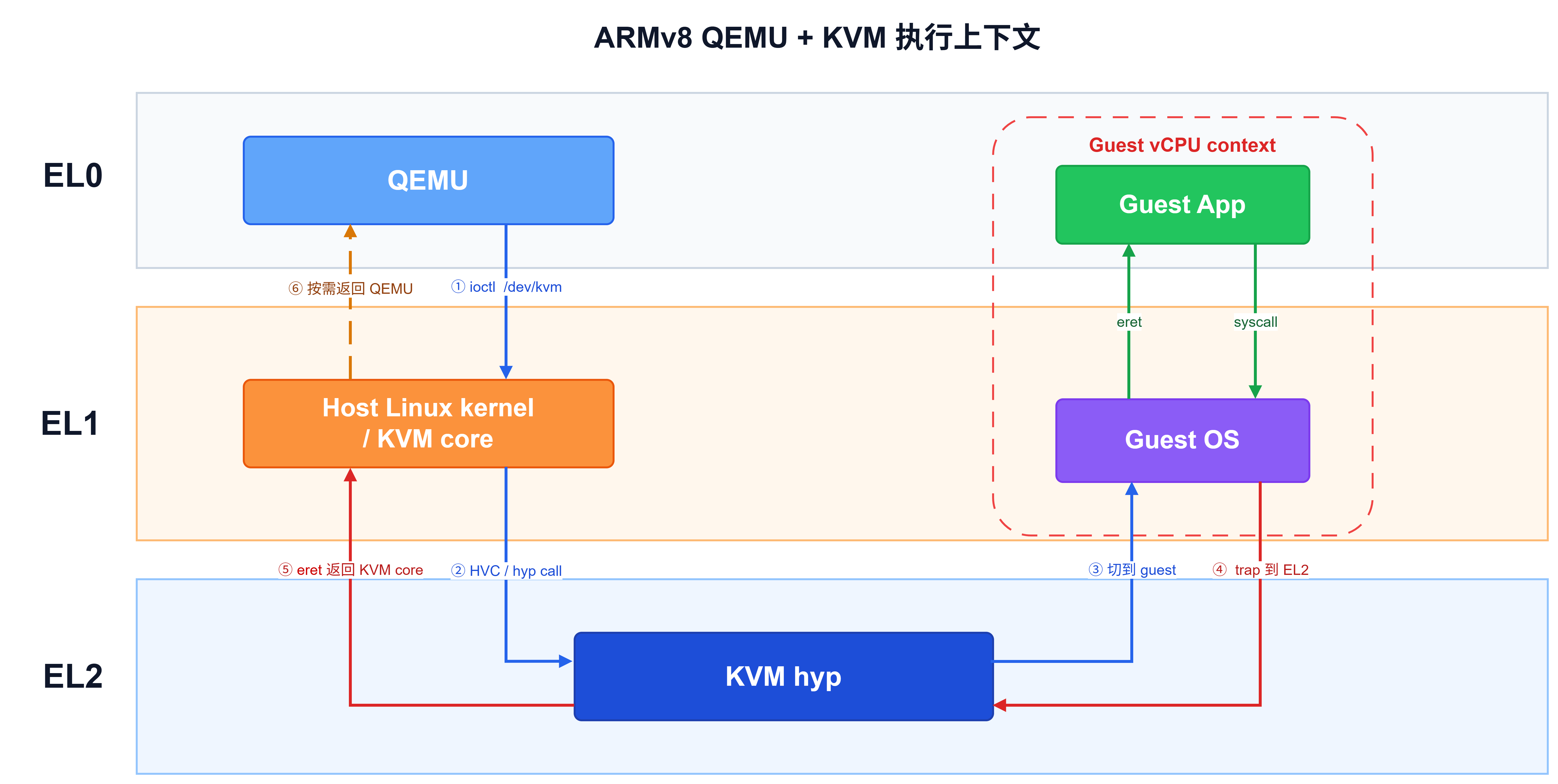
这张图想表达的核心不是完整启动流程,而是运行位置、上下文切换和主要控制流:QEMU 通过 /dev/kvm 创建 VM/vCPU,并在 vCPU fd 上发起 KVM_RUN;Host Linux kernel / KVM core 位于 EL1;KVM hyp 位于 EL2。KVM core 可以通过 HVC/hyp call 进入 EL2 的 KVM hyp,KVM hyp 再切到 guest vCPU 上下文。Guest 内部的 syscall/eret 只是在 guest EL0 和 guest EL1 之间切换;当 guest 行为触发虚拟化层介入时,控制权会通过 exception/trap 进入 EL2,再由 KVM core 判断是否需要进一步返回 QEMU。
需要注意的是,图中放在 EL1 的 Host Linux kernel / KVM core 和 Guest OS 不是两套独立的硬件层级。ARMv8 中 EL1 是 CPU 架构定义的异常等级;在同一个物理 CPU 上,EL1 会在 Host Linux kernel 和 Guest OS 之间分时承载不同上下文,二者由 KVM hyp 在必要时保存、恢复和切换。
3.1 QEMU
QEMU 位于图中的 EL0。它不是最终执行 guest 指令的主体,而是负责把一台虚拟机"组织出来":创建虚拟机进程,解析命令行参数,分配 guest RAM,构造虚拟硬件平台,加载 kernel、initrd、firmware 或 disk image,模拟 UART、virtio、PCIe 等设备,并连接 tap、socket、文件、块设备等 I/O 后端。
QEMU 与 KVM 的连接点是 /dev/kvm。QEMU 通过 ioctl 请求 KVM 创建 VM、创建 vCPU、注册 guest memory,并最终通过 KVM_RUN 命令请求运行某个 vCPU。也就是说,QEMU 发起和管理虚拟机,但 guest kernel 真正获得 CPU 执行时间时,执行路径已经进入 KVM 和硬件虚拟化机制。
3.2 KVM core
KVM core 位于图中的 Host Linux kernel / KVM core,属于 EL1 中的虚拟化执行路径,是 QEMU 通过 /dev/kvm 和一组 ioctl 进入 KVM 的主要接口层。KVM core 作为 Linux 内核的一部分,复用 Linux 的调度、内存管理、中断处理和设备驱动基础能力。虚拟机可以表现为一个 QEMU 进程,vCPU 可以表现为 QEMU 进程中的线程;这些线程由 Linux 调度到物理 CPU 上运行。
KVM core 负责维护 VM/vCPU 的内核对象、处理 QEMU 发来的 KVM ioctl、管理 vCPU 状态、注册内存区域、维护二阶段地址转换相关结构,并在 KVM_RUN 时进入虚拟化执行路径。Guest 因 exception/trap 进入 EL2 并返回 KVM core 后,KVM core 还会判断该事件是在内核中完成处理,还是通过 struct kvm_run 返回给 QEMU 用户态处理。它不是一个脱离 Linux 独立运行的完整 hypervisor,而是 Linux 内核虚拟化能力的一部分。
也就是说,KVM core 负责面向 QEMU 和 Host Linux kernel 资源管理的一侧;它会在需要执行 guest 时进入 KVM hyp,也会在 guest trap 到 EL2 后接收 KVM hyp 返回的信息并继续完成后续分发。
3.3 KVM hyp
EL2 是 ARMv8 为虚拟化提供的异常等级。KVM hyp 指的就是 KVM 中运行在 EL2 的那部分代码(hypervisor 执行层)。它不是 KVM 的全部,而是 KVM core 为了使用硬件虚拟化能力放在更高异常等级的一小段低层执行代码。
EL2 入口并不是 KVM 初始化时临时凭空创建的。如果固件或 bootloader 把 Linux 从 EL2 交进来,Arm64 早期启动代码会先把 VBAR_EL2 指向一组最小的 hyp stub 向量,随后退回 EL1 继续运行 Linux host kernel。这个早期 stub 不是 KVM hyp,它只为后续 EL1 内核保留通过 hvc #0 临时进入 EL2 的能力,用于设置或重置 VBAR_EL2、执行 soft restart 等少数操作。
KVM 初始化 EL2 路径时会复用这条通道。EL1 侧先通过 __hyp_set_vectors() 请求早期 hyp stub 修改 VBAR_EL2,把 EL2 异常入口从 stub 向量切到 KVM 的初始化向量;随后 KVM 通过 HVC 进入 EL2 初始化代码,完成 EL2 状态、页表、栈等准备工作,并在 EL2 内部把 VBAR_EL2 设置为 KVM hyp 的 host vector。完成这一步后,后续 vCPU 运行和 guest trap 才会进入 KVM hyp 的正式执行路径。
arch/arm64/kernel/hyp-stub.S 定义了 __hyp_stub_vectors,并且 HVC_SET_VECTORS 路径会写 vbar_el2;__hyp_set_vectors 则是 EL1 侧通过
hvc #0请求设置 EL2 向量的封装。https://github.com/torvalds/linux/blob/master/arch/arm64/kernel/hyp-stub.S
KVM 自己的 EL2 初始化路径里,arch/arm64/kvm/hyp/nvhe/hyp-init.S 会设置真正的 KVM hyp host vector,也就是把 VBAR_EL2 指向 KVM 的 hyp 向量。https://github.com/torvalds/linux/blob/master/arch/arm64/kvm/hyp/nvhe/hyp-init.S
当 QEMU 通过 ioctl KVM_RUN 请求运行 vCPU 时,KVM core 会进入虚拟化执行路径,随后切到 KVM hyp。KVM hyp 再负责完成必须由更高特权级处理的事情,例如切换 host/guest CPU 状态、装载 guest vCPU 状态、配置二阶段地址转换、控制 guest 对敏感系统寄存器或设备访问的 trap 行为,以及在 guest 触发需要处理的事件时重新接管控制权。
后文提到的 VM exit ,指的就是 vCPU 从 guest 执行状态退出到虚拟化控制层这一类事件。放到 Armv8/Arm64 语境下,它通常表现为 guest EL0/EL1 触发 exception 或 trap 到 EL2;是否进一步返回 QEMU 用户态,则由 KVM core 根据 exit 原因决定。
这里需要注意,KVM hyp 并不等同于一个像 Xen 那样独立管理全部系统资源的完整 hypervisor。它更像是 Linux/KVM 放在 EL2 的最小执行层:真正的资源管理、调度、设备模型和大量策略仍然分别由 host Linux 和 QEMU 完成;EL2 负责提供硬件虚拟化所需的最高特权控制点。
3.4 Guest vCPU
Guest app 和 guest OS 不运行在 QEMU 的函数调用栈里。Guest app 发起系统调用时,进入的是 guest OS;guest OS 访问自己看到的虚拟 CPU 和虚拟硬件。只有当 guest 的行为触发需要虚拟化层介入的事件,例如访问某些 MMIO 设备、触发特定系统寄存器 trap、发生虚拟中断相关事件时,控制权才会从 guest 返回 KVM hyp,再由 KVM core 判断是否需要进一步返回 QEMU 的设备模型。
这一点和纯 QEMU TCG 不同。TCG 模式下,guest EL0/EL1 是 QEMU 软件模拟出来的 CPU 状态,翻译后的代码运行在 host EL0 的 QEMU 进程中;QEMU + KVM 模式下,guest kernel 则真实运行在 ARM 硬件 EL1,只是由 EL2 管控,并通过 stage-2 translation、trap 控制和虚拟中断机制实现隔离。
从 guest 自己的视角看,它像是在一台真实机器上运行:guest app 在 guest EL0,guest kernel 在 guest EL1。区别在于,这个 guest EL1 上下文由 KVM/EL2 管控,并通过二阶段地址转换(stage-2)、trap 控制和虚拟中断等机制与 host 隔离。
3.5 小结
因此,QEMU + KVM 的核心可以概括为一句话:QEMU 在 EL0 组织虚拟机,KVM core 在 Host Linux kernel 中管理 VM/vCPU 和 KVM ioctl,KVM hyp 在 EL2 完成关键上下文切换和虚拟化控制,guest OS 则在受控的 guest vCPU 上下文中运行。
这一章先建立分层关系和异常等级视角。接下来再沿虚拟机生命周期看源码入口:QEMU 如何打开 /dev/kvm,如何创建 VM/vCPU,如何注册 guest memory,以及如何通过 KVM_RUN 请求 KVM 运行 guest。
4. 虚拟机生命周期与源码入口
本章以 QEMU 7.0.0-rc3 为参考版本,按照虚拟机创建、运行和退出的生命周期梳理 QEMU 与 KVM 的关键交互点。重点关注主干路径:命令行参数进入 MachineState,QEMU 初始化 machine 与 KVM accelerator,向 KVM 注册 guest RAM,创建 vCPU,设置 Arm vCPU 初始状态,最后通过 KVM_RUN 进入 guest 执行。
需要说明的是,本章不展开 QEMU 设备模型、迁移、热插拔和错误恢复等旁支流程;这些路径会影响实际运行细节,但不改变 QEMU/KVM 生命周期主线。
下面给出一个典型的 Arm64 Linux host 上启动 Arm64 Linux guest 的示例命令。示例中的 kernel、initrd 和 rootfs 路径仅用于说明参数结构,实际使用时需要替换为本机文件路径。由于本章讨论的是 QEMU + KVM,host CPU 架构需要与 guest 架构兼容;如果在 x86 host 上运行 Arm guest,则不能使用 KVM 直接加速,需要改用 TCG。
bash
qemu-system-aarch64 \
-machine virt,accel=kvm,gic-version=3 \
-cpu host \
-smp 4 \
-m 2048M \
-kernel ./Image \
-initrd ./initramfs.cpio.gz \
-append "console=ttyAMA0 root=/dev/vda rw" \
-drive if=none,file=./rootfs.ext4,format=raw,id=system \
-device virtio-blk-device,drive=system \
-netdev user,id=net0 \
-device virtio-net-device,netdev=net0 \
-nographic 这条命令与后续源码路径可以形成如下对应关系:-machine virt,accel=kvm,gic-version=3 对应 machine 创建、Arm virt board 初始化和 KVM accelerator 初始化;-cpu host 与 -smp 4 对应 CPU 对象创建、vCPU 创建和 Arm vCPU 初始化;-m 2048M 对应 guest RAM 构建和 KVM memory slot 注册;-kernel、-initrd、-append 对应 Arm 启动加载路径;-drive、virtio-blk-device、netdev 和 virtio-net-device 对应 QEMU 设备模型以及运行期可能出现的 MMIO/PIO exit 处理;-nographic 则常用于将 guest 串口控制台连接到当前终端,便于观察启动过程。
4.1 启动参数解析与虚拟平台初始化
QEMU system emulation 的启动入口位于 softmmu/vl.c。命令行参数解析后,-machine、-accel kvm、-cpu、-smp、-m、-kernel、-initrd、-drive、-netdev 等配置会进入 machine、accelerator、CPU 和设备相关对象。随后 QEMU 创建 MachineState,应用 machine 属性,并调用具体 board 的初始化函数。
源码入口主要包括 softmmu/vl.c 和 hw/core/machine.c:
c
/* softmmu/vl.c */
void qemu_init(int argc, char **argv, char **envp)
{
...
/* 根据 -machine 选择 MachineClass,并创建 current_machine。 */
qemu_create_machine(machine_opts_dict);
...
/* 将命令行中的 machine 属性应用到 MachineState。 */
qemu_apply_machine_options(machine_opts_dict);
...
/* 根据 -accel 或默认策略初始化 KVM/TCG 等 accelerator。 */
configure_accelerators(argv[0]);
...
/* 进入 board 初始化阶段。 */
qemu_init_board();
}
static void qemu_init_board(void)
{
...
/* 调用 MachineClass->init(),完成具体虚拟平台初始化。 */
machine_run_board_init(current_machine);
}
/* hw/core/machine.c */
void machine_run_board_init(MachineState *machine)
{
...
/* 让 accelerator 有机会初始化与 machine 相关的接口。 */
accel_init_interfaces(ACCEL_GET_CLASS(machine->accelerator));
/* 对 Arm virt machine 来说,这里会进入 hw/arm/virt.c:machvirt_init()。 */
machine_class->init(machine);
} 对于 Arm virt machine,machvirt_init() 会创建虚拟硬件平台,包括 CPU 对象、RAM 地址布局、GIC、timer、UART、PCIe、virtio transport、firmware/bootinfo 等。KVM 负责提供 vCPU 执行能力,但虚拟机的硬件拓扑和启动材料主要由 QEMU 在 board 初始化阶段组织。
4.2 KVM 后端初始化与 VM 创建
当选择 KVM accelerator 后,QEMU 会进入 accel/kvm/kvm-all.c:kvm_init()。该函数负责打开 /dev/kvm,检查 KVM API 版本和 capability,并通过 KVM_CREATE_VM 在内核中创建 VM 对象。
c
/* accel/kvm/kvm-all.c */
static int kvm_init(MachineState *ms)
{
...
s = KVM_STATE(ms->accelerator);
/* /dev/kvm 对应 KVM 全局设备 fd,用于 KVM_GET_API_VERSION 等全局 ioctl。 */
s->fd = qemu_open_old("/dev/kvm", O_RDWR);
if (s->fd == -1) {
fprintf(stderr, "Could not access KVM kernel module: %m\n");
ret = -errno;
goto err;
}
/* 确认用户态 QEMU 与内核 KVM 的 API 版本兼容。 */
ret = kvm_ioctl(s, KVM_GET_API_VERSION, 0);
if (ret < KVM_API_VERSION) {
...
fprintf(stderr, "kvm version too old\n");
goto err;
}
/* 查询当前 KVM 后端支持的 memory slot 数量。 */
s->nr_slots = kvm_check_extension(s, KVM_CAP_NR_MEMSLOTS);
...
do {
/* 在 /dev/kvm fd 上创建一个 VM,返回值是该 VM 对应的 vmfd。 */
ret = kvm_ioctl(s, KVM_CREATE_VM, type);
} while (ret == -EINTR);
if (ret < 0) {
fprintf(stderr, "ioctl(KVM_CREATE_VM) failed: %d %s\n", -ret,
strerror(-ret));
goto err;
}
/* 后续 KVM_CREATE_VCPU、KVM_SET_USER_MEMORY_REGION 等 VM 级 ioctl 使用该 fd。 */
s->vmfd = ret;
...
} 这里有两个层次的 fd:s->fd 是 /dev/kvm 的全局设备 fd,用于查询 API 版本和全局 capability;s->vmfd 是 KVM_CREATE_VM 返回的 VM fd,表示内核中的一个具体虚拟机实例。内存注册、vCPU 创建和 VM 级 capability 查询都会围绕 s->vmfd 展开。
4.3 Guest 内存创建与物理地址布局
Guest RAM 首先是 QEMU 用户态中的 MemoryRegion 或内存后端对象。QEMU 根据 -m、-object memory-backend-*、NUMA 等配置确定内存大小和来源,再由具体 machine 将 RAM 放入 guest 物理地址空间。KVM 在这一阶段尚未直接获得 GPA 到 host 用户态地址的映射关系。
以 Arm virt machine 为例,默认内存后端创建和 RAM 映射分别出现在 softmmu/vl.c、hw/core/machine.c 和 hw/arm/virt.c:
c
/* softmmu/vl.c */
static void qemu_init_board(void)
{
if (machine_class->default_ram_id && current_machine->ram_size &&
numa_uses_legacy_mem() && !current_machine->ram_memdev_id) {
/* 没有显式 memory-backend 时,为 machine 创建默认 RAM 后端。 */
create_default_memdev(current_machine, mem_path);
}
...
machine_run_board_init(current_machine);
}
/* hw/core/machine.c */
void machine_run_board_init(MachineState *machine)
{
if (machine->ram_memdev_id) {
/* 使用用户通过 -object memory-backend-* 指定的 RAM 后端。 */
machine->ram = machine_consume_memdev(machine, MEMORY_BACKEND(o));
}
...
machine_class->init(machine);
}
/* hw/arm/virt.c */
static void machvirt_init(MachineState *machine)
{
...
/* 将 machine->ram 挂到系统地址空间,base 即 guest 可见的 RAM 起始 GPA。 */
memory_region_add_subregion(sysmem, vms->memmap[VIRT_MEM].base,
machine->ram);
...
}这一阶段解决的是 QEMU 侧的内存组织问题:guest RAM 的大小、后端来源以及在 guest 物理地址空间中的位置。KVM 仍需要通过 memory slot 注册,才能在 vCPU 运行时建立 GPA 到 host 用户态内存的映射。
4.4 Guest 内存注册到 KVM
QEMU 通过 memory listener 监听系统地址空间中的 RAM 区域变化,并把这些区域转换成 KVM memory slot。核心路径位于 accel/kvm/kvm-all.c:kvm_memory_listener_register() 注册 listener,kvm_region_add() 处理 RAM 区域新增,kvm_set_user_memory_region() 最终向 KVM 发起 KVM_SET_USER_MEMORY_REGION。
c
/* accel/kvm/kvm-all.c */
static int kvm_init(MachineState *ms)
{
...
/* 监听系统内存地址空间,把 RAM MemoryRegion 同步给 KVM。 */
kvm_memory_listener_register(s, &s->memory_listener,
&address_space_memory, 0, "kvm-memory");
...
}
void kvm_memory_listener_register(KVMState *s, KVMMemoryListener *kml,
AddressSpace *as, int as_id, const char *name)
{
...
/* RAM 区域新增或删除时,分别进入 kvm_region_add()/kvm_region_del()。 */
kml->listener.region_add = kvm_region_add;
kml->listener.region_del = kvm_region_del;
memory_listener_register(&kml->listener, as);
}
static void kvm_region_add(MemoryListener *listener,
MemoryRegionSection *section)
{
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
memory_region_ref(section->mr);
/* 将 MemoryRegionSection 转换成 KVM slot。 */
kvm_set_phys_mem(kml, section, true);
}
static void kvm_set_phys_mem(KVMMemoryListener *kml,
MemoryRegionSection *section, bool add)
{
MemoryRegion *mr = section->mr;
void *ram;
...
/* 非 RAM 区域通常不注册为 KVM memory slot。 */
if (!memory_region_is_ram(mr)) {
return;
}
/* host 用户态虚拟地址,KVM 后续通过该地址访问 backing memory。 */
ram = memory_region_get_ram_ptr(mr) + mr_offset;
...
mem->memory_size = slot_size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(mr);
/* 向内核 KVM 注册 GPA -> userspace_addr 的映射关系。 */
err = kvm_set_user_memory_region(kml, mem, true);
}
static int kvm_set_user_memory_region(KVMMemoryListener *kml,
KVMSlot *slot, bool new)
{
struct kvm_userspace_memory_region mem;
mem.slot = slot->slot | (kml->as_id << 16);
mem.guest_phys_addr = slot->start_addr;
mem.userspace_addr = (unsigned long)slot->ram;
mem.memory_size = slot->memory_size;
mem.flags = slot->flags;
/* VM 级 ioctl:把一个 guest 物理地址区间注册为 KVM memory slot。 */
ret = kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
...
}memory slot 的关键含义是:QEMU 告诉 KVM 某段 guest 物理地址范围对应哪段 host 用户态内存。QEMU 负责分配、维护和命名这些内存区域;KVM 负责在 vCPU 执行时利用这些信息建立二阶段地址转换所需的映射。
4.5 vCPU 创建与运行状态共享区映射
VM fd 创建完成后,QEMU 会为每个虚拟 CPU 创建对应的 KVM vCPU。QEMU 7.0.0-rc3 中的主路径是 vCPU 线程调用 kvm_init_vcpu():该函数调用 kvm_get_vcpu(),最终通过 KVM_CREATE_VCPU 创建内核 vCPU 对象,并把 vCPU fd 保存到 CPUState::kvm_fd。
c
/* accel/kvm/kvm-accel-ops.c */
static void *kvm_vcpu_thread_fn(void *arg)
{
CPUState *cpu = arg;
...
/* vCPU 线程启动后,为当前 CPUState 创建或取得 KVM vCPU fd。 */
r = kvm_init_vcpu(cpu, &error_fatal);
...
do {
if (cpu_can_run(cpu)) {
/* vCPU 线程循环调用 kvm_cpu_exec(),实际进入 KVM_RUN。 */
r = kvm_cpu_exec(cpu);
}
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));
...
}
/* accel/kvm/kvm-all.c */
static int kvm_get_vcpu(KVMState *s, unsigned long vcpu_id)
{
...
/* 在 vmfd 上创建 vCPU,返回值是该 vCPU 的 fd。 */
return kvm_vm_ioctl(s, KVM_CREATE_VCPU, (void *)vcpu_id);
}
int kvm_init_vcpu(CPUState *cpu, Error **errp)
{
...
ret = kvm_get_vcpu(s, kvm_arch_vcpu_id(cpu));
cpu->kvm_fd = ret;
cpu->kvm_state = s;
cpu->vcpu_dirty = true;
/* 查询 struct kvm_run 共享页大小。 */
mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0);
/* mmap vCPU fd,得到 QEMU 与 KVM 共享的 struct kvm_run 区域。 */
cpu->kvm_run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE,
MAP_SHARED, cpu->kvm_fd, 0);
...
/* 进入架构相关 vCPU 初始化,例如 Arm 的 KVM_ARM_VCPU_INIT。 */
ret = kvm_arch_init_vcpu(cpu);
} KVM_CREATE_VCPU 返回的是 vCPU fd,后续寄存器同步、KVM_RUN 和 VM exit 信息读取都围绕该 fd 展开。struct kvm_run 是 QEMU 与 KVM 之间共享的运行状态页,KVM 在 VM exit 时通过该区域向 QEMU 返回 exit_reason 和 exit 相关参数。
4.6 Arm vCPU 初始化与寄存器同步
vCPU fd 只表示内核中已经创建了一个 vCPU 对象。真正运行 guest 之前,QEMU 还需要初始化 Arm vCPU 类型、特性位、启动状态,并把 QEMU CPUState 中维护的寄存器状态同步到 KVM。
Arm vCPU 初始化入口主要位于 target/arm/kvm64.c 和 target/arm/kvm.c:
c
/* target/arm/kvm64.c */
int kvm_arch_init_vcpu(CPUState *cs)
{
ARMCPU *cpu = ARM_CPU(cs);
...
memset(cpu->kvm_init_features, 0, sizeof(cpu->kvm_init_features));
/* secondary CPU 可通过该特性以 powered-off 状态启动。 */
if (cs->start_powered_off) {
cpu->kvm_init_features[0] |= 1 << KVM_ARM_VCPU_POWER_OFF;
}
/* 使用内核 KVM 提供的 PSCI 0.2 支持。 */
if (kvm_check_extension(cs->kvm_state, KVM_CAP_ARM_PSCI_0_2)) {
cpu->psci_version = QEMU_PSCI_VERSION_0_2;
cpu->kvm_init_features[0] |= 1 << KVM_ARM_VCPU_PSCI_0_2;
}
...
/* 发起 KVM_ARM_VCPU_INIT,把 target 和 features 传给 KVM。 */
ret = kvm_arm_vcpu_init(cs);
...
}
/* target/arm/kvm.c */
int kvm_arm_vcpu_init(CPUState *cs)
{
ARMCPU *cpu = ARM_CPU(cs);
struct kvm_vcpu_init init;
init.target = cpu->kvm_target;
memcpy(init.features, cpu->kvm_init_features, sizeof(init.features));
return kvm_vcpu_ioctl(cs, KVM_ARM_VCPU_INIT, &init);
} 在 vCPU 进入运行路径前,QEMU 还会通过 KVM_SET_ONE_REG 把核心寄存器、PC、PSTATE、系统寄存器等状态写入 KVM:
c
/* target/arm/kvm64.c */
int kvm_arch_put_registers(CPUState *cs, int level)
{
ARMCPU *cpu = ARM_CPU(cs);
CPUARMState *env = &cpu->env;
struct kvm_one_reg reg;
int i, ret;
for (i = 0; i < 31; i++) {
/* 同步 X0-X30 通用寄存器。 */
reg.id = AARCH64_CORE_REG(regs.regs[i]);
reg.addr = (uintptr_t)&env->xregs[i];
ret = kvm_vcpu_ioctl(cs, KVM_SET_ONE_REG, ®);
if (ret) {
return ret;
}
}
...
/* 同步 guest 启动或恢复时的 PC。 */
reg.id = AARCH64_CORE_REG(regs.pc);
reg.addr = (uintptr_t)&env->pc;
ret = kvm_vcpu_ioctl(cs, KVM_SET_ONE_REG, ®);
...
/* 同步系统寄存器和 coprocessor register 列表。 */
write_cpustate_to_list(cpu, true);
if (!write_list_to_kvmstate(cpu, level)) {
return -EINVAL;
}
...
}因此,vCPU 创建和 vCPU 初始化是两个不同阶段:前者创建内核对象和 fd,后者定义这个 vCPU 以什么 CPU 类型、特性集合和寄存器状态开始执行。
4.7 启动镜像与设备树加载
QEMU 在启动 guest 前需要准备启动材料。对于 Arm virt machine,hw/arm/virt.c:machvirt_init() 会设置 arm_boot_info,随后调用 hw/arm/boot.c:arm_load_kernel()。该路径根据用户是否指定 firmware、kernel、initrd、dtb,选择固件启动或直接 kernel 启动。Arm virt machine 会延后最终 DTB 加载,使 machine 初始化完成后还能补充动态生成的设备树节点。
c
/* hw/arm/virt.c */
static void machvirt_init(MachineState *machine)
{
...
/* 为 Arm 启动路径准备 RAM、DTB、PSCI 和 firmware 状态。 */
vms->bootinfo.ram_size = machine->ram_size;
vms->bootinfo.loader_start = vms->memmap[VIRT_MEM].base;
vms->bootinfo.get_dtb = machvirt_dtb;
vms->bootinfo.skip_dtb_autoload = true;
vms->bootinfo.firmware_loaded = firmware_loaded;
vms->bootinfo.psci_conduit = vms->psci_conduit;
/* 加载或登记 guest 启动所需的 kernel/initrd/dtb/bootloader。 */
arm_load_kernel(ARM_CPU(first_cpu), machine, &vms->bootinfo);
/* virt machine 将最终 DTB 加载延后到 machine 初始化完成之后。 */
vms->machine_done.notify = virt_machine_done;
qemu_add_machine_init_done_notifier(&vms->machine_done);
}
/* hw/arm/boot.c */
void arm_load_kernel(ARMCPU *cpu, MachineState *ms,
struct arm_boot_info *info)
{
...
/* 从 MachineState 取得 -kernel、-append、-initrd、-dtb 等参数。 */
info->kernel_filename = ms->kernel_filename;
info->kernel_cmdline = ms->kernel_cmdline;
info->initrd_filename = ms->initrd_filename;
info->dtb_filename = ms->dtb;
if (!info->kernel_filename || info->firmware_loaded) {
/* 固件启动路径:firmware 负责后续加载或启动 guest。 */
arm_setup_firmware_boot(cpu, info);
} else {
/* 直接 kernel 启动路径:QEMU 加载 kernel/initrd 并准备 bootloader stub。 */
arm_setup_direct_kernel_boot(cpu, info);
}
...
if (!info->skip_dtb_autoload && have_dtb(info)) {
/* 通用 Arm board 可在这里把 DTB 放到 guest 可见内存中。 */
arm_load_dtb(info->dtb_start, info, info->dtb_limit, as, ms);
}
}
/* hw/arm/virt.c */
static void virt_machine_done(Notifier *notifier, void *data)
{
...
/* Arm virt machine 设置 skip_dtb_autoload,因此最终 DTB 加载在这里完成。 */
if (arm_load_dtb(info->dtb_start, info, info->dtb_limit, as, ms) < 0) {
exit(1);
}
}镜像格式解析、kernel/initrd 放置、DTB 生成或加载都属于 QEMU 的虚拟平台构建职责。KVM 不解析 guest 镜像,也不生成设备树;KVM 只在 vCPU 运行时执行已经准备好的 guest 代码。
4.8 vCPU 运行入口:KVM_RUN
当 VM、guest RAM、vCPU 和启动状态准备完成后,QEMU 的 vCPU 线程进入运行循环。核心路径是 accel/kvm/kvm-accel-ops.c:kvm_vcpu_thread_fn() 调用 accel/kvm/kvm-all.c:kvm_cpu_exec(),再通过 vCPU fd 执行 KVM_RUN。
c
/* accel/kvm/kvm-accel-ops.c */
static void *kvm_vcpu_thread_fn(void *arg)
{
...
do {
if (cpu_can_run(cpu)) {
/* 每轮可运行时进入 KVM vCPU 执行路径。 */
r = kvm_cpu_exec(cpu);
}
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));
...
}
/* accel/kvm/kvm-all.c */
int kvm_cpu_exec(CPUState *cpu)
{
struct kvm_run *run = cpu->kvm_run;
...
/* 注意,这里是个循环,会循环调用 KVM_RUN !! */
do {
if (cpu->vcpu_dirty) {
/* QEMU 侧 CPUState 有更新时,先同步到 KVM。 */
kvm_arch_put_registers(cpu, KVM_PUT_RUNTIME_STATE);
cpu->vcpu_dirty = false;
}
/* 架构相关的入 guest 前准备,例如中断、mpstate 或寄存器状态处理。 */
kvm_arch_pre_run(cpu, run);
/* 核心入口:请求 KVM 运行当前 vCPU。 */
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
/* KVM_RUN 返回后执行架构相关的收尾处理。 */
attrs = kvm_arch_post_run(cpu, run);
...
} while (ret == 0);
...
} KVM_RUN 调用进入内核后,guest 指令在硬件辅助虚拟化路径上执行。只要没有发生需要 host 处理的事件,控制流主要停留在 KVM 和 CPU 虚拟化机制中;当发生 MMIO、PIO、系统事件或架构相关 trap 时,KVM_RUN 返回 QEMU,由 QEMU 根据 exit_reason 处理。
4.9 VM Exit 处理与设备模拟
沿着 KVM_RUN 的执行路径看,VM exit 的第一站是 KVM hyp/EL2,而不是 QEMU。对于 Armv8 来说,常见来源包括 stage-2 translation fault、被配置为 trap 的系统寄存器访问、HVC/SMC、WFI/WFE 或中断相关事件。
KVM hyp 负责完成 EL2 侧的低层处理,例如保存 guest 状态、记录 trap 原因、恢复 host 侧执行环境,并把控制权交还给 KVM core。随后 KVM core 会判断该事件能否在内核中完成处理:如果可以,KVM core 可以再次进入 KVM hyp 并恢复 guest 执行;如果需要用户态设备模型或 VMM 策略参与,KVM core 会把退出原因和必要参数写入 QEMU mmap 的 struct kvm_run,并让当前 KVM_RUN ioctl 返回。
因此,"KVM 退出到 QEMU"更准确地说,是 KVM_RUN 系统调用返回到 QEMU 的 vCPU 线程。QEMU 并不是被 KVM hyp 直接调用;在此之前,QEMU 的 vCPU 线程一直 阻塞 在 ioctl(vcpu_fd, KVM_RUN) 中。一次需要用户态处理的 exit 可以概括为:
text
QEMU vCPU thread
-> ioctl(vcpu_fd, KVM_RUN)
-> KVM core
-> KVM hyp / EL2
-> guest EL0/EL1 executes
<- exception/trap to EL2
<- return to KVM core
<- ioctl(KVM_RUN) returns if userspace handling is required KVM_RUN 返回后,QEMU 会查看 struct kvm_run 中的 exit_reason,决定接下来如何处理。常见场景包括 MMIO 访问、PIO 访问、系统事件、调试事件、内部错误等。
在 kvm_cpu_exec() 中可以看到类似的分发逻辑:
c
/* accel/kvm/kvm-all.c */
int kvm_cpu_exec(CPUState *cpu)
{
...
switch (run->exit_reason) {
case KVM_EXIT_IO:
/* PIO exit:转发到 QEMU 的 I/O address space。 */
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
ret = 0;
break;
case KVM_EXIT_MMIO:
/* MMIO exit:根据 GPA 分发到对应 MemoryRegion 或设备模型。 */
address_space_rw(&address_space_memory,
run->mmio.phys_addr, attrs,
run->mmio.data,
run->mmio.len,
run->mmio.is_write);
ret = 0;
break;
case KVM_EXIT_SYSTEM_EVENT:
switch (run->system_event.type) {
case KVM_SYSTEM_EVENT_SHUTDOWN:
/* guest 请求关机。 */
qemu_system_shutdown_request(SHUTDOWN_CAUSE_GUEST_SHUTDOWN);
ret = EXCP_INTERRUPT;
break;
case KVM_SYSTEM_EVENT_RESET:
/* guest 请求复位。 */
qemu_system_reset_request(SHUTDOWN_CAUSE_GUEST_RESET);
ret = EXCP_INTERRUPT;
break;
default:
/* 交给架构相关代码处理。 */
ret = kvm_arch_handle_exit(cpu, run);
break;
}
break;
default:
/* 未在通用层处理的 exit,进入架构相关分发逻辑。 */
ret = kvm_arch_handle_exit(cpu, run);
break;
}
...
} 对于需要设备模型参与的 exit,例如访问某个由 QEMU 模拟的 MMIO 设备,QEMU 会调用对应设备模型完成读写,然后再次 进入 KVM_RUN。这也是 QEMU 和 KVM 分工最直观的地方:CPU 执行尽量留在 KVM,设备模拟和复杂 I/O 场景按需回到 QEMU。
4.10 vCPU/VM 退出与资源释放
虚拟机退出可能由管理命令、guest shutdown、guest reset、内部错误、进程退出或设备状态变化触发。KVM 相关资源的释放需要区分 vCPU 线程退出、KVM fd 生命周期和进程退出三个层次。
vCPU 线程退出路径位于 accel/kvm/kvm-accel-ops.c,vCPU 资源处理位于 accel/kvm/kvm-all.c:
c
/* accel/kvm/kvm-accel-ops.c */
static void *kvm_vcpu_thread_fn(void *arg)
{
...
do {
...
} while (!cpu->unplug || cpu_can_run(cpu));
/* vCPU 线程退出时,处理 KVM vCPU 相关资源。 */
kvm_destroy_vcpu(cpu);
cpu_thread_signal_destroyed(cpu);
...
}
/* accel/kvm/kvm-all.c */
static int do_kvm_destroy_vcpu(CPUState *cpu)
{
KVMState *s = kvm_state;
long mmap_size;
...
/* 架构相关 vCPU 清理。 */
ret = kvm_arch_destroy_vcpu(cpu);
/* 解除 struct kvm_run 共享页映射。 */
mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0);
ret = munmap(cpu->kvm_run, mmap_size);
if (cpu->kvm_dirty_gfns) {
/* 如果启用了 dirty ring,同步释放 dirty ring 映射。 */
ret = munmap(cpu->kvm_dirty_gfns, s->kvm_dirty_ring_bytes);
}
vcpu = g_malloc0(sizeof(*vcpu));
vcpu->vcpu_id = kvm_arch_vcpu_id(cpu);
vcpu->kvm_fd = cpu->kvm_fd;
/* QEMU 将 vCPU fd park 起来,以支持后续复用,而不是在这里直接 close。 */
QLIST_INSERT_HEAD(&kvm_state->kvm_parked_vcpus, vcpu, node);
...
} /dev/kvm fd 和 VM fd 的错误清理路径也在 kvm_init() 中可见:
c
/* accel/kvm/kvm-all.c */
static int kvm_init(MachineState *ms)
{
...
err:
if (s->vmfd >= 0) {
/* 初始化失败时关闭 VM fd。 */
close(s->vmfd);
}
if (s->fd != -1) {
/* 初始化失败时关闭 /dev/kvm fd。 */
close(s->fd);
}
g_free(s->memory_listener.slots);
return ret;
} 从生命周期角度看,QEMU 负责管理虚拟机进程、vCPU 线程、设备模型和用户态内存对象;KVM 内核对象通过 fd 与 QEMU 关联,其生命周期受 fd 引用计数和进程生命周期约束。vCPU 退出时,QEMU 会解除 struct kvm_run 等共享映射并处理 vCPU fd;VM 结束时,剩余 fd 和内核对象随 QEMU 进程退出或相应错误路径被释放。
5、设备虚拟化
5.1 设备模拟:为什么 QEMU 仍然重要
先看不使用 virtio 的设备模拟。它的前提是:guest 并不知道后端是 QEMU。Guest OS 看到的是一块被挂到虚拟总线或物理地址空间上的"设备",guest driver 按照这个设备的寄存器语义访问 MMIO/PIO 区域。对 guest 来说,这就是在操作硬件;对 QEMU 来说,这些寄存器访问会落到某个设备模型的 read/write 回调中。
以 MMIO 为例,QEMU 在虚拟平台初始化时会把某段 guest physical address 注册成 I/O memory region,并为它绑定 MemoryRegionOps。这类区域不是普通 RAM,guest 对它执行 load/store 时,KVM 无法像访问 RAM 那样直接完成访问;如果该访问需要用户态处理,当前 KVM_RUN 会返回,struct kvm_run 中给出 KVM_EXIT_MMIO 以及访问地址、长度、方向和数据。x86 上的 PIO 访问也有类似路径,对应 KVM_EXIT_IO。
c
int kvm_cpu_exec(CPUState *cpu)
{
......
switch (run->exit_reason) {
case KVM_EXIT_IO:
DPRINTF("handle_io\n");
/* Called outside BQL */
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
ret = 0;
break;
case KVM_EXIT_MMIO:
DPRINTF("handle_mmio\n");
/* Called outside BQL */
address_space_rw(&address_space_memory,
run->mmio.phys_addr, attrs,
run->mmio.data,
run->mmio.len,
run->mmio.is_write);
ret = 0;
break;
......
}
......
} QEMU 收到 exit 后,会根据访问地址在自己的地址空间模型中找到对应的 MemoryRegion,再调用设备模型注册的 read/write 回调 。真正的"模拟硬件行为"发生在这里:写 UART 发送寄存器可能变成向 stdio 或 socket 输出一个字符;读状态寄存器可能返回设备内部状态;块设备控制器收到命令后,可能进一步转成对镜像文件或块后端的读写。处理完成后,QEMU 再次进入 KVM_RUN,KVM 完成这次挂起的访问,guest driver 继续向后执行。
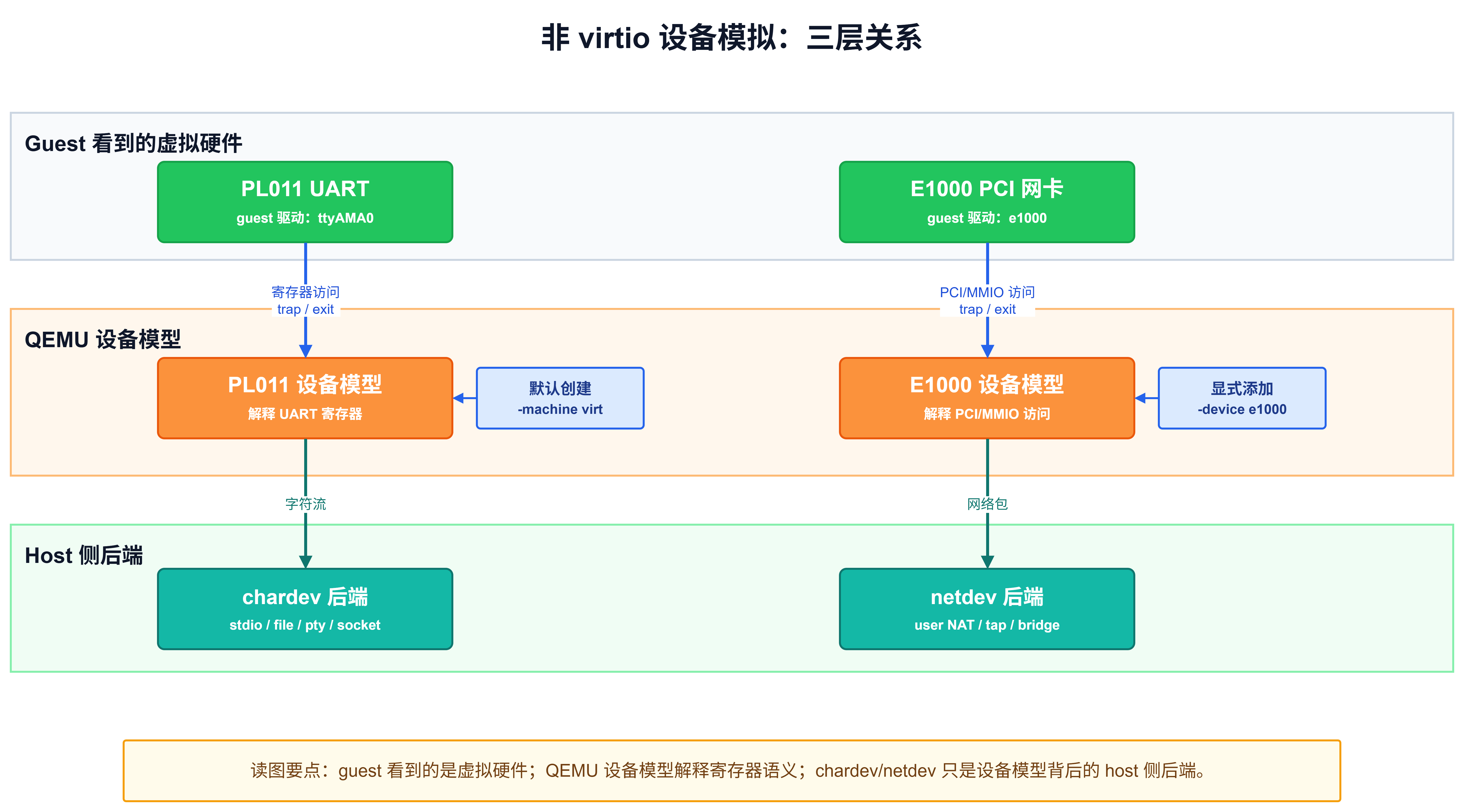
为了把这件事说清楚,可以先把一个虚拟设备拆成三层:
- 第一层是 guest 看到的虚拟硬件,例如 PL011 UART 或 E1000 网卡;
- 第二层是 QEMU 内部的设备模型,负责解释这些硬件的寄存器语义;
- 第三层是 host 侧后端,负责把设备模型产生的字节流、网络包或块 I/O 连接到 host 上的某种资源。
下面这个命令只把串口和网卡作为设备模拟案例;系统盘仍使用 virtio-blk-device,只是为了让启动命令保持简洁。
bash
qemu-system-aarch64 \
-machine virt,accel=kvm,gic-version=3 \
-cpu host \
-smp 4 \
-m 2048M \
-kernel ./Image \
-initrd ./initramfs.cpio.gz \
-append "console=ttyAMA0 root=/dev/vda rw" \
-drive if=none,file=./rootfs.ext4,format=raw,id=system \
-device virtio-blk-device,drive=system \
-serial stdio \
-netdev user,id=net0 \
-device e1000,netdev=net0 \
-display none 先看串口。qemu-system-aarch64 决定当前运行的是 AArch64 system emulator;在这个前提下,-machine virt 选择 AArch64 目标下的 virt 虚拟机器类型。可以把 virt 理解为 QEMU 提供的一块通用 Arm 虚拟主板 ,它会创建 CPU 拓扑、RAM 地址布局、GIC、timer、PCIe host bridge,以及默认的 PL011 UART 等基础虚拟硬件。
那么 guest Linux 为什么知道自己使用的虚拟串口是 PL011?因为 Arm virt machine 会为 guest 生成 device tree。命令行没有显式指定 -dtb 时,QEMU 会在内存中构造 DTB,并把它传给 guest kernel 。Guest Linux 启动早期解析 DTB,根据 compatible、reg、interrupts 等属性发现设备、匹配驱动并注册字符设备。对这个例子来说,DTB 告诉 guest:某个 MMIO 地址上有一个 arm,pl011 兼容的 UART;guest 内核匹配 PL011 驱动后,通常会注册出 ttyAMA0。-append "console=ttyAMA0 ..." 只是告诉 guest Linux:请把这个串口作为控制台使用。
QEMU 7.0.0-rc3 的 hw/arm/virt.c:create_uart() 可以看到这条路径:virt machine 创建 TYPE_PL011 设备,把第一路串口后端 serial_hd(0) 作为 chardev 属性传给它,然后把 PL011 的地址、中断和 compatible = "arm,pl011", "arm,primecell" 写入 DTB。
c
/* hw/arm/virt.c */
static void create_uart(const VirtMachineState *vms, int uart,
MemoryRegion *mem, Chardev *chr)
{
const char compat[] = "arm,pl011\0arm,primecell";
DeviceState *dev = qdev_new(TYPE_PL011);
...
qdev_prop_set_chr(dev, "chardev", chr);
...
memory_region_add_subregion(mem, base, sysbus_mmio_get_region(s, 0));
sysbus_connect_irq(s, 0, qdev_get_gpio_in(vms->gic, irq));
nodename = g_strdup_printf("/pl011@%" PRIx64, base);
qemu_fdt_add_subnode(ms->fdt, nodename);
qemu_fdt_setprop(ms->fdt, nodename, "compatible", compat, sizeof(compat));
qemu_fdt_setprop_sized_cells(ms->fdt, nodename, "reg", 2, base, 2, size);
qemu_fdt_setprop_cells(ms->fdt, nodename, "interrupts",
GIC_FDT_IRQ_TYPE_SPI, irq,
GIC_FDT_IRQ_FLAGS_LEVEL_HI);
...
} 如果用户显式指定 -dtb my.dtb,需要把它理解为"替换 QEMU 交给 guest 的硬件描述",而不是"让 QEMU 按这份 DTB 创建设备"。QEMU 仍然按照 qemu-system-aarch64、-machine virt 以及 -device 等参数创建设备模型;my.dtb 只影响 guest 启动时看到的硬件描述。
因此,自定义 DTB 必须描述 QEMU 已经创建并支持的设备模型。例如 QEMU 实际创建的是 PL011 UART,那么 DTB 中对应节点就应该描述 PL011 的 compatible、reg 和 interrupts。如果 DTB 写成某个自定义 UART,guest 可能加载自定义 UART 驱动并按另一套寄存器语义访问;但 QEMU 仍然按 PL011 设备模型处理这段 MMIO,结果就会错配。若 reg 或 interrupts 写错,guest 则可能访问错误地址或收不到中断。
再看 -serial stdio。它为第一路虚拟串口 指定 host 侧 chardev 后端 。这里的"后端"指 QEMU 设备模型最终连接的 host 资源。stdio 表示把这个虚拟串口连接到 QEMU 进程当前的标准输入/输出;如果换成 file:serial.log,就是写到文件;换成 pty,就是接到伪终端;换成 /dev/ttyS0,就是接到 host 上的物理串口设备。PL011 设备模型负责解释"guest 写这个寄存器意味着发送字符",chardev 后端只负责"这个字符最终写到哪里"。
这也能在 PL011 设备模型源码中看到。QEMU 7.0.0-rc3 的 PL011 模型位于 hw/char/pl011.c,它通过 MemoryRegionOps 注册 MMIO read/write 回调;guest 写 UART data register 时进入 pl011_write(),PL011 模型识别这是发送寄存器写入,然后才把字符交给 chardev。
c
/* hw/char/pl011.c */
static const MemoryRegionOps pl011_ops = {
.read = pl011_read,
.write = pl011_write,
.endianness = DEVICE_NATIVE_ENDIAN,
};
static void pl011_init(Object *obj)
{
...
memory_region_init_io(&s->iomem, OBJECT(s), &pl011_ops,
s, "pl011", 0x1000);
sysbus_init_mmio(sbd, &s->iomem);
...
}
static void pl011_write(void *opaque, hwaddr offset,
uint64_t value, unsigned size)
{
PL011State *s = (PL011State *)opaque;
unsigned char ch;
switch (offset >> 2) {
case 0: /* UARTDR */
ch = value;
qemu_chr_fe_write_all(&s->chr, &ch, 1);
s->int_level |= PL011_INT_TX;
pl011_update(s);
break;
...
}
} 因此,虚拟串口的完整链路可以概括为:qemu-system-aarch64 选择 AArch64 目标;-machine virt 创建 PL011 UART 并把它写入 DTB;guest Linux 解析 DTB 后加载 PL011 驱动并注册 ttyAMA0;console=ttyAMA0 让 guest 控制台使用这个串口;guest 写串口时访问 PL011 的 MMIO 寄存器;KVM 将需要用户态处理的 MMIO 访问返回 QEMU;hw/char/pl011.c 按 PL011 语义解释寄存器写入;最后 -serial stdio 指定的 chardev 后端把字符写到当前终端。
模拟网卡也是同一个思路,只是比串口多了一层网络协议栈和网络后端。-device e1000,netdev=net0 创建的是 QEMU 模拟的 Intel E1000 PCI 网卡,guest 通过 PCI 枚举发现它,并使用 e1000 驱动访问它的 PCI BAR/MMIO 寄存器;这些寄存器语义由 QEMU 的 e1000 设备模型解释。这里的 e1000 不是 host 上的物理 E1000 网卡,而是 guest 看到的虚拟网卡型号。
-netdev user,id=net0 创建的是 host 侧网络后端,id=net0 只是给这个 QEMU 后端对象取的名字,不是 host Linux 里的 eth0、ens33、tap0,也不是某个物理网卡索引。这里的 user 指 QEMU 的 user-mode networking:QEMU 在用户态提供一套简单的 NAT/协议转换能力,让 guest 发出的网络包可以通过 host 的普通 socket 和 TCP/IP 协议栈访问外部网络。最终数据当然仍会从 host 的某个真实网络出口出去,例如有线网卡、Wi-Fi 或 VPN,但这个选择由 host 网络栈和路由表决定,不是 id=net0 指定的。
因此,完整路径可以理解为:guest 应用走 guest TCP/IP 协议栈,把包交给 guest e1000 驱动;e1000 驱动访问虚拟网卡寄存器和收发队列;QEMU 的 e1000 设备模型把这些操作转换成网络包;user 后端再把这些包转换为 host 侧普通网络访问。串口里的 chardev 和网卡里的 netdev 作用类似:它们都不是 guest 看到的硬件型号,而是 QEMU 设备模型背后连接的 host 侧资源。
把串口和网卡放在一起看,区别主要在设备模型的创建方式 。PL011 串口不是不需要设备模型,而是由 virt machine 的初始化代码默认创建 ;-serial stdio 只是在这个默认串口后面接一个 chardev 后端。E1000 网卡不是 virt machine 默认设备,而是由 -device e1000,netdev=net0 显式添加 ;netdev=net0 再把它接到网络后端。两者分层是一致的:先有 QEMU 设备模型,再把设备暴露给 guest,最后通过 chardev、netdev 等后端连接 host 资源。
设备模拟,这种方式的优点是兼容性强、可塑性高。QEMU 可以模拟大量不同架构、不同总线和不同设备模型,因此非常适合系统 bring-up、调试、兼容性测试和通用虚拟平台。但它也有明显成本:控制和数据都围绕"设备寄存器语义 + QEMU 回调"展开,高频 I/O 容易产生较多 trap、KVM_RUN 返回和 QEMU 设备模型处理开销。
因此,即使 vCPU 执行已经由 KVM 加速,QEMU 仍然是 QEMU + KVM 架构中不可替代的一部分。KVM 让 guest 指令尽量直接运行在硬件上,QEMU 则负责把虚拟机所需的设备和 I/O 世界组织起来。后面的 virtio,就是在这个基础上进一步减少"像真实硬件那样逐步模拟寄存器行为"的成本。
5.2 virtio:半虚拟化设备模型
有了 5.1 的参照,virtio 的区别就更清楚了。它不是取消设备模型,而是把"模拟某个真实硬件控制器"的接口,换成一套专门面向虚拟化设计的标准设备接口。Guest 看到的仍然是设备,但驱动不再是 E1000、AHCI 这类真实硬件驱动,而是 virtio-net、virtio-blk、virtio-console 这类 virtio frontend driver。
从分层上看,virtio 仍然可以拆成三部分:guest 中的 virtio frontend driver,中间的 virtqueue,以及 QEMU 中的 virtio backend。Host 侧资源仍然可能是镜像文件、tap 设备、user-mode network、socket 等后端;真正变化的是 guest 和 QEMU 之间的通信方式。传统设备模拟围绕"寄存器语义"逐步解释访问,virtio 则围绕共享内存中的队列批量交换请求。
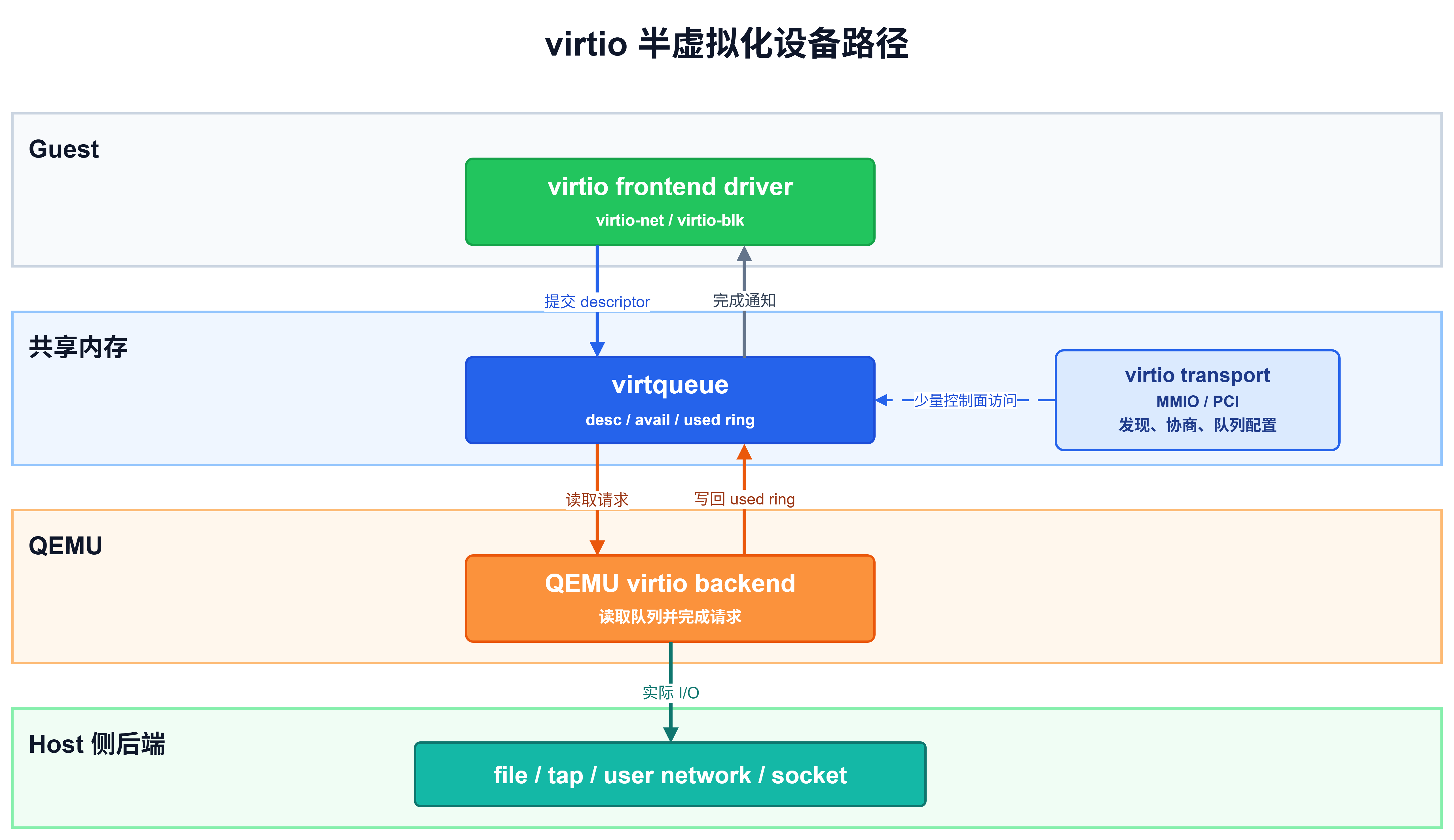
virtqueue 是 virtio 的核心。Guest frontend driver 把 I/O 请求组织成 descriptor,放入 virtqueue 的 available ring;QEMU backend 从 guest memory 中读取这些 descriptor,完成 I/O 后把结果写入 used ring,并通过中断通知 guest。控制面仍然需要少量 MMIO 或 PCI 配置访问,例如 feature 协商、队列配置和通知;但数据主体不再靠反复模拟真实设备寄存器传递,而是通过共享内存中的队列完成。
这里的"通知"通常也称为 kick 或 notify:guest frontend driver 把 descriptor 放入 virtqueue 后,需要通过 transport 提供的通知机制提醒 device/backend 侧来处理队列;backend 处理完成并写回 used ring 后,再通过中断通知 guest。也就是说,virtqueue 承载请求和结果本身,kick/notify 与 interrupt 则负责让双方知道"队列状态已经变化"。
以网卡为例,5.1 中的 E1000 可以替换成 virtio-net:
bash
-netdev user,id=net0 \
-device virtio-net-device,netdev=net0 这里的 net0 仍然是 QEMU 的网络后端对象,含义和 E1000 示例中一样;变化的是 guest 看到的设备从 E1000 PCI 网卡变成了 virtio-net 设备。Guest Linux 使用 virtio-net 前端驱动,把收发包请求放入 virtqueue;QEMU 的 virtio-net backend 读取队列,再把网络包交给 net0 指向的 host 侧后端。也就是说,host 侧出口可以不变,变化的是 guest driver 与 QEMU backend 之间的设备接口。
块设备也是同样的逻辑。前面命令里的 -device virtio-blk-device,drive=system 会让 guest 看到一块 virtio-blk 设备;guest 的 virtio-blk 驱动把读写请求放入 virtqueue;QEMU backend 再把这些请求转换成对 drive=system 所绑定镜像文件的读写。它不需要把自己伪装成某个真实 SATA 或 SCSI 控制器,因此少了大量传统控制器寄存器和命令语义的模拟成本。
virtio 设备还需要一种 transport 暴露给 guest。常见 transport 包括 virtio-mmio 和 virtio-pci:前者常见于 Arm virt 这类平台设备场景,后者则通过 PCI 设备暴露。Transport 负责设备发现、feature 协商、队列配置、通知和中断承载;virtio 设备本身的请求格式和 virtqueue 机制则保持相对统一。
Linux guest 侧的前端驱动通常在
drivers/net/virtio_net.c、drivers/block/virtio_blk.c,virtqueue/ring 的通用实现则在drivers/virtio/virtio_ring.c。QEMU 侧的通用 virtio 逻辑位于
hw/virtio/virtio.c,可以看到virtio_add_queue()、virtqueue_pop()、virtqueue_push()、virtio_queue_notify()、virtio_notify()这些核心函数;具体设备后端则分散在
hw/net/virtio-net.c、hw/block/virtio-blk.c等文件中。比如 QEMU 7.0.0-rc3 的hw/block/virtio-blk.c中,virtio_blk_handle_output()处理 guest kick 后的队列请求,virtio_blk_req_complete()再把完成结果推回 virtqueue。
这就是 virtio 比完整设备模拟更高效的关键:它牺牲的是"看起来像某个真实硬件"的透明性,换来的是更适合虚拟化的数据结构和更少的模拟路径开销。对于块设备、网卡、console、balloon、vsock 等常见设备,virtio 通常是 QEMU + KVM 中优先考虑的通用方案。下一节的 vhost,则是在 virtio 已经建立标准前后端接口之后,继续把高频数据路径从 QEMU 中移出去。
5.3 vhost:把 virtio 数据面移出 QEMU
virtio 解决的是设备接口标准化和半虚拟化问题,但它并没有消除 QEMU 的数据面开销。如果 virtio backend 仍然完全位于 QEMU 进程中,高吞吐 I/O 仍可能频繁经过用户态设备模型、QEMU 线程调度和 host 系统调用。vhost 要解决的,就是把 virtio 后端中最频繁的数据处理路径从 QEMU 进程中移出去。
需要先明确一点:vhost 不会改变 guest 看到的设备类型。Guest 看到的仍然是 virtio 设备,仍然使用 virtio-net、virtio-blk 等前端驱动,仍然通过 virtqueue 提交请求。变化发生在后端:原本由 QEMU 消费 virtqueue descriptor 的工作,可以交给 Host Linux kernel 中的 vhost 模块,也可以交给一个独立的用户态 vhost 后端进程。
以网络为例,不使用 vhost 时,guest 的 virtio-net 驱动把收发包请求放入 virtqueue,QEMU 的 virtio-net backend 读取队列,再把数据交给 tap、user 等 host 网络后端。启用 vhost-net 后,QEMU 仍然负责创建 virtio-net 设备、协商 feature、配置 virtqueue、设置通知和中断相关 fd;但真正消费 virtqueue、处理网络包并与 Host Linux kernel 网络路径交互的工作,主要由内核 vhost-net 完成。
bash
-netdev tap,id=net0,ifname=tap0,script=no,downscript=no,vhost=on \
-device virtio-net-device,netdev=net0 这个例子中,-device virtio-net-device,netdev=net0 仍然决定 guest 看到的是 virtio-net 设备;-netdev tap,...,vhost=on 则表示这个网络后端使用 tap,并启用内核 vhost-net 加速数据面。和 5.2 中的 -netdev user,id=net0 不同,user-mode network 本身是 QEMU 用户态网络栈,通常不走 vhost-net;vhost-net 更常见的搭配是 tap,因为它可以直接接入 Host Linux kernel 的网络路径。
从路径上看,vhost-net 可以理解为把 5.2 图中的 "QEMU virtio backend 读取队列" 下沉到内核。Guest 提交 descriptor、kick 设备、接收 interrupt 的 virtio 机制没有变;只是 QEMU 不再负责每个网络包的数据面处理,而是把 virtqueue、eventfd、内存映射等信息配置给内核 vhost。这样高频收发包可以少经过 QEMU 进程,降低上下文切换和用户态转发开销。
QEMU 在 vhost 场景中仍然重要。它负责虚拟设备的创建、命令行配置、feature 协商、virtqueue 初始化、内存映射关系、fd 传递、热插拔、迁移协同等控制面工作。可以把 vhost 理解为"QEMU 保留控制面,把数据面交给更合适的位置",而不是"QEMU 被完全绕过"。
vhost 也可以是用户态形态 ,这就是 vhost-user。它不是把后端下沉到内核,而是把 virtio 数据面从 QEMU 进程拆到一个独立的用户态后端进程。QEMU 和外部后端通过 Unix domain socket 运行 vhost-user 协议,把 guest memory、virtqueue、eventfd 等信息协商过去;之后由外部进程消费 virtqueue descriptor。
因此,vhost-user 并不是因为"用户态"本身更快。它的收益取决于外部后端是否有专门的数据面实现。例如网络场景中,后端可以接入 DPDK、OVS-DPDK 这类用户态高速包处理路径;存储场景中,后端可以接入 SPDK 等用户态存储栈。相比 QEMU 内置 backend,这类后端可以围绕批处理、轮询、hugepage、少拷贝路径和专用线程模型设计。若外部后端只是普通用户态程序,并没有专门优化,vhost-user 并不会天然带来性能提升。
所以,内核 vhost 和 vhost-user 的共同点是:guest 仍然使用 virtio 前端,virtqueue 协议仍然复用,QEMU 仍然负责控制面;不同点是数据面被移动到哪里。vhost-net 把数据面移到 Host Linux kernel,vhost-user 把数据面移到独立用户态后端。它们的目标都不是改变 guest 设备模型,而是减少 QEMU 主进程对高频 I/O 路径的参与。
Linux kernel 侧,vhost 通用框架主要在
drivers/vhost/vhost.c,网络数据面在drivers/vhost/net.c,用户态 ABI 则由include/uapi/linux/vhost.h定义。QEMU 侧,
hw/net/vhost_net.c负责把 virtio-net 和 vhost-net 后端连接起来,典型入口包括vhost_dev_init()、vhost_dev_start();hw/virtio/vhost.c负责通用 vhost 设备和 virtqueue 配置,例如设置 vring 地址、kick fd、call fd;
hw/virtio/vhost-user.c则实现 vhost-user 协议,可以看到vhost_user_set_mem_table()、vhost_user_set_vring_kick()、vhost_user_set_vring_call()等函数。这些函数名对应的正是前文说的"QEMU 保留控制面,把队列和通知机制交给内核或外部后端"。
因此,vhost 不是设备直通。它没有把某个真实 PCI 设备直接交给 guest,guest 也不会使用真实硬件的原生驱动。它优化的是 virtio 后端的数据路径,而不是改变 guest 的设备模型。下一节的 VFIO 设备直通,才是把物理设备或 PCIe function 受控地暴露给 guest 的另一条路线。
5.4 设备直通:绕过设备模拟路径
设备直通走的是另一条路线:不再由 QEMU 模拟一个设备,也不再通过 virtio 后端转译 I/O 请求,而是把某个物理设备或 PCIe function 受控地分配给 guest。Guest 看到的是接近真实硬件的 PCI 设备,使用该设备的原生驱动;设备的 MMIO、DMA 和中断则分别通过 stage-2 映射、IOMMU/SMMU 映射和 VFIO/KVM 中断路由接入虚拟机。
这里的关键是 VFIO。VFIO 不是一个普通设备模型,也不是 virtio 后端,而是 Linux 提供给用户态 VMM 的安全设备直通框架。QEMU 通过 VFIO 打开真实设备,获取设备 region、BAR、中断和 DMA 映射接口;VFIO 则和 IOMMU 一起保证这个设备只能访问分配给虚拟机的资源。IOMMU group 表示一组在 DMA 隔离上无法再细分的设备。做直通时,通常需要整个 IOMMU group 都处于可控状态,否则就无法保证设备隔离边界。
在 QEMU 命令行中,典型形式如下:
bash
-device vfio-pci,host=0000:65:00.0 这个参数不是创建一个"仿真网卡"或"仿真 GPU",而是让 QEMU 通过 VFIO 打开 host 上的 PCI function 0000:65:00.0,并把它作为 PCI 设备呈现给 guest。实际使用前,host 通常需要开启 IOMMU,并把该设备从原 host 驱动解绑,绑定到 vfio-pci。设备进入 guest 后,guest 使用设备的原生驱动,例如真实网卡驱动、NVMe 驱动或 GPU 驱动。
从 guest CPU 的 MMIO 访问路径看,直通最重要的变化是 stage-2 映射。设备模拟场景中,guest driver 访问某段设备 MMIO 地址时,这段 IPA 通常不会被直接映射到真实设备,而是触发 stage-2 abort 进入 KVM,再由 KVM 返回 QEMU,让 QEMU 设备模型解释这次寄存器访问。直通场景中,设备 BAR/MMIO 区域会被映射进 guest 的 stage-2 地址空间。guest driver 仍然访问自己的 guest physical address / IPA,但硬件经过 stage-1 和 stage-2 翻译后,会把这次访问送到真实设备的 MMIO 物理地址。正常路径下,这类寄存器访问不再因为 MMIO 模拟而陷入 KVM/QEMU。
DMA 路径和 CPU MMIO 路径不同。stage-2 负责 CPU 访问的第二阶段地址翻译,设备自己发起的 DMA 不走 CPU 的 stage-2 page table。直通设备 DMA 访问 guest memory 时,依赖的是 IOMMU/SMMU:QEMU/VFIO 把 guest memory 对应的 IOVA 映射关系交给 IOMMU,设备只能在这些被允许的地址范围内 DMA。这样既能让设备直接读写 guest memory,又不会让设备随意访问 host 的其他内存。
中断路径也不是"硬件中断无控制地直接进入 guest"。设备可以产生真实的 INTx、MSI 或 MSI-X,但这些中断需要通过 VFIO/KVM 建立路由,最终以 guest 可见的虚拟中断形式投递给 guest OS。普通路径中,KVM 负责把设备中断注入到目标 vCPU;在支持 interrupt remapping、posted interrupt 或 ARM GICv4/GICv4.1 的系统上,中断可以更直接地投递到 vCPU,减少软件介入,但路由和隔离关系仍然由 hypervisor 预先配置。
因此,QEMU 在直通场景中仍然参与配置和管理路径。它需要打开 VFIO group 和 device fd,读取设备 region、BAR、中断能力等信息,把设备配置空间和 BAR 暴露给 guest,并把 guest memory 和中断路由配置交给 VFIO/KVM。也就是说,QEMU 仍然负责"把真实设备安全地接入虚拟机";只是正常 MMIO、DMA 和中断数据路径不再像设备模拟那样由 QEMU 逐次解释。
这也是设备直通和前面几种路径的根本区别。QEMU 设备模拟强调兼容性,virtio 强调标准半虚拟化接口,vhost 强调把 virtio 数据面移出 QEMU;VFIO 直通则是尽量让 guest 直接驱动物理设备。它减少了虚拟设备模型和后端转译的成本,也能暴露更多硬件特性,例如特定网卡 offload、NVMe 控制器能力、GPU 加速能力等。
代价也很明显。首先,直通设备通常会被某个 guest 独占,host 和其他虚拟机不能再正常共享同一个 function;如果要共享,往往需要依赖 SR-IOV 这类硬件能力,把一个物理设备拆成多个 virtual function。其次,设备复位、热插拔、挂起恢复、快照和迁移都更复杂,因为设备内部状态不再完全由 QEMU 掌握。再次,IOMMU group 的隔离粒度、主板 ACS 支持、设备 reset 能力和驱动兼容性都会影响能否稳定直通。
Linux kernel 侧 VFIO 的核心框架位于
drivers/vfio/,PCI 设备支持位于drivers/vfio/pci/,用户态 ABI 由include/uapi/linux/vfio.h定义;不同内核版本中文件拆分会略有差异。QEMU 7.0.0-rc3 侧可以从
hw/vfio/pci.c和hw/vfio/common.c入手:vfio_realize()负责 PCI VFIO 设备初始化,vfio_get_device()通过 VFIO group 获取设备 fd,vfio_region_setup()处理设备 region/BAR 暴露,vfio_dma_map()/vfio_dma_unmap()对应 IOMMU DMA 映射,VFIO_DEVICE_SET_IRQS、vfio_add_kvm_msi_virq()、vfio_intx_enable_kvm()等路径则对应中断配置和 KVM irqfd 接入。
因此,设备直通适合低延迟、高带宽或需要完整硬件能力的场景,例如高性能网卡、NVMe 控制器、GPU、FPGA 或其他加速卡。它不适合作为所有设备的默认方案:通用性、可迁移性、可共享性和运维复杂度都不如 QEMU 模拟设备或 virtio/vhost 路径。
5.5 小结
QEMU + KVM 的设备路径可以按"通用性到性能"理解:QEMU 设备模拟最通用,virtio 提供标准半虚拟化接口,vhost 优化 virtio 数据面,VFIO 直通绕过设备模拟。实际部署中这些路径经常混用:例如串口使用 QEMU 模拟,系统盘使用 virtio-blk,网卡使用 vhost-net,而 GPU 使用 VFIO 直通。