
|-----------|
| 🚀 算法题 🚀 |
🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀
🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨
🌲 作者简介:硕风和炜,CSDN-Java领域优质创作者🏆,保研|国家奖学金|高中学习JAVA|大学完善JAVA开发技术栈|面试刷题|面经八股文|经验分享|好用的网站工具分享💎💎💎
🌲 恭喜你发现一枚宝藏博主,赶快收入囊中吧🌻
🌲 人生如棋,我愿为卒,行动虽慢,可谁曾见我后退一步?🎯🎯
|-----------|
| 🚀 算法题 🚀 |


🍔 目录
-
- [🚩 题目链接](#🚩 题目链接)
- [⛲ 题目描述](#⛲ 题目描述)
- [🌟 求解思路&实现代码&运行结果](#🌟 求解思路&实现代码&运行结果)
- [💬 共勉](#💬 共勉)
🚩 题目链接
⛲ 题目描述
给你一个正整数 n ,表示总共有 n 个城市,城市从 1 到 n 编号。给你一个二维数组 roads ,其中 roadsi = ai, bi, distancei 表示城市 ai 和 bi 之间有一条 双向 道路,道路距离为 distancei 。城市构成的图不一定是连通的。
两个城市之间一条路径的 分数 定义为这条路径中道路的 最小 距离。
返回城市 1 和城市 n 之间的所有路径的 最小 分数。
注意:
- 一条路径指的是两个城市之间的道路序列。
- 一条路径可以 多次 包含同一条道路,你也可以沿着路径多次到达城市 1 和城市 n 。
- 测试数据保证城市 1 和城市n 之间 至少 有一条路径。
示例 1:
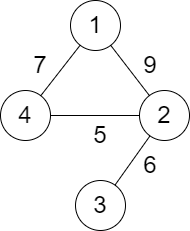
输入:n = 4, roads = \[1,2,9,2,3,6,2,4,5,1,4,7]
输出:5
解释:城市 1 到城市 4 的路径中,分数最小的一条为:1 -> 2 -> 4 。这条路径的分数是 min(9,5) = 5 。
不存在分数更小的路径。
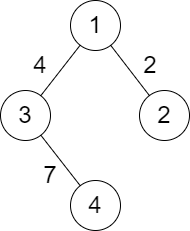
示例 2:输入:n = 4, roads = \[1,2,2,1,3,4,3,4,7]
输出:2
解释:城市 1 到城市 4 分数最小的路径是:1 -> 2 -> 1 -> 3 -> 4 。这条路径的分数是 min(2,2,4,7) = 2 。
提示:
- 2 <= n <= 105
- 1 <= roads.length <= 105
- roadsi.length == 3
- 1 <= ai, bi <= n
- ai != bi
- 1 <= distancei <= 104
- 不会有重复的边。
- 城市 1 和城市 n 之间至少有一条路径。
🌟 求解思路&实现代码&运行结果
🥦 题目要求
🎯题目描述
- 给定 n 座城市,以及若干双向道路,每条道路附带距离权值;
- 一条路径的得分定义为这条路径经过所有道路里的最小距离;
- 允许重复经过城市、重复走道路;
- 求从城市 1 到城市 n 的所有可行路径中,路径得分的最小值。
🎯核心隐藏结论
只要两条城市连通,连通块内任意一条边都可以被纳入某条 1~n 的路径中。因此问题等价于:找出城市 1 所在连通块内所有权值最小的边。
🥦 核心逻辑拆解
采用迭代 DFS遍历连通块,完整解题逻辑分为 4 步:
- 构建无向邻接表:道路双向通行,每个节点存储相连节点与对应道路权值;
- 标记访问节点:布尔数组记录已遍历节点,避免重复入栈造成死循环;
- 栈模拟 DFS 遍历连通块:从起点 1 出发,遍历所有和 1 连通的节点;
- 遍历同步更新最小边权:每遍历一条道路,就更新全局最小值,最终该最小值即为答案。
🎯为什么不用递归 DFS?
题目数据范围可达 (10^5) 个节点,链式连通图会造成递归深度 10 万层,触发 JVM 虚拟机栈溢出;迭代 DFS 使用堆内存存储栈容器,无深度限制,适配大数据场景。
🥦 实现代码
java
class Solution {
public int minScore(int n, int[][] roads) {
// 1. 构建邻接表,下标0空置,城市编号从1开始
List<List<int[]>> graph = new ArrayList<>();
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<>());
}
// 双向道路,两边互相添加邻接关系
for (int[] road : roads) {
int a = road[0];
int b = road[1];
int weight = road[2];
graph.get(a).add(new int[]{b, weight});
graph.get(b).add(new int[]{a, weight});
}
boolean[] visited = new boolean[n + 1];
Deque<Integer> stack = new ArrayDeque<>();
stack.push(1);
visited[1] = true;
int minRoad = Integer.MAX_VALUE;
// 迭代DFS主循环
while (!stack.isEmpty()) {
int curCity = stack.pop();
// 遍历当前城市所有相连道路
for (int[] edge : graph.get(curCity)) {
int neighbor = edge[0];
int w = edge[1];
// 更新连通块最小道路权值
minRoad = Math.min(minRoad, w);
// 未访问节点入栈,标记已访问防止重复遍历
if (!visited[neighbor]) {
visited[neighbor] = true;
stack.push(neighbor);
}
}
}
return minRoad;
}
}🥦 关键原理说明
🎯 邻接表存储无向图
道路是双向边,每条道路需要在两个城市的邻接列表中互相记录,保证 DFS 可以双向遍历。
🎯 访问标记的作用
只标记节点是否访问,而非标记边;同一节点不会重复入栈,避免循环遍历造成超时。边可以重复读取,目的是更新全局最小权值。
🎯 迭代 DFS 栈的底层区别
- 递归 DFS:使用 JVM 线程栈,内存空间小、深度受限,大数据必栈溢出;
- 迭代 DFS:ArrayDeque 存储在堆内存,内存容量大,支持十万级节点遍历。
🎯无需单独判断节点 n
题目保证 1 和 n 连通,从 1 出发遍历整个连通块一定会覆盖 n,连通块最小值天然包含合法路径的最优解。
🥦 运行效率
🎯 时间复杂度
时间复杂度(O(n + m)),n 为城市数量,m 为道路数量
- 建图:遍历全部m条道路;
- DFS 遍历:每个节点仅入栈一次,每条双向边仅访问两次;
- 所有操作均为线性遍历,无嵌套循环。
🎯空间复杂度
空间复杂度(O(n + m))
- 邻接表存储全部边,占用(O(m))空间;
- 访问数组、栈容器最多存储n个节点,占用(O(n))空间。
💬 共勉
|----------------------------------|
| 最后,我想和大家分享一句一直激励我的座右铭,希望可以与大家共勉! |

