背景
基于Python Flask的疾病数据采集与可视化大屏,旨在实现对疾病数据的采集、分析和可视化展示,为医疗领域提供决策支持和治疗方法分析。其中,关联规则算法被应用于治疗方法分析,旨在发现不同治疗方式之间的关联性和规律性,从而为医疗决策提供依据。通过大屏可视化展示,医疗从业者可以直观了解不同治疗方法之间的相关性,探索潜在的治疗方案组合,优化治疗流程,提高医疗效率和疗效。这项研究背景旨在结合数据采集、关联规则算法和可视化技术,为医疗决策提供更科学、数据驱动的支持,推动医疗信息化与智能化发展。
前端设计
HTML结构:
HTML结构包括必要的元素,如<!doctype html>、<html>、<head>、<body>,以及用于资源的各种脚本和链接元素。
CSS和JavaScript库:
页面包括对外部资源的引用,如jQuery、ECharts(用于数据可视化)和其他自定义CSS和JavaScript文件。
这些资源对于实现功能(如动态加载、数据可视化和样式设置)至关重要。
页面布局:
页面布局包括一个标题部分(<div class="head">),显示标题和天气信息。
主要内容结构在一个<div class="mainbox">中,其中包含多个以网格布局显示的部分。
动态内容:
页面使用JavaScript加载动态内容。诸如图表(ECharts库)和词云等元素是根据脚本中提供的数据动态生成的。
图表、词云和树形结构的数据定义在脚本中,使用类似JSON的结构。
交互元素:
页面包含交互元素,如工具提示、窗口调整大小时图表的动态调整,以及用于数据可视化的动画过渡。
词云和树形结构可视化具有交互功能,如悬停效果和单击事件。
响应式设计:
设计包括响应式功能,因为图表和元素会根据窗口宽度调整大小,并根据窗口宽度动态调整页面的字体大小。
页面的字体大小根据窗口宽度动态调整,以确保响应性。
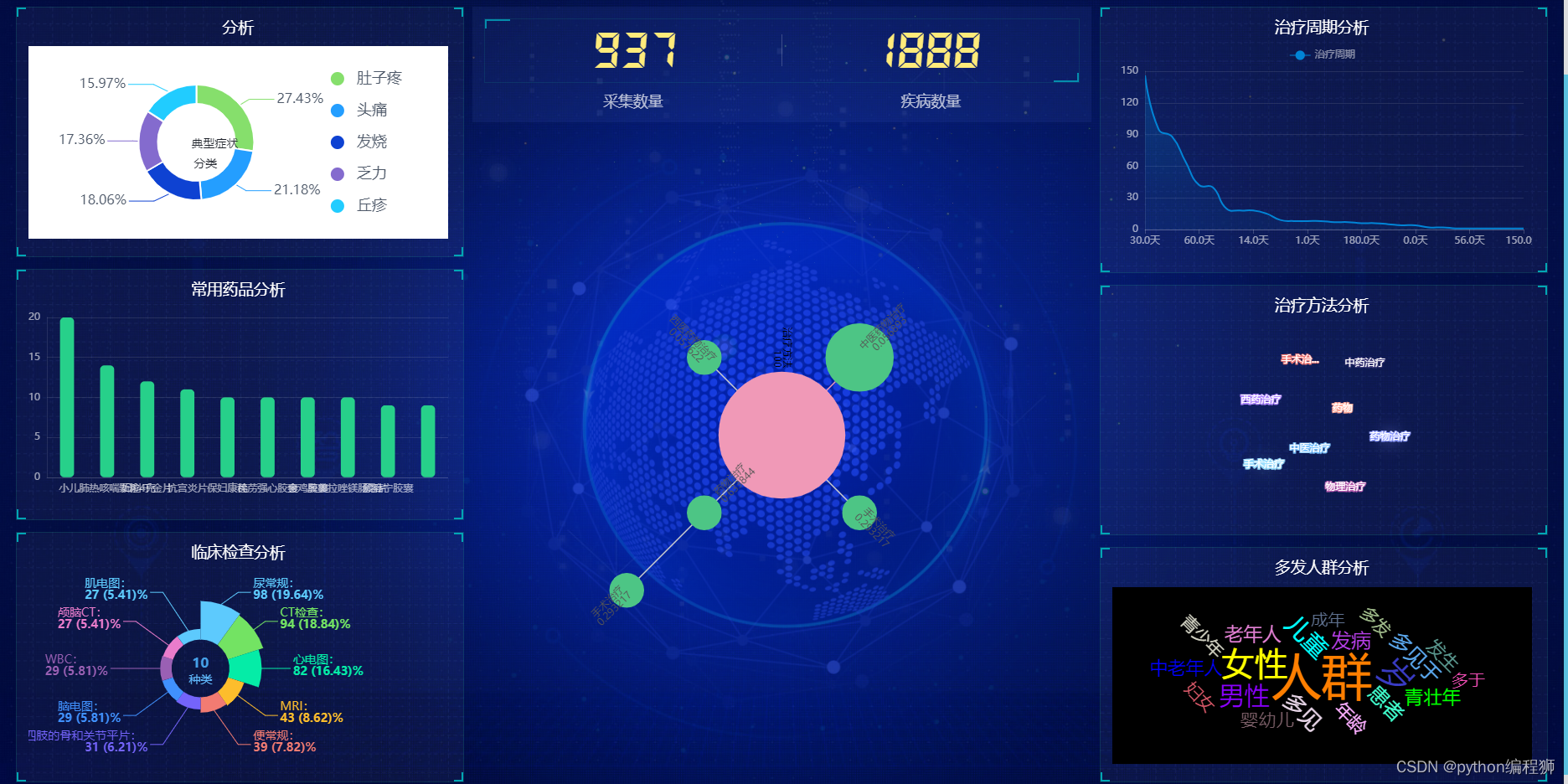
数据可视化:
包括各种类型的数据可视化,如饼图、柱状图、词云和树状结构,以便以视觉上吸引人的方式呈现数据。
关联规则算法实现
关联规则算法用于发现数据集中项目之间的关联关系,其中最常见的算法之一是Apriori算法。以下是关联规则算法的实现描述:
数据预处理:
通过读取Excel文件获取数据,并针对数据集进行清洗和处理,包括处理缺失值和对治疗方法进行处理。
数据转换:
将处理后的数据转换为适合关联规则算法的格式,这里使用mlxtend库中的TransactionEncoder将数据转换为布尔类型的数据集。
频繁项集挖掘:
使用Apriori算法来挖掘频繁项集,该算法通过设定最小支持度阈值来确定频繁项集。
针对挖掘到的频繁项集,计算支持度,并找出支持度最大和最小的频繁项集。
关联规则生成:
基于频繁项集,生成关联规则,其中关联规则的支持度和置信度是评估规则好坏的重要指标。
用户可以根据设定的最小支持度和最小置信度阈值来生成关联规则。
关联规则筛选:
可以根据关联规则的长度和支持度进行筛选,选择特定长度的规则,并根据支持度进行排序展示。
关联规则查询:
提供了查询特定项集的关联规则的功能,用户可以输入关联规则中的特定项,查找包含该项的关联规则。
算法比较:
在实现中也提到了使用FP-growth算法来查找频繁项集,可以通过比较不同算法的效果和性能来选择适合的算法。
总体而言,关联规则算法实现包括数据预处理、频繁项集挖掘、关联规则生成、关联规则筛选和查询等步骤,帮助用户发现数据集中的关联关系并进行进一步分析和应用。主要代码如下:
python
def association_rule(dataset, min_support=0.15):
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=min_support, use_colnames=True)
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))
res = frequent_itemsets
x = max(res['support'])
n = min(res['support'])
print('max:', x, 'min:', n)
return frequent_itemsets
res1 = association_rule(dataset, min_support=0.05)
print(res1)结果如下图:

大屏效果