
一、数据中台关键技术汇总
语言框架 :Java、Maven、Spring Boot
数据分布式采集 :Flume、Sqoop、kettle
数据分布式存储 :Hadoop HDFS
离线批处理计算 :MapReduce、Spark、Flink
实时流式计算 :Storm/Spark Streaming、Flink
批处理消息队列 :Kafka
查询分析 :Hbase 、Hive 、ClickHouse、Presto
搜索引擎 :Elasticsearch
数据库 :MySQL、Redis、MongoDB、Oracle、PostgreSQL、MariaDB、SQL Server、达梦
数据挖掘、机器学习 :Spark MLLib、TensorFlow、NLP(AI大模型)
二、OLAT与OLTP
OLAP(联机分析处理):
全称为 Online Analytical Processing,它强调对大量历史数据的分析与处理。OLAP系统通常用来查询多维数据库,以便观察数据的多个维度之间的关系,并进行复杂的计算和汇总。
它的主要功能包括查询、分析、预测、数据挖掘等,为用户提供灵活的数据分析和快速决策支持。
OLTP(联机事务处理):
全称为 Online Transaction Processing,它强调对数据的实时处理。
OLTP系统通常用于处理企业的日常交易数据,例如订单处理、库存管理、银行交易等。它的主要功能是支持事务和实时数据处理,为用户提供高效的交易处理服务。

二者区别:
(1)功能区别 :OLAP聚焦于数据分析和预测,为使用者提供数据挖掘和多维分析等功能,通过复杂的计算和统计分析来发现数据背后的规律。而 OLTP 更注重交易数据的实时处理,支持并发的事务处理和数据插入、更新、删除等操作。
(2)数据处理区别 :OLAP通常处理大规模的历史数据,它需要快速的数据查询和复杂的统计计算,以满足用户对数据多维分析的需求。OLTP则处理实时的事务数据,它需要高效的事务处理和快速的数据录入,以保证日常交易的正常运行。
(3)数据结构区别 :OLAP采用多维数据库结构,通过维度、度量、层次等数据元素来组织和管理数据,以便进行复杂的查询和分析。而OLTP通常采用关系数据库结构,通过表和关系来存储和管理交易数据,以支持事务的正确处理。
(4)应用场景区别 :OLAP 适用于需要进行复杂数据分析和决策的场景,例如市场营销分析、销售业绩分析、客户关系管理等。而 OLTP 适用于需要进行实时数据处理和高并发事务处理的场景,例如在线交易管理、订单处理、支付结算等。
三、数据湖三剑客
Hudi:
过分布式文件系统(HDFS或者云存储)来摄取(Ingests)、管理(Manages)大型分析型数据集,Hudi 是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使HDFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
Hudi是在大数据存储上的一个数据集,可以将 Change Logs 通过 upsert 的方式合并进 Hudi;
Hudi 对上可以暴露成一个普通的 Hive 或 Spark 的表,通过 API 或命令行可以获取到增量修改的信息,继续供下游消费;
Hudi 还保管了修改历史,支持回滚;
Hudi 内部有主键到文件级的索引,默认是记录到文件的布隆过滤器,高级的有存储到 HBase 索引提供更高的效率。
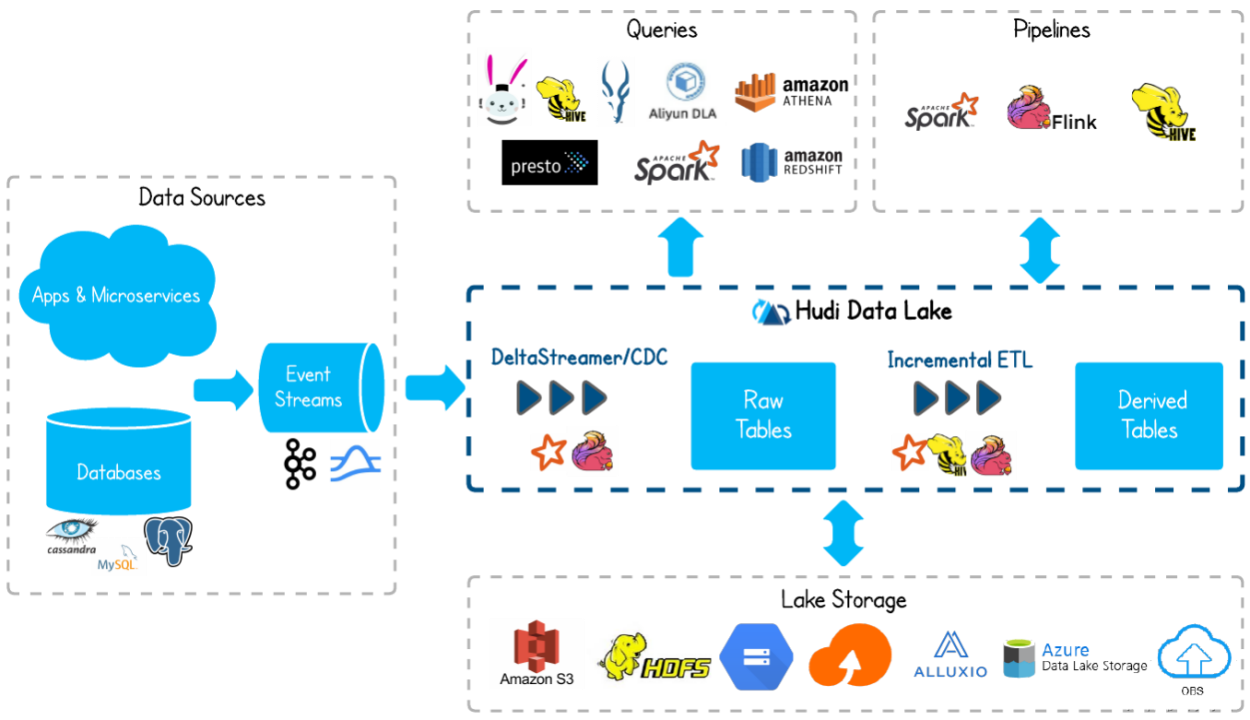
Delta Lake:
流批一体的Data Lake存储层,支持 update/delete/merge。
在数据写入方面,Delta 与 Spark 是强绑定的;在查询方面,开源 Delta 目前支持 Spark 与 Presto,但是,Spark 是不可或缺的,因为 delta log 的处理需要用到 Spark。

Iceberg:
是一种可伸缩的表存储格式,内置了许多最佳实践。
允许我们在一个文件里面修改或者过滤数据;当然多个文件也支持这些操作。
在查询方面,Iceberg 支持 Spark、Presto,提供了建表的 API,用户可以使用该 API 指定表名、schema、partition 信息等,然后在 Hive catalog 中完成建表。
四、开源技术探索
Apache Doris:
是一个现代化的基于MPP(大规模并行处理)技术的分析型数据库产品。
简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。
Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。

Open Metadata:
使用端到端元数据管理解决方案释放数据资产的价值,该解决方案包括数据发现、治理、数据质量、可观察性和人员协作。
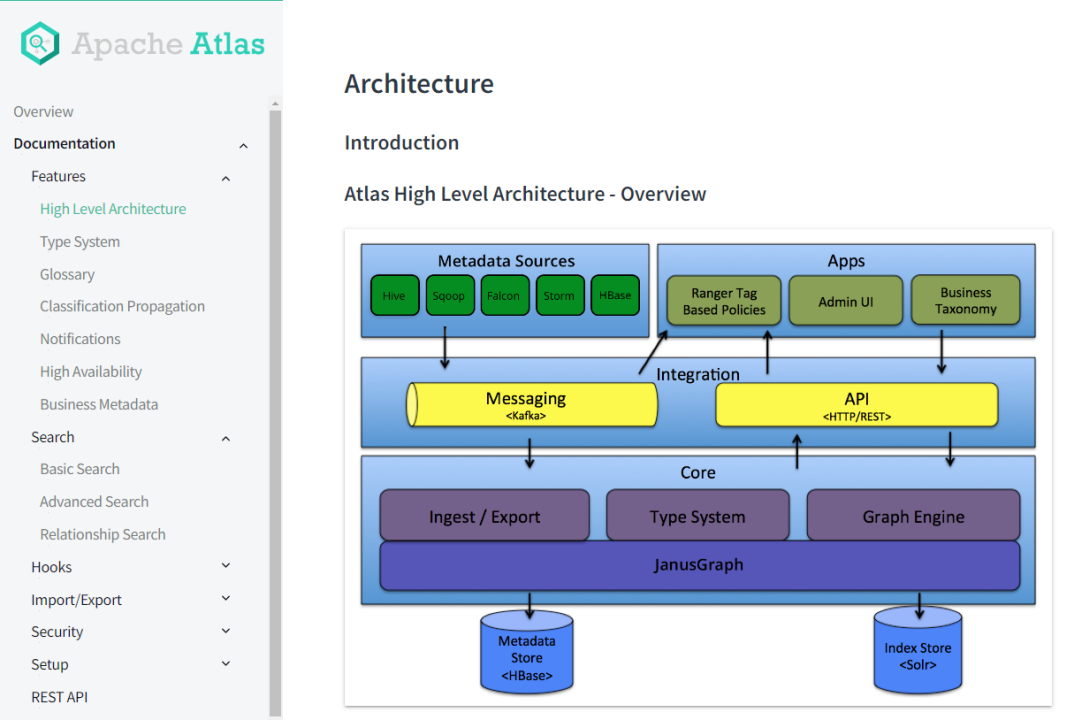
Apache Atlas:
是Apache Hadoop的数据和元数据治理的框架,是为解决Hadoop生态系统的元数据治理问题而产生的开源项目。
它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心登能力。
完结
九位数之极,本合集到现在已经到达第九篇,虽然还有很多内容想说,但是整体的架构脉络已基本上描述完毕。
接下来计划再出几篇番外,对其中的某些要点进行单项解析、功能 UI 赏析、物联网与中台、以及实际应用案例等内容。
大家也可以提提建议,对哪些板块比较感兴趣,将会优先考虑这些板块进行单项解析。
-- 欢迎点赞、关注、转发、收藏【我码玄黄】,gonghao同名