


目录
[🌊1. 研究目的](#🌊1. 研究目的)
[🌊2. 研究准备](#🌊2. 研究准备)
[🌊3. 研究内容](#🌊3. 研究内容)
[🌍3.1 softmax回归的从零开始实现](#🌍3.1 softmax回归的从零开始实现)
[🌍3.2 基础练习](#🌍3.2 基础练习)
[🌊4. 研究体会](#🌊4. 研究体会)
🌊1. 研究目的
- 理解softmax回归的原理和基本实现方式;
- 学习如何从零开始实现softmax回归,并了解其关键步骤;
- 通过简洁实现softmax回归,掌握使用现有深度学习框架的能力;
- 探索softmax回归在分类问题中的应用,并评估其性能。
🌊2. 研究准备
- 根据GPU安装pytorch版本实现GPU运行研究代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌊3. 研究内容
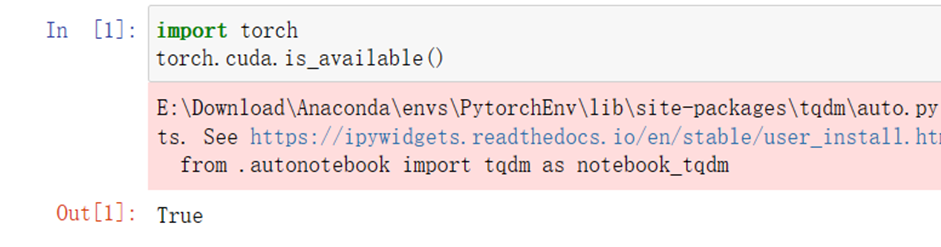
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch 以及torch.cuda.is_available() ,若返回TRUE则说明研究环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但研究运行是在CPU进行的,结果如下:
🌍3.1 softmax回归的从零开始实现
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成基本数据操作的研究代码与练习结果如下:
导入必要库和加载数据:
python
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
python
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)实现softmax运算
python
X = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
X.sum(0, keepdim=True), X.sum(1, keepdim=True)
python
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(X)
X_prob, X_prob.sum(1)
定义模型
python
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)定义损失函数
python
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y_hat[[0, 1], y]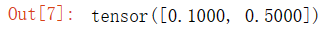
python
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)
计算分类准确率
python
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
accuracy(y_hat, y) / len(y)
python
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
evaluate_accuracy(net, test_iter)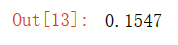
训练模型
python
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)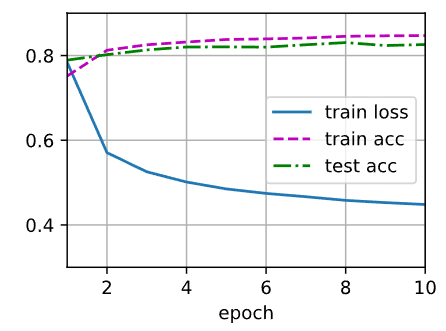
预测
python
def predict_ch3(net, test_iter, n=6):
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
🌍3.2 基础练习
1.本节直接实现了基于数学定义softmax运算的softmax函数。这可能会导致什么问题?提示:尝试计算(\exp(50))的大小。
当计算exp(50)时,可能会遇到数值溢出的问题。softmax函数的定义是通过对输入向量中的每个元素进行指数运算,然后进行归一化,使得所有元素的和为1。指数函数在输入较大时会迅速增长,当输入超过一定阈值时,指数函数的输出将变得非常大,可能超出计算机所能表示的范围。
在本节直接实现的softmax函数中,如果输入向量中的某个元素较大(例如50),那么对应的指数运算结果将变得非常大,导致数值溢出。这会导致计算结果不准确或无法表示。在实际应用中,通常会使用数值稳定的方法来计算softmax函数,以避免数值溢出的问题。常见的数值稳定方法是通过减去输入向量中的最大值来进行计算,即softmax函数的输入进行平移。
因此,在直接实现基于数学定义的softmax函数时,可能会遇到数值溢出的问题,导致计算结果不准确或无法表示。
python
import numpy as np
def softmax(x):
# 减去输入向量中的最大值,以避免数值溢出
x -= np.max(x)
# 计算指数运算
exp_x = np.exp(x)
# 归一化,计算softmax值
softmax_x = exp_x / np.sum(exp_x)
return softmax_x
# 计算 exp(50) 的 softmax 值
x = np.array([50])
softmax_value = softmax(x)
#这段代码通过减去输入向量中的最大值(在这种情况下就是50)来避免数值溢出。
#然后,使用NumPy的exp函数计算指数运算,最后进行归一化得到softmax值。
#由于采取了数值稳定的计算方法,即使输入为较大的数值(例如50),也能够正确计算softmax值。
#在这种情况下,softmax值为1,表示该元素在归一化后的向量中占比为100%。
print(softmax_value)结果:
2.本节中的函数cross_entropy是根据交叉熵损失函数的定义实现的。它可能有什么问题?提示:考虑对数的定义域。
根据提示考虑对数的定义域。交叉熵损失函数在计算中通常会涉及对数运算,而对数函数在定义域上有限制。对数函数的定义域是正实数,即输入值必须大于零。
在李沐老师的本节中,如果交叉熵损失函数的计算结果中包含负数或零,将会导致问题。这是因为对数函数在定义域之外没有定义,尝试对负数或零进行对数运算将会导致错误或异常。
特别是在计算softmax函数的交叉熵损失时,可能会遇到这样的问题。当预测值与真实值之间存在较大的差异时,交叉熵损失函数的计算结果可能会出现负数或零。这将导致对数运算无法进行,进而影响整个损失函数的计算。
为了解决这个问题,通常会在交叉熵损失函数的计算中添加一个小的平滑项,例如加上一个较小的常数(如10的-8次方)以确保避免出现负数或零。这被称为"平滑交叉熵"或"平滑对数损失"。
因此,如果在直接实现基于交叉熵损失函数的代码中,没有处理对数函数定义域的限制,可能会导致错误或异常,特别是在涉及预测值与真实值之间差异较大的情况下。
3.请想一个解决方案来解决上述两个问题。
为了解决上述两个问题,即数值溢出和对数函数定义域的限制,可以采取以下解决方案:
数值溢出问题:在计算softmax函数时,通过减去输入向量中的最大值来避免数值溢出。这样做可以确保指数函数的输入在合理的范围内,避免结果过大而导致数值溢出。这个方法在前面的回答中已经提到了。
对数函数定义域问题:在计算交叉熵损失函数时,添加一个小的平滑项。可以在对数函数的输入上加上一个较小的常数,例如(如10的-8次方),以确保避免出现负数或零。这样可以避免对数函数在定义域之外的值上计算,确保损失函数的计算结果正确。
下面是一个示例代码,展示了如何结合这两个解决方案来计算softmax函数和交叉熵损失函数:
python
import numpy as np
def softmax(x):
x -= np.max(x)
exp_x = np.exp(x)
softmax_x = exp_x / np.sum(exp_x)
return softmax_x
def cross_entropy(predicted, target):
# 添加平滑项,避免对数函数定义域的问题
smooth = 1e-8
# 计算交叉熵损失
loss = -np.sum(target * np.log(predicted + smooth))
return loss
# 假设有一个预测向量和真实标签向量
predicted = np.array([0.9, 0.1, 0.2])
target = np.array([1, 0, 0])
# 计算softmax函数的输出
softmax_output = softmax(predicted)
# 计算交叉熵损失
loss = cross_entropy(softmax_output, target)
print(loss)结果:
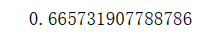
在这段代码中,我们在softmax函数中采用了减去最大值的方法,以避免数值溢出。在交叉熵损失函数中,添加了平滑项(如10的-8次方)以确保避免对数函数的定义域问题。通过结合这两个解决方案,可以在计算softmax函数和交叉熵损失函数时避免数值溢出和对数函数定义域的限制,从而得到准确的计算结果。
4.返回概率最大的分类标签总是最优解吗?例如,医疗诊断场景下可以这样做吗?
在一些情况下,返回概率最大的分类标签可以是一个合理的决策,但并不总是最优解。特别是在医疗诊断等重要领域,仅仅依靠概率最大的分类标签可能会带来一些问题。
以下是一些原因:
- 不确定性:分类模型的预测结果往往包含一定程度的不确定性。即使一个类别的概率最大,但它的概率可能仍然相对较低。仅仅基于最大概率进行决策可能会忽略其他类别的潜在可能性。
- 类别之间的差异:在某些情况下,不同类别之间的重要性或影响力可能会有所不同。概率最大的类别可能不是最重要的类别,或者可能不是需要优先考虑的类别。
- 风险和成本:在医疗诊断等领域,决策的结果可能会对患者的生命和健康产生直接影响。仅仅基于概率最大的分类标签进行决策可能会忽略可能的风险和成本,导致不准确的结果或不适当的行动。
因此,在医疗诊断场景下,通常需要更细致的分析和决策过程。除了分类模型的输出概率,还需要考虑其他因素,例如患者的病史、症状、实验室检查结果等。医疗决策往往是复杂的,并需要由专业医生进行综合判断。
尽管返回概率最大的分类标签在某些情况下可能是合理的,但在医疗诊断等重要领域,仅仅依靠概率最大的分类标签并不足够,需要综合考虑其他因素,并由专业人士进行决策。
5.假设我们使用softmax回归来预测下一个单词,可选取的单词数目过多可能会带来哪些问题?
- 当可选取的单词数目过多时,使用softmax回归来预测下一个单词可能会面临以下问题:
- 计算复杂度增加:Softmax回归的计算复杂度与类别数目成正比。如果可选取的单词数目非常大,那么计算softmax函数的指数运算和归一化操作将变得非常昂贵,导致训练和推理的效率下降。
- 内存消耗增加:计算softmax函数所需的内存空间与类别数目成正比。当可选取的单词数目非常多时,需要存储大量的权重参数和临时计算结果,这可能导致内存消耗过大,甚至超过可用的内存限制。
- 数据稀疏性问题:当可选取的单词数目非常多时,每个单词的出现频率可能会变得非常稀疏。这会导致模型在训练过程中难以准确地估计每个单词的权重参数,从而影响模型的性能和泛化能力。
- 样本不平衡问题:在大规模的单词集中,不同单词的出现频率可能会有很大差异,导致样本不平衡问题。某些常见的单词可能会有更多的训练样本,而一些罕见的单词可能只有很少的训练样本。这会影响模型对于不常见单词的预测能力。
为了解决上述问题,可以采取一些技术手段,例如:
- 降低可选取的单词数目:可以通过限制词汇表的大小或使用更精确的单词选择方法,减少可选取的单词数目,从而降低计算和内存的负担。
- 使用分层softmax或负采样等技术:这些技术可以减少计算复杂度和内存消耗,同时处理数据稀疏性和样本不平衡问题。
- 使用更高级的模型:除了softmax回归,还可以尝试其他模型,如深度神经网络、注意力机制等,以提高模型的表达能力和性能。
🌊4**. 研究体会**
通过这次研究,我深入学习了softmax回归模型,理解了它的原理和基本实现方式。开始了解softmax回归的背景和用途,它在多类别分类问题中的应用广泛;学习了如何从零开始实现softmax回归,并掌握了其中的关键步骤。
在从零开始实现softmax回归时,首先需要构建模型的参数,包括权重和偏差。通过使用Python和NumPy库,能够方便地进行矩阵运算,计算模型的预测结果。然后,实现了softmax函数,它将模型的原始输出转化为概率分布。通过对softmax函数的应用,可以得到每个类别的概率预测。接下来,定义了损失函数,使用交叉熵损失来度量模型预测与真实标签之间的差异。通过最小化损失函数,可以优化模型的参数,使得模型的预测更加准确。在优化过程中,采用了梯度下降算法,通过计算损失函数关于参数的梯度,更新参数的数值。
通过简洁实现softmax回归,更加熟悉了深度学习框架的使用。可以通过几行代码完成模型的定义、数据的加载和训练过程。还学会了使用框架提供的工具来评估模型的性能,如计算准确率和绘制混淆矩阵。这使能够更方便地对模型进行调试和优化,以获得更好的分类结果。
最后,通过实验探索了softmax回归在分类问题中的应用,并评估了其性能。使用了一些真实的数据集,如MNIST手写数字数据集,来进行实验。在实验中,将数据集划分为训练集和测试集,用训练集来训练模型,然后用测试集来评估模型的性能。
在从零开始实现的实验中,对模型的性能进行了一些调优,比如调整学习率和迭代次数。观察到随着迭代次数的增加,模型的训练损失逐渐下降,同时在测试集上的准确率也在提升。这证明了的模型在一定程度上学习到了数据的规律,并能够泛化到新的样本。
