前言:近年来,随着人工智能技术的飞速发展,尤其是深度学习领域的突破,时序预测领域也迎来了新的变革。传统的预测方法,如线性回归、时间序列分析等,虽然在某些场景下表现良好,但在面对复杂、非线性的时序数据时,往往显得力不从心。此时,一种融合了深度学习最新成果的技术------多头注意力与宽度学习,正逐渐崭露头角,为解决这一难题提供了新的思路。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
深度神经网络虽然具有残差连接来确保信息完整性,但需要较长的训练时间。宽度学习模型则采用级联结构实现信息重用,保证原始信息的完整性。它是一个单一、简单且专门化的网络,无需重新训练,并具有大多数机器学习模型的快速解决能力和大多数深度学习模型的拟合能力。对于宽度学习模型的更深入理解,请参阅原文(链接提供)。此外,该论文指出,多头注意力机制能够充分提取不同维度和层次的关键特征,并有效利用这些关键特征。他们通过列举之前的研究表明,带有注意力机制的模型可以通过捕获一部分语义信息来确保信息的有效性,从而在不同层次捕获丰富的信息。
因此,作者提出了使用宽度学习系统(BLS)来扩展混沌时间序列数据的维度,并引入多头注意力机制来提取不同级别的语义信息,包括线性和非线性相关性、混沌机制和噪声。同时,他们还利用残差连接来确保信息完整性,这里给出文章的主要贡献点:
1)提出了一种名为"Multi-Attn BLS"的BLS新范式,可以用于动态建模混沌时序数据。该模型可以通过级联和注意机制最大程度地丰富固定特征,并从混沌时间序列系统中有效提取语义信息。
2)Multi-Attn BLS使用带有位置编码的多头注意力机制来学习复杂的混沌时间序列模式,并通过捕捉时空关系最大化地提取语义信息。
3)Multi-Attn BLS在三个基准测试上取得了出色的预测效果,其它在混沌时间序列中也具有很强的可解释性。
其中Multi-Attn BLS主要可分为三个部分:1)混沌时序数据预处理;2)基于BLS随机映射的非线性动态特征重新激活;3)利用多头注意力机制进行多层语义信息提取,如下图所示:
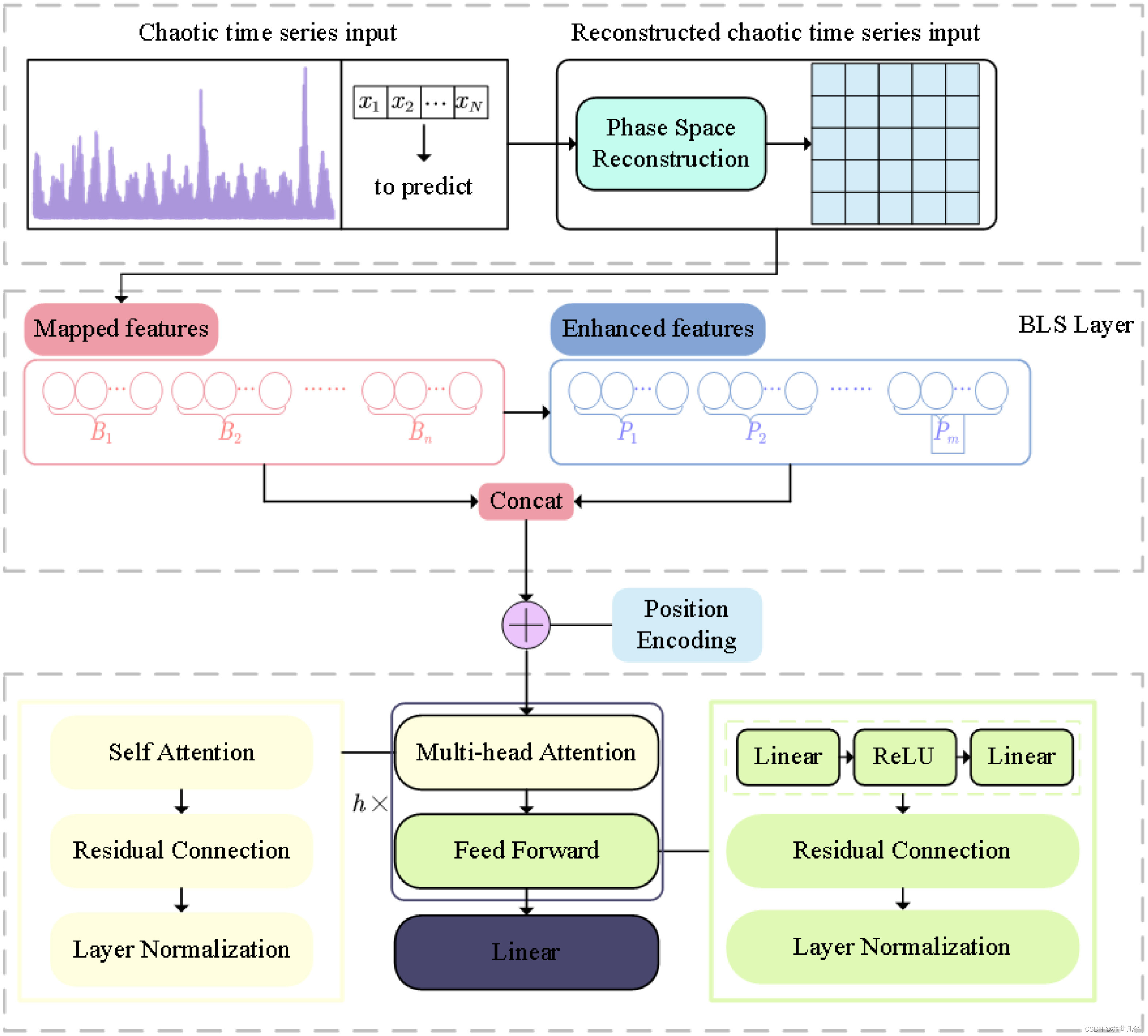
首先,根据相空间重构理论,Liyun Su,Lang Xiong和Jialing Yang使用C-C方法来解决嵌入维度和延迟时间,以恢复混沌系统,并将混沌时间序列转变为可预测模式。然后,重新构建的混沌时间序列数据被BLS的特征层和增强层随机映射并增强到高维系统,从而生成含有不同模式的混沌时间序列的混合特征。最后,使用多头注意力机制和残差连接来提取系统中保留的时空关系,包括线性相关、非线性确定性和噪声
混沌时间序列是动力系统产生的单变量或多变量时间序列。相空间重构定理将混沌时间序列映射到高维空间,以重构原始动力系统的一组表示。根据Takens嵌入定理,必须重构相空间以恢复原始的混沌吸引子,并使混沌系统的时间序列获得固定维度。对于观察到的混沌时间序列{x(t),t=1,2,3,...,N}{x(t),t=1,2,3,...,N},重构后相空间中的一个相点是,如下:
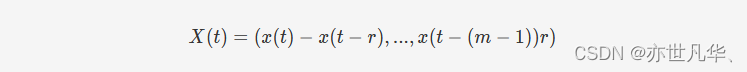
在这里t=N1,N1+1,...,N;N=1+(m−1)rt=N1,N1+1,...,N;N=1+(m−1)r,重构后的时间序列进一步由{X,Y}{X,Y}表示,其中下面公式提供了XX和YY之间的关系,表示为Y=g(X)Y=g(X)。我们可以将重构后的时间序列输入到BLS中进行高维信息的映射:

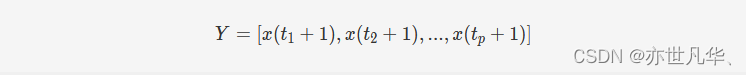
对于BLS的整体架构如下图所示,在这里我们实际上只用到了它的映射能力,即特征节点层和增强节点层,也就是上面的mapping feature nodes和enhancement feature nodes。
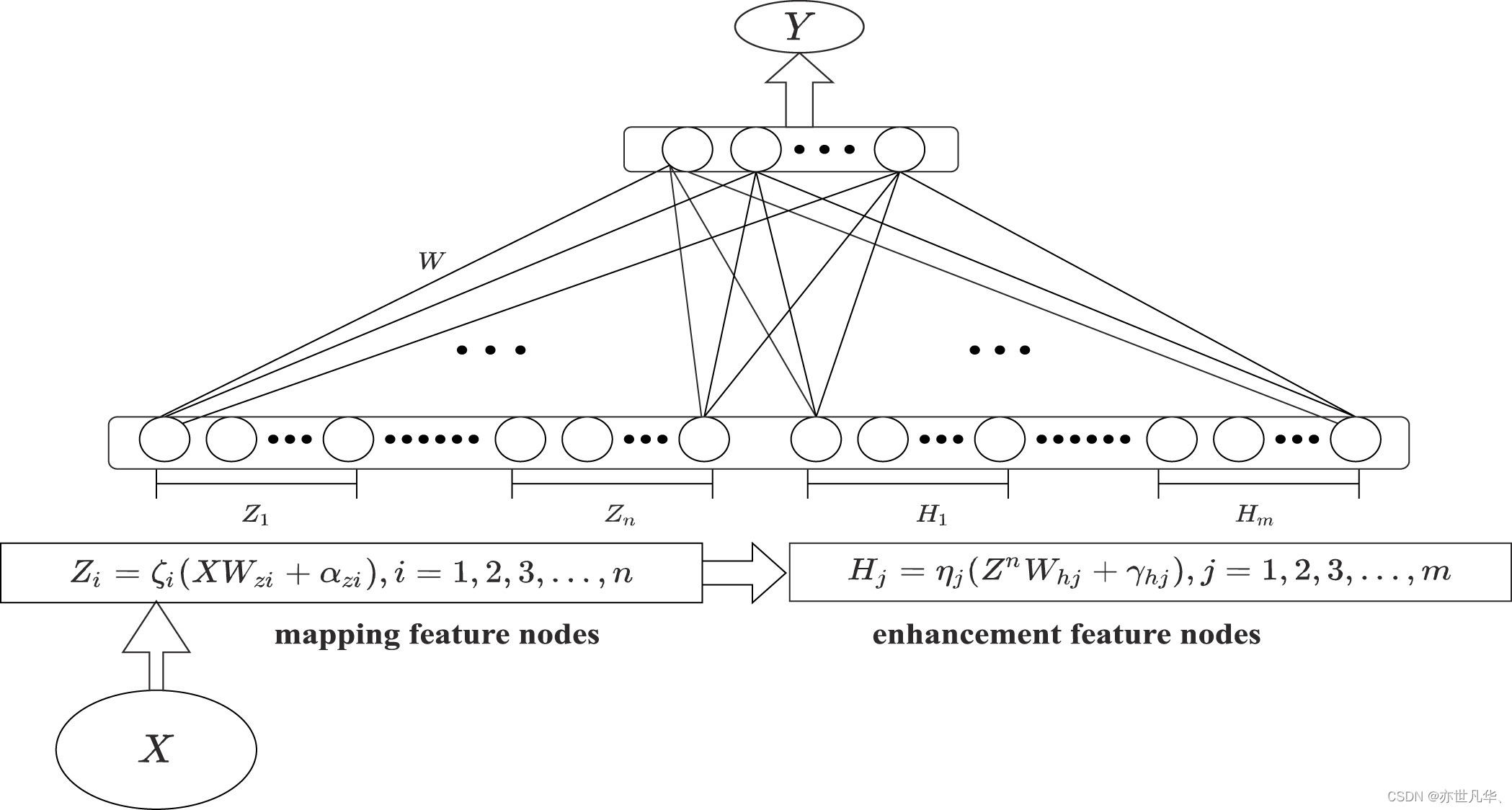
这两层的搭建方法如下,假设有输入的经过预处理后的时序数据集为XX, YY,其中XX是包含NN个样本的输入数据,每个样本有MM个维度,YY是输出结果也包含NN个样本,每个样本有KK个维度,代表每个样本所属的类别。首先,输入数据XX通过下面的等式转换成nn组映射特征层,每组有kk个节点:
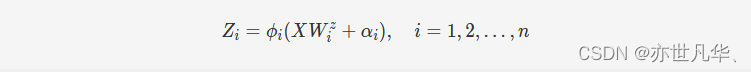
其中 ϕi(⋅)ϕi(⋅) 是第ii个非线性函数,WizWiz是随机生成的权重矩阵,αiαi是随机生成的偏置项。为了克服随机性,原文作者使用稀疏自编码器机制对得到的特征进行微调,以获得更紧凑的特征集,具体步骤如下,对于给定的输入数据 XX,ZZ 是通过上面的方程获得的随机特征,获得稀疏自编码器解的公式可以定义为:

演示效果
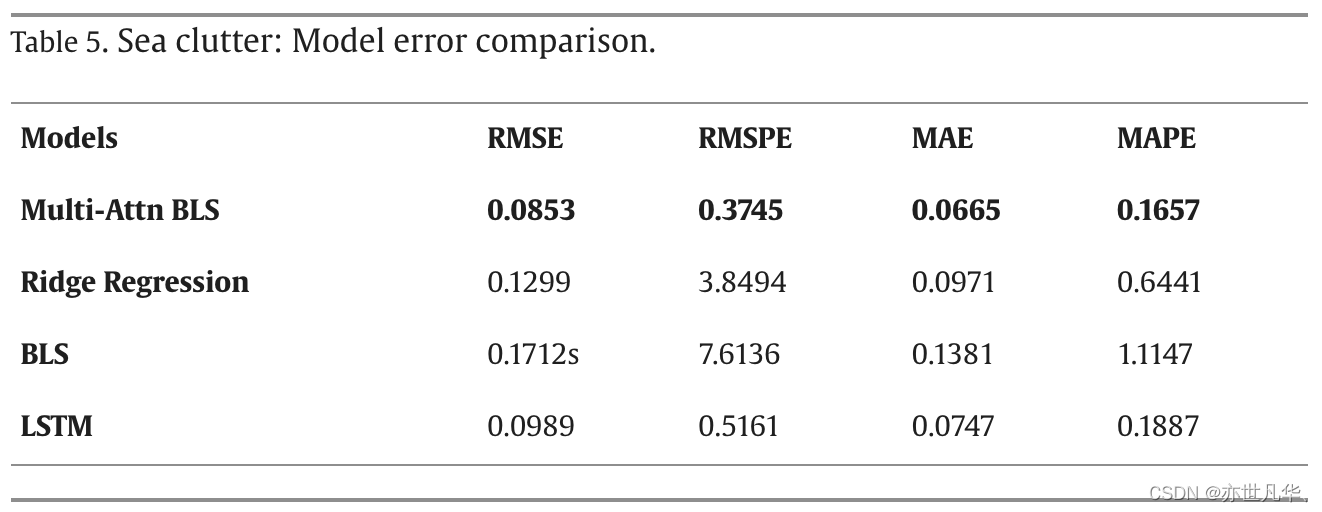
原文作者将他们所提出的模型在两份数据集上做了对比实验,结果如下图所示,可以看到Multi-Attn BLS在四类指标上都能取得最优值,其性能其优于岭回归算法、传统BLS模型和LSTM,如下图所示:
我将本次复现的代码集成到一个main.py文件中,需要的小伙伴们可以在终端输入相应命令调用,笔者本地的环境为macOS M2,使用的编程语言为python3.9,注意尽量不要使用版本太低的python。本次复现没有使用很复杂、冷门的库,因此最重要的是配置好pytorch环境,关于这个的文档很多,大家可以任意找一份配置好环境。
代码的文件结构如下图所示:
Data_Processing.py:是对数据的前处理函数,如果需要使用自有数据集可以忽略这部分
MultiAttn_layer.py:是复现的多头注意力层
VIT_layer.py:则是改进的使用VIT模块搭建的多头注意力层
BLSlayer.py:是BLS映射层,用来得到特征层和增强层

X.npy和y.npy文件是我本次使用的测试数据,分别是数据和代码,使用时请注意将您的数据和代码也以这种.npy格式保存到该文件夹中。它们具体的数据类型和格式如下,X每一行表示一个样本,545是每一个样本的输入维度;Y采用数字编码,是一个一维向量:

终端进入该文件夹后,可以使用以下命令来调用main.py启动模型训练:
python3 -c "from main import MultiAttn_BLS; MultiAttn_BLS('./X.npy','./y.npy')"MultiAttn_BLS函数的输入参数介绍如下:
bash
:param datapath: str 数据的路径
:param labelpath: str 标签的路径
:param N1: int 特征层节点组数,默认为12
:param N2: int 特征层组内节点数,默认为12
:param num_heads: int 多头自注意力头的数量,默认为4
(为了让多头自注意力机制能适应BLS生成的节点维度,N1应为num_heads的奇数倍)
:param layer_num: int 多头自注意力层数,默认为3
:param batch_size: int 多头自注意力层训练的批次量,默认为16
:param s: float 缩放尺度,一般设置为0.8
:param num_epochs: int 多头自注意力层训练的迭代次数,默认为50
:param test_size: float 划分数据集:测试集的比例,默认为0.3
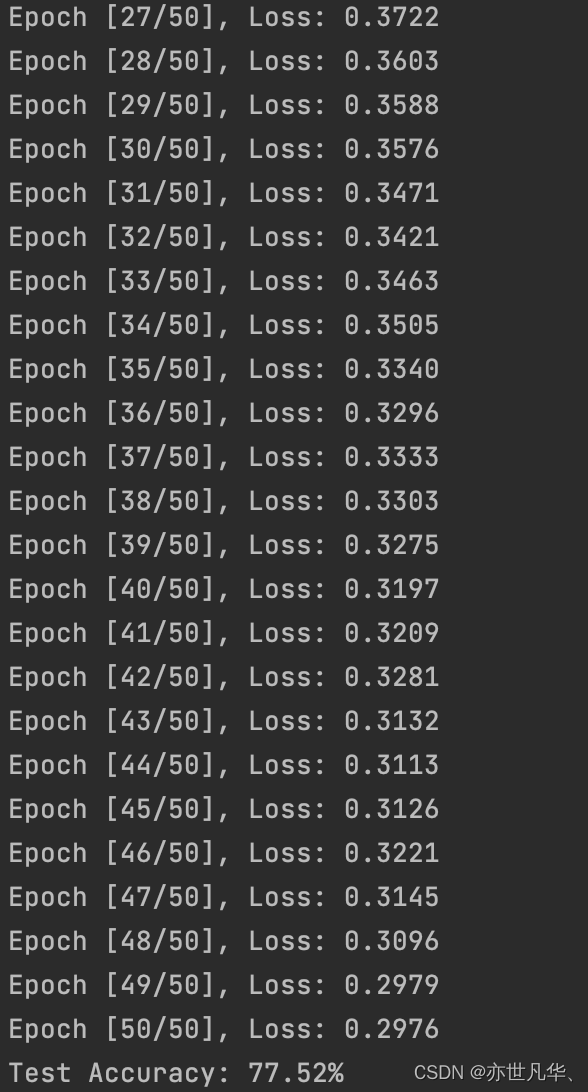
:return: 训练结束后的模型我基于本地的数据集做了一份分类任务,可以看到随着epoch增加,训练损失在不断下降,测试的准确率可以达到77.52%,还不错的结果。大家可以根据自己的需要修改模型的输出层来适应不同的学习任务,如下:
核心代码
这段代码实现了一种基于BLS(Batch-Mode Least Squares)的特征生成方法,用于将输入数据映射到高维特征空间中。具体来说,该方法包括以下步骤:
1)对输入数据进行预处理(标准化)并加入偏置项。
2)生成多个窗口(Window)的节点,每个窗口包含N1个节点,窗口数为N2。
3)对于每个窗口,利用BLS算法将其映射到高维特征空间中,并得到该窗口的系数矩阵(Beta1OfEachWindow)。
4)将每个窗口的映射结果拼接成一个特征向量,作为BLS映射层的输出(OutputOfFeatureMappingLayer)。
5)利用生成的特征向量和一个全连接的神经网络层(Enhance Layer)来进一步提取特征。
6)对于测试数据,按照同样的方式生成特征向量。
最终,该方法将输入数据映射到高维特征空间中,并生成了用于训练和测试的特征向量,如下:
python
# BLS映射层
import numpy as np
from sklearn import preprocessing
from numpy import random
from scipy import linalg as LA
def show_accuracy(predictLabel, Label):
count = 0
label_1 = Label.argmax(axis=1)
predlabel = predictLabel.argmax(axis=1)
for j in list(range(Label.shape[0])):
if label_1[j] == predlabel[j]:
count += 1
return (round(count / len(Label), 5))
def tansig(x):
return (2 / (1 + np.exp(-2 * x))) - 1
def sigmoid(data):
return 1.0 / (1 + np.exp(-data))
def linear(data):
return data
def tanh(data):
return (np.exp(data) - np.exp(-data)) / (np.exp(data) + np.exp(-data))
def relu(data):
return np.maximum(data, 0)
def pinv(A, reg):
return np.mat(reg * np.eye(A.shape[1]) + A.T.dot(A)).I.dot(A.T)
def shrinkage(a, b):
z = np.maximum(a - b, 0) - np.maximum(-a - b, 0)
return z
def sparse_bls(A, b): #A:映射后每个窗口的节点,b:加入bias的输入数据
lam = 0.001
itrs = 50
AA = A.T.dot(A)
m = A.shape[1]
n = b.shape[1]
x1 = np.zeros([m, n])
wk = x1
ok = x1
uk = x1
L1 = np.mat(AA + np.eye(m)).I
L2 = (L1.dot(A.T)).dot(b)
for i in range(itrs):
ck = L2 + np.dot(L1, (ok - uk))
ok = shrinkage(ck + uk, lam)
uk = uk + ck - ok
wk = ok
return wk
def generate_mappingFeaturelayer(train_x, FeatureOfInputDataWithBias, N1, N2, OutputOfFeatureMappingLayer, u=0):
Beta1OfEachWindow = list()
distOfMaxAndMin = []
minOfEachWindow = []
for i in range(N2):
random.seed(i + u)
weightOfEachWindow = 2 * random.randn(train_x.shape[1] + 1, N1) - 1
FeatureOfEachWindow = np.dot(FeatureOfInputDataWithBias, weightOfEachWindow)
scaler1 = preprocessing.MinMaxScaler(feature_range=(-1, 1)).fit(FeatureOfEachWindow)
FeatureOfEachWindowAfterPreprocess = scaler1.transform(FeatureOfEachWindow)
betaOfEachWindow = sparse_bls(FeatureOfEachWindowAfterPreprocess, FeatureOfInputDataWithBias).T
# betaOfEachWindow = graph_autoencoder(FeatureOfInputDataWithBias, FeatureOfEachWindowAfterPreprocess).T
Beta1OfEachWindow.append(betaOfEachWindow)
outputOfEachWindow = np.dot(FeatureOfInputDataWithBias, betaOfEachWindow)
distOfMaxAndMin.append(np.max(outputOfEachWindow, axis=0) - np.min(outputOfEachWindow, axis=0))
minOfEachWindow.append(np.mean(outputOfEachWindow, axis=0))
outputOfEachWindow = (outputOfEachWindow - minOfEachWindow[i]) / distOfMaxAndMin[i]
OutputOfFeatureMappingLayer[:, N1 * i:N1 * (i + 1)] = outputOfEachWindow
return OutputOfFeatureMappingLayer, Beta1OfEachWindow, distOfMaxAndMin, minOfEachWindow
def generate_enhancelayer(OutputOfFeatureMappingLayer, N1, N2, N3, s):
InputOfEnhanceLayerWithBias = np.hstack(
[OutputOfFeatureMappingLayer, 0.1 * np.ones((OutputOfFeatureMappingLayer.shape[0], 1))])
if N1 * N2 >= N3:
random.seed(67797325)
weightOfEnhanceLayer = LA.orth(2 * random.randn(N2 * N1 + 1, N3) - 1)
else:
random.seed(67797325)
weightOfEnhanceLayer = LA.orth(2 * random.randn(N2 * N1 + 1, N3).T - 1).T
tempOfOutputOfEnhanceLayer = np.dot(InputOfEnhanceLayerWithBias, weightOfEnhanceLayer)
parameterOfShrink = s / np.max(tempOfOutputOfEnhanceLayer)
OutputOfEnhanceLayer = tansig(tempOfOutputOfEnhanceLayer * parameterOfShrink)
return OutputOfEnhanceLayer, parameterOfShrink, weightOfEnhanceLayer
def BLS_Genfeatures(train_x, test_x, N1, N2, N3, s):
u = 0
train_x = preprocessing.scale(train_x, axis=1)
FeatureOfInputDataWithBias = np.hstack([train_x, 0.1 * np.ones((train_x.shape[0], 1))])
OutputOfFeatureMappingLayer = np.zeros([train_x.shape[0], N2 * N1])
OutputOfFeatureMappingLayer, Beta1OfEachWindow, distOfMaxAndMin, minOfEachWindow = \
generate_mappingFeaturelayer(train_x, FeatureOfInputDataWithBias, N1, N2, OutputOfFeatureMappingLayer, u)
OutputOfEnhanceLayer, parameterOfShrink, weightOfEnhanceLayer = \
generate_enhancelayer(OutputOfFeatureMappingLayer, N1, N2, N3, s)
InputOfOutputLayerTrain = np.hstack([OutputOfFeatureMappingLayer, OutputOfEnhanceLayer])
test_x = preprocessing.scale(test_x, axis=1)
FeatureOfInputDataWithBiasTest = np.hstack([test_x, 0.1 * np.ones((test_x.shape[0], 1))])
OutputOfFeatureMappingLayerTest = np.zeros([test_x.shape[0], N2 * N1])
for i in range(N2):
outputOfEachWindowTest = np.dot(FeatureOfInputDataWithBiasTest, Beta1OfEachWindow[i])
OutputOfFeatureMappingLayerTest[:, N1 * i:N1 * (i + 1)] = (outputOfEachWindowTest - minOfEachWindow[i]) / \
distOfMaxAndMin[i]
InputOfEnhanceLayerWithBiasTest = np.hstack(
[OutputOfFeatureMappingLayerTest, 0.1 * np.ones((OutputOfFeatureMappingLayerTest.shape[0], 1))])
tempOfOutputOfEnhanceLayerTest = np.dot(InputOfEnhanceLayerWithBiasTest, weightOfEnhanceLayer)
OutputOfEnhanceLayerTest = tansig(tempOfOutputOfEnhanceLayerTest * parameterOfShrink)
InputOfOutputLayerTest = np.hstack([OutputOfFeatureMappingLayerTest, OutputOfEnhanceLayerTest])
return InputOfOutputLayerTrain, InputOfOutputLayerTest下面这段代码实现了一个多头自注意力层,用于在神经网络中提取特征,具体来说,该多头自注意力层的输入是一个特征矩阵,输出是一个经过多层多头自注意力层和前馈神经网络层变换后的特征矩阵。其中,多头自注意力层能够在不同头之间共享信息,从而提高模型的泛化能力,而前馈神经网络层能够引入非线性变换,从而提取更复杂的特征:
python
# 多头注意力层
import torch
import math
import ssl
import numpy as np
import torch.nn.functional as F
import torch.nn as nn
ssl._create_default_https_context = ssl._create_unverified_context
def pos_encoding(OutputOfFeatureMappingLayer, B, N, C):
OutputOfFeatureMappingLayer = torch.tensor(OutputOfFeatureMappingLayer, dtype=torch.float).reshape(B, N, C)
# 定义位置编码的最大序列长度和特征维度
max_sequence_length = OutputOfFeatureMappingLayer.size(1)
feature_dim = OutputOfFeatureMappingLayer.size(2)
# 计算位置编码矩阵
position_encodings = torch.zeros(max_sequence_length, feature_dim)
position = torch.arange(0, max_sequence_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, feature_dim, 2).float() * (-math.log(10000.0) / feature_dim))
position_encodings[:, 0::2] = torch.sin(position * div_term)
position_encodings[:, 1::2] = torch.cos(position * div_term)
# 将位置编码矩阵扩展为和输入张量 x 的形状一致
position_encodings = position_encodings.unsqueeze(0).expand_as(OutputOfFeatureMappingLayer)
OutputOfFeatureMappingLayer = OutputOfFeatureMappingLayer + position_encodings
return OutputOfFeatureMappingLayer
class MultiHeadSelfAttentionWithResidual(torch.nn.Module):
def __init__(self, input_dim, output_dim, num_heads=4):
super(MultiHeadSelfAttentionWithResidual, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_heads = num_heads
# 每个注意力头的输出维度
self.head_dim = output_dim // num_heads
# 初始化查询、键、值权重矩阵
self.query_weights = torch.nn.Linear(input_dim, output_dim)
self.key_weights = torch.nn.Linear(input_dim, output_dim)
self.value_weights = torch.nn.Linear(input_dim, output_dim)
# 输出权重矩阵
self.output_weights = torch.nn.Linear(output_dim, output_dim)
def forward(self, inputs):
# 输入形状: (batch_size, seq_len, input_dim)
batch_size, seq_len, _ = inputs.size()
# 计算查询、键、值向量
queries = self.query_weights(inputs) # (batch_size, seq_len, output_dim)
keys = self.key_weights(inputs) # (batch_size, seq_len, output_dim)
values = self.value_weights(inputs) # (batch_size, seq_len, output_dim)
# 将向量分割成多个头
queries = queries.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1,
2) # (batch_size, num_heads, seq_len, head_dim)
keys = keys.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1,
2) # (batch_size, num_heads, seq_len, head_dim)
values = values.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1,
2) # (batch_size, num_heads, seq_len, head_dim)
# 计算注意力分数
scores = torch.matmul(queries, keys.transpose(-2, -1)) # (batch_size, num_heads, seq_len, seq_len)
# 对注意力分数进行缩放
scores = scores / np.sqrt(self.head_dim)
# 计算注意力权重
attention_weights = F.softmax(scores, dim=-1) # (batch_size, num_heads, seq_len, seq_len)
# 使用注意力权重对值向量加权求和
attention_output = torch.matmul(attention_weights, values) # (batch_size, num_heads, seq_len, head_dim)
# 将多个头的输出拼接并投影到输出维度
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, seq_len,
self.output_dim) # (batch_size, seq_len, output_dim)
# 使用线性层进行输出变换
output = self.output_weights(attention_output) # (batch_size, seq_len, output_dim)
# 添加残差连接
output = output + inputs
return output
class FeedForwardLayerWithResidual(torch.nn.Module):
def __init__(self, input_dim, hidden_dim):
super(FeedForwardLayerWithResidual, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.output_dim = input_dim
# 定义第一个线性层
self.linear1 = torch.nn.Linear(input_dim, hidden_dim)
# 定义激活函数
self.relu = torch.nn.ReLU()
# 定义第二个线性层
self.linear2 = torch.nn.Linear(hidden_dim, self.output_dim)
def forward(self, inputs):
# 输入形状: (batch_size, seq_len, input_dim)
batch_size, seq_len, input_dim = inputs.size()
# 将输入展平
inputs = inputs.view(batch_size, input_dim * seq_len)
# 第一个线性层
hidden = self.linear1(inputs)
# 激活函数
hidden = self.relu(hidden)
# 第二个线性层
output = self.linear2(hidden)
# 将输出形状重塑为与输入相同
# output = output.view(batch_size, seq_len, self.output_dim)
# 添加残差连接
output = output + inputs
return output
class MultiAttn_layer(torch.nn.Module):
def __init__(self, input_dim, output_dim, in_features, hidden_features, layer_num, num_heads=4):
super(MultiAttn_layer, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_heads = num_heads
self.norm = nn.LayerNorm(in_features, eps=1e-06, elementwise_affine=True)
self.FC = nn.Linear(in_features=in_features, out_features=2)
self.layer_num = layer_num
if hidden_features is None:
self.hidden_dim = 4 * self.output_dim
else:
self.hidden_dim = hidden_features
# 多头自注意力层
self.self_attn = MultiHeadSelfAttentionWithResidual(input_dim, output_dim, num_heads)
# 前馈神经网络层
self.feed_forward = FeedForwardLayerWithResidual(in_features, hidden_features)
def forward(self, inputs):
# 输入形状: (batch_size, seq_len, input_dim)
attn_output = self.self_attn(inputs)
# 先经过多头自注意力层
for i in range(self.layer_num-1):
attn_output = self.self_attn(attn_output)
# 再经过前馈神经网络层
output = self.feed_forward(attn_output)
output = self.norm(output)
output = self.FC(output)
return output在上面的多头注意力层中,我们手动搭建了一个多头注意力层,并复现了论文中的前馈网络层。实际上,我们可以使用目前比较火热的一些Transformer模型中的模块来帮助我们快速搭建好想要的模型,这些优秀模型的架构在一定程度上更合理、不易出错。在这里我使用了Vision Transformer模型中的部分网络架构来改进了多头注意力层,代码如下:
python
# 改进后的多头注意力层
import torch
import math
import ssl
import torch.nn as nn
from timm.models.vision_transformer import vit_base_patch8_224
ssl._create_default_https_context = ssl._create_unverified_context
def pos_encoding(OutputOfFeatureMappingLayer, B, N, C):
OutputOfFeatureMappingLayer = torch.tensor(OutputOfFeatureMappingLayer, dtype=torch.float).reshape(B, N, C)
# 定义位置编码的最大序列长度和特征维度
max_sequence_length = OutputOfFeatureMappingLayer.size(1)
feature_dim = OutputOfFeatureMappingLayer.size(2)
# 计算位置编码矩阵
position_encodings = torch.zeros(max_sequence_length, feature_dim)
position = torch.arange(0, max_sequence_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, feature_dim, 2).float() * (-math.log(10000.0) / feature_dim))
position_encodings[:, 0::2] = torch.sin(position * div_term)
position_encodings[:, 1::2] = torch.cos(position * div_term)
# 将位置编码矩阵扩展为和输入张量 x 的形状一致
position_encodings = position_encodings.unsqueeze(0).expand_as(OutputOfFeatureMappingLayer)
OutputOfFeatureMappingLayer = OutputOfFeatureMappingLayer + position_encodings
return OutputOfFeatureMappingLayer
class MultiAttn_layer(torch.nn.Module):
def __init__(self, input_dim, output_dim, in_features, hidden_features, layer_num, num_heads=4):
super(MultiAttn_layer, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_head = num_heads
self.norm = nn.LayerNorm(input_dim, eps=1e-06, elementwise_affine=True)
self.fc = nn.Linear(in_features=in_features, out_features=2, bias=True)
self.infeatures = in_features
self.layer_num = layer_num
model = vit_base_patch8_224(pretrained=True)
model.blocks[0].norm1 = nn.LayerNorm(input_dim, eps=1e-06, elementwise_affine=True)
model.blocks[0].attn.qkv = nn.Linear(in_features=input_dim, out_features=input_dim*3, bias=True)
model.blocks[0].attn.proj = nn.Linear(in_features=input_dim, out_features=input_dim, bias=True)
model.blocks[0].proj = nn.Linear(in_features=input_dim, out_features=input_dim, bias=True)
model.blocks[0].norm2 = nn.LayerNorm(input_dim, eps=1e-06, elementwise_affine=True)
model.blocks[0].mlp.fc1 = nn.Linear(in_features=input_dim, out_features=input_dim*3, bias=True)
model.blocks[0].mlp.fc2 = nn.Linear(in_features=input_dim*3, out_features=input_dim, bias=True)
self.blocks = model.blocks[0]
def forward(self, inputs):
output = self.blocks(inputs)
for i in range(self.layer_num-1):
output = self.blocks(output)
output = self.norm(output)
output = output.view(output.shape[0], self.infeatures)
output = self.fc(output)
return output写在最后
多头注意力机制以其独特的并行处理能力和对关键信息的敏感捕捉,为时序预测提供了新的视角。它不再局限于传统的线性或简单的非线性模型,而是能够深入数据的内在结构,挖掘出更丰富的模式和信息。与此同时,宽度学习作为一种新型的机器学习框架,通过集成多种学习算法,实现了模型在宽度上的扩展,进一步提升了预测精度和泛化能力。
然而,正如我们所知,技术的探索永无止境。多头注意力与宽度学习在时序预测领域的应用仍然面临着诸多挑战和机遇。如何进一步优化模型结构、提高预测精度、降低计算成本,以及如何将这一技术应用于更多实际场景中,都是我们未来需要深入研究和探讨的问题。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号
