文章目录
主要解决什么问题?
本文主要想要解决的问题是 如何使用uncalibrated的照片来进行Nerf重建。虽然说现在已经有了一些方式可以对相机位姿进行估计和优化,但是他们限制很多,且必须要有一个合理的初始化区间。在优化未知位姿的时候,对正面的场景也只能在short camera trajectories的优化。本文提出的方式,首先是不需要一个大致的相机位姿的初始化,只需要有一个大致的相机位姿分布,且可以在较大的轨迹内进行优化。
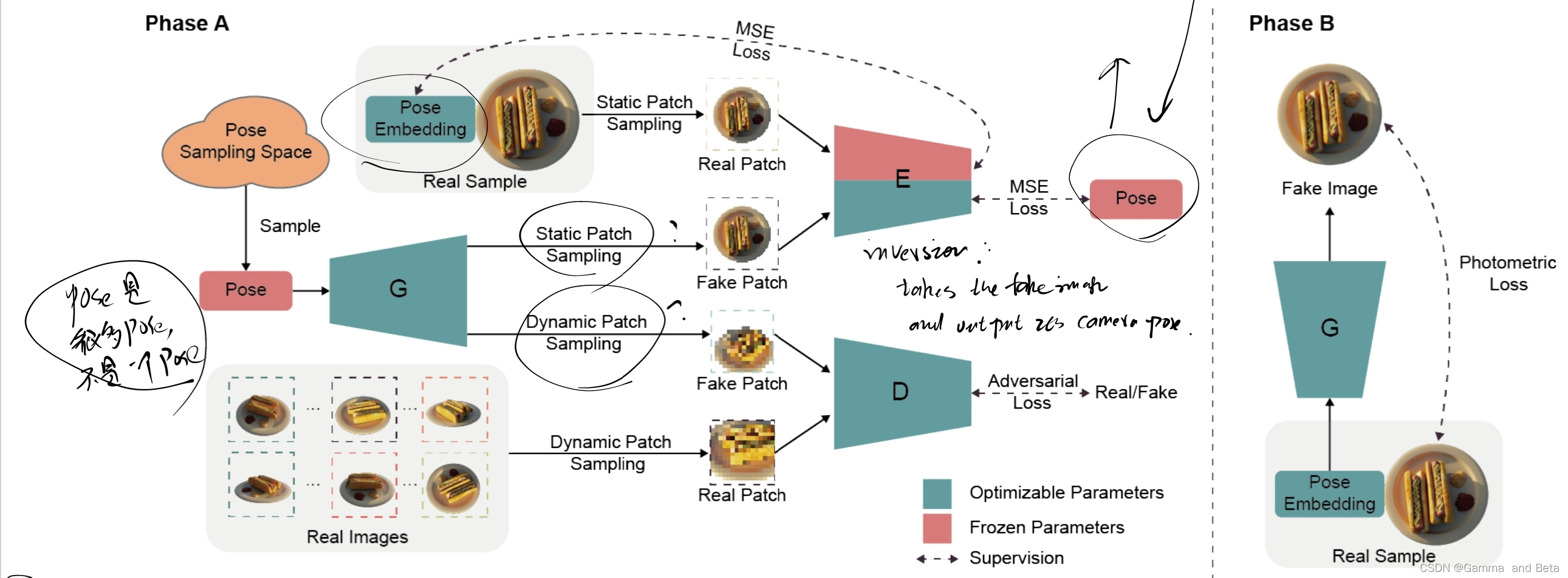
结构设计以及为什么有效果?
文中使用的结合了GAN结构的Fframework。一共分成了两个阶段,其实就是coarse-to-fine的样子,第一个阶段大致的输出一个粗糙的nerf estimation 以及 相机相机位姿,然后第二个阶段开始联合优化 (nerf estimation和相机的位姿。)
具体是怎么做的呢,又为什么会这么要这么做呢?
首先生成器的输入是一个相机pose,这个Pose是从事先定义好的分布中采样得来的。那么生成器会根据提供的相机位姿,去生成假的照片,然后对这些假的照片进行渲染(这里就就和一般的nerf一样)。假照片会被打散成patch然后拿去给判别器识别。这里文中提到了一个 动态采样的概念, 简单来说是 图像的大小不变,但是他的scale和offset是动态变化的。我估计使用动态采样的目的是为了让判别器更加的鲁棒。上述的结构的训练就是和一般的GAN一样。这只能让模型学习一个大概的Nerf和相机位姿。
为了要更加精确的相机位姿,文中还训练了一个inversion network,那么他的主要目的是从原始图像中采样一些image patches然后重新映射会相机位姿空间。就是说要根据相片去估计他们的位姿。这个过程和之前的过程是反着的,所以我猜这也是为什么叫inversion的原因。所以这个inversion 网络的输入数据是原始图像的一些samples,输出的结果是对应的相机位姿。通过这个方法可以学习到真照片个和相机位姿之间的关系。而且inversion 网络是用自监督的形式来进行训练的。
前面说的是A阶段,B 阶段主要是一个nerf表示和相机位姿一个联合优化,主要是优化photometric loss。
关于训练方式,这篇文章也有一些创新,比如regularized learning strategy, 他主要是通过阶段A和阶段B的交替进行来同时提高nerf 预测和 位姿预测的准确性。
个人想法。
读完首先给我的感觉是这个网络设计不是特别好训练,而且GAN缺陷可能会导致这个方式没法用到特别大的数据上。网络结果设计还是很巧妙,个人认为主要是以工程设计的创新为主。