前言
构建一个检索增强生成 (Retrieval-Augmented Generation, RAG) 应用的 PoC(概念验证,Proof of Concept)过程相对简单,但要将其推广到生产环境中则会面临多方面的挑战。这主要是因为 RAG 系统涉及多个不同的组件,每个组件都需要精心设计和优化,以确保整体性能达到令人满意的水平。
『RAG 高效应用指南』系列将就如何提高 RAG 系统性能进行深入探讨,提供一系列具体的方法和建议。同时读者也需要记住,提高 RAG 系统性能是一个持续的过程,需要不断地评估、优化和迭代。
根据具体应用场景选择合适的优化方法及其组合,是优化 RAG 系统的核心策略。
为什么要进行 query 理解
在 RAG 系统中,进行 query 理解是非常关键的一步。query 理解指的是对用户提出的问题进行深入分析,提取出关键信息,从而更准确地从知识库中检索出与用户查询最相关的信息,进而生成高质量的回答。
在 RAG 系统中,对用户 query 进行理解,包括但不限于以下原因:
1、用户表达的模糊性
由于自然语言的复杂性,相同的词汇在不同的上下文中可能有不同的含义,query 理解可以帮助系统识别并纠正这些错误,确保准确地理解用户的真正需求。
比如,用户输入「我想知道子龙是谁?」这里的「子龙」可能指代多种含义,如历史人物赵子龙或者某个昵称。又比如,用户输入 「book」,而 book 有多种含义,可能指一本书,也可能指预订一个座位。
通过 query 理解,系统可以分析上下文,判断用户的意图,从而检索到相关的正确信息。
2、query 和 doc 不在同一个语义空间
用户的 query 通常是非结构化的,可能使用非正式或口语化的语言进行自由表达,而文档则可能采用正式的书面表达。query 理解可以帮助将用户的表述转换为文档中术语,从而提高召回率。
比如,用户输入「手机坏了怎么办」,而文档中可能使用的是「手机维修步骤」这样的表述。又比如,用户可能问「如何让网站更快」,而文档内容可能是「提高网站性能的方法」。
当用户的 query 和文档不在同一个语义空间时,这增加了检索系统的复杂性,因为它需要在不同的表达方式、术语使用、上下文信息等方面建立联系。
3、用户的 query 可能比较复杂
用户的 query 有时可能涉及多个子问题或包含多个步骤,需要将复杂的 query 分解成更易处理的部分,逐一进行处理,以便提供准确和完整的答案。
比如,用户 query:「如何用 Python 分析数据,并生成预测报告?」,而文档内容可能是「使用 Python 分析股票数据的方法包括数据获取、数据清洗、特征提取等步骤」、「生成预测报告的方法包括建立预测模型、进行模型训练和测试、生成报告」。在这个例子,用户的 query 涉及数据分析和报告生成两个主要部分。通过 query 理解,系统可以将复杂的 query 分解为两个子问题:「如何用 Python 分析数据?」和「如何生成预测报告?」,然后分别进行处理和回答。
处理复杂 query 时,RAG 系统需要能够识别并分解用户的查询,将其拆分为更小、更具体的子问题。这样不仅可以提高检索的准确性,还可以使生成的回答更加精确和相关。
query 理解有哪些技术
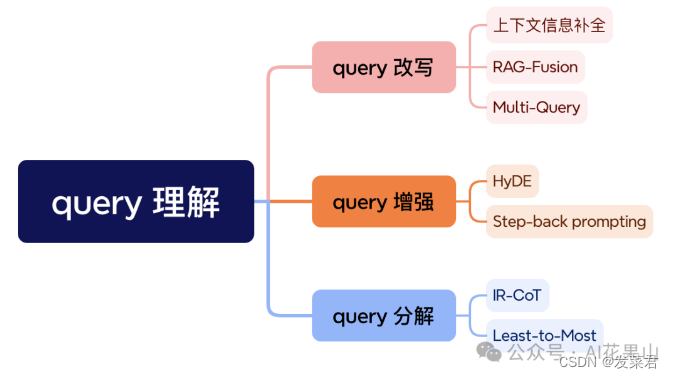
在 RAG 系统中,query 理解技术是提高信息检索效率和准确性的关键。我把当前常用的 query 理解技术分为三大类:query 改写、query 增强和 query 分解,如图所示。当然,也还有很多其他技术,这里先介绍下面这几种。
在多轮对话中,用户的当前输入往往包含隐含的指代关系和省略的信息。例如,用户在对话中提到的「它」可能指代之前对话中提到的某个具体事物。如果缺乏这些上下文信息,系统无法准确理解用户意图,从而导致语义缺失,无法有效召回相关信息。
在这种情况下,我们可以使用上下文信息补全,这里的上下文不仅仅是指多轮对话的信息,还包含当前对话的背景信息,比如时间、地点等。我们可以通过使用大型语言模型(LLM),对当前的 query 进行重写,将上下文中隐含的信息纳入到新生成的 query 中。
下面是一段多轮对话的示例:
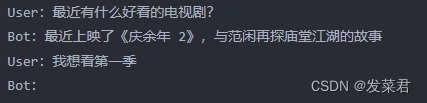
在这个例子,用户的问题「我想看第一季」包含了隐含的指代信息,没有上下文信息的补全,系统无法知道具体指的是哪部电视剧。通过采用上下文信息补全,我们把前面的对话信息也纳入其中,对 query 进行改写,可以生成类似「我想看庆余年第一季」的完整 query,从而提高后续检索的清晰度和相关性。
上下文信息补全可以提高 query 的清晰度,使系统能够更准确地理解用户意图,不过,因为需要多调用一次 LLM,会增加整体流程的 latency 问题。因此,我们也需要权衡计算复杂度和延迟的问题。
RAG-Fusion
RAG Fusion 旨在提升搜索精度和全面性,它的核心原理是根据用户的原始 query 生成多个不同角度的 query ,以捕捉 query 的不同方面和细微差别。然后通过使用逆向排名融合(Reciprocal Rank Fusion,RRF)技术,将多个 query 的检索结果进行融合,生成一个统一的排名列表,从而增加最相关文档出现在最终 TopK 列表的机会。
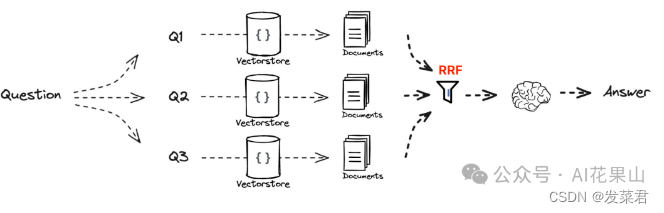
RAG Fusion 的整体流程如图所示,工作流程如下
1、多查询生成:直接使用用户输入的 query 进行查询,查询结果可能太窄导致无法产生较为全面的结果。通过使用 LLM 将原始查询扩展成多样化的查询,从而增加搜索的视野和深度。
2、逆向排名融合(RRF):RRF 是一种简单而有效的技术,用于融合多个检索结果的排名,以提高搜索结果的质量。它通过将多个系统的排名结果进行加权综合,生成一个统一的排名列表,使最相关的文档更有可能出现在结果的顶部。这种方法不需要训练数据,适用于多种信息检索任务,且在多个实验中表现优于其他融合方法。
3、生成性输出:将重新排名的文档和查询输入到 LLM ,生成结构化、富有洞见的答案或摘要。
Multi-Query
跟 RAG Fusion 类似,MultiQuery 是一种通过生成多种视角的查询来检索相关文档的方法。它使用 LLM 从用户输入的查询生成多个不同的查询视角,然后为每个查询检索一组相关文档,并合并这些结果以获得更全面的文档集合。
跟 RAG Fusion 不同的是,MultiQuery 没有使用 RRF 来融合多个搜索结果列表的排名,而是将多个搜索结果放到 context 中。这样做的好处是能够在上下文中保留更多的检索结果,提供更丰富的信息源,同时减少了在排名融合上的复杂性。通过这种方法,用户可以获得更加多样化和全面的信息集合,有助于更好地理解和回答复杂的问题。
HyDE
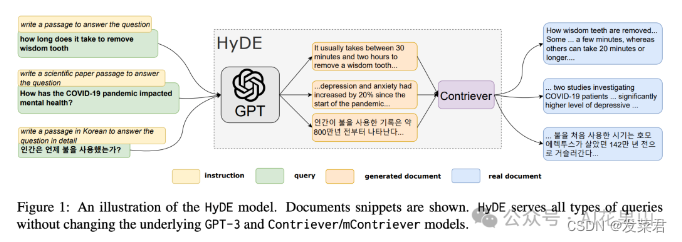
通常,RAG 向量检索通过使用内积相似度来度量查询(query)和文档(doc)之间的相似性。事实上,这里存在一个挑战:query 和 doc 不在同一个语义空间(前面已经介绍),通过将 query 和 doc 向量化,然后基于向量相似性来检索,检索的精度有限而且噪声可能比较大。为了解决这个问题,一种可行的方法是通过标注大量的数据来训练 embedding 函数。
而 HyDE(假设性文档嵌入,Hypothetical Document Embeddings)技术是一种无监督的方法,它基于这样一个假设:与 query 相比,假设性回答(LLM 直接对 query 生成的答案)与文档共享更相似的语义空间。
HyDE 具体是怎么工作的呢?
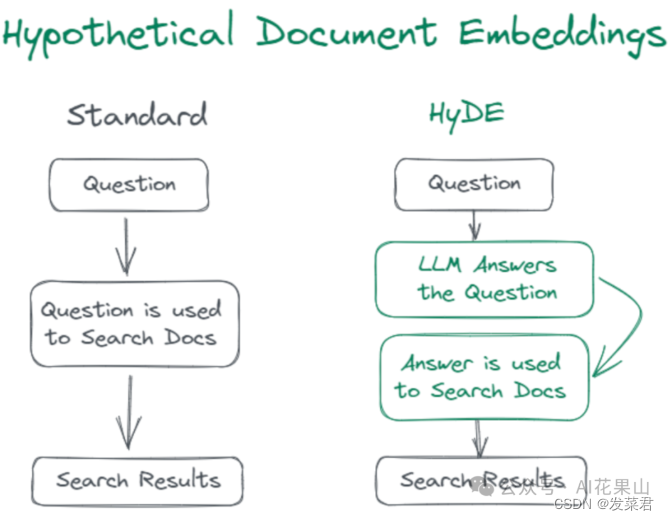
首先,HyDE 针对 query 直接生成一个假设性文档或者说回答(hypo_doc)。然后,对这个假设性回答进行向量化处理。最后,使用向量化的假设性回答去检索相似文档。
经过这么一顿操作,以前的 query - doc 检索就变成了 query - hypo_doc - doc 的检索,而此时 hypo_doc 和 doc 可能在语义空间上更接近。因此,HyDE 可以在一定程度上提升文档检索的精准度和相关度。
举个例子,假设用户提问「如何提高睡眠质量?」,HyDE 首先生成一个假设性回答,比如「提高睡眠质量的方法包括保持规律的睡眠时间、避免咖啡因和电子设备等。」,这个假设回答经过编码后,可能与提供的知识库中的文档内容(如不喝咖啡,不玩手机等电子设备)更接近,从而更容易找到相关文档。
HyDE 的核心优势在于:
-
避免了在同一向量空间中学习两个嵌入函数的复杂性。
-
利用无监督学习,直接生成和利用假设文档。
-
在缺乏标注数据的情况下,仍能显著提高检索的准确性和效率。
然而,因为 HyDE 强调问题的假设性回答和查找内容的相似性,因此也存在着不可避免的问题,即,假设性回答的质量取决于大型语言模型的生成能力,如果模型生成的回答不准确或不相关,会影响检索效果。例如,如果讨论的主题对 LLM 来说比较陌生,这种方法就无效了,可能会导致生成错误信息的次数增加。
Step-back prompting
Step-back prompting 技术旨在提高 LLM 进行抽象推理的能力,它引导 LLM 在回答问题前进行深度思考和抽象处理,将复杂问题分解为更高层次的问题。
Step-Back Prompting 包含两个主要步骤:
-
抽象(Abstraction):不是直接针对问题进行回答,而是首先促使 LLM 提出一个更高级别的「回溯问题」(step-back question),这个问题涉及更广泛的高级概念或原则,并检索与这些概念或原则相关的相关事实。
-
推理(Reasoning):在高级概念或原则的基础上,利用语言模型的内在推理能力,对原始问题进行推理解答。这种方法被称为基于抽象的推理(Abstraction-grounded Reasoning)。
 研究者在多个挑战性推理密集型任务上测试了 Step-Back Prompting,包括 STEM、知识问答(Knowledge QA)和多跳推理(Multi-Hop Reasoning)。实验涉及 PaLM-2L、GPT-4 和 Llama2-70B 模型,并观察到在各种任务上的性能显著提升。例如,在 MMLU(物理和化学)上,PaLM-2L 的性能分别提高了 7% 和 11%,在 TimeQA 上提高了 27%,在 MuSiQue 上提高了 7%。
研究者在多个挑战性推理密集型任务上测试了 Step-Back Prompting,包括 STEM、知识问答(Knowledge QA)和多跳推理(Multi-Hop Reasoning)。实验涉及 PaLM-2L、GPT-4 和 Llama2-70B 模型,并观察到在各种任务上的性能显著提升。例如,在 MMLU(物理和化学)上,PaLM-2L 的性能分别提高了 7% 和 11%,在 TimeQA 上提高了 27%,在 MuSiQue 上提高了 7%。
Step-Back Prompting 适用于需要复杂推理的领域,如:
• STEM 领域:涉及物理和化学等科学原理的应用问题。
• 知识问答:需要大量事实性知识的问题回答。
• 多跳推理:需要通过多个步骤或信息源进行推理的问题。
IR-CoT
IR-CoT(Interleaving Retrieval with Chain-of-Thought Reasoning),是一种用于解决多步骤问题(Multi-Step Questions)的技术。IR-CoT 通过交替执行检索(retrieval)和推理(reasoning)步骤来提高大型语言模型(LLMs)在处理复杂问题时的性能,如图所示。
IR-CoT 的核心思想是将检索步骤与推理步骤相结合,以指导检索过程并反过来使用检索结果来改进推理链(Chain-of-Thought, CoT)。论文作者认为,对于多步 QA 任务,单纯基于问题的一次性检索是不够的,因为后续检索的内容取决于已经推导出的信息。
IR-CoT的工作流程如下:
-
初始化检索:使用问题作为查询,从知识库中检索一组相关段落。
-
交替执行两个步骤:
• 扩展 CoT:利用问题、到目前为止收集的段落和已经生成的 CoT 句子来生成下一个 CoT 句子。
• 扩展检索信息:使用上一个 CoT 句子作为查询来检索额外的段落,并将它们添加到已收集的段落集中。
-
重复上述步骤:直到 CoT 报告答案或达到最大允许的推理步骤数。
-
终止:返回所有收集的段落作为检索结果,并使用这些段落作为上下文,通过直接 QA 提示或CoT 提示来回答原始问题。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊 ,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。