1.gpt基于transformer(本质是加权求和) 基于注意力机制
2.注意力机制是为了编解码服务的
3.编码解码中的码是"剥离了英语中文这种类别之外的单纯的语义关系",比如香蕉的语义相近的就应该是猴子,黄色,无论中文还是英语,都是这样的语义关系

4.tokenizer(分词器)和one hot(独热编码)对最基础的语义单元(字母/单词)(token)数字化
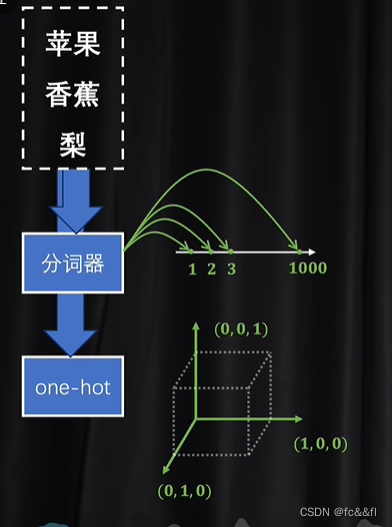
分词器:很难表达出复杂的语义关系;独热编码:所有的token都是一个独立的,很难体现之间的语义关系
5.潜空间:找到这个潜空间(一个方法是升维,一个是对独热编码降维)
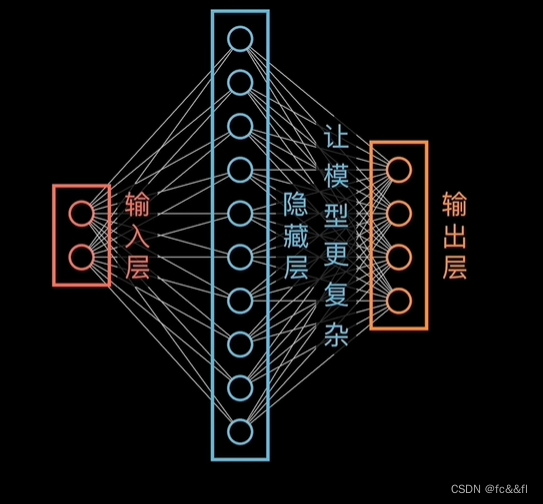
6.神经网络中的隐藏层,神经网络实现非线性变化,神经网络实现升维和降维

- 编码就是将文本里面的token编成独热码,然后进行降维,相当于把输入的一句话根据语义投射到一个潜空间里,高维---->低维,这个过程叫embedding,也就是嵌入,这个过程也叫做词嵌入,因为使用的是矩阵乘法,所以将token投入到潜空间的矩阵叫做嵌入矩阵
然后根据潜空间进行翻译等各种处理(我的理解就是将各种输入,无论英文汉语,都提取出来,形成一个只包含纯粹的语义关系的潜空间)

NLP里每个维度对应的是基础语义,图片里对应的是通道(三色)
8.如何找到实现降维的嵌入矩阵?
Word2Vec(结果是得到嵌入矩阵),不需要激活函数
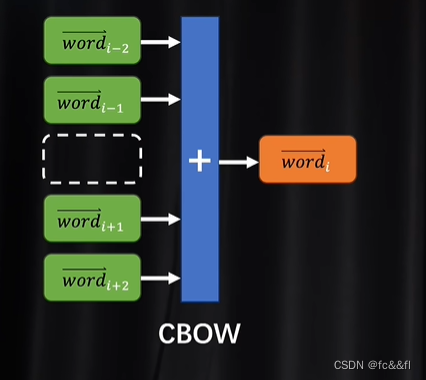
9.利用CBOW去评估得到word2vec(合力,分力)
10.利用skip-gram去评估得到word2vec(已知一个token,推断上下文token,然后判断对不对,和cbow相反)
11.对于词和词组合后的理解靠的就是注意力机制(transformer的核心)
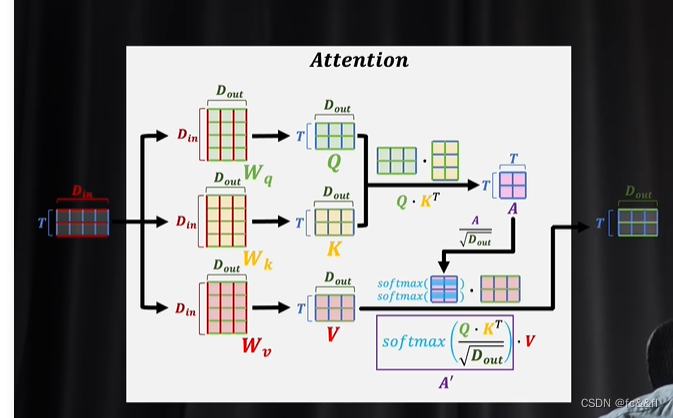
注意力机制输入的是一组词向量,注意力机制要解决美女,让一让和美女,加一下微信,这种上下文对美女美丽程度的影响
A'上下文关联的修改系数
12.选择两个矩阵相乘Wq,Wk是为了让模型可以表达更复杂的情况
13.注意力机制:从一个多义词中,比如苹果,选择一个表达
14.自注意力机制,交叉注意力(做翻译比较ok)
15.训练过程
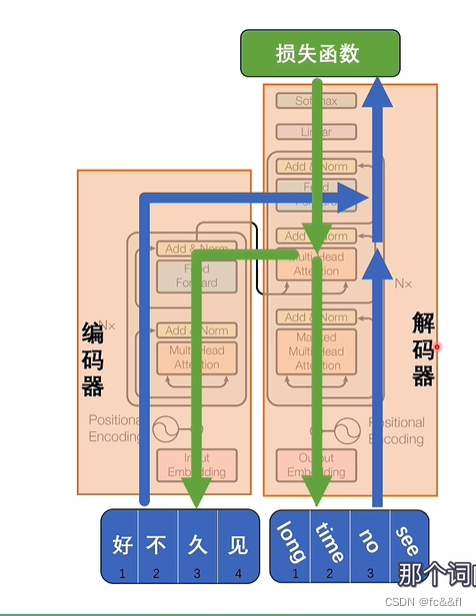
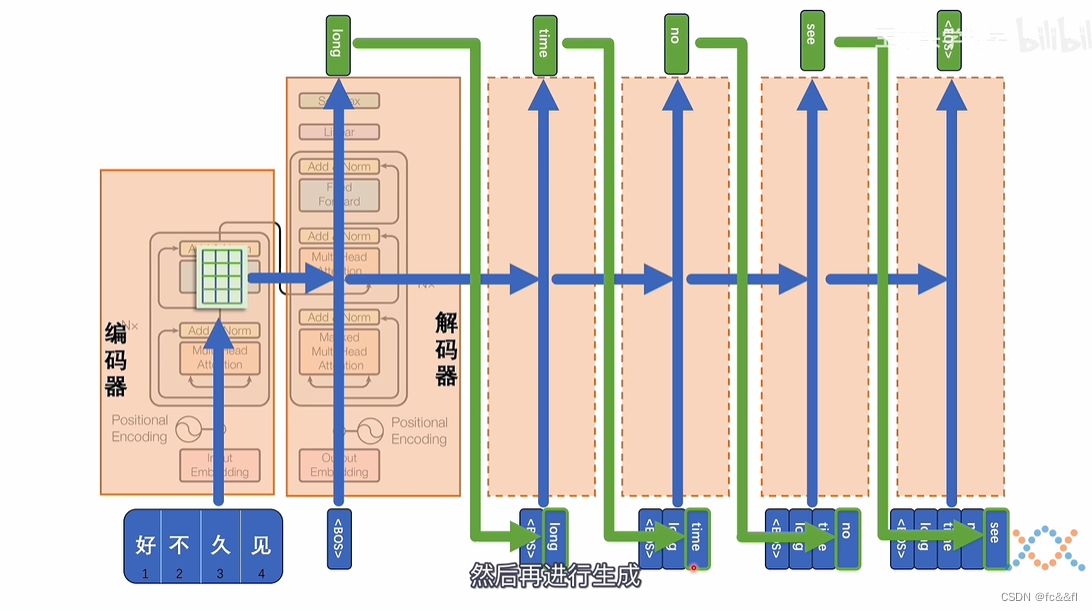
16.有的大模型只用解码器,编码器
17.相对位置编码:为了保证的token的先后顺序,在并行计算的同时
18.多头注意力机制:比卷积神经网络更好,可以跨越,结果更灵活,transformer叠加了很多层
19.掩码
文章来源于从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)_哔哩哔哩_bilibili