锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - Transformer架构介绍
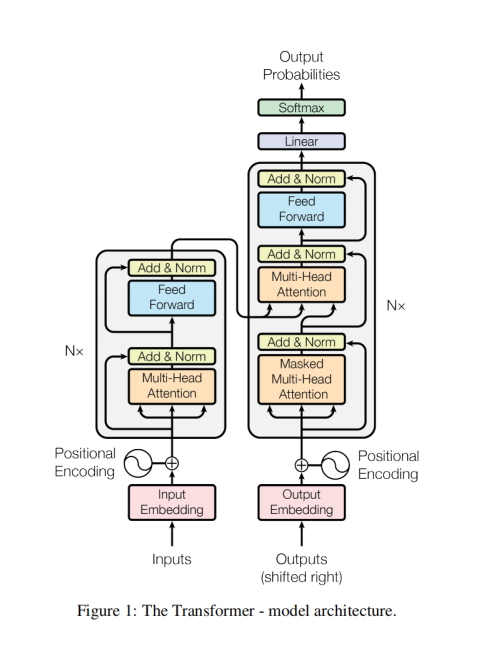
Transformer架构图可以通过图示清晰地展示出其各个组成部分及其功能。每个部分都有明确的任务和结构,协同工作以处理序列数据。接下来,我将基于Transformer架构图来详细解释每个部分的结构和功能。
1. 输入嵌入(Input Embeddings)
输入嵌入层的作用是将原始的词语表示(通常是单词或子词)转换为高维的密集向量。每个单词或子词通过词嵌入(Embedding)转化为向量,模型之后将处理这些向量。
-
功能:将输入的离散单词映射为连续的高维空间向量,便于后续的处理。
-
结构:该层的输出是一个序列的嵌入矩阵,矩阵的维度为batch_size, seq_len, embedding_dim。
解码器那边有一个类似的Ouput Embedding 输出嵌入
与 Input Embedding 的关系
| 特性 | Input Embedding | Output Embedding |
|---|---|---|
| 作用对象 | 源语言序列 | 目标语言序列 |
| 词汇表 | 源语言词汇表 | 目标语言词汇表 |
| 位置 | 编码器输入端 | 解码器输入端 |
| 功能 | 理解源语言 | 生成目标语言 |
2. 位置编码(Positional Encoding)
由于Transformer不具有像RNN或LSTM那样的时间步长顺序结构,它需要一个方法来注入序列中元素的位置信息。位置编码是将每个词语在序列中的位置表示为一个向量,与输入嵌入相加。
-
功能:向模型提供词语的位置信息,使得Transformer能够理解词语在序列中的相对位置。
-
结构:位置编码向量与输入嵌入矩阵逐元素相加,形状保持不变,仍为batch_size, seq_len, embedding_dim。
3. 编码器(Encoder)
编码器由多个相同结构的层(通常是6层)堆叠而成。每层都包括两个主要的子层:
-
自注意力机制(Self-Attention)
-
前馈神经网络(Feed-Forward Neural Network)
每个编码器层的输出作为下一个编码器层的输入,最终输出将包含输入序列的上下文信息。
3.1 自注意力机制(Self-Attention)
自注意力机制让每个词的表示能够基于输入序列中所有其他词的表示进行调整。计算方法涉及将输入词向量转换为查询(Q)、键(K)和值(V)向量,并通过计算查询与所有键的相似度(通常通过点积)来更新表示。
-
功能:捕捉输入序列中各元素之间的关系,并通过加权求和来更新词的表示。
-
结构:每个输入序列位置的表示都会与其他所有位置的表示交互。每个位置通过查询(Q)、键(K)、值(V)向量来计算注意力权重并加权求和得到新的表示。
3.2 前馈神经网络(Feed-Forward Neural Network)
每个编码器层还包含一个前馈神经网络。这个网络通常由两个全连接层(线性变换)构成,中间有一个非线性激活函数(例如ReLU)。
-
功能:进一步对每个位置的表示进行处理,以增强模型的表达能力,防止过拟合
-
结构:首先是一个全连接层,然后是一个激活函数(如ReLU),最后是另一个全连接层。该操作是对每个位置独立进行的。
3.3 残差连接和层归一化(Residual Connections & Layer Normalization)
在自注意力和前馈神经网络之后,都会有残差连接(Residual Connection)和层归一化(Layer Normalization)。残差连接有助于防止深度神经网络中的梯度消失或梯度爆炸问题,而层归一化有助于加速训练过程并提高稳定性。
-
功能:避免深层网络中的训练问题,保持模型的稳定性。
-
结构:每个子层的输入和输出相加,然后进行层归一化。
4. 解码器(Decoder)
解码器的结构和编码器类似,也由多个相同结构的层堆叠而成。每层解码器包括四个主要子层:
-
掩码机制(Masked)
2.自注意力机制(Self-Attention)
3.编码器-解码器注意力机制(Encoder-Decoder Attention)
4.前馈神经网络(Feed-Forward Neural Network)
4.1 掩码机制(Masked)
主要作用在训练或生成序列时,确保模型只能使用当前时刻及之前的信息,不能"偷看"未来的信息。
通过注意力掩码(Attention Mask) 实现,通常是一个上三角矩阵(或类似结构),将未来位置的值设为负无穷(或极小数),使softmax权重接近0。
4.2 自注意力机制(Self-Attention)
解码器的自注意力机制和编码器的自注意力机制类似,不同之处在于解码器的自注意力需要防止信息泄漏,即只能看到当前位置及其之前的位置的信息,这通常通过**掩蔽(masking)**操作来实现。
-
功能:生成当前词汇的表示时,只能基于已生成的词汇来调整表示。
-
结构:通过掩蔽机制,确保每个解码器位置只能关注它之前的位置,而不能访问未来的信息。
4.3 编码器-解码器注意力机制(Encoder-Decoder Attention)
这个子层的任务是将解码器的当前表示与编码器的输出进行对比,通过注意力机制来获得关于输入序列的重要信息。这有助于解码器在生成输出时,能够参考输入序列的上下文。
-
功能:使解码器能够关注编码器生成的上下文信息。
-
结构:通过查询来自解码器,键和值来自编码器的输出,计算加权和。
4.4 前馈神经网络(Feed-Forward Neural Network)
解码器的前馈神经网络结构和编码器中的一样,也是由两个全连接层组成,中间有一个ReLU激活函数。
-
功能:进一步处理解码器的表示,增强表达能力。
-
结构:同编码器一样,包含两个线性变换层和一个ReLU激活函数。
5. 输出层(Output Layer)
解码器的最终输出会传递给输出层,通常是一个全连接层,它将解码器的输出映射到目标词汇表的维度,生成每个时间步的预测词汇。
-
功能:生成序列的预测输出,例如在翻译任务中,输出为目标语言的词汇。
-
结构:这个层的输出维度为batch_size, seq_len, vocab_size,表示每个词的位置的输出分布。
6. Softmax和预测(Softmax & Prediction)
在输出层的最后,通常会使用Softmax函数来将模型的输出转换为概率分布,然后选择概率最高的词作为模型的预测输出。
-
功能:根据输出分布生成最终的预测结果。
-
结构:Softmax将每个位置的输出转换为一个概率分布,并选择概率最高的词作为最终的输出。
总结
Transformer的每个部分都承担着不同的任务,协同工作以完成复杂的序列到序列的转换任务:
-
输入嵌入:将词转换为向量。
-
位置编码:注入词语的位置信息。
-
编码器:处理输入序列并生成上下文信息。
-
解码器:生成输出序列并依赖编码器的上下文。
-
输出层:将解码器输出转换为词汇表中的词。