
今天讲一篇文章《Exploring Large Language Models for Knowledge Graph Completion》 ,这篇文章主题:基于大模型做知识图谱补全
1.文章主要思想:
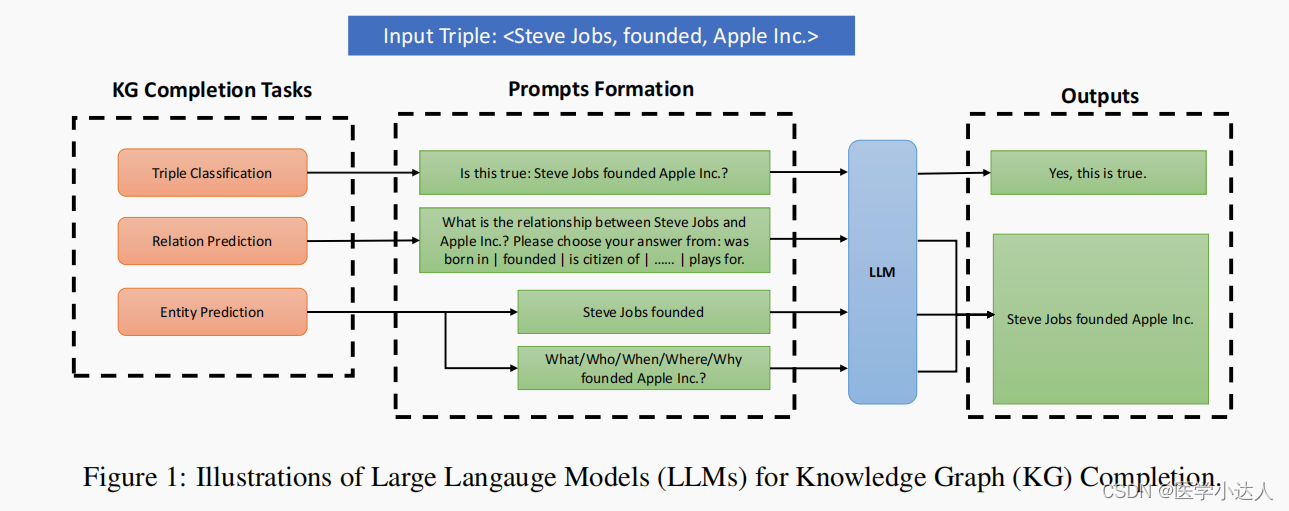
本章描述知识图谱补全中的三个任务:三元组分类、关系预测和实体(链接)预测,以及如何将它们转换为简单的提示问题,以供LLM完成任务。
三元组分类 。 给定一个三元组(h, r, t),任务是将其分类为正确或不正确。例如,给定三元组< 史蒂夫·乔布斯,成立,苹果公司 >,任务是将其分类为正确的。答案会是"这是真的吗:史蒂夫·乔布斯创立了苹果公司?"LLM的理想输出是"Yes, this is true"。
关系预测。 给定一个头实体和一个尾实体,任务是预测它们之间的关系 。例如,给定头部实体"Steve Jobs"和尾部实体"Apple Inc.",任务是预测它们的关系是"建立的"。提示的形式是"史蒂夫·乔布斯和苹果公司之间是什么关系?"请从以下选项中选择你的答案:出生在|创立|是|的公民...... |为。"人们期望的回答是:"史蒂夫·乔布斯创立了苹果公司。"
实体(链接)预测 。 给定头部实体和关系,任务是预测与头部实体相关的尾部实体 。给定尾部实体和关系,任务是预测头部实体。例如,给定头部实体"Steve Jobs"和关系"founded",任务是预测尾部实体"Apple Inc."。如果问尾部实体,提示的形式是"史蒂夫·乔布斯创立了",如果问头部实体,提示的形式是"什么/谁/何时/何地/为什么创立了苹果公司?"理想的回答是"史蒂夫·乔布斯创立了苹果公司。"部实体"Steve Jobs"和尾部实体"Apple Inc.",任务是预测它们的关系是"建立的"。提示的形式是"什么/谁/何时/何地/为什么创立了苹果公司?"理想的回答是"史蒂夫·乔布斯创立了苹果公司。"
2 本文方法
采用模型:KG-ChatGLM-6B****和KG-LLaMA (7B和13B)
1. p-tuning v2微调 ChatGLM-6B
2. 用LoRA微调LLaMA-7B和13B
3 实验设置

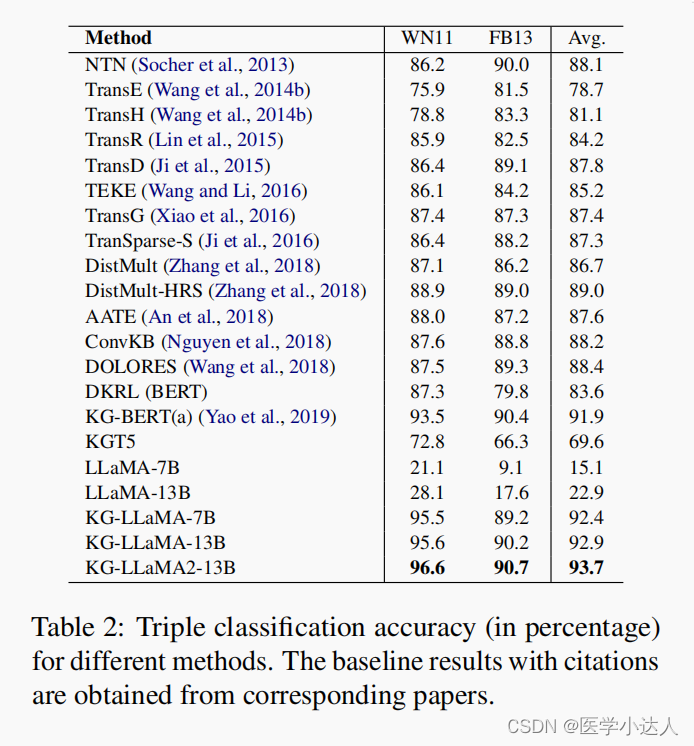
4 实验结果
5. 代码实战
GitHub - yao8839836/kg-llm: Exploring large language models for knowledge graph completion
installing requirement packages
pip install -r requirements_chatglm.txt1.DATA
(1) The four KGs we used as well as entity and relation descriptions are in ./data.
(2) The input files for LLMs are also in each folder of ./data, see train_instructions_llama.json and train_instructions_glm.json as examples.
(3) The output files of our models are also in each folder of ./data, see pred_instructions_llama13b.csv and generated_predictions.txt (from ChatGLM-6B) as examples.
2. LLaMA fine-tuning and inference examples
Firstly, put LLaMA model files under models/LLaMA-HF/ and ChatGLM-6b model files under models/chatglm-6b/.
In our experiments, we utilized an A100 GPU for all LLaMA models and a V100 GPU for all ChatGLM models.
python lora_finetune_wn11.py
python lora_finetune_yago_rel.py
python lora_infer_wn11.py
python lora_infer_yago_rel.py3. ChatGLM fine-tuning and inference examples
python ptuning_main.py --do_train --train_file data/YAGO3-10/train_instructions_glm_rel.json --validation_file data/YAGO3-10/test_instructions_glm_rel.json --prompt_column prompt --response_column response --overwrite_cache --model_name_or_path models/chatglm-6b --output_dir models/yago-rel-chatglm-6b --overwrite_output_dir --max_source_length 230 --max_target_length 20 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --gradient_accumulation_steps 16 --predict_with_generate --max_steps 80000 --logging_steps 300 --save_steps 10000 --learning_rate 1e-2 --pre_seq_len 8 --quantization_bit 4
python ptuning_main.py --do_predict --validation_file data/YAGO3-10/test_instructions_glm_rel.json --test_file data/YAGO3-10/test_instructions_glm_rel.json --overwrite_cache --prompt_column prompt --response_column response --model_name_or_path models/yago-rel-chatglm-6b/checkpoint-10000 --output_dir /data/YAGO3-10/glm_r_result --overwrite_output_dir --max_source_length 230 --max_target_length 20 --per_device_eval_batch_size 1 --predict_with_generate --pre_seq_len 8 --quantization_bit 44. Raw LLaMA inference
python test_llama_fb13.py
最后,感谢作者的优秀文章!大家加油!