1.6.4自动编码器和变体自动编码器
自编码器包括一个编码器神经网络,随后是一个解码器神经网络,其目的是在输出处重建输入数据。自动编码器的设计在网络中施加了一个瓶颈,它鼓励原始输入的压缩表示。通常,自编码器旨在利用数据中的关键结构将输入压缩成网络的瓶颈或潜在空间表示,这足以重建原始输入数据。因此,它被用于降维和去噪等应用。
该模型包括一个由θ参数化的编码器函数g和一个由Φ参数化的解码器函数f。瓶颈层给出如下:
 (1.45)
(1.45)
其中x为输入数据,z为编码的潜在向量。解码器输出端的重构输入可以表示为:
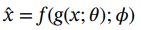 (1.46)
(1.46)
然后使用重构损失(如均方误差(MSE))迭代优化自编码器网络:
 (1.47)
(1.47)
与旨在将输入数据投影到单个潜在向量上的自编码器相比,变体自编码器40-42的目标是将输入数据学习或编码到潜在空间中的分布上。变体自编码器可以看作是在训练期间应用正则化,以防止网络过拟合。输入数据x被编码为潜在空间上的一个分布,即 ,然后从该潜在分布
,然后从该潜在分布 中采样一个点,然后将其送入解码器以重构输入数据为
中采样一个点,然后将其送入解码器以重构输入数据为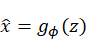 。均方误差等重构损失与
。均方误差等重构损失与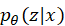 对均值为0、方差为1的高斯分布(即N(0,1))的Kullback-Leibler (KL)散度一起用于反向传播并学习网络的权值。
对均值为0、方差为1的高斯分布(即N(0,1))的Kullback-Leibler (KL)散度一起用于反向传播并学习网络的权值。
在实践中,编码分布被选择为正态分布,这样编码器就可以被训练来返回平均值和描述这些高斯分布的协方差矩阵。将输入编码为带有一些方差的分布而不是单点的原因是,它允许非常自然地表达潜在空间正则化:编码器返回的分布被强制接近标准正态分布,从而使整个特征空间接近标准正态分布。我们可以注意到,两个高斯分布之间的KL散度有一个封闭的形式,可以直接用两个分布的均值和协方差矩阵表示。变体自编码器(VAE)的损失函数可写为:
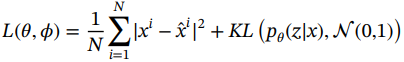 (1.48)
(1.48)
这里N是例子的数量。
KL散度是对从近似分布中采样的数据概率与目标分布之间的对数差的期望,定义如下:
 (1.49)
(1.49)
KL散度具有以下性质:
- 当两个分布近似相同时,KL散度为0:
 (1.50)
(1.50)
- 对于任意两个分布,KL散度总是正的:
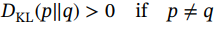 (1.51)
(1.51)
3.为了保证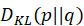 是有限的,p的支持需要包含在q中,否则如果式(1.49)q(x)->0,那么
是有限的,p的支持需要包含在q中,否则如果式(1.49)q(x)->0,那么 。
。
4.KL散度是一个非对称度量,即
 (1.52)
(1.52)
从概念上讲,在潜空间中学习分布的VAE架构使空间连续,这意味着潜空间中两个间隔较近的点比两个间隔较远的点产生更多相似的内容,并且是完整的,这意味着从潜空间中采样的任何点都会在VAE的解码器处产生有意义的输出。由于在反向传播期间,梯度不能流过概率层,因此提取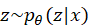 的采样过程需要一种特殊的技术,称为"重新参数化技巧"。重参数化技巧建议从零均值和单位方差的高斯中随机抽样ε,然后通过潜在分布的均值u来移动其方差σ,然后通过潜在分布的方差来对其进行缩放。图1.15给出了重新参数化技巧,用于从潜在分布中采样随机变量,使其具有确定性。重新参数化技巧允许优化分布的参数,同时仍然保持从该分布中随机抽样的能力。
的采样过程需要一种特殊的技术,称为"重新参数化技巧"。重参数化技巧建议从零均值和单位方差的高斯中随机抽样ε,然后通过潜在分布的均值u来移动其方差σ,然后通过潜在分布的方差来对其进行缩放。图1.15给出了重新参数化技巧,用于从潜在分布中采样随机变量,使其具有确定性。重新参数化技巧允许优化分布的参数,同时仍然保持从该分布中随机抽样的能力。
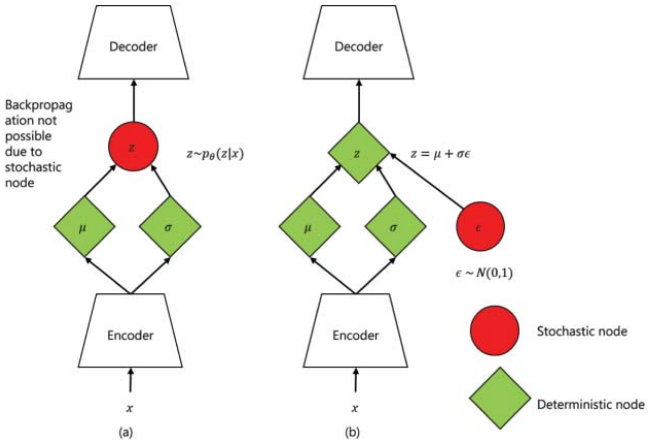
图1.15变体自编码器架构说明:(a)在反向传播过程中突出问题的原始形式,以及(b)重新参数化技巧。
1.6.5 生成对抗网络
Goodfellow在2014年提出的生成对抗网络(Generative adversarial networks, GANs)43是利用神经网络进行无监督学习领域的一个突破。该技术是最有前途的无监督学习方法之一,因为它具有建模高维分布的能力,并且与之前的无监督学习方法(如VAEs, Boltzmann机等)相比,计算成本更低的训练过程。GANs的工作原理是一个两人最小最大博弈,其中两个神经网络(称为生成器和鉴别器)相互对抗。生成器试图通过生成看起来真实的数据来欺骗鉴别器,而鉴别器的任务是对真实数据和虚假数据进行分类。在训练过程中,生成器在创建看起来真实的图像方面逐渐变得更好,而鉴别器在区分它们方面变得更好。对于pg = pr,最小最大博弈具有全局(且唯一)最优,其中pg是生成分布,pr是真实数据分布。当鉴别器不再能够区分真假图像时,该过程达到平衡。一旦训练完毕,只有生成器被用来生成与真实数据分布相似的新的真实数据。图1.16说明了用于训练普通GAN网络的生成器和鉴别器的工作原理。
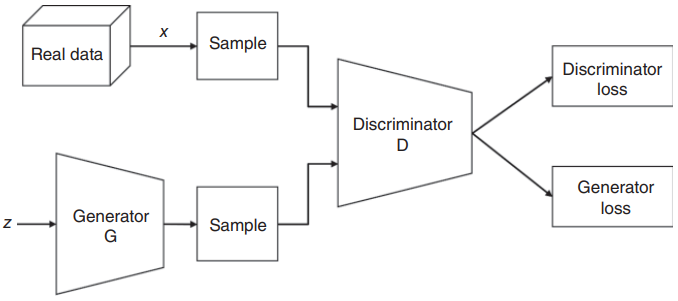
图1.16 香草GAN架构示意图,概述了生成器和鉴别器的原理。
在训练过程中,鉴别器对来自生成器的真实数据和虚假数据进行分类,并对错误地将真实实例分类为虚假或虚假实例分类为真实的鉴别器权重进行处罚。因此,逐渐更好地分类真实和虚假数据。GAN的生成器部分通过结合来自鉴别器的反馈来学习创建假数据,从某种意义上说,生成器损失会惩罚生成器未能欺骗鉴别器。如果生成器完全成功,那么鉴别器的准确率为50%,这意味着它无法再区分真实数据和虚假数据。如果GAN继续训练超过这个点,那么生成器开始在完全随机的反馈上训练,它自己的质量可能会崩溃。
1.6.5.1 最小最大损失
在最小最大损失的情况下,判据器的目标是最大化从真实分布中提取的数据的对数似然的期望,即 ,同时最小化从随机分布
,同时最小化从随机分布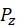 中采样的生成器生成的数据的对数似然的期望,即
中采样的生成器生成的数据的对数似然的期望,即 或等价的
或等价的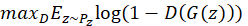 。因此,鉴别函数的目标是
。因此,鉴别函数的目标是
 (1.53)
(1.53)
另一方面,生成器的目标是生成 ,使得生成器产生的假示例与鉴别器输出的真实数据相似。因此,将这两个方面结合起来,竞争目标可以表示为D和G在进行最小最大博弈,其组合损失函数为:
,使得生成器产生的假示例与鉴别器输出的真实数据相似。因此,将这两个方面结合起来,竞争目标可以表示为D和G在进行最小最大博弈,其组合损失函数为:
 (1.54)
(1.54)
这很好,因为 与生成器优化无关。可以看出,生成器正试图最小化
与生成器优化无关。可以看出,生成器正试图最小化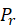 和
和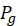 之间的Jensen-Shannon (JS)散度。JS散度取值范围为0 ~ 1,定义如下:
之间的Jensen-Shannon (JS)散度。JS散度取值范围为0 ~ 1,定义如下:
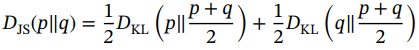 (1.55)
(1.55)
值得注意的是,与VAEs中使用的KL散度不同,JS散度是对称的,在两个分布不相交的情况下,无论两个分布如何,都会导致log(2)的最大值。相比之下,在这种情况下,KL散度将为∞。从公式(1.55)中很容易看出, 的最小值是在p ~ q时得到的。因此,生成器试图实现的是
的最小值是在p ~ q时得到的。因此,生成器试图实现的是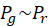 ,这意味着生成器生成的数据与真实数据相似。鉴别器试图使D(x)接近1,D(G(z))接近0,从而使损失最大化,从而达到D * (x) = 1/2的最优值,即纳什均衡。
,这意味着生成器生成的数据与真实数据相似。鉴别器试图使D(x)接近1,D(G(z))接近0,从而使损失最大化,从而达到D * (x) = 1/2的最优值,即纳什均衡。
GAN的最大最小损耗主要受梯度消失和模态坍缩的影响。如果鉴别器太好,那么生成器训练可能会因为梯度消失而失败。此外,随机输入GAN中的生成器有望产生各种输出。但是,如果生成器产生一个特别合理的输出,则生成器可能会学习只产生该输出。如果生成器在几次迭代中开始产生相同的输出,那么鉴别器的最佳策略是始终拒绝该输出。但是,如果鉴别器的下一次迭代陷入局部最小值并且没有找到最佳策略,那么下一次生成器迭代就很容易为当前鉴别器找到最合理的输出。结果,发生器陷入局部最小值,产生有限的输出集,这种现象称为模态崩溃。
1.6.5.2 Wasserstein 损失
在Wasserstein生成式对抗网络(WGANs)中,鉴别器不会对输入数据进行真假分类,而是输出一个数字。鉴别器训练只是试图使真实实例的输出大于假实例的输出。因此,WGAN中的鉴别器通常被称为批评家而不是鉴别器。鉴别器试图最大化评论家损失D(x) - D(G(z)),其中D(x)是评论家对真实实例的输出,G(z)是给定z的生成器的输出。D(G(z))是评论家对假数据的输出。因此,它试图最大化其对真实数据的输出与对假数据的输出之间的差异。发电机试图使发电机损耗D(G(z))最大化。因此,它试图最大化鉴别器对其假数据的输出。WGAN不容易受到模型崩溃的影响,并且可以避免梯度消失问题。
1.6.6 Transformer
Transformer已经成为最近最流行的深度学习架构之一,因为它在从自然语言处理任务到视觉任务的广泛应用中可用,并且在多个公共数据集上取得了最先进的结果。然而,重要的是要注意,transformer具有很高的计算和内存需求,这可能不是嵌入式解决方案的理想选择。一些作品,如注意力就是你所需要的44,专注于在模拟trasnformer功能的同时解决上述瓶颈。在下面的段落中,我们将对trasnformer中的不同模块进行解释,以方便读者理解相关作品。
在44中介绍了由6个编码器、6个解码器组成的transformer的思想,并使用机器翻译作为应用。机器翻译任务将一个句子或一个短语(单词序列)作为输入,并输出翻译成目标语言的短语。每个编码器在架构上是相同的,同时有自己的一组可学习的权重,由一个自关注层和一个前馈层组成。自注意层可以被视为一种上下文感知的编码机制,它使用来自其他单词的信息来更好地编码。从技术实现的角度来看,自注意机制涉及每个单词的三个向量,即Attention Is All You Need 44 query (Q)、key (K)和value (V),它们由三个不同的全连接层生成,输出维数小于输入嵌入向量的维数。为了计算每个单词相对于短语中所有其他单词的分数,在单词的查询向量和短语中所有单词的关键向量之间进行点积。分数进一步除以关键向量dK维数的平方根,通过对梯度进行归一化来稳定训练。接下来,通过softmax函数传递所有分数以生成标准化分布。最后,如公式(1.56)所示,将softmax输出与值向量矩阵相乘,生成给定位置的自关注层输出Z。然后将此输出简单地馈送到以下全连接层:
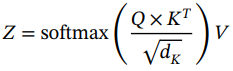 (1.56)
(1.56)
Transformer还引入了多头注意的概念,包括随机初始化多个自注意层,以便有不同的编码来覆盖多个子空间。多头注意力产生多个输出Z,它们被连接在一起,并与一个联合训练的权重向量W相乘,W将它们投射到一个向量中,该向量被馈送到完全连接的层。为了捕获给定序列中单词的顺序,生成位置编码,其中编码中的每个元素表示一个正弦波。然后将其添加到单词嵌入向量中,从而得到编码器的输入向量。此外,每个编码器由一个带有规范化层的剩余连接组成。在解码器中,来自顶部编码器的输入键和值向量作为输入,由编码器-解码器注意层使用。在每个时间步长之后,解码器的输出与位置编码一起反馈给解码器,该位置编码成为解码器中自注意层的输入。解码器自注意层通过屏蔽所有尚未被预测到−∞的剩余位置来防止将来出现位置,并且只有预测的输出序列作为解码器自注意层的输入。解码器的最后一层由一个logit层组成,该层具有所有可能单词的维数,并在其上应用softmax选择概率最高的一个作为预测单词。
Transformer的整体架构如图1.17所示。
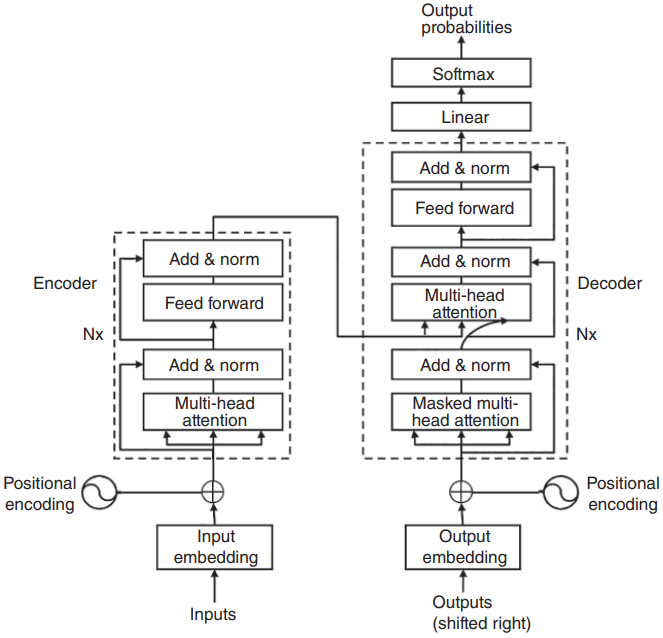
图1.17 Transformer网络结构。来源:改编自44。