小罗碎碎念
这一期
顶刊详析,选择的是2019年7月发表于Nature Medicine的Clinical-grade computational pathology using weakly supervised deep learning on whole slide images。

如果你不清楚我为什么要选一篇2019年的文章进行分析,请看6月4号的这篇推文,然后你就会有兴趣回来看这篇文章了。
人工智能在病理组学中的发展历程概述|24年6月·顶刊速递·06-04
重点关注
在这篇文章中,可以看到你们大多数人感兴趣的内容,并且每一张图我都有详细的分析,部分知识点还做了扩充,只要你有耐心看完,那么你一定能彻底掌握这篇文章!!

交流群
欢迎大家来到【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前群内成员已达三位数,大部分来自全国百强医院/前50院校。此外,小罗也借助自媒体,与华盛顿大学、北大、北航、华科、北科、南方医等院校的课题组建立了联系,欢迎更多的人加入我们的队伍!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位,即可邀您入群。

文献概述
这篇文章讨论了在病理学领域应用深度学习技术的最新进展,特别是在
弱监督学习框架下对整个切片图像(Whole Slide Images, WSIs)进行分析的研究。
文章强调了病理学在现代医学,尤其是癌症治疗中的核心作用,但指出传统的显微镜诊断方法一个世纪以来几乎没有变化。随着数字病理学的出现,通过数字切片扫描仪将玻璃切片数字化,为病理学家提供了一个潜在的新标准,使得计算病理学领域得以发展。
文章着重介绍了一种基于多实例学习(Multiple Instance Learning, MIL)的深度学习系统,该系统仅使用报告的诊断作为训练标签,避免了昂贵且耗时的逐像素手动注释。研究者们评估了这一框架在未经任何形式筛选的44,732张切片图像数据集上的表现,并针对前列腺癌、基底细胞癌和乳腺癌转移至腋窝淋巴结的测试结果显示出超过0.98的曲线下面积(AUC)。
这项研究的主要贡献是提出了一种新框架,可以在不需要像素级注释的情况下大规模训练分类模型 。研究者们收集了三个大规模的计算病理学数据集,包括前列腺核心活检数据集、皮肤数据集和乳腺癌转移至淋巴结的数据集,每个数据集的规模都远远超过了该领域其他数据集。研究者们还展示了如何使用循环神经网络(Recurrent Neural Network, RNN)来整合整个切片的信息,并报告最终的分类结果。
文章还讨论了模型在不同放大倍数下的测试性能,以及如何通过不同的聚合策略来提高模型的鲁棒性。此外,研究者们还探讨了数据集大小对分类准确性的影响,并通过可视化技术来洞察模型对组织病理学图像的特征表示。
最后,文章强调了这项研究对于临床实践的意义,提出了临床级决策支持系统的概念,并与传统的全监督学习方法进行了比较。研究表明,即使在小规模、精心策划的数据集上训练的深度学习模型,也无法很好地泛化到临床级别的、真实世界的数据中。因此,文章提出的弱监督学习方法在训练大规模、多样化的数据集时具有明显的优势,无需数据筛选。
一、引言
病理学是现代医学特别是癌症治疗的基础。病理学家对载玻片上的诊断是临床和药物研究的基础,更重要的是,它是决定如何治疗患者的依据。然而,使用显微镜进行癌症的诊断、分级和分期的标准做法几乎一个世纪以来几乎没有变化1,2。
虽然其他医学领域,如放射学,在计算方法的研究和临床应用方面有着悠久的历史,但病理学在数字革命中一直处于幕后。直到最近几年,数字病理学才作为一个潜在的新护理标准出现,其中载玻片通过数字切片扫描仪数字化为全切片图像(WSIs)。随着扫描器技术的变得更加可靠,WSIs的数量越来越多,计算病理学领域也随之出现,以促进计算机辅助诊断,并使病理学家能够实现数字化工作流程3-5。这些诊断决策支持工具可以开发出来,以提高病理学家的效率和准确性,最终提供更好的患者护理。
传统上,用于医学图像分析决策支持系统的预测模型依赖于基于专家知识的手动特征提取。这些方法本质上特定于领域,并且它们的性能通常不足以用于临床应用。近年来,这种方法由于深度学习6在解决图像分类任务,如ImageNet7-10上的分类和分类方面取得的巨大成功和进步而发生了变化,其中高容量深度神经网络模型的性能据报道已超过人类表现10。
医学图像分析领域已经广泛应用了深度学习,在某些情况下,对于诊断任务可以达到临床影响。值得注意的是,文献11报道了皮肤镜图像的皮肤科医生级别的诊断,而文献12展示了光学相干断层扫描图像的眼科医生级别的表现。
与其它领域相比,计算病理学面临与病理数据生成特性相关的额外挑战。缺乏大型注释数据集的问题甚至比其它领域更严重。这部分是由于数字病理学的新颖性以及与载玻片数字化相关的高成本。此外,病理图像非常大:在20×放大倍率(0.5µmpixel−1)下扫描的载玻片产生的图像文件有数吉像素;大约470个WSIs包含的像素数量与整个ImageNet数据集大致相同。
利用病理数据集的特异性,大多数计算病理学工作应用监督学习来分类WSI中的小图块 13-22。这通常需要专家病理学家在像素级别进行广泛的注释。因此,最先进的病理数据集小而经过精心策划。CAMELYON1623乳腺癌转移检测挑战包含了该领域最大的标注数据集之一,共有400个非穷尽注释的WSIs。
在小型数据集上应用深度学习进行监督式分类已经取得了鼓舞人心的结果。值得注意的是,CAMEYLON16挑战赛报告称,在区分良性组织和转移性乳腺癌方面的表现与病理学家相当23。然而,这些模型在临床实践中的适用性仍然存疑,因为临床样本的广泛差异并未在小数据集中得到体现。本文中提出的实验将证实这一说法。
为了正确解决当前计算方法的不足,并使决策支持工具能够应用于临床,需要在代表性广泛的数据集上训练和验证模型,这些数据集应能代表日常临床中遇到的广泛病例。在那样大的规模上,依赖于昂贵且耗时的手工标注是不可能的 。我们通过收集一个大型计算病理学数据集,并提出一个无需像素级标注即可在非常大的规模上训练分类模型的新框架,来解决所有这些问题。此外,根据我们在这项工作中展示的结果,我们将正式定义临床级决策支持系统的概念,提出一种新的衡量临床适用性的方法,与现有文献中的方法形成对比。
我们这项工作最主要的贡献之一是学习分类模型的规模。我们在计算病理学领域收集了三个数据集:
- (1)一个包含
24,859张切片的前列腺核心活检数据集; - (2)一个包含
9,962张切片的皮肤数据集; - (3)一个包含
9,894张切片的乳腺转移至淋巴结数据集。
每个数据集至少比所有其他数据集大一个数量级。为了将这个规模放在其他计算机视觉问题的背景中,我们分析了相当于88个ImageNet数据集的像素数量(图1a)。

需要强调的是,数据未经策划。每种组织类型收集的切片代表至少1年的临床病例,因此代表性真实病理实验室中生成的切片,包括常见的瑕疵,如气泡、切片刀不规则切割、固定问题、灼烧、折痕和裂缝,以及数字化瑕疵,如条纹和模糊区域。
在三种组织类型中,我们包括了17,661个外部切片,这些切片是由美国和其他44个国家的相应机构病理实验室生成的(扩展数据图1),展示了计算病理学研究中前所未有的技术变异性。

所选数据集代表了不同但互补的临床实践视角,并提供了关于灵活、强大的决策支持系统应能解决何种挑战的见解。前列腺癌是新癌症病例的主要来源,在肺癌之后,是男性死亡的第二大常见原因24。
多项研究表明,前列腺癌诊断具有高的观察者间和观察者内变异性25-27,并且经常基于非常小的病变的存在,这些病变占据整个组织表面积的<1%(图1b)。
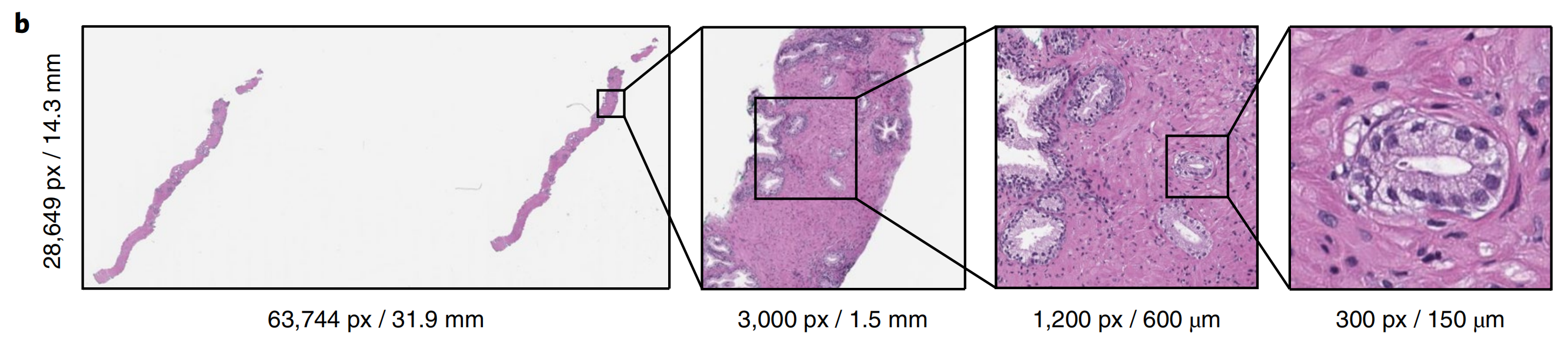
使诊断更加可重复,并辅助诊断低肿瘤体积的病例,是决策支持系统如何改善患者护理的例子。皮肤癌基底细胞癌(BCC)很少引起转移或死亡28。在其最常见的形式(结节性)中,病理学家可以轻松识别和诊断病变。在美国,大约有430万人每年被诊断出患有这种疾病29,这是最常见的癌症形式。在这种情况下,决策支持系统应通过简化病理学家的工作来提高临床效率。
为了充分利用我们数据集的规模,依靠监督学习是不可行的,因为监督学习需要手动标注 。相反,我们建议使用从解剖病理实验室信息系统(LISs)或电子健康记录中容易获得的切片级诊断来以弱监督方式训练分类模型。关键的是,从病理报告检索到的诊断数据比用于监督学习的专家标注更容易扩展,因为在大规模上进行标注是时间上禁止的。
更具体地说,切片级诊断对特定WSI内的所有图块施加一个弱标签。此外,我们知道,如果切片为阴性,则其所有图块也必须为阴性,不包含肿瘤。相反,如果切片为阳性,那么至少所有可能图块中的一个必须含有肿瘤。这种WSI分类问题的形式化是通用标准多实例假设的一个例子,其解决方案首先在文献30中描述。多实例学习(MIL)自那时以来已被广泛应用于许多机器学习领域,包括计算机视觉31-34。
当前用于弱监督WSI分类的方法依赖于在MIL假设的变体下训练的深度学习模型。通常使用两步方法:
- 首先使用MIL在图块级别训练分类器
- 然后将WSI内每个图块的预测分数进行聚合
通常通过使用各种策略(池化)结合它们的结果,或者通过学习融合模型36。受这些文献的启发,我们开发了一个新的框架,该框架利用MIL训练深度神经网络,从而得到在语义上丰富的图块级特征表示。然后使用这些表示在递归神经网络(RNN)中整合整个切片的信息,并报告最终的分类结果(图1c,d)。
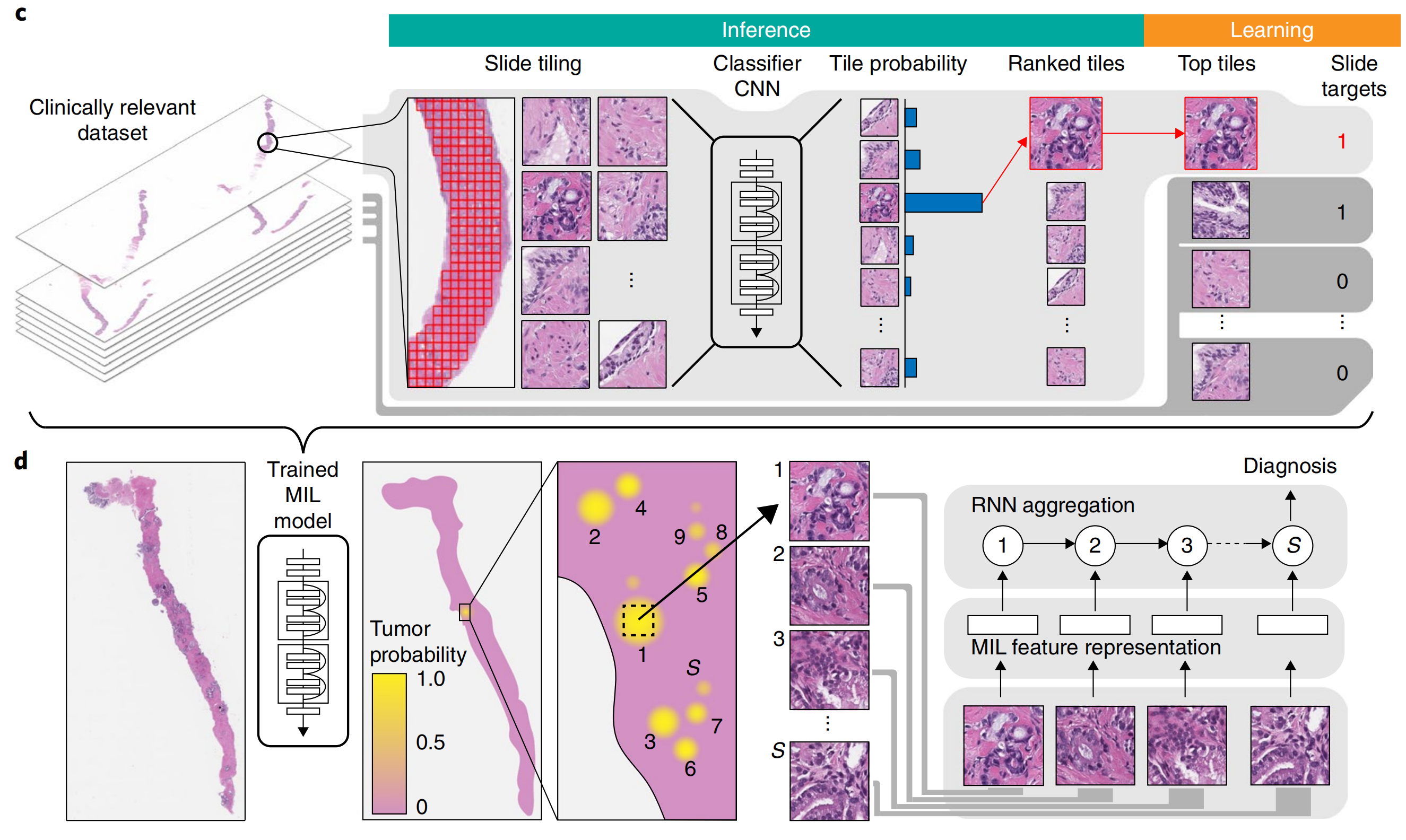
二、结果
2-1:使用 MIL 训练的 ResNet34 模型对每种组织类型的测试性能
本研究通过训练基于多重实例学习(MIL)的ResNet34模型,对组织切片进行分类。
在测试时,如果至少有一个切片被预测为阳性,则整个载玻片被视为阳性 。这种基于切片级别的聚合方式来源于多重实例假设,通常被称为最大池化。
测试集性能是通过针对每个数据集在不同放大倍数下训练的模型进行评估的(扩展数据图2)。
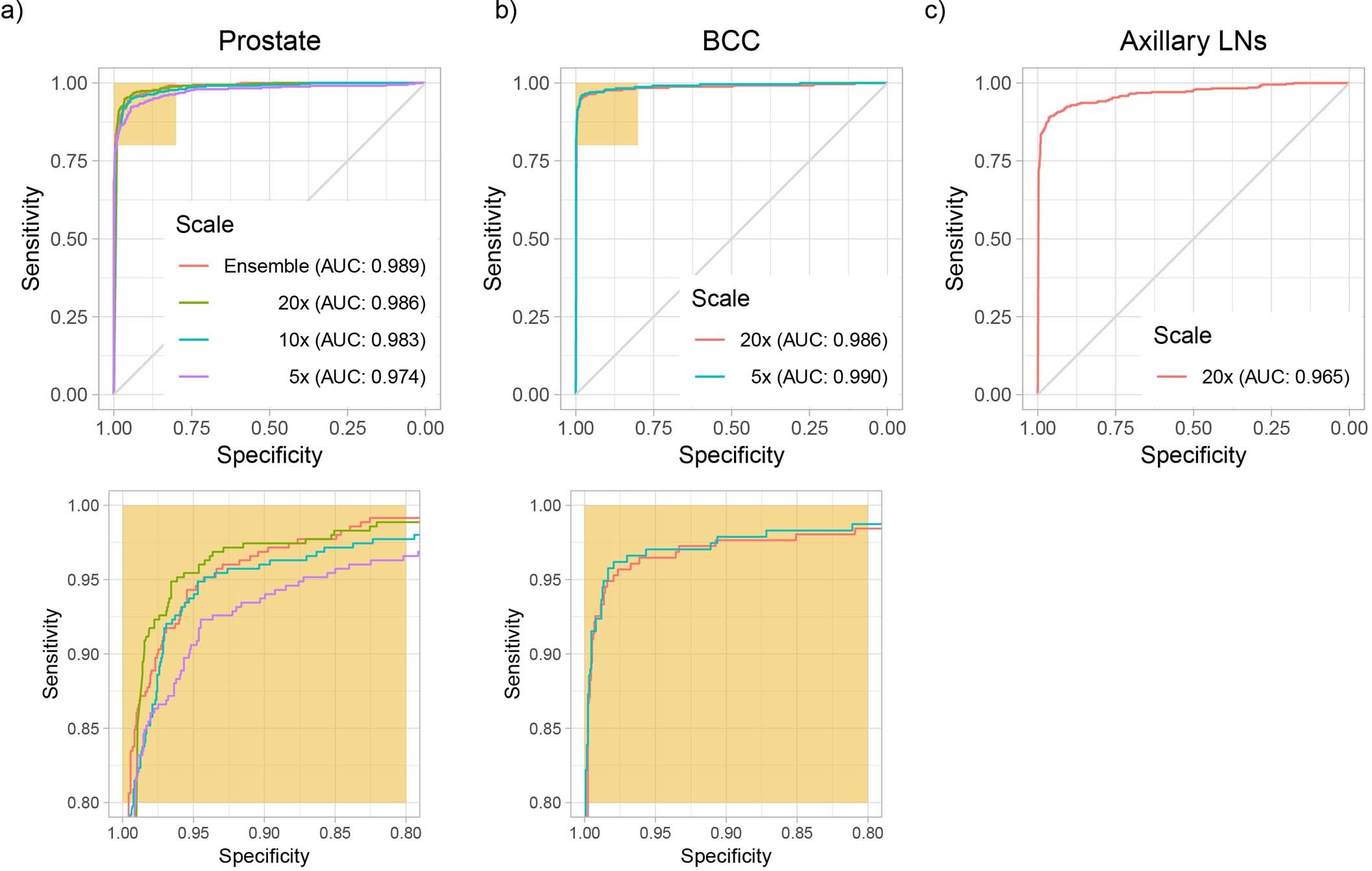
- a,前列腺数据集(n = 1,784)的结果最好,在 20 倍放大率下的 AUC 为 0.989;
- b,对于 BCC(n = 1,575),在 5 倍放大率下训练的模型表现最好,AUC 为 0.990;
- c,在乳腺癌转移检测任务(n = 1,473)中表现最差,在 20 倍放大率下的 AUC 为 0.965。
腋窝淋巴结数据集是三个数据集中最小的,这与假设一致,即要在实际临床数据中实现较低的错误率,需要较大的数据集。
组织学包含不同尺度的信息,病理学家在不同放大倍数下审查患者组织切片。例如,在前列腺组织病理学中,结构和细胞学特征对于诊断都至关重要,并且在不同放大倍数下更容易被识别。
对于前列腺数据集,最高放大倍数一致地给出了更好的结果(图a),而对于黑素细胞癌(BCC)检测,5倍放大倍数显示出更高的准确性(图b)。
有趣的是,测试集中不同放大倍数条件下的错误模式是互补的:在前列腺数据中,20倍模型在假阴性方面表现更好,而5倍模型在假阳性方面表现更好。通过在不同放大倍数下进行最大池化,构建了简单的集成模型。
值得注意的是,这些简单的多尺度模型在前列腺数据集的准确性和曲线下面积(AUC)方面优于单一尺度模型,但其他数据集则不然。
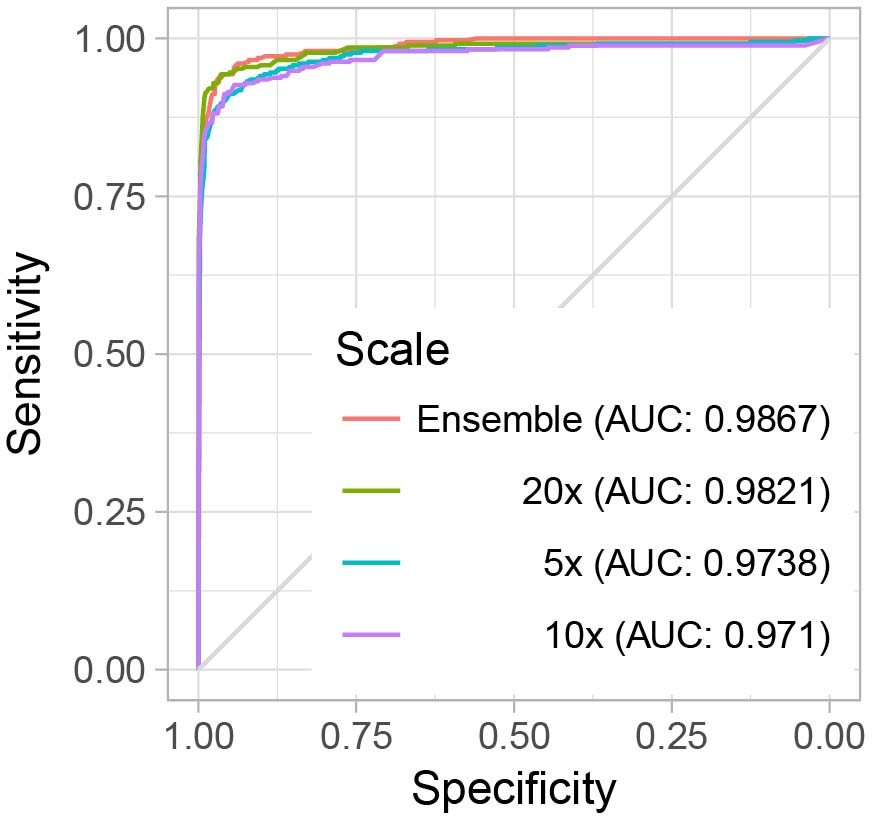
在20倍放大倍数下训练的模型在前列腺、BCC和腋窝淋巴结数据集的测试集上分别达到了0.986、0.986和0.965的AUC值,突显了所提出方法在从多种类型的组织中区分肿瘤区域和良性区域的效力。
2-2:分类准确率与数据集大小的关系
本研究对数据集大小与分类准确性的依赖关系进行了实验分析,以确定数据集是否足够大以至于在验证集上的错误率达到饱和。
实验中,前列腺数据集(不包括测试部分)被分为一个共同的验证集,包含2,000张切片,以及不同大小的训练集(100、200、500、1,000、2,000、4,000、6,000和8,000张切片),每个训练数据集都是之前所有数据集的超集。
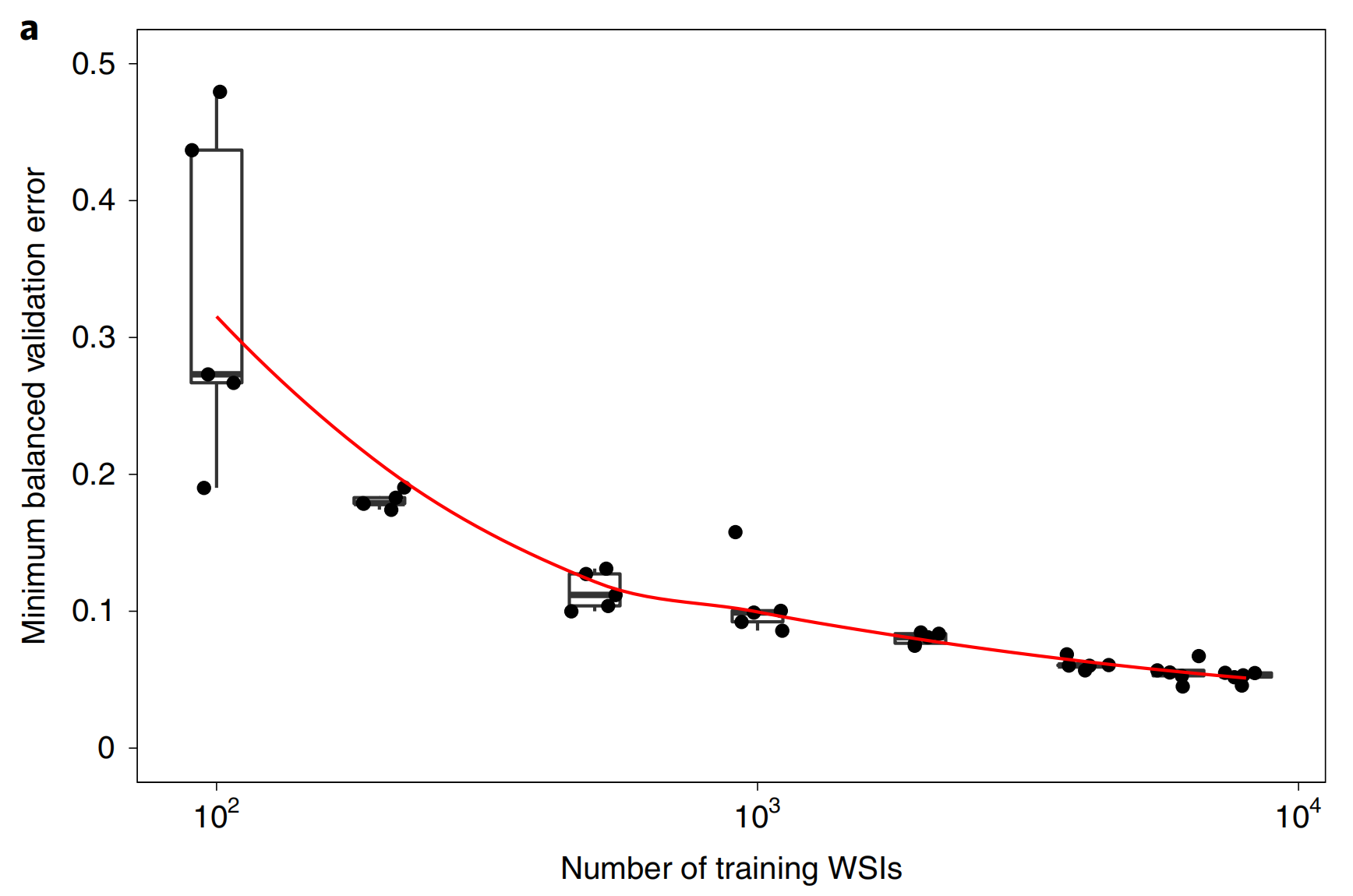
结果表明,虽然验证错误率开始趋于饱和,但可以预期,比本研究收集的数据集更大的数据集将带来进一步的改进(图2a)。
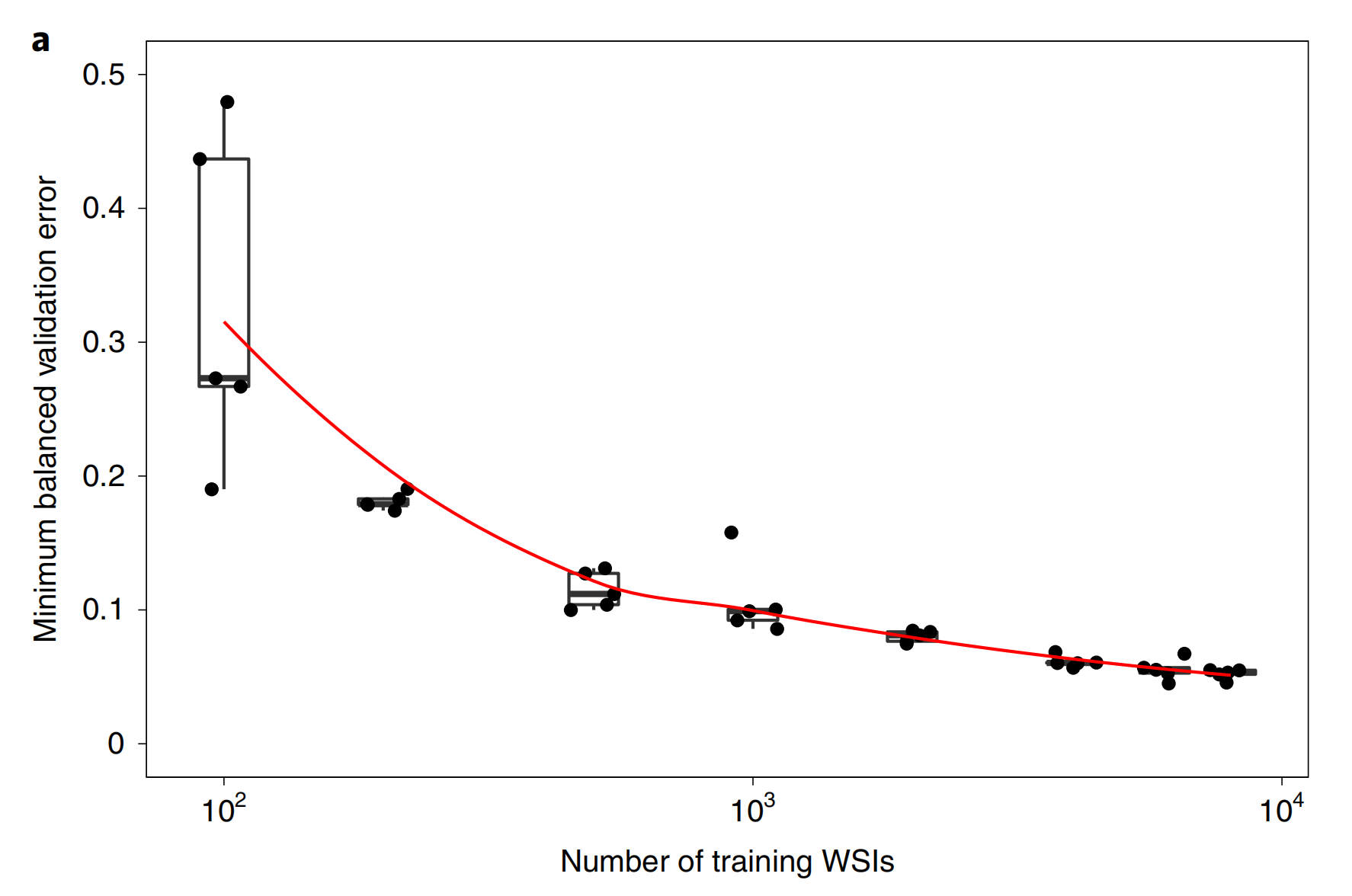
尽管达到满意结果所需的切片数量可能因组织类型而异,但总体上观察到,为了获得良好的性能,至少需要10,000张切片。
2-3:通过二维特征空间的可视化进行模型自省
Fig. 2 展示了数据集大小对临床级多实例学习(MIL)分类性能的影响以及模型的自省分析。
以下是对图的各部分的分析:
a. 数据集大小对MIL分类性能的影响:
- 研究表明,数据集的大小对于实现临床级的MIL分类性能至关重要。
- 使用不同大小的数据集对ResNet34模型进行了训练;对于每个报告的训练集大小,训练了五个模型,并将验证误差以箱形图的形式报告(n=5)。
- 这个实验强调了在MIL假设下,为了学习泛化,需要大量的切片。
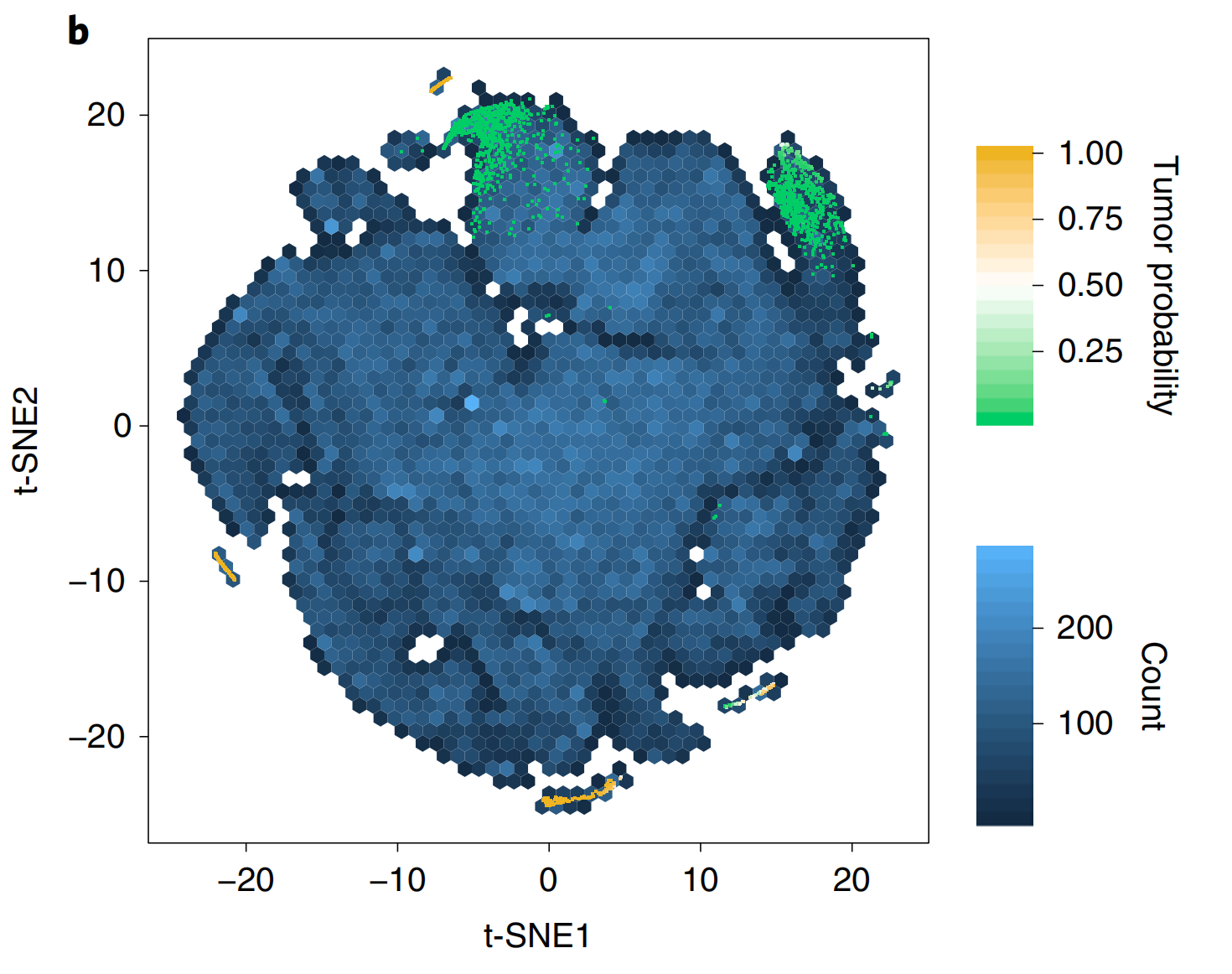
b. 前列腺模型学习到的特征表示:
- 前列腺模型学习到了组织病理学瓦片的丰富特征表示。
- 使用20倍放大倍数训练的ResNet34模型,获取了测试集中随机瓦片集合的最终分类层之前的特征嵌入(n=182,912)。
- 通过
t-SNE技术将嵌入降到二维,并使用六边形热图进行绘制。 - 来自阴性和阳性切片的排名最高的瓦片由颜色表示其肿瘤概率的点表示。
知识点补充:t-SNE技术
t-SNE(t-distributed Stochastic Neighbor Embedding)是一种用于高维数据可视化的机器学习算法 。它由Laurens van der Maaten和Geoffrey Hinton于2008年提出,特别适合于将具有复杂结构的高维数据集嵌入到二维或三维空间中,以便于可视化和分析。
t-SNE的工作原理可以概括为以下几个步骤:
-
概率分布:在原始高维空间中,t-SNE首先计算每个数据点与其邻居之间的相似度,并基于这些相似度构建一个概率分布,表示每个点被其邻居点表示的概率。
-
映射到低维空间:接着,t-SNE寻找一个低维(通常是二维或三维)空间,使得在这个新空间中,相似的数据点以高概率彼此接近,而不相似的数据点则以低概率接近。
-
优化 :通过优化一个
成本函数(通常是一个概率分布的距离度量),t-SNE调整低维空间中的数据点位置,以保持高维空间中的相似度结构。 -
迭代 :优化过程是迭代进行的,通常使用
梯度下降算法来逐步改善数据点在低维空间中的布局。
t-SNE的一些关键特点包括:
-
非线性 :t-SNE能够捕捉数据中的非线性结构,这使得它在处理复杂的、非线性可分的数据集时特别有效。
-
局部保持 :t-SNE倾向于保持高维空间中的局部结构,这意味着在原始空间中彼此接近的点,在低维可视化中也会彼此接近。
-
可视化 :t-SNE生成的二维或三维图形可以揭示数据中的聚类结构和异常点,这对于识别数据模式和理解数据分布非常有用。
然而,t-SNE也有一些局限性,比如计算成本较高,对于数据点的全局结构捕捉不如局部结构好 ,且对于参数选择敏感 ,特别是对于邻居数目和 perplexity(困惑度)参数的选择。此外,t-SNE的结果可能依赖于随机初始化,因此可能需要多次运行以获得稳定的结果。
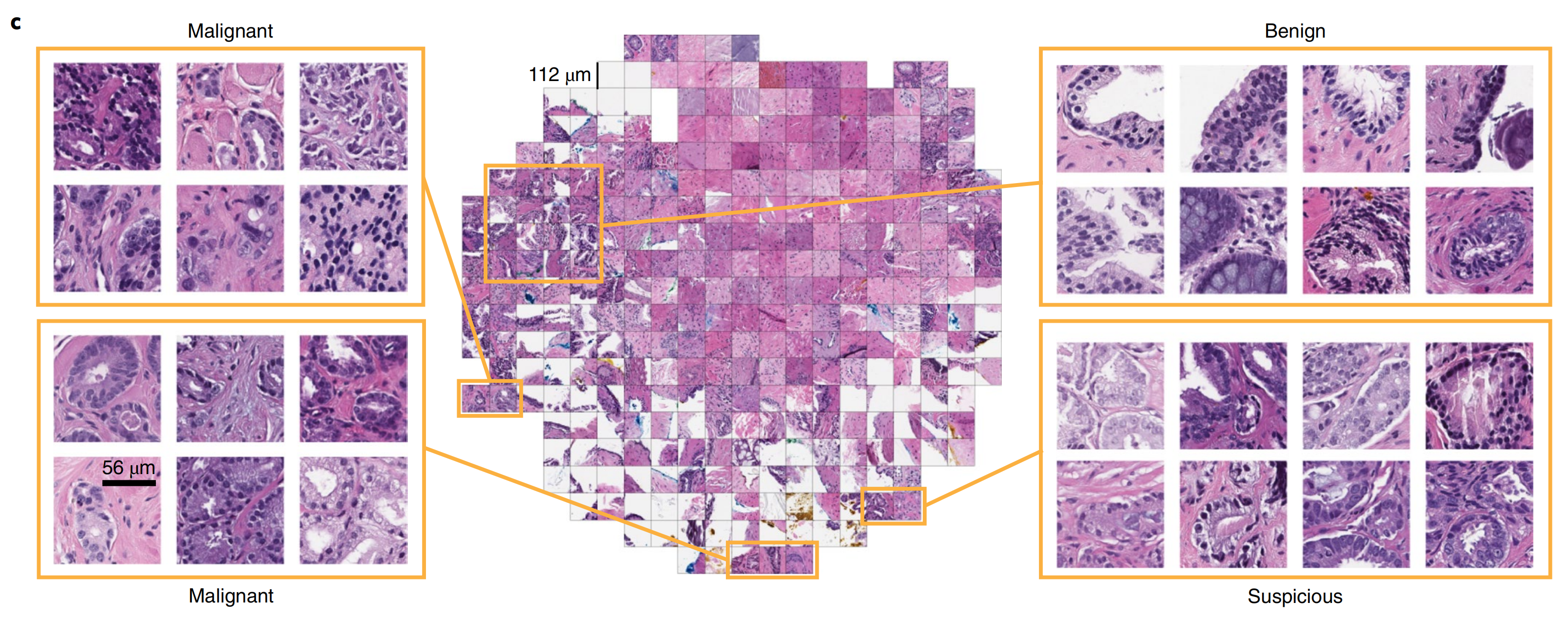
c. 模型自省分析:
- 从二维t-SNE空间中随机抽取了与点相对应的不同区域的瓦片。
- 异常腺体聚集在图表的底部和左侧。
- 肿瘤概率约为0.5的区域包含具有前列腺腺癌可疑特征的腺体。
- 正常腺体聚集在图表的左上区域。
知识点补充:模型自省分析
"模型自省分析"(Model introspection analysis)是一个涉及检查和解释机器学习模型内部工作机制的过程。这种分析的目的是更好地理解模型如何做出预测,以及模型预测背后的逻辑。
在深度学习和其他复杂模型中,模型自省分析尤为重要,因为这些模型的决策过程往往是一个"黑箱",难以直观理解。以下是模型自省分析中的一些关键方面:
-
特征重要性:确定哪些输入特征对模型的预测有最大的影响。
-
激活图分析:通过可视化神经网络中单个神经元的激活情况,来理解模型对特定特征的响应。
-
注意力机制:特别是在序列模型或卷积神经网络中,分析模型在做出决策时关注的输入数据的哪些部分。
-
层级结构可视化:对于深度神经网络,可视化网络中不同层级的激活,以理解模型如何从原始数据中抽象出复杂特征。
-
错误分析:研究模型预测错误的案例,以识别模型的弱点或潜在的改进空间。
-
对抗样本分析:通过分析对抗样本(即那些故意设计来误导模型的输入)来理解模型的脆弱性。
-
模型解释性工具 :使用诸如
LIME(局部可解释模型-不透明估计)、SHAP(SHapley Additive exPlanations)等工具来解释模型预测。 -
决策边界可视化:在二维或三维空间中可视化模型的决策边界,以理解模型如何区分不同的类别。
模型自省分析对于提高模型的透明度、增强用户对模型的信任、以及促进模型的公平性和可解释性至关重要。通过这种分析,研究人员和开发者可以更好地理解模型的行为,改进模型的性能,并确保模型的决策过程符合道德和法律标准。
知识点补充:模型解释性工具------
SHAP
关于这个工具,我之前写过一篇推文,感兴趣的同学欢迎前去考古。另外,偷偷透露一下,其实小罗最擅长的可是编程类的教程哦,跟着我的教程走,工科的合作对象都可以省了,前提是你有耐心看我的教程,哈哈。
2-4:不同切片聚合方法的比较
本研究比较了不同的载玻片聚合方法。
在多重实例学习(MIL)假设下的最大池化操作并不稳健,单个错误的分类可能导致整个载玻片的预测改变,从而可能产生大量的假阳性。
为了减轻这种错误,可以在MIL分类结果之上学习一个载玻片聚合模型。例如,Hou等人36采用基于由集成分类器预测的每个类别的切片数量来学习逻辑回归模型。同样,Wang等人18从由切片级分类器生成的肿瘤概率热图中提取几何特征,并训练了一个随机森林模型,赢得了CAMELYON16挑战。
遵循后一种方法,我们训练了一个随机森林模型,该模型基于从我们的MIL基础切片分类器生成的热图中手动提取的特征。对于前列腺癌分类,20倍放大倍数下训练的随机森林在测试集上产生了0.98的AUC,这与单独的MIL没有统计学上的显著差异(扩展数据图4)。
尽管这种方法大幅降低了假阳性率,并且在20倍放大倍数下比基本的最大池化聚合实现了更好的误差平衡,但这是以敏感度不可接受的降低为代价的。
先前的聚合方法没有利用在训练过程中学到的特征表示信息。给定一个切片的向量表示,即使单个切片没有被切片分类器分类为阳性,但它们结合起来可能足够可疑,以至于触发基于表示的载玻片级分类器的阳性响应。
基于这些想法和来自文献37的实证支持,我们引入了一个基于RNN的模型 ,该模型能够整合表示级别的信息,以发出最终的载玻片分类(图1d)。
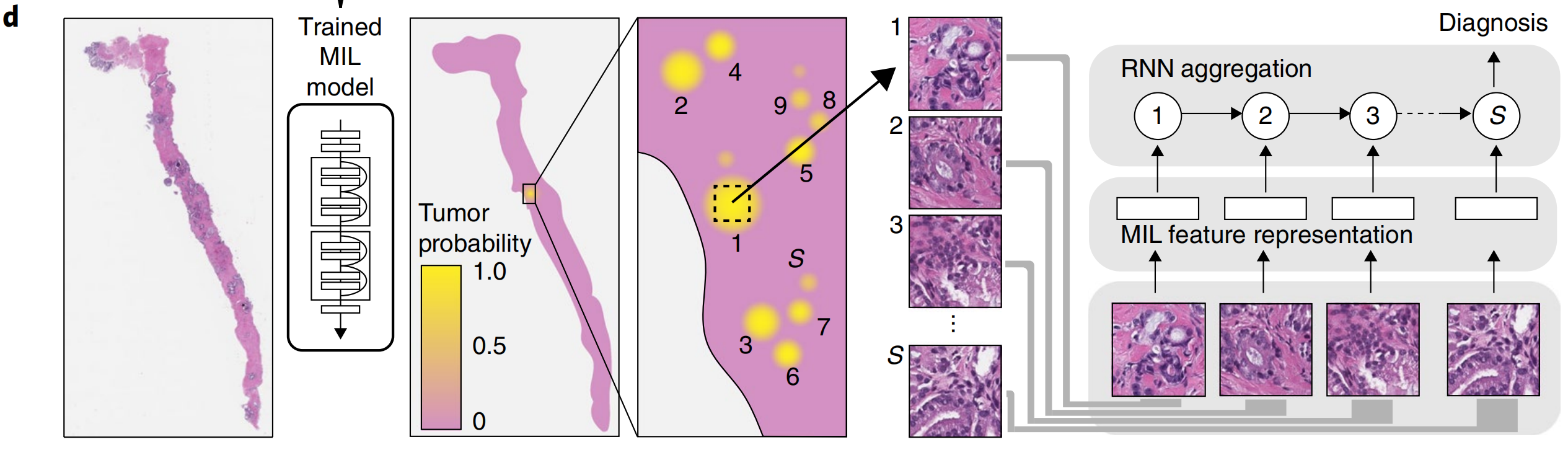
有趣的是,信息也可以跨不同的放大倍数整合,以产生多尺度分类。在20倍放大倍数下,MIL-RNN模型在前列腺、BCC和乳腺癌转移数据集上分别产生了0.991、0.989和0.965的AUC(图3)。
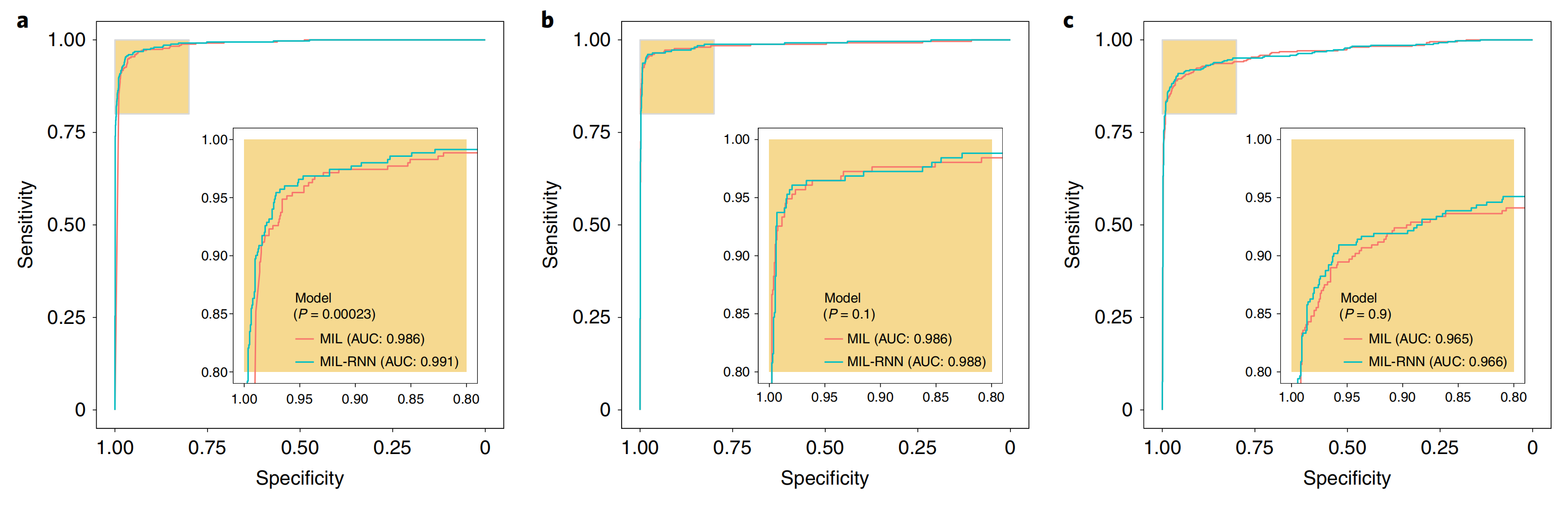
对于前列腺实验,MIL-RNN方法在统计上显著优于最大池化聚合。多尺度方法在前列腺数据上进行了测试,但其性能并不比在20倍放大倍数下训练的单尺度模型更好。
2-5:病理学专家对 MIL-RNN 误差模式的分析
病理学专家对MIL-RNN错误模式的深入分析表明,经过20倍放大训练的MIL-RNN模型在测试集上出现的错误主要包括假阴性和假阳性。
在
前列腺模型中
12个假阴性中有3个被算法正确预测为阴性,另外3个切片显示非典型的形态特征,但不足以诊断为癌症。确认的6个假阴性特征为肿瘤体积非常低。
考虑到对真实标签的更正,前列腺测试集的AUC从0.991提高到0.994。在72个假阳性中,算法错误地将小灶腺体识别为癌症,这些腺体通常具有深染的核和突出的核仁。许多标记的腺体还显示了腔内分泌物。总体上,算法将大多数这些病例报告为可疑是合理的,从而满足了筛查工具的要求。
对于
黑素细胞癌(BCC)模型
4个假阴性被更正为真阴性,4个假阳性被更正为真阳性。考虑到这些更正,BCC的AUC从0.988提高到0.994。12个假阴性病例的特征是肿瘤体积低,15个假阳性包括鳞状细胞癌和多种良性的皮肤肿瘤。
对于
乳腺癌转移模型
17个最初分类为假阴性的病例被正确分类为阴性,而4个切片显示可疑的形态特征,可能需要后续测试。总共21个假阴性被更正为真阴性,2个假阳性被更正为真阳性。假阴性到真阴性的更正是因为感兴趣的组织未能在更深的苏木精-伊红切片上显示,或在制备冷冻切片时发生了采样错误。假阳性到真阳性的更正是因为软组织转移灶或肿瘤栓塞。考虑到这些更正,AUC从0.965提高到0.989。
在23个假阴性中,8个是宏转移,13个是微转移,2个是孤立肿瘤细胞(ITCs)。值得注意的是,12个病例(4个假阴性和8个假阳性)显示了新辅助化疗的治疗效果迹象。
这些分析表明,尽管存在一些错误,但MIL-RNN模型在大多数情况下能够准确预测,并且对于一些错误,病理学专家的再评估表明这些错误可能是由于标签的不准确或切片的采样问题。这些发现强调了在临床应用中,人工智能模型的结果需要与病理学专家的判断相结合,并且对数据集进行细致的审查和验证是提高模型性能的关键。
2-6:调查多个机构和不同扫描仪在制片过程中产生的技术差异
本研究调查了不同机构和不同扫描仪引入的制片技术变异性。
计算病理学中存在多种可变性来源。除了所有形态学可变性之外,在玻璃制片和扫描过程中还会引入技术可变性。这种可变性如何影响辅助模型的预测是一个必须彻底研究的问题。
评估模型在不同扫描仪上数字化切片的性能对于在具有不同扫描仪厂商工作流程的部门或操作不同厂商扫描仪且没有培训符合其需求模型的设施的小型诊所中应用同一模型至关重要。
为了测试整个切片扫描仪类型对模型性能的影响,我们使用最近获得美国食品和药物管理局批准用于初步诊断的Philips IntelliSite Ultra Fast Scanner扫描了大量的内部前列腺测试集。我们观察到性能在AUC方面下降了3个百分点。
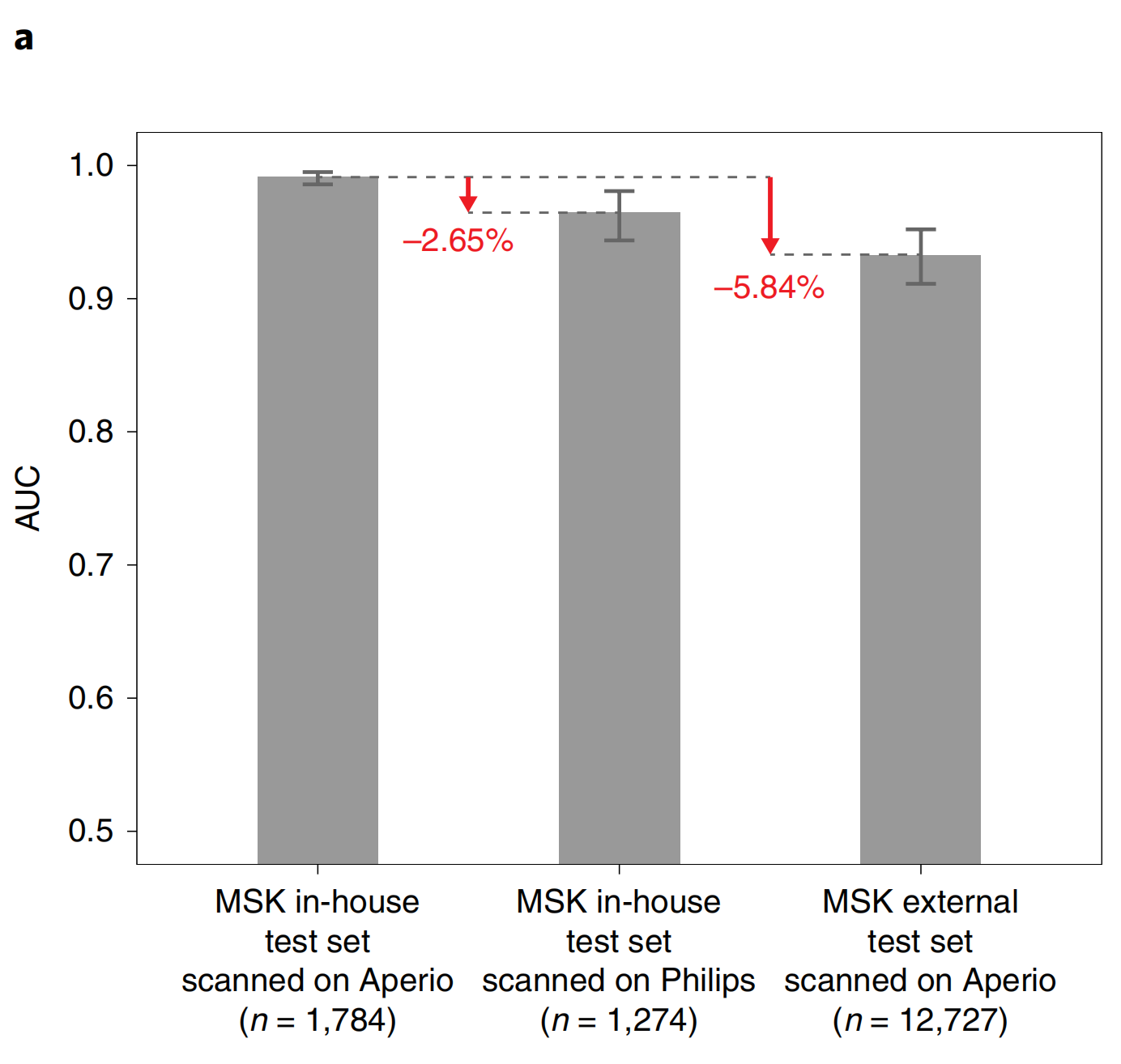
分析Leica Aperio WSIs和相应的Philips数字切片之间的预测不匹配揭示了亮度、对比度和锐度方面的感知差异,这可能会影响预测性能。实际上,进一步降低泛化误差的有效解决方案可能是训练混合数据集或在新型扫描仪上微调模型。
为了测量制片过程对模型性能的影响,我们收集了一个非常大的数据集,包含超过12,000张前列腺会诊切片,这些切片来自美国和其他国家的其他机构提交给纪念斯隆凯特琳癌症中心(MSK)。
需要注意的是,这些切片通常是诊断上具有挑战性的,是请求专家病理学家审查的基础。我们将20倍放大的MIL-RNN模型应用于大量提交的切片数据集,观察到AUC下降了约6个百分点(上图)。重要的是,性能下降主要表现在对新测试集的特异性上,而敏感性仍然很高。
2-7:完全监督学习与弱监督学习的比较
为了验证完全监督学习模式下,在小型、精心策划的数据集上训练的模型是否能够很好地转化为临床实践,本研究使用CAMELYON16数据集进行了几项实验。
CAMELYON16数据集包括270张训练切片的像素级注释,是迄今为止最大的公开数字病理学注释数据集之一。我们实现了一个基于Wang等人18的CAMELYON16挑战赛获胜团队的方法,用于自动检测转移性乳腺癌的模型。这种方法可以被认为是该任务的最先进技术,依赖于完全监督学习和像素级专家注释。
与文献18的主要区别在于我们使用的架构(ResNet34而不是GoogLeNetv3),他们使用的硬负挖掘,以及训练载玻片级随机森林分类器的特征。我们的实现方法在CAMELYON16测试集上达到了0.930的AUC,与文献18中的0.925相似。这个模型本可以赢得CAMELYON16挑战赛的分类部分,并在公开排行榜上排名第五。
在CAMELYON16上完全监督训练的同一模型应用于腋窝淋巴结数据集的MSK测试集,结果AUC为0.727,与其在CAMELYON16测试集上的表现相比下降了20%。
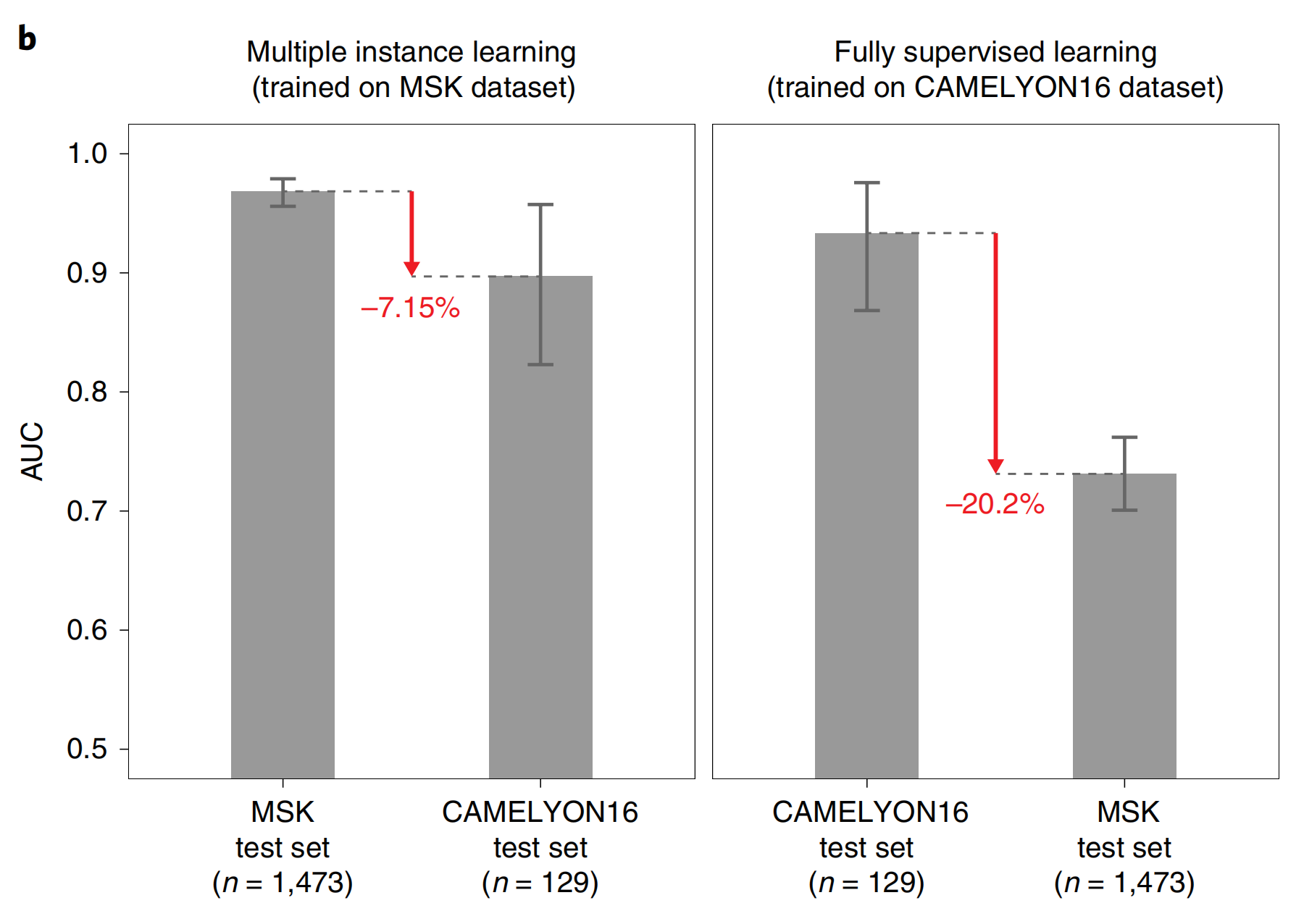
相反的实验,即在我们的MIL模型上训练MSK腋窝淋巴结数据并在CAMELYON16测试数据上测试,产生了0.899的AUC,与MSK测试集上的0.965相比,性能下降幅度要小得多。
这些结果表明,当前在小型数据集上训练的深度学习模型,即使具有详尽的像素级标签的优势,也无法泛化到临床级别的真实世界数据。
我们假设,小型、精心策划的数据集不足以捕捉癌症在生物学和形态学上的巨大变异性,以及组织病理学中染色和准备过程引入的技术变异性。我们的观察结果敦促在将深度学习模型应用于临床决策支持之前,对真实世界数据集进行谨慎和深入评估。
这些结果还表明,诸如本研究提出的弱监督方法与传统的完全监督学习相比具有明显优势,因为它们使大量、多样化的数据集训练成为可能,而无需数据策划。
三、讨论
本研究的核心假设是,在不需要对全切片图像(WSI)进行像素级注释的情况下,可以实现临床级别的性能。
为了验证这一假设,我们开发了一个结合卷积神经网络(CNN)和循环神经网络(RNN)的深度学习框架,采用多重实例学习(MIL)方法。
我们收集了一个包含来自15,187名患者的44,732张切片的大型数据集,涵盖了三种不同类型的癌症。我们构建了一个最先进的计算集群,这对于项目的可行性至关重要。广泛的验证实验证实了这一假设,并显示了临床级别决策支持的实现可能性。
这些结果的影响是深远的。
首先,由于不需要手动像素级注释,因此可以汇编出比以往研究大得多的数据集。
其次,这使得我们的算法能够从临床实践中向临床医生展示的全套切片中学到知识,代表了生物学和技术变异性的全部财富。
第三,因此不需要数据整理,因为模型可以学会识别哪些手工特征对于分类任务并不重要。
第四,上述两点使得使用本方法训练的模型能够更好地推广到病理实践中观察到的真实数据。
第五,泛化性能在临床上是相关的,所有测试的癌症类型的AUC值均大于0.98。
第六,我们严格定义了临床级别,并提出了将该系统整合到临床工作流程中的策略。
在完全运作的数字病理学部门,预测模型在每个扫描的切片上运行。
算法根据预测的肿瘤概率对病例和每个病例中的切片进行排序,一旦从病理实验室获得就立即进行。
在诊断报告中,病理学家通过一个界面收到模型的建议,该界面在筛查情景中会标记阳性切片以进行快速审查,或者在诊断情景中忽略所有良性切片。
在后者的情况下,我们的前列腺模型可以在不损失患者级别的敏感性的情况下,使病理学家的工作量减少超过75%。对于必须在癌症诊断的日益复杂、详细和数据驱动的环境中操作的病理学家来说,这样的工具将使他们能够处理非专业化的病理学。
Fig. 6 展示了所提出的决策支持系统对临床实践的影响。
以下是对图中两个主要部分的分析:
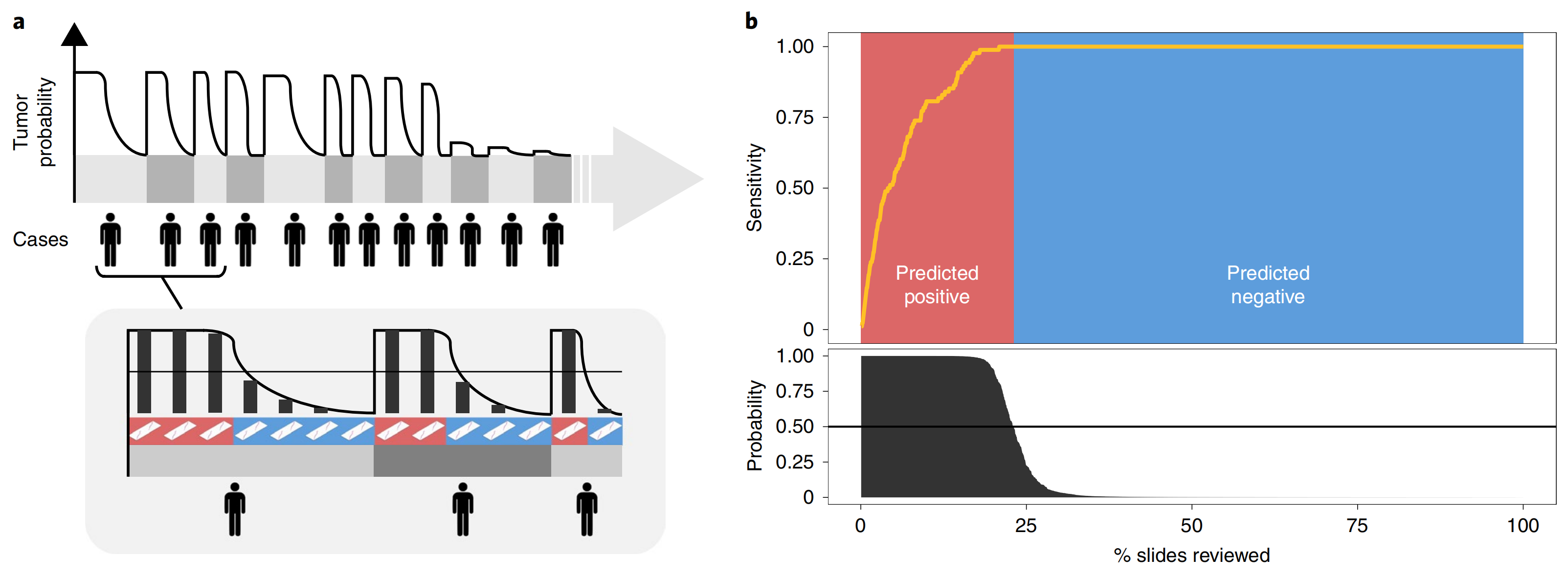
a. 基于肿瘤概率对病例和切片进行排序:
- 该图说明了如何根据肿瘤概率对病例和每个病例中的切片进行排序。
- 通过这种方式,病理学家可以将注意力集中在可能对癌症呈阳性的切片上。
- 这种排序机制允许病理学家更有效地分配他们的时间和资源,专注于那些更有可能含有肿瘤组织的样本,从而加快诊断过程并提高工作效率。
b. 遵循算法预测对病理学家工作量的影响:
- 该图说明了如果遵循算法的预测,病理学家可能忽略超过75%的切片,同时在病例层面保持对前列腺癌100%的敏感性(n=1,784)。
- 这意味着算法可以帮助排除那些不太可能包含癌症的切片,从而显著减少病理学家必须手动检查的切片数量。
- 通过减少需要检查的切片数量,算法不仅提高了病理学家的工作效率,还可能减少人为的错误和疏漏,因为它们可以更集中地检查剩余的切片。
总体而言,Fig. 6 强调了决策支持系统在临床病理诊断中的潜力,特别是在提高病理学家工作效率和诊断准确性方面。通过智能化地筛选和排序切片,该系统能够辅助病理学家更快速地识别出那些需要进一步检查的病例,从而在保持高敏感性的同时减少不必要的工作量。这对于病理诊断领域来说是一个重要的进步,因为它有助于解决病理学家面临的工作量过大和资源有限的问题。
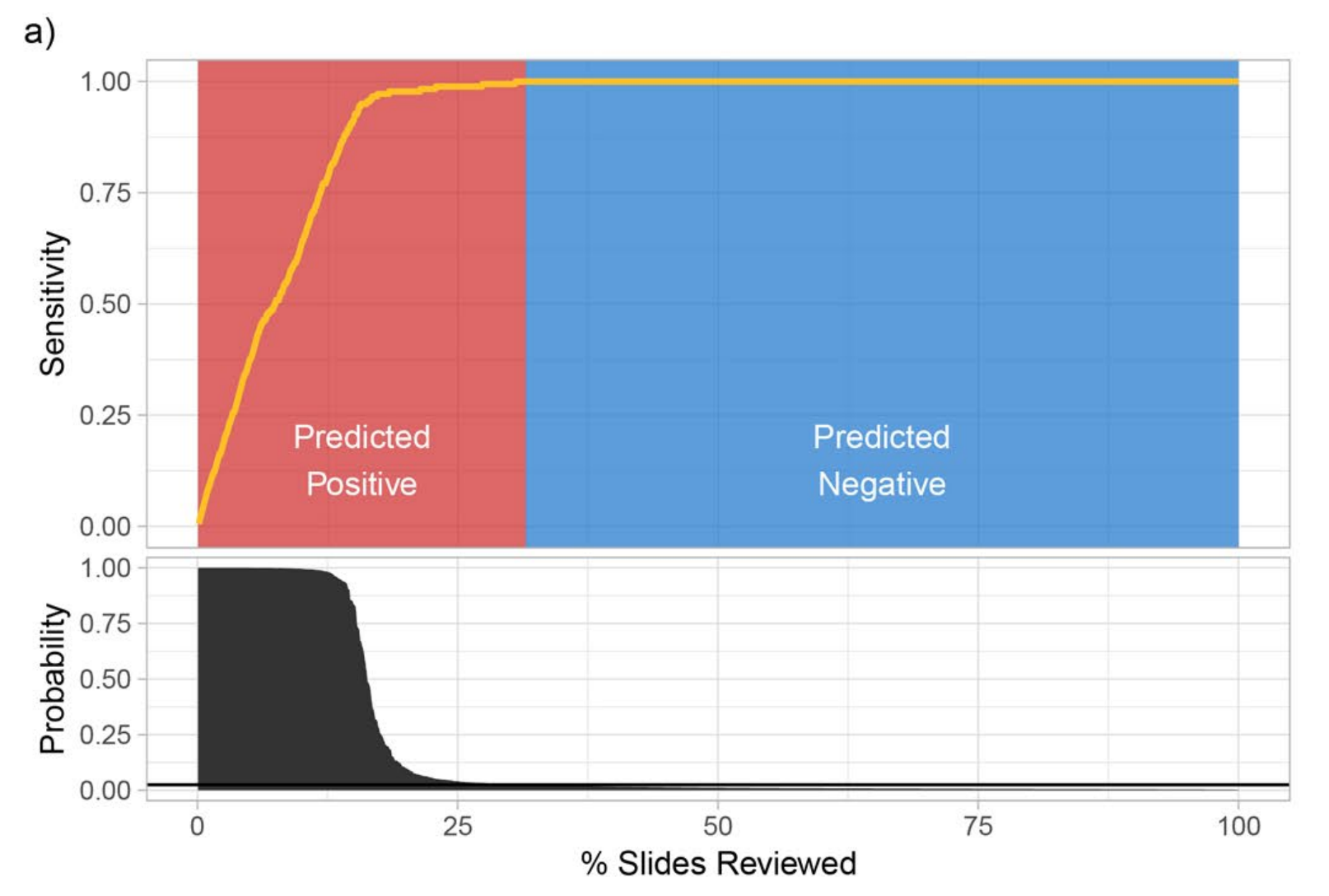
基底细胞癌(BCC)和乳腺癌转移模型中决策支持系统的应用。
以下是对图的两个主要部分的分析:
a. BCC模型的决策支持:
- 对于BCC数据集,共有1,575张切片。
- 根据MIL-RNN模型预测的癌症阳性概率对切片进行了排序。
- 当设定阳性预测阈值为0.025时,可以忽略大约68%的切片,同时在病例层面保持100%的敏感性。
- 这意味着在BCC的诊断中,该模型可以帮助病理学家排除大部分不太可能含有癌症的切片,显著减少需要手动检查的切片数量,同时确保不会漏掉任何真正的癌症病例。
b. 乳腺癌转移模型的决策支持:
- 对于乳腺癌转移数据集,共有1,473张切片。
- 同样地,切片根据MIL-RNN模型预测的癌症阳性概率进行了排序。
- 当设定阳性预测阈值为0.21时,可以忽略大约65%的切片,同时在病例层面保持100%的敏感性。
- 这表明在乳腺癌转移的诊断中,该模型同样能够高效地筛选出需要进一步检查的切片,减少病理学家的工作量,确保诊断的准确性。
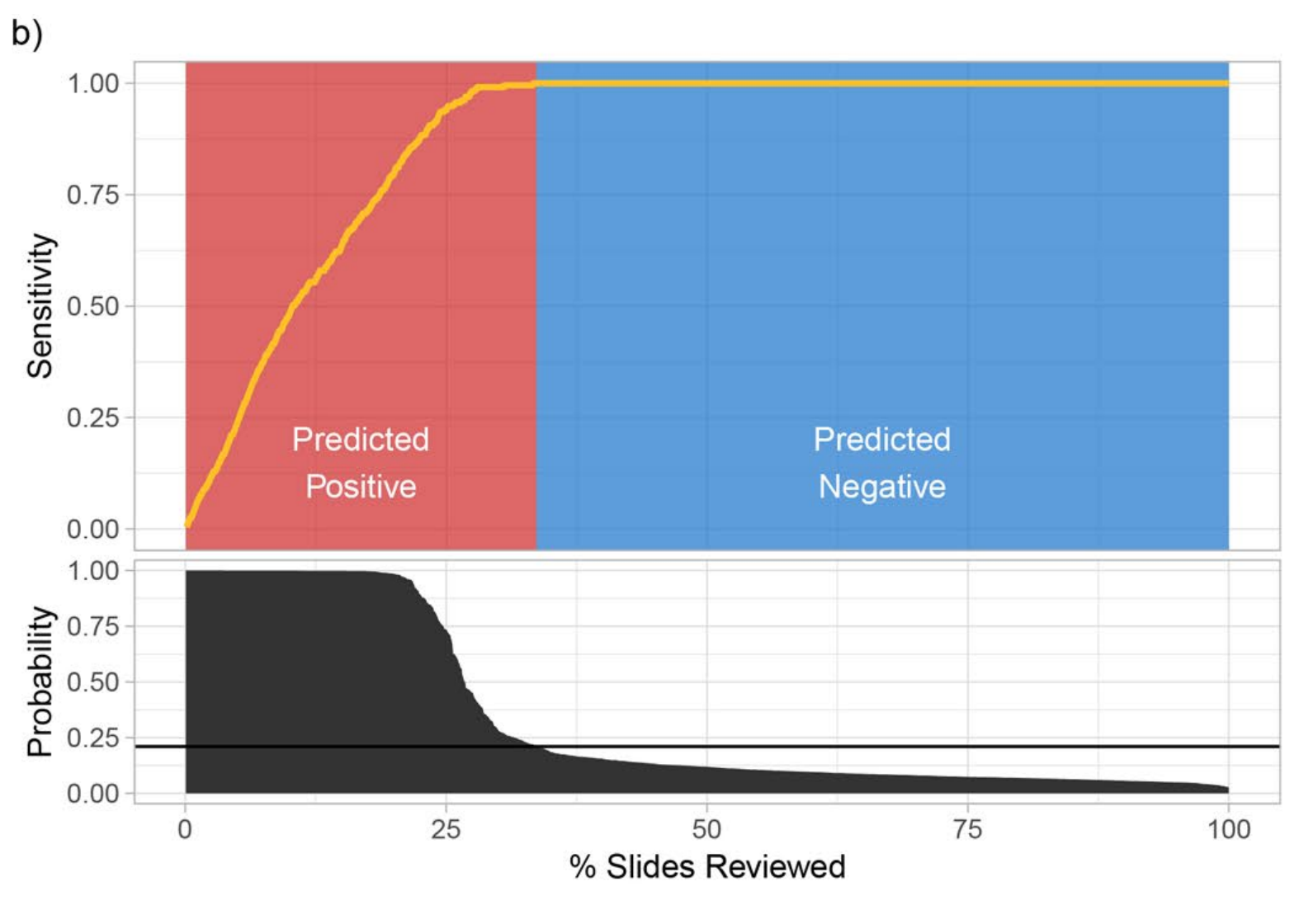
综合来看,Extended Data Fig. 6 强调了决策支持系统在提高病理诊断效率和准确性方面的潜力。通过MIL-RNN模型的预测,病理学家可以优先检查那些更有可能含有癌症的切片,同时安全地忽略那些预测为阴性的切片。这种方法不仅可以减轻病理学家的工作负担,还可以确保及时准确地诊断癌症,对于临床实践具有重要的意义。