文章目录
论文链接:Visual Prompt Multi-Modal Tracking
开源代码:Official implementation of ViPT
简介
这篇文章说了个什么事情呢,来咱们先看简单的介绍图

简单来说,这篇文章主要干了这么一个事情:
以前的多模态呢,都是直接提取特征然后拼接到一起。这个文章不一样,我把所有的模态分开主次,其中只有一个主要模态,剩下的都是附加的。这些附加的模态可就不要再提取特征了,而是通过他们来提取prompt出来。并且使用这些prompt来帮助我的模型更好的在主要模态上提取特征。除此之外,还有一个不一样的点就是在主要模态上提取特征的时候,backbone,这里叫fundation model的模型参数是不更新的。
OK,你已经看完这篇文章了。。当然啦,如果还想知道知道更多的技术细节,咱们接着往下看。
关于具体的思路
咱们来看第二张图,模型的详细介绍
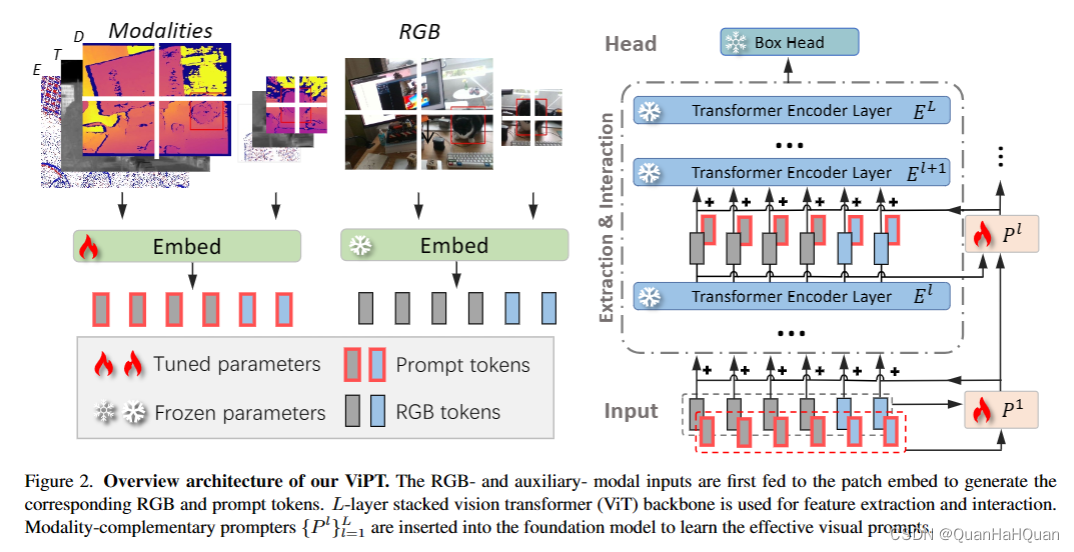
这个图其实画的很好,过程非常直观。接下来咱们只需要展开说说其中的细节就可以了
问题描述
首先,我们想要得到的是追踪器,单模态的方法中,假如说叫做 F R G B : { X R G B , B 0 } → B F_{RGB} : \{X_{RGB}, B_0\} \rightarrow B FRGB:{XRGB,B0}→B,那么 B B B就是目标的box, B 0 B_0 B0就是这个框的初始值, X R G B X_{RGB} XRGB就是需要搜索的帧。那么接下来,在多模态的方法中,加入了一个啥呢 F R G B : { X R G B , X A , B 0 } → B F_{RGB} : \{X_{RGB}, X_{A},B_0\} \rightarrow B FRGB:{XRGB,XA,B0}→B,变成这个样子了。其中这个 A A A代表的就是其他的模态,比如说深度图,热力图之类的东西。
接下来,我们把问题拆成两个部分,首先是 f 1 : X R G B , X A , B 0 } → H R G B f_1 : {X_{RGB}, X_{A},B_0\}} \rightarrow H_{RGB} f1:XRGB,XA,B0}→HRGB 。这个部分表示的是特征提取和交互的部分,之后我们紧跟 f 2 : H R G B → B f_2 : H_{RGB} \rightarrow B f2:HRGB→B ,这个部分也就是最后的预测头。
算法细节
在这里会将一些细节,但是也不会那么细。简单来说是这样的
- 使用类似ViT之类的模型从最初的 X R G B X_{RGB} XRGB得到 H R G B 0 H^0_{RGB} HRGB0,接下来就可以进行后续的迭代编码:
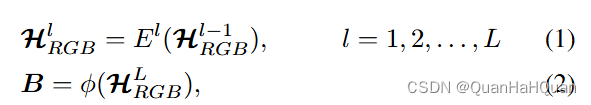
- 然后的公式其实就很直观了哈,咱们紧接上一步,接着往下看。首先我们可以知道,通过RGB和补充模态A,我们可以得到两个初始化的值 H R G B 0 H^0_{RGB} HRGB0和 H A 0 H^0_{A} HA0。接下来, H R G B 0 H^0_{RGB} HRGB0通入我们的解码器,或者叫Foundation model,而 H R G B 0 H^0_{RGB} HRGB0和 H A 0 H^0_{A} HA0被送到一个叫做MCP (modality-complementaryprompter) 的模块里面,这个模块咱们之后细讲。接下来,从MCP学到的prompt就被按照这样的方式使用起来了:
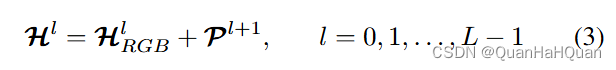
这个其中的P其实就是我们的prompt,H就是我们需要送入下一层解码器的输入。那么这个具体怎么得到呢?咱们再往下看 - 简单来说,MCP就是这个样子:
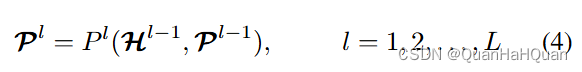
展开来说呢, H 0 = H R G B 0 H^0 = H^0_{RGB} H0=HRGB0, P 0 = H A 0 P^0 = H^0_{A} P0=HA0。然后 P l P^l Pl表示第l个MCP模块,这个MCP模块具体长成这样:
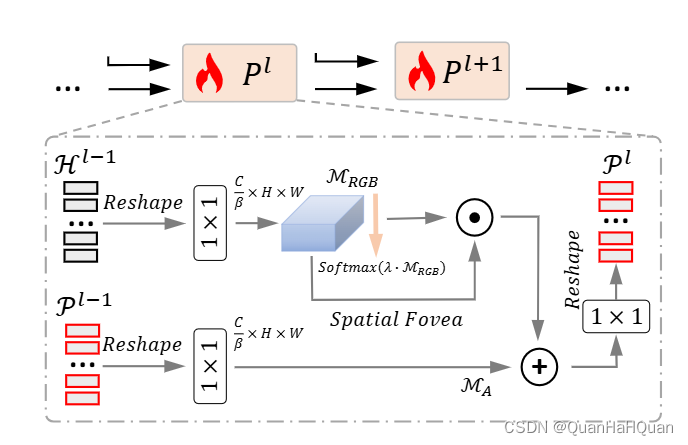
- OK,细节基本就是这样,再具体的可以去看一下原来的论文。
实验结果
模型的潜力
- better adaptability than full fine-tuning
- a closer association between RGB and RGB+auxiliary modality tracking, as well as learning about the modal complementarities
- 其实说白了就是更好的适应性和更好的学习能力
模型结果
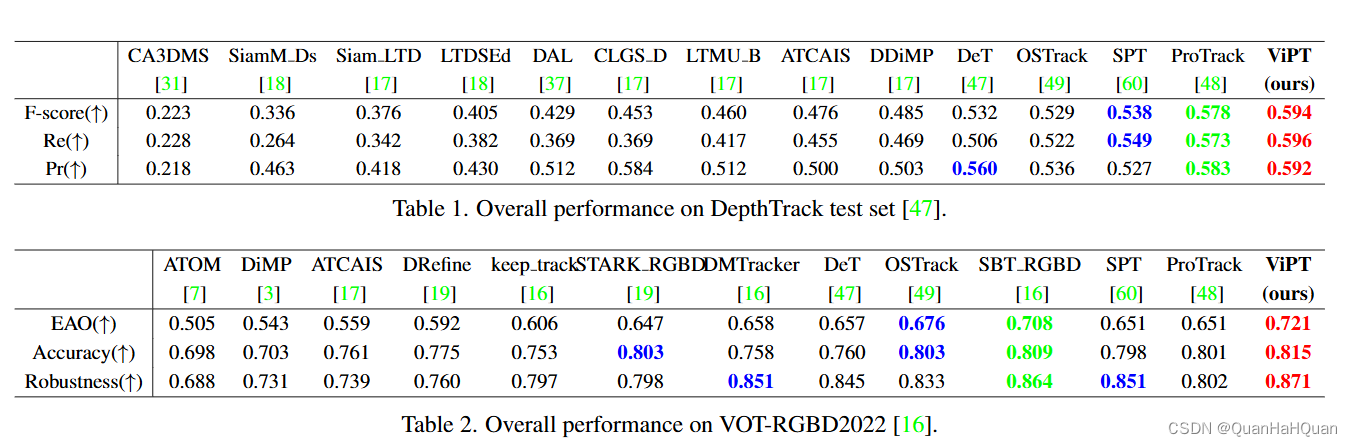

OK,那么以上就是本篇文章的全部内容了,感兴趣的小伙伴可以点击开头的链接阅读原文哦
关于更多的文章,请看这里哦文章分享专栏 Paper sharing Blog