今天,通义千问团队带来了Qwen2系列模型,Qwen2系列模型是Qwen1.5系列模型的重大升级。包括了:
-
5个尺⼨的预训练和指令微调模型, 包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B;
-
在中⽂英语的基础上,训练数据中增加了27种语⾔相关的⾼质量数据;
-
多个评测基准上的领先表现;
-
代码和数学能⼒显著提升;
-
增⼤了上下⽂⻓度⽀持,最⾼达到128K tokens(Qwen2-72B-Instruct) 。

Qwen2介绍
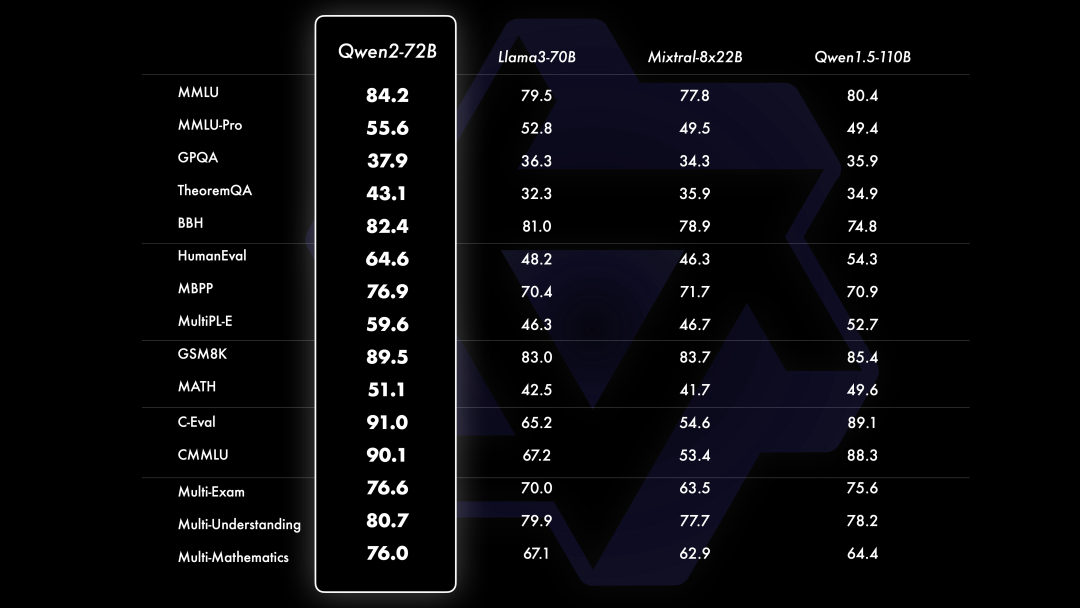
相⽐Qwen1.5,Qwen2在⼤规模模型实现了⾮常⼤幅度的效果提升。如下我们针对Qwen2-72B进⾏评测。在针对预训练语⾔模型的评估中,对⽐当前最优的开源模型,Qwen2-72B在包括⾃然语⾔理解、知识、代码、数学及多语⾔等多项能⼒上均显著超越当前领先的模型,如Llama-3-70B以及Qwen1.5最⼤的模型Qwen1.5-110B。这得益于其预训练数据及训练⽅法的优化。
在⾃然语⾔理解和逻辑推理等⽅⾯,尤其是科学类问题上,Qwen2-72B的优势更为明显。⽽在代码测试中,Qwen2-72B同样取得不俗的成绩,并且在多个编程语⾔上都有较为突出的表现。数学能⼒则由于其预训练数据中数学部分的优化实现了⼤幅度提升。此外,在⼤家较为关注的多语⾔的表现上,Qwen2-72B在多个领域的多语⾔评测上均具有⼀定的优势。这也意味着,Qwen2有潜⼒在更多的国家和地区得到落地应⽤。
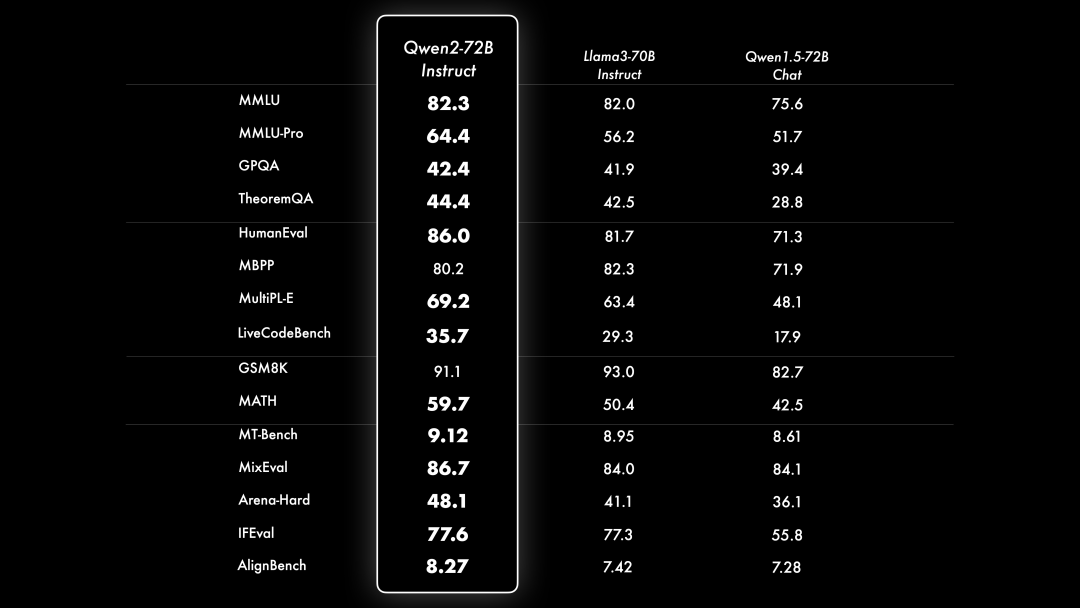
在微调和对⻬上投⼊了⼤量的精⼒进⾏研究。Qwen2的策略包括⼴泛采集指令和提示词,以及利⽤合成数据,如使⽤拒绝采样、代码执⾏反馈、回译等⽅法。为了进⼀步和⼈类偏好对⻬,Qwen2采⽤了DPO的⽅法。除了使⽤常⻅的DPO及DPO的变体如IPO、KTO外,Qwen2还探索了DPO与在线学习的结合,从⽽提升模型能⼒的上限。⽽为了降低对⻬所产⽣的"对⻬税",Qwen2使⽤模型合并的⽅法来缓解此问题。这⼀系列的努⼒最终帮助我们⼤幅度的提升了指令微调模型的基础能⼒以及智⼒等。结果如下所示:
⽽在较⼩的模型规模上,Qwen2同样是各个模型尺⼨上的佼佼者。详细请关注魔搭社区的每个模型的模型介绍页面。
长文本处理
Qwen2系列中的所有Instruct模型,均在32k上下文长度上进行训练,并通过YARN或Dual Chunk Attention等技术扩展至更长的上下文长度。
下图展示了我们在Needle in a Haystack测试集上的结果。值得注意的是,Qwen2-72B-Instruct能够完美处理128k上下文长度内的信息抽取任务。结合其本身强大的性能,只要有充足的算力,它一定能成为你处理长文本任务的首选!
此外,Qwen2系列中的其他模型的表现也十分突出:Qwen2-7B-Instruct几乎完美地处理长达128k的上下文;Qwen2-57B-A14B-Instruct则能处理64k的上下文长度;而该系列中的两个较小模型则支持32k的上下文长度。
除了长上下文模型,我们还开源了一个智能体解决方案,用于高效处理100万tokens级别的上下文。
安全
下表展示了大型模型在四种多语言不安全查询类别(非法活动、欺诈、色情、隐私暴力)中生成有害响应的比例。测试数据来源于Jailbreak,并被翻译成多种语言进行评估。我们发现Llama-3在处理多语言提示方面表现不佳,因此没有将其纳入比较。通过显著性检验(P值),我们发现Qwen2-72B-Instruct模型在安全性方面与GPT-4的表现相当,并且显著优于Mistral-8x22B模型。