Poly
学习率调整策略需要继承_LRScheduler类,该类包含三个重要属性和两个重要方法
学习率与batch-size的关系
一般来说,batch-size的大小一般与学习率的大小成正比。batch-size越大一般意味着算法收敛方向的置信度越大,也可以选择较大的学习率来加快收敛速度。而小的batch-size规律性较差,需要小的学习率保证不出错。在显存允许的情况下,选择大的batch-size。
预设规则的学习率变化法:StepLR、Multi-StepLR
自适应的学习率变化法:ExponentialLR,CosineAnnealingLR,LambdaLR,OneCycleLR,Poly
Poly学习率调整策略的优点包括:
更好的泛化能力:Poly学习率调整策略可以在训练后期逐渐降低学习率,避免过拟合,提高模型的泛化能力。
对超参数不敏感:Poly学习率调整策略的性能不太受超参数的影响,相对比较稳定。
计算量较小:Poly学习率调整策略的计算量相对较小,不会影响训练速度。
Poly学习率调整策略的缺点包括:
收敛速度较慢:Poly学习率调整策略在训练初期学习率较低,收敛速度较慢。
不适用于所有模型:Poly学习率调整策略可能不适用于所有类型的模型,需要根据具体情况进行选择。
code 如下
python
from torch.optim.lr_scheduler import _LRSchedule
from torch.optim.optimizer import Optimizer
// 定义
class PolyLR(_LRScheduler):
def __init__(self,optimizer,max_iters,power=0.9,last_epoch=-1,min_lr=1e-6):
# super(PolyLR,self).__init__(optimizer,last_epoch)
self.power = power
self.max_iters = max_iters
self.min_lr = min_lr
super(PolyLR, self).__init__(optimizer, last_epoch)
def get_lr(self) -> float:
return [ max( base_lr * ( 1 - self.last_epoch/self.max_iters )**self.power, self.min_lr)
for base_lr in self.base_lrs]
model = AlexNet(num_classes=2)
optimizer = torch.optim.Adam(model.parameters(),lr=0.1)
scheduler = PolyLR(optimizer, max_iters=150, power=0.9, last_epoch=-1, min_lr=1e-6)使用方法和位置
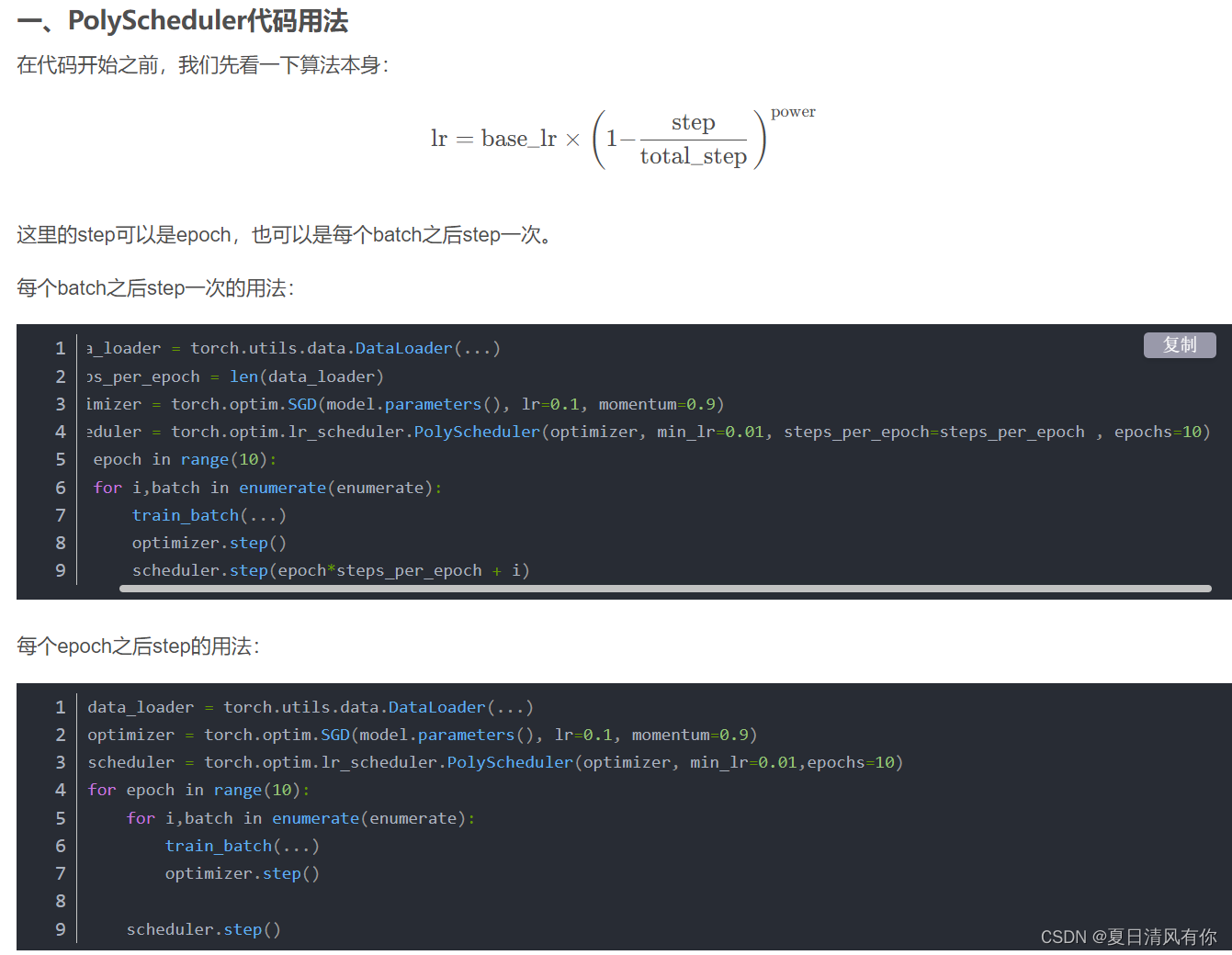
参考链接:1 https://blog.csdn.net/shengweiit/article/details/130649229
2 https://blog.csdn.net/qq_31580989/article/details/121491181