准备深入学习transformer,并参考一些资料和论文实现一个大语言模型,顺便做一个教程,今天是第二部分。
本系列禁止转载,主要是为了有不同见解的同学可以方便联系我,我的邮箱 fanzexuan135@163.com
使用注意力Dropout减少过拟合
在上一节中,我们通过在注意力权重矩阵中应用因果注意力掩码,实现了因果注意力机制。除了因果注意力掩码之外,我们还可以添加一个Dropout掩码来随机遮盖一些注意力权重,以减少过拟合。
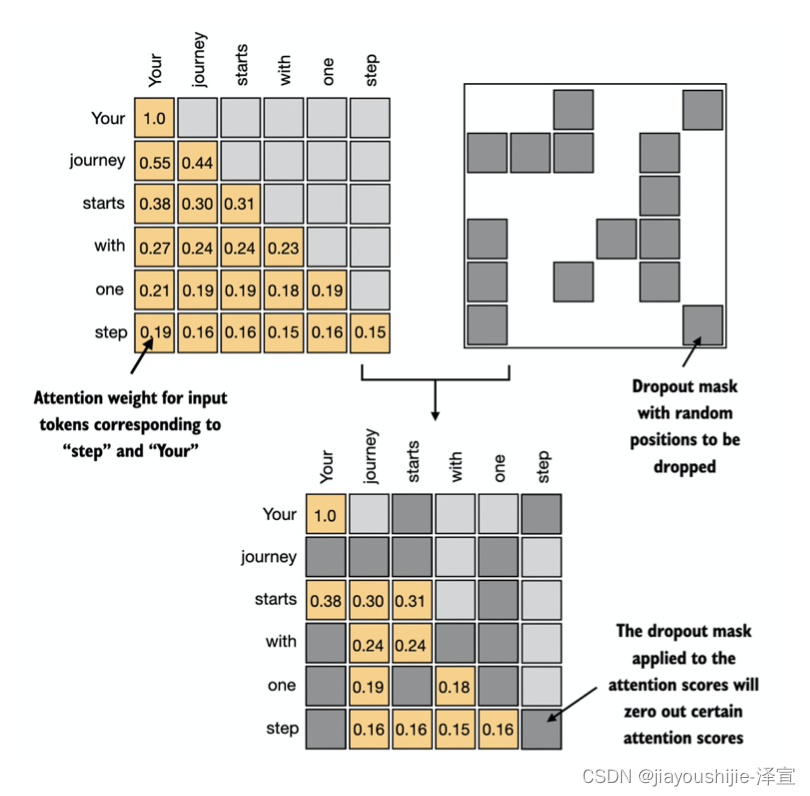
Dropout是深度学习中常用的一种正则化技术。在训练过程中,Dropout会随机遮盖(置零)一些神经元的激活值。这种方法可以防止模型过度依赖某些特定的隐层单元,从而提高模型的泛化能力。需要注意的是,Dropout只在训练阶段使用,在推理阶段需要关闭。
在Transformer架构中,包括GPT等模型,通常在两个地方应用Dropout:计算注意力分数之后,或者在将注意力权重应用于值向量之后。这里我们选择在计算注意力权重之后应用Dropout掩码,因为这是实践中更常见的做法。
在下面的代码示例中,我们使用0.5的Dropout率,即随机遮盖一半的注意力权重。(在后面章节中训练GPT模型时,我们会使用更小的Dropout率,如0.1或0.2。)
python
import torch.nn as nn
torch.manual_seed(1337)
dropout = nn.Dropout(0.5) # 定义一个Dropout层
example = torch.ones(6, 6) # 创建一个全1矩阵
print(dropout(example))输出:
tensor([[2., 0., 2., 2., 0., 2.],
[2., 0., 0., 2., 2., 2.],
[2., 0., 2., 0., 2., 0.],
[2., 2., 2., 0., 0., 2.],
[2., 2., 2., 2., 0., 2.],
[0., 0., 0., 0., 2., 2.]])可以看到,Dropout层随机将矩阵中大约一半的元素置零。当我们将Dropout应用于注意力权重矩阵时,就相当于随机遮盖矩阵中的一些元素。为了补偿激活单元数量的减少,Dropout会将保留下来的元素的值放大一倍(因子为 1 1 − p \frac{1}{1-p} 1−p1,其中 p p p为Dropout率)。这种缩放对于在训练和推理阶段保持注意力权重的整体平衡至关重要。
现在,让我们将Dropout应用到注意力权重矩阵本身:
python
torch.manual_seed(42)
print(dropout(attn_weights))结果如下:
tensor([[1.0734, 0.0000, 0.0000, 0.0000, 0.8566, 0.0000],
[1.1854, 0.8846, 0.0000, 0.0000, 1.4744, 0.0000],
[0.0000, 1.1720, 0.7676, 0.0000, 0.0000, 0.0000],
[1.6606, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[1.5157, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 1.4510, 0.0000, 0.0000, 1.6292, 0.0000]],
grad_fn=<MulBackward0>)注意力权重矩阵中有更多的元素被置零,而剩余的元素的值被相应放大。
至此,我们已经了解了因果注意力和Dropout掩码的实现原理。下一节,我们将开发一个简洁的Python类来实现它们。这个类可以方便地集成到后续章节中的语言模型中去。
实现一个紧凑的因果注意力类
在前面的小节中,我们已经一步步实现了包含因果注意力和Dropout的注意力机制。为了方便后续在语言模型中使用,我们将把这些功能封装到一个名为CausalAttention的Python类中。
这个类与之前实现的SelfAttentionV2类非常相似,主要区别在于增加了Dropout和因果掩码。另外,为了处理来自第2章数据加载器生成的批次数据,我们还需要确保代码能够处理批次大小(batch size)大于1的情况。
为了简单起见,我们通过复制输入文本来模拟批次输入:
python
batch = torch.stack([inputs, inputs], dim=0)
print(batch.shape) 这会生成一个形状为(2, 6, 3)的3D张量,表示有2个输入文本,每个文本包含6个token,每个token是一个3维的嵌入向量。
以下是CausalAttention类的实现,其中高亮部分为新增的Dropout和因果掩码相关代码:
python
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout) # Dropout层
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length), diagonal=1) # 因果掩码
)
def forward(self, x):
b, num_tokens, d_in = x.shape # 新的批次维度b
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1,2)
attn_scores.masked_fill_( # 应用因果掩码
self.mask.bool()[:num_tokens, :num_tokens], torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights) # 应用Dropout掩码
context_vec = attn_weights @ values
return context_vec虽然除了高亮部分的新增代码,其他代码行在之前的小节中都已经出现过,但这里我们在__init__方法中使用了self.register_buffer。在PyTorch中,register_buffer的使用并不是绝对必要的,但在这里它提供了一些优势。例如,当我们在后续章节中使用CausalAttention类构建语言模型时,通过register_buffer注册的张量会随着模型一起自动移动到相应的设备(CPU或GPU)上。这意味着我们不需要手动确保这些张量与模型参数在同一设备上,从而避免设备不匹配的错误。
我们可以像使用之前的SelfAttention类一样使用CausalAttention类:
python
torch.manual_seed(1337)
context_length = batch.shape[1]
ca = CausalAttention(d_in, d_out, context_length, 0.5)
context_vecs = ca(batch)
print(context_vecs.shape, context_vecs.shape)输出的context_vecs张量形状为(2, 6, 3),其中第一维表示批次中的文本数量,第二维表示每个文本的token数,第三维表示每个token对应的3维嵌入向量。
图15提供了一个思维导图,总结了我们在本章中实现的4种不同的注意力模块。
图15 注意力机制模块总结
如图15所示,在本小节中,我们重点关注了神经网络中的因果注意力机制的概念和实现。在下一小节,我们将在此基础上实现多头注意力模块。
从单头注意力扩展到多头注意力
在本章的最后一节,我们将之前实现的因果注意力类扩展为多头注意力。术语"多头"是指将注意力机制划分为多个独立运行的"头"。在这种情况下,单个因果注意力模块可以被视为单头注意力,其中只有一组注意力权重按顺序处理输入。
在接下来的小节中,我们将逐步实现这种从因果注意力到多头注意力的扩展。第一小节将直观地通过堆叠多个CausalAttention模块来构建一个多头注意力模块,以说明其原理。第二小节将以更复杂但计算效率更高的方式实现相同的多头注意力模块。
堆叠多个单头注意力层
实际上,实现多头注意力需要创建注意力机制的多个实例(如图12所示),每个实例都有自己的权重,然后组合它们的输出。使用多个自注意力机制实例的计算开销可能很大,但对于Transformer等模型所擅长的复杂模式识别任务来说,这一步骤至关重要。
多头注意力背后的主要思想是多次(并行)运行注意力机制,每次使用不同的学习线性投影。在之前的MultiHeadAttentionWrapper类中,通过创建一个CausalAttention对象的列表(self.heads)来实现多个头,每个对象代表一个独立的注意力头。CausalAttention类独立执行注意力机制,然后将每个头的结果连接起来。相比之下,下面的MultiHeadAttention类在单个类内实现多头功能。它通过重塑投影的query、key和value张量来将输入拆分为多个头,然后在计算注意力后组合这些头的结果。
让我们看一下MultiHeadAttention类的代码,然后进一步讨论它:
python
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
attn_scores = queries @ keys.transpose(-2, -1)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(
mask_bool[None, None, :, :], torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = (attn_weights @ values).transpose(1, 2)
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vec 尽管由于张量的重塑(view)和转置(transpose)操作,MultiHeadAttention类中的代码看起来非常复杂,但从数学角度来看,MultiHeadAttention类实现了与之前的MultiHeadAttentionWrapper相同的概念从高层次来看,在之前的MultiHeadAttentionWrapper中,我们通过堆叠多个单头注意力层来创建一个多头注意力层。而MultiHeadAttention类采取了一种集成的方法。它从一个多头层开始,然后在内部将这个层拆分为单个的注意力头,如图17所示。

图17 MultiHeadAttention类内部的张量分割
在MultiheadAttentionWrapper类中,我们为每个注意力头初始化了两个权重矩阵 W 1 Q W^Q_1 W1Q和 W 2 Q W^Q_2 W2Q,并计算了两个query矩阵 Q 1 Q_1 Q1和 Q 2 Q_2 Q2,如图17上半部分所示。而在MultiHeadAttention类中,我们只初始化一个更大的权重矩阵 W Q W^Q WQ,执行一次矩阵乘法得到query矩阵 Q Q Q,然后将 Q Q Q分割为 Q 1 Q_1 Q1和 Q 2 Q_2 Q2,如图17下半部分所示。对于keys和values,我们做了类似的处理,只是为了减少视觉混乱,图中没有展示。
这种张量分割是通过PyTorch的view和transpose方法实现的。输入首先经过线性层转换(用于queries、keys和values),然后被重塑以表示多个头。
关键操作是将d_out维度分割为num_heads和head_dim,其中head_dim = d_out // num_heads。这种分割是使用view方法实现的:形状为(b, num_tokens, d_out)的张量被重塑为(b, num_tokens, num_heads, head_dim)。
然后,张量被转置,将num_heads维度移到num_tokens维度之前,得到形状为(b, num_heads, num_tokens, head_dim)的张量。这种转置对于在不同的头上正确对齐queries、keys和values,以及高效地执行批量矩阵乘法至关重要。
为了说明这种批量矩阵乘法,假设我们有如下示例张量:
python
a = torch.tensor([[[1, 2],
[3, 4],
[5, 6]],
[[7, 8],
[9, 10],
[11, 12]]]) 现在,我们执行a与其转置视图的批量矩阵乘法:
python
print(a @ a.transpose(-2, -1))结果如下:
tensor([[[ 5, 11, 17],
[11, 25, 39],
[17, 39, 61]],
[[61, 77, 93],
[77, 97, 117],
[93, 117, 141]]])在这种情况下,PyTorch中的矩阵乘法实现处理了3维输入张量,使得矩阵乘法在最后两个维度(num_tokens, head_dim)之间执行,然后为各个头重复这个过程
事实上,上面的代码等价于分别计算每个头的矩阵乘法:
python
first_head = a[0]
first_res = first_head @ first_head.T
print("First head:\n", first_res)
second_head = a[1]
second_res = second_head @ second_head.T
print("\nSecond head:\n", second_res)结果与之前使用批量矩阵乘法print(a @ a.transpose(-2, -1))得到的结果完全一致:
First head:
tensor([[ 5, 11, 17],
[11, 25, 39],
[17, 39, 61]])
Second head:
tensor([[ 61, 77, 93],
[ 77, 97, 117],
[ 93, 117, 141]])继续看MultiHeadAttention类,在计算注意力权重和上下文向量之后,来自所有头的上下文向量先被转置回形状(b, num_tokens, num_heads, head_dim),然后被重塑(展平)为形状(b, num_tokens, d_out),从而有效地组合了所有头的输出。
此外,我们在MultiHeadAttention中添加了一个输出投影层(self.out_proj),它在组合头部之后应用。这个输出投影层在CausalAttention类中不存在。虽然输出投影层并不是绝对必要的(详见附录B的参考文献部分),但它在许多语言模型架构中都有使用,所以为了完整性,我们在这里添加了它。
即使MultiHeadAttention类看起来比MultiHeadAttentionWrapper更复杂,因为增加了张量的重塑和转置,但它实际上更高效。这是因为我们只需要一次矩阵乘法就可以计算keys(同样适用于queries和values)。而在MultiHeadAttentionWrapper中,我们需要为每个注意力头重复这个矩阵乘法,而矩阵乘法在计算上是最昂贵的步骤之一。
MultiHeadAttention类的使用方式与之前的SelfAttention和CausalAttention类相似:
python
torch.manual_seed(1337)
batch_size, context_length, d_in = batch.shape
d_out = 192
mha = MultiHeadAttention(d_in, d_out, context_length, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape) 从结果可以看出,输出维度直接由d_out参数控制:
tensor([[[-0.0469, -0.7954, 0.0223, ..., -0.2137, 0.5619, 0.1230],
[-0.5040, -0.5462, 0.1067, ..., -0.1799, 0.3765, 0.1092],
[-0.4682, -0.4948, 0.1663, ..., -0.1372, 0.3107, 0.0615],
[-0.4477, -0.4517, 0.1744, ..., -0.1111, 0.2581, 0.0206],
[-0.4262, -0.4115, 0.1693, ..., -0.0798, 0.1959, -0.0211],
[-0.3920, -0.3594, 0.1446, ..., -0.0400, 0.1222, -0.0600]],
[[-0.0469, -0.7954, 0.0223, ..., -0.2137, 0.5619, 0.1230],
[-0.5040, -0.5462, 0.1067, ..., -0.1799, 0.3765, 0.1092],
[-0.4682, -0.4948, 0.1663, ..., -0.1372, 0.3107, 0.0615],
[-0.4477, -0.4517, 0.1744, ..., -0.1111, 0.2581, 0.0206],
[-0.4262, -0.4115, 0.1693, ..., -0.0798, 0.1959, -0.0211],
[-0.3920, -0.3594, 0.1446, ..., -0.0400, 0.1222, -0.0600]]],
grad_fn=<ViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 192])在本节中,我们实现了MultiHeadAttention类,它将在接下来的章节中用于构建和训练语言模型。请注意,为了便于阅读输出,我们使用了相对较小的嵌入大小和注意力头数量。作为比较,最小的GPT-3模型(1.3亿参数)有12个注意力头,上下文向量嵌入大小为768。最大的GPT-3模型(1750亿参数)有96个注意力头,上下文向量嵌入大小为12288。请注意,在GPT模型中,token输入的嵌入大小和上下文嵌入的大小是相同的(d_in = d_out)。
练习:初始化GPT大小的注意力模块
使用MultiHeadAttention类,初始化一个多头注意力模块,其注意力头数量与最小的GPT-3模型相同(12个注意力头)。同时,确保使用与GPT-3相似的输入和输出嵌入大小(768维)。请注意,最小的GPT-3模型支持的上下文长度为2048个token。
本章小结
- 注意力机制通过为每个输入元素计算增强的上下文向量表示,将输入元素转化为包含所有输入信息的表示。
- 自注意力机制通过对输入的加权求和来计算上下文向量表示。
- 在简化版的注意力机制中,注意力权重通过点积计算得出。
- 点积实际上就是两个向量逐元素相乘然后求和的简洁表示。
- 矩阵乘法虽然不是严格必需的,但它能帮助我们更高效、更紧凑地实现计算,替代嵌套的for循环。
- 在语言模型中使用的自注意力机制(也称为缩放点积注意力)引入了可训练的权重矩阵,用于计算输入的中间变换:queries、values和keys。
- 当处理从左到右读取和生成文本的语言模型时,我们添加一个因果注意力掩码,防止语言模型访问未来的token。
- 除了用因果注意力掩码将注意力权重置零之外,我们还可以添加一个Dropout掩码来减少语言模型的过拟合。
- 基于Transformer的语言模型中的注意力模块涉及多个因果注意力实例,这被称为多头注意力。
- 我们可以通过堆叠多个因果注意力模块来创建一个多头注意力模块。
- 创建多头注意力模块的一种更高效的方法涉及批量矩阵乘法。
以下是本章节中引用或参考的文献:
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
-
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
-
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI Blog.
-
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
-
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
-
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1), 1929-1958.