数据驱动的世界中,生成模型扮演着至关重要的角色,尤其是在需要创建逼真样本的任务中。扩散模型(Diffusion Models, DM),以其卓越的样本质量和广泛的模式覆盖能力,已经成为众多数据生成任务的首选。然而,这些模型在实际部署时面临的挑战,如长时间的推理过程和对内存的大量需求,限制了它们在资源受限的设备上的应用。为了克服这些限制,本文提出了一种创新的稀疏微调方法,旨在不牺牲生成质量的前提下,显著提升扩散模型的效率和实用性。这种方法通过在卷积和线性层引入稀疏掩码,有效减少了模型的计算复杂度,降低了内存需求,同时通过渐进式训练策略,确保了生成样本的高质量。它在GPU上的推理速度提升了约1.2倍,且与硬件架构的兼容性使其在实际部署中更具优势。这种平衡了效率和质量的方法,为扩散模型的广泛应用铺平了道路。
 手动重新设计UViT模型和使用ASP进行稀疏剪枝UViT模型的结果
手动重新设计UViT模型和使用ASP进行稀疏剪枝UViT模型的结果
Table 1展示了在CIFAR10 32x32和CelebA 64x64两个数据集上,对U-ViT(一种基于Transformer的扩散模型)进行不同处理后的评估结果。表格中列出了以下几种处理方法的结果:
-
UViT Small U-ViT: 这是基线模型UViT在未进行任何稀疏化处理时的性能。在CIFAR10数据集上的FID为3.20,MACs为11.34亿次;在CelebA数据集上的FID为2.87,MACs为11.34亿次。
-
Half UViT Small U-ViT: 这是将UViT模型参数减少近50%后的模型性能。可以看到,FID显著增加,在CIFAR10数据集上FID为678.20,在CelebA数据集上FID为441.37,而MACs分别减少到5.83亿次。
-
UViT Small ASP: 这是使用NVIDIA提供的Automatic Sparsity (ASP)工具对UViT模型进行稀疏剪枝后的性能。在CIFAR10数据集上的FID为319.87,在CelebA数据集上的FID为438.31,MACs分别减少到5.76亿次。
从Table 1中,我们可以观察到几个关键的发现:
当直接将模型大小减半(Half UViT Small)时,对模型的生成质量产生了明显的负面影响。具体来说,FID值显著增加,这表明模型生成的样本与真实数据集的分布存在较大差异,意味着生成图像的质量和多样性有所下降。
尽管使用ASP(Automatic Sparsity)进行稀疏剪枝可以在一定程度上减少模型的计算复杂度,即降低MACs(Multiply-Accumulate operations),但这种方法同样会导致FID值增加。这反映出稀疏化处理后的模型在生成高质量样本方面的能力有所减弱。
这些实验结果凸显了在减少计算负荷的同时保持生成质量的难度。它们也揭示了当前稀疏化技术在扩散模型上的应用所面临的挑战,并为本文提出的SparseDM方法提供了研究动机。SparseDM旨在通过引入稀疏性来提升扩散模型的效率,同时尽量保持生成样本的质量,解决现有方法在稀疏化过程中遇到的质量和效率的权衡问题。
稀疏微调扩散模型(Sparse Finetuning DM)
为了实现2:4结构化稀疏推理和其他比例的稀疏剪枝,研究者提出的稀疏微调扩散模型框架。这个框架旨在通过引入稀疏掩码来减少模型的计算复杂度,同时保持生成样本的质量。
 框架的概览图,包括预训练的密集扩散模型(Dense DM)、生成数据、训练和采样、稀疏掩码在DM上的使用、带有训练和推理稀疏掩码的DM微调、以及训练后的稀疏DM的部署
框架的概览图,包括预训练的密集扩散模型(Dense DM)、生成数据、训练和采样、稀疏掩码在DM上的使用、带有训练和推理稀疏掩码的DM微调、以及训练后的稀疏DM的部署
Figure 1 提供了对稀疏微调扩散模型框架的全面概览,重点展示了如何通过引入渐进式稀疏掩码来优化训练过程。这个过程始于一个预训练的密集型扩散模型,该模型已经在特定数据集上接受了训练,能够生成高质量的样本。随后,研究者们利用这个模型生成数据,这些数据将作为接下来训练阶段的输入。
关键的创新点在于引入了稀疏掩码,这些掩码被应用于模型的卷积层和线性层,以确定哪些权重应该保留,哪些应该被置零。通过这种方式,模型的复杂度得以降低,同时减少了计算和内存需求。图1中可能展示了一个稀疏掩码的示例,通过二进制序列(如"0 1 1 0 1 0 0 1 1 0 1 0 0 1 0 1")来形象化地表示权重的稀疏分布。
训练过程是渐进式的,这意味着随着训练的进行,稀疏掩码的稀疏度会逐渐增加。这种策略允许模型有时间适应稀疏化带来的变化,避免了突然引入稀疏性可能导致的性能损失。在训练的后期,稀疏掩码被固定,模型在此基础上进行微调,以进一步优化性能并确保生成样本的质量。
最终,经过微调的稀疏模型准备好部署。这个模型不仅在保持生成质量方面表现出色,而且由于稀疏化处理,其计算和内存需求都有所降低。图1通过可视化的方式,清晰地传达了从预训练到部署的整个流程,以及如何在整个过程中有效地引入和优化稀疏掩码。这一框架不仅展示了稀疏化的渐进性质,还强调了在训练和推理中保持稀疏一致性的重要性,为有效训练和部署稀疏模型提供了一种创新的方法。
在稀疏微调扩散模型中,研究者们面临的一大挑战是如何在保持模型性能的同时减少模型的复杂度。为了解决这个问题,他们采用了改进的直通估计器(STE)。STE是一种在稀疏网络训练中用于梯度估计的技术,它允许模型在前向传播时利用稀疏掩码来减少计算量,而在反向传播时则忽略这些掩码,直接对原始的密集权重应用梯度。这种方法的关键在于,它允许稀疏网络在训练过程中保持梯度的准确性,避免了由于稀疏性导致的训练不稳定问题。
STE的工作原理是在前向传播时,通过稀疏掩码将密集权重投影到稀疏权重上,这样只有部分权重参与计算,从而减少了计算量。在反向传播时,STE使用一个特殊技巧:它将前向传播中使用的稀疏掩码的梯度(通常是零或一的简单向量)直接应用于原始的密集权重。这样,尽管模型在前向传播时是稀疏的,但在反向传播时仍然能够接收到完整的梯度更新,确保了模型能够在训练中学习到有效的权重。
为了进一步降低模型的参数数量和计算需求,研究者们引入了稀疏掩码。这些掩码是随机生成的二进制矩阵,其作用是在模型的卷积层和线性层中选择性地保留或置零权重。稀疏掩码中的每个元素都是一个二进制值,1表示对应的权重被保留,而0表示权重被置零,即不被计算。
这种方法的关键在于逐步引入稀疏掩码,而不是一次性地将所有权重稀疏化。通过这种方式,模型可以逐渐适应稀疏结构,而不是突然面临大量的权重丢失,这有助于减少由于突然稀疏化带来的性能损失。随着训练的进行,模型可以学习到哪些权重对于生成高质量的样本是重要的,哪些权重可以被安全地剪枝掉。
引入稀疏掩码的过程通常与STE结合使用,以确保在训练过程中梯度能够正确地传播,同时模型能够逐渐学习到稀疏权重的最优解。这种方法不仅减少了模型的计算复杂度,还有助于提高模型的存储效率,因为只有被保留的权重需要被存储和更新。
为了最小化因突然引入稀疏性而导致的性能下降,研究者们开发了一种渐进式稀疏训练策略。这种方法的核心思想是逐步引导模型从密集状态过渡到稀疏状态,而不是一次性地应用高比例的稀疏性。在训练的早期阶段,模型以较低的稀疏度开始,这意味着只有少数权重被置零。随着训练的进行,稀疏掩码逐渐增加其稀疏度,权重被逐步剪枝。这个过程允许模型在每个阶段都有足够的时间来适应新的稀疏结构,并重新学习那些对于生成高质量样本至关重要的权重。
这种渐进式的训练方法有几个关键优势:
- 稳定性:它避免了由于突然剪枝大量权重而导致的模型性能急剧下降。
- 适应性:模型有机会逐步适应稀疏性,从而更好地保留重要特征。
- 优化:随着稀疏度的逐渐增加,模型可以持续优化剩余权重,以保持或提升生成样本的质量。
一旦模型完成了稀疏化处理,接下来的步骤是对稀疏模型进行微调。微调是提高稀疏模型性能的重要环节,研究者通过调整损失函数和训练策略来确保稀疏模型生成的样本质量。这可能涉及到对损失函数添加正则化项,或者使用不同的优化算法和学习率策略。微调过程允许模型细化其稀疏权重,强化那些对生成高质量样本最为关键的连接。
微调的目的是两方面的:
- 质量保证:确保即使在稀疏化之后,生成的样本也能保持与原始密集模型相似或可接受的质量水平。
- 性能提升:通过微调,稀疏模型能够在特定的数据分布上进一步优化其性能,提高样本的准确性和多样性。
在模型的推理阶段,稀疏模型利用引入的稀疏掩码来实现加速。由于只有非零权重参与计算,这大大减少了模型在执行时所需的计算资源和内存占用。推理过程中的加速不仅提高了模型的运行效率,也使得模型更适合部署在资源受限的环境中。
研究者还针对NVIDIA Ampere架构GPU进行了优化,利用了这些GPU支持的2:4稀疏模式。在这种模式下,每四个权重中只有两个是非零的,这允许GPU更高效地执行矩阵乘法操作,从而实现近2倍的计算加速。这种优化使得稀疏模型在保持生成质量的同时,还能在实际应用中实现快速推理。
通过这一框架,研究者成功地提高了扩散模型的部署效率,同时在保持生成样本质量的前提下,显著降低了模型的计算和内存需求。这一成果对于推动扩散模型在资源受限设备上的应用具有重要意义。
实验
研究者们在多个数据集上评估了他们的方法,包括CIFAR10、CelebA、MS COCO和ImageNet,涵盖了从32×32到256×256的不同分辨率。他们使用了两种主要的评估指标:计算效率(以乘累加操作,MACs,计)和生成质量(以Fréchet Inception Distance,FID,计)。
实验结果显示,在2:4稀疏度条件下,与未稀疏化的模型相比,稀疏模型在MACs上减少了大约50%,而FID仅增加了0.60至2.19(平均1.22)。这表明,尽管模型的计算量减少了,但生成样本的质量仍然得到了很好的保持。特别是在高分辨率和高保真图像生成方面,稀疏模型表现出了更好的FID效果。
 在不同数据集(MS-COCO 256×256, ImageNet 256×256, CIFAR10 32×32, CelebA 64×64)上,2:4稀疏U-ViT生成的图像样本
在不同数据集(MS-COCO 256×256, ImageNet 256×256, CIFAR10 32×32, CelebA 64×64)上,2:4稀疏U-ViT生成的图像样本
研究者们还提供了在不同数据集上生成的图像样本,以直观展示稀疏模型生成的图像质量。通过对比,可以发现稀疏模型生成的图像与原始模型生成的图像在视觉上几乎没有差异,这进一步证实了稀疏模型在保持生成质量方面的有效性。
在硬件测试中,研究者们在NVIDIA A40 GPU上对模型进行了加速比测试。测试结果显示,稀疏模型的推理速度比密集模型快了大约1.2倍,这与理论加速比相符,证明了稀疏模型在实际硬件上的有效加速能力。
研究者们还探讨了不同稀疏度对模型性能的影响。实验结果表明,并非稀疏度越高越好,而是存在一个最优的稀疏度范围,可以平衡计算效率和生成质量。例如,在某些情况下,2:4的稀疏度比其他更高或更低的稀疏度提供了更好的FID结果。
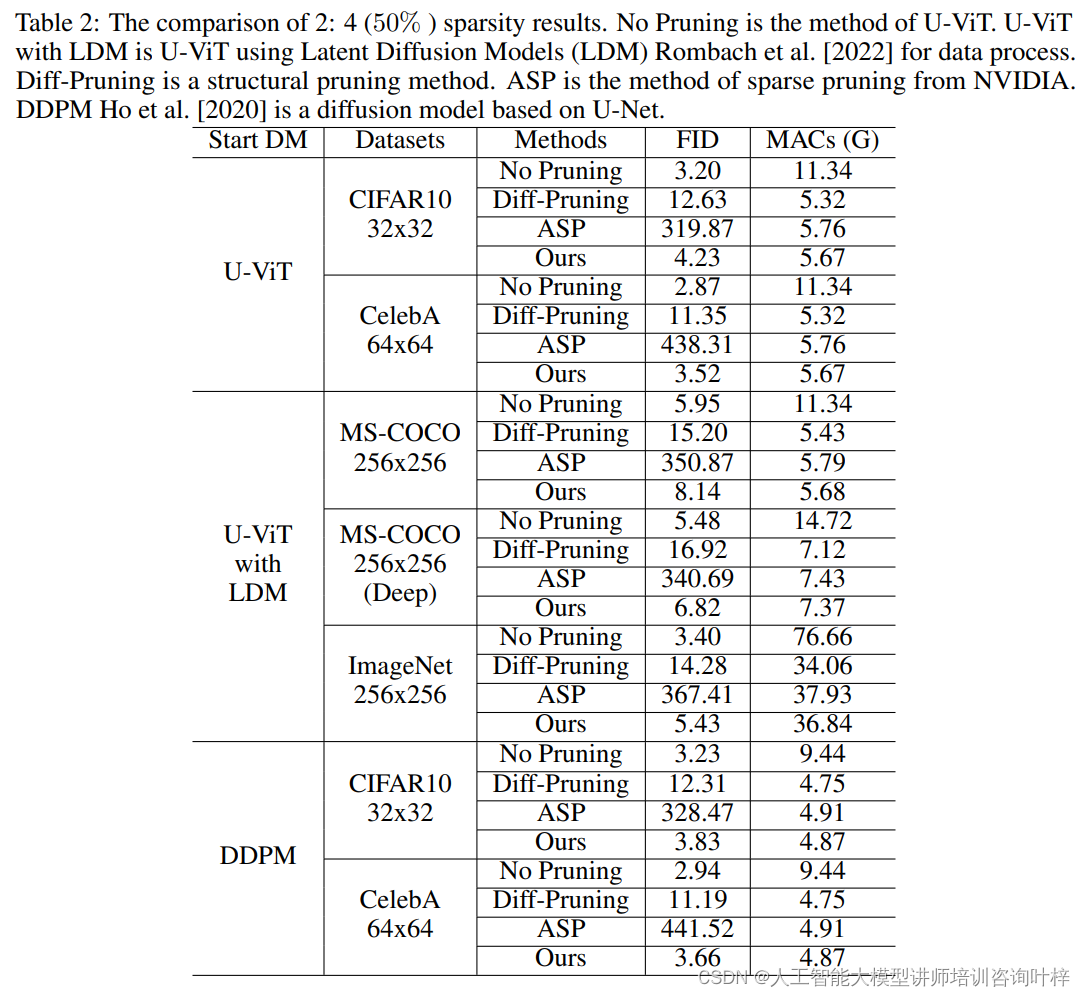 比较了不同数据集(CIFAR10, CelebA, MS-COCO, ImageNet)和不同方法(No Pruning, Diff-Pruning, ASP, Ours)在2:4稀疏率下的FID和MACs
比较了不同数据集(CIFAR10, CelebA, MS-COCO, ImageNet)和不同方法(No Pruning, Diff-Pruning, ASP, Ours)在2:4稀疏率下的FID和MACs
为了进一步理解稀疏微调方法的各个组成部分对性能的影响,研究者们进行了一系列消融实验。这些实验包括对STE方法、传统渐进式稀疏训练和固定稀疏掩码的比较。结果表明,研究者提出的方法在多个方面都优于这些基线方法,特别是在FID和加速比方面。
 比较了不同稀疏率对FID的影响(图3a)、传统渐进式稀疏训练与固定稀疏训练的比较(图3b)、不同稀疏比率下FID和MACs的权衡(图3c)、2:4稀疏训练过程的比较(图3d和3e)、以及未训练掩码、STE训练掩码和本文方法掩码的比较(图3f)
比较了不同稀疏率对FID的影响(图3a)、传统渐进式稀疏训练与固定稀疏训练的比较(图3b)、不同稀疏比率下FID和MACs的权衡(图3c)、2:4稀疏训练过程的比较(图3d和3e)、以及未训练掩码、STE训练掩码和本文方法掩码的比较(图3f)
本文提出的稀疏微调扩散模型框架,不仅在理论上具有创新性,而且在实际应用中也显示出了巨大的潜力。随着深度学习技术的不断进步和硬件平台的不断发展,我们期待这一框架能够在更多的领域得到应用,推动扩散模型技术向更高效率和更广泛应用场景发展。