子数组vs子数列
1、子数组(n^2) 子序列(2^n)
2、子数组是子序列的一个子集
3、子数组必须连续,子序列可以不连续
一、最长递增子序列

算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子系列中,最长递增子序列的长度。
2、状态转移方程
(1)长度为1------>dpi=1
(2) 长度大于1------>满足前提(numsj<numsi)------>max(dpj+1,dpi) (0<=j<=i-1)
3、初始化
如果无法更新,最差情况自己也是一个子序列,所以dp表全都初始化为1
4、填表顺序
需要借助前面的状态,所以要从左往右
5、返回值
dp表中的最大值------>可以用ret去更新出最大值,也可以用*max_element(dp.begin(),dp.end())
6、复杂度
时间复杂度:N^2 (因为是子序列而非子数组,所以当我们固定住i的时候,他的前面可以是i-1、i-2、i-3...... 所以需要遍历一遍更新出最大的长度)
空间复杂度:N
cpp
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n=nums.size();
vector<int> dp(n,1);
for(int i=1;i<n;++i)
for(int j=0;j<i;++j)
if(nums[j]<nums[i]) dp[i]=max(dp[j]+1,dp[i]); //前提条件要满足
return *max_element(dp.begin(),dp.end());//dp数组中的最大值
}
};二、摆动序列

算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子序列中,最长递增子序列的长度。 (错误)
因为会存在两种状态,所以我们需要两个dp数组:
fi表示以i位置为结尾的所有子序列中,最后一个位置呈现"上升"趋势的最长摆动序列的长度
gi表示以i位置为结尾的所有子序列中,最后一个位置呈现"下降"趋势的最长摆动序列的长度
2、状态转移方程
fi(上升):
(1)长度为1------>1
(2) 长度大于1------>满足前提(numsj<numsi)------>max(gj+1,fi) (0<=j<=i-1)
gi(下降):
(1)长度为1------>1
(2) 长度大于1------>满足前提(numsj>numsi)------>max(fj+1,gi) (0<=j<=i-1)
3、初始化
如果无法更新,最差情况自己也是一个子序列,所以g表和f表全都初始化为1
4、填表顺序
需要借助前面的状态,所以要从左往右,两个表一起填
5、返回值
两个表中的最大值
cpp
class Solution {
public:
int wiggleMaxLength(vector<int>& nums) {
//f[i]表示以i位置结尾的最长子序列中,最后呈现上升趋势 (前提nums[i]<nums[j])
//g[i]表示以i位置结尾的最长子序列中,最后成下降趋势 (前提nums[i]>nums[j])
int n=nums.size();
vector<int> f(n,1),g(n,1);
for(int i=1;i<n;++i)
for(int j=0;j<i;++j)
if(nums[i]<nums[j]) g[i]=max(f[j]+1,g[i]);
else if(nums[i]>nums[j]) f[i]=max(g[j]+1,f[i]);
return max(*max_element(f.begin(),f.end()),*max_element(g.begin(),g.end()));
}
};三、最长递增子序列的个数

在讲解前先来个小demo:如何在数组中找出最大值出现的次数
方案1:第一次for循环确定最大的值是多少,第二次for循环统计最大的值出现了几次
方案2:利用贪心策略一次for循环搞定(定义maxval记录当前的最大值,count统计数量)
(1)x==maxval:++count
(2)x<maxval:直接无视
(3)x>maxval:更新最大值------>maxval=x,然后重新计数------>count=1
算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子序列中,最长递增子序列的个数。 (错误)
因为我们在填表的时候并不能确认最长递增子序列的长度是多少,所以无法直接统计。我们就得用demo中的方案2的思想,来解决这个问题。
leni表示以i位置为结尾的所有子序列中,最长递增子序列的"长度"
counti表示以i位置为结尾的所有子序列中,最长递增子序列的"个数"
2、状态转移方程
numsj<numsi时
(1)lenj+1==leni------>counti+=countj
(2)lenj+1<leni 无视
(3)lenj+1>leni------>leni=lenj+1 counti=countj(更新最大值并重新计数)
3、初始化
全都初始化为1
4、填表顺序
需要借助前面的状态,所以要从左往右,两个表一起填
5、返回值
recount统计结果
cpp
class Solution {
public:
int findNumberOfLIS(vector<int>& nums) {
int n=nums.size();
vector<int> len(n,1),count(n,1); //count统计以i位置结尾时最长子序列的个数 len是长度
int retlen=1,recount=1;//统计最大长度和最大长度的个数
for(int i=1;i<n;++i)
{
for(int j=0;j<i;++j)
if(nums[i]>nums[j]) //构成子序列的前提条件
if(len[j]+1==len[i]) count[i]+=count[j];
else if(len[j]+1>len[i])len[i]=len[j]+1,count[i]=count[j];
//更新一下最长长度和最大数
if(retlen==len[i]) recount+=count[i];
else if(retlen<len[i])
{
retlen=len[i];
recount=count[i];
}
}
return recount;
}
};四、最长数链对

算法原理:
预处理:由于题目要求是任意顺序组成数链对,所以我们在处理的时候不仅要考虑前面,还要考虑后面,这样不利于我们的动态规划表示,所以我们要先按照第一个元素进行排序(比如a,b c,d,a<c<d 所以d>a,所以后面的不需要考虑到),我们要进行sort,在C++中,vector、pair的默认比较逻辑都是按照字典序的,恰好符合我们的要求,所以我们可以直接调用sort。

1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有数对链序列中,最长数对链的长度。
2、状态转移方程
dpi:
(1)长度为1------1
(2)长度大于1------pj1>pi0 ------max(dpi,dpj+1)
3、初始化
初始化为1
4、填表顺序
需要借助前面的状态,所以要从左往右
5、返回值
要返回dp表中的最大值,但由于我们排序过,所以最大值必然出现在dpn-1。
cpp
class Solution {
public:
int findLongestChain(vector<vector<int>>& pairs) {
//vector的排序就像字典序一样
//预处理直接sort 正好符合我们的要求
sort(pairs.begin(),pairs.end());
int n=pairs.size();
vector<int> dp(n,1);
for(int i=1;i<n;++i)
for(int j=0;j<i;++j)
if(pairs[j][1]<pairs[i][0]) dp[i]=max(dp[j]+1,dp[i]);//(1,5)(2,3)(4,10)(5,9)
return dp[n-1];//最大值必然在最后面
}
};五、最长定差子序列(经典)

算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子序列中,最长的等差子序列长度
2、状态转移方程
dpi:
(1)b不存在------>1
(2)b存在------>取最后一个即可dpj+1
我们会发现前一个数基本上是可以确定是多少的,并且有多个的话也可以用后面的覆盖前面的,因此我们可以用哈希表做优化
优化思路:
(1)将元素+dpi的值存在哈希表中
(2)直接在哈希表中做动态规划
3、初始化
hasharr\[0]=1
4、填表顺序
从左往右
5、返回值
dp表里的最大值
cpp
class Solution {
public:
int longestSubsequence(vector<int>& arr, int difference) {
//数据量太大了O(n^2)必然会超时
int n=arr.size();
unordered_map<int,int> hash;//第一个是元素,第二个是以这个元素为结尾时的最长等差子序列长度
int ret=1;
for(int&v:arr) //为了降低时间复杂度,我们发现这道题只需要最后的那个相同的
{
hash[v]=hash[v-difference]+1; //因为v-difference不在的时候,会被自己创建出来并初始化为0
ret=max(ret,hash[v]);
}
return ret;
}
};为什么哈希表不需要先将数组中的元素全部初始化为1???因为hashv=hashv-difference+1,当v-differences不存在的时候,重载方括号会去调用insert并允许我们修改second,在创建的时候初始化了。
六、最长的斐波那契子序列长度

算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子序列中,最长的斐波那契子序列长度(错误)。
因为我们至少得确定两个位置,才能知道序列是否满足斐波那契子序列的要求。
dpij表示以i位置及j位置为结尾所有子序列中,最长的斐波那契子序列长度。
2、状态转移方程
dpij: (假设abc对应的坐标分别是kij)
(1)如果a存在且a<b------>dpki+1
(2)a存在且b<a<c------>2
(3)a不存在------>2
我们固定两个数用了两层for循环了,如果找第三个数的时候还要在前面用一层for循环的话,那么就是n^3的时间复杂度了,所以我们可以用哈希表来帮助我们存储下标和元素的映射关系。并且我们只需要保存靠后的元素下标即可。
**优化思路:**将元素与下标绑定存放在哈希表中。
3、初始化
都初始化为2
4、填表顺序
从左往右
5、返回值
dp表里的最大值ret 但是如果ret是2的话就返回0
cpp
class Solution {
public:
int lenLongestFibSubseq(vector<int>& arr)
{
//必须通过元素快速找到dp表对应的下标
unordered_map<int,int> hash;//哈希帮助我们快速定位
int n=arr.size();
for(int i=0;i<n;++i) hash[arr[i]]=i;
int ret=2;//起始为2
vector<vector<int>> dp(n,vector<int>(n,2));//得知道两个位置,才能确定前面的
for(int j=2;j<n;++j) //固定最后的位置
for(int i=1;i<j;++i)//固定倒数第2个位置
{
int a=arr[j]-arr[i];
if(hash.count(a)&&a<arr[i]) dp[i][j]=dp[hash[a]][i]+1;
ret=max(dp[i][j],ret);
}
return ret==2?0:ret;
}
};七、最长等差数列

算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子序列中,最长的等差子序列的长度(错误)。
因为我们至少得确定两个位置,才能知道序列是否满足等差子序列的要求。
dpij表示以i位置及j位置为结尾所有子序列中,最长的等差子序列长度。
2、状态转移方程
dpij: (假设abc对应的坐标分别是kij)
(1)如果a存在且a<b------>dpki+1
(2)a存在且b<a<c------>2
(3)a不存在------>2
我们固定两个数用了两层for循环了,如果找第三个数的时候还要在前面用一层for循环的话,那么就是n^3的时间复杂度了,所以我们可以用哈希表来帮助我们存储下标和元素的映射关系。并且我们只需要保存靠后的元素下标即可。
优化思路:
(1)将元素与下标绑定存放在哈希表中。
(2)i位置填完后,将i位置的值放进哈希表中
3、初始化
都初始化为2
4、填表顺序
有两种方式(选择方法2)
(1)先固定最后一个数,然后枚举倒数第二个数(必须在dp前先将元素与下标的关系绑定再哈希表中,到时候在找的时候还得判断b<a<c的情况)
(2)先固定倒数第二个数,再枚举最后一个数(可以等i位置填完后再将i的位置丢进哈希表,这样可以保证哈希表内的元素的下标必然是小的,就可以不需要判断b<a<c的情况)
5、返回值
dp表里的最大值ret
cpp
class Solution {
public:
int longestArithSeqLength(vector<int>& nums) {
//得确定至少两个位置,通过这两个位置求出了等差是多少,才能确定最终的结果
unordered_map<int,int> hash;
int n=nums.size();
hash[nums[0]]=0;
//必须要先固定两个数
int ret=2;
vector<vector<int>> dp(n,vector<int>(n,2));
for(int i=1;i<n;++i) //边遍历边丢,这样就能确保哈希表里面的都是前面的元素
{
for(int j=i+1;j<n;++j)
{
int a=2*nums[i]-nums[j];
if(hash.count(a)) dp[i][j]=dp[hash[a]][i]+1;
ret=max(dp[i][j],ret);
}
hash[nums[i]]=i;//记住最后一个即可
}
return ret;
}
};八、等差数列划分II-子序列

算法原理:
1、状态表示(经验+题目要求)
dpi表示以i位置为结尾所有子序列中,最长的等差子序列的长度(错误)。
因为我们至少得确定两个位置,才能知道序列是否满足等差子序列的要求。
dpij表示以i位置及j位置为结尾所有子序列中,最长的等差子序列长度。
2、状态转移方程
dpij: (假设abc对应的坐标分别是kij)
(1)如果a存在且a<b------>dpij+=dpki+1
(2)a存在且b<a<c------>0
(3)a不存在------>0
我们固定两个数用了两层for循环了,如果找第三个数的时候还要在前面用一层for循环的话,那么就是n^3的时间复杂度了,所以我们可以用哈希表来帮助我们存储下标和元素的映射关系。并且我们只需要保存靠后的元素下标即可。
优化思路:
(1)将元素与下标绑定存放在哈希表中。(该题需要统计所有的子序列,所以相同元素下标不同的情况都要统计,因此我们要将元素绑定一个下标数组)
(2)i位置填完后,将i位置的值放进哈希表中
3、初始化
都初始化为0
4、填表顺序
先固定倒数第二个数,再枚举最后一个数(可以等i位置填完后再将i的位置丢进哈希表,这样可以保证哈希表内的元素的下标必然是小的,就可以不需要判断b<a<c的情况)
5、返回值
dp表的总和------用一个sum去统计
6、细节处理
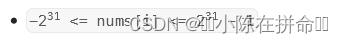
可能会溢出,所以我们要下标要存储long