一、研究背景
在两个实验中,使用了一组综合性的生物统计数据来探索和预测健康状况(特别是疾病的发生)。实验的核心在于应用高级数据分析技术,具体包括随机森林分类和聚类分析,来洞察和预测个体的健康状况。首先,对数据进行了精细的预处理,确保了分析的准确性和有效性。接下来,通过一系列的数据可视化手段,包括生成相关系数热力图,成功地揭示了数据中的关键模式和趋势。
随后,采用随机森林模型,这是一种强大的机器学习技术,对疾病(即响应变量"illness")的发生进行了预测。通过这种方法,不仅能够评估各种健康指标与疾病发生之间的关系,还能够预测个体的健康风险。模型的性能通过一系列的评估指标得到了验证,包括混淆矩阵和接收者操作特征曲线(ROC),这些都是评估分类模型性能的重要工具。
最后,进行了聚类分析,这进一步加深了对数据集中潜在群体特征的理解。这一步骤不仅揭示了不同健康参数之间的关联性,还可能揭示了特定健康状况的潜在风险因素。
二、实证分析
首先读取数据,因为数据很乱,要进行预处理:
最后,格式整理好的数据如下:
R
# 去除第一行的列名,并用分号分割数据
data <- data[-1]
data <- strsplit(data, ";")
# 将数据转换为数据框
df <- as.data.frame(do.call(rbind, data))
# 设置列名
colnames(df) <- column_names
# 将字符型数据转换为数值型(如果需要)
df[] <- lapply(df, as.numeric)
# 显示数据框的前几行
head(df)
str(df)
head(df,5)
查看其属性:
 数据预处理,创建一个指示缺失值的数据框
数据预处理,创建一个指示缺失值的数据框
R
###数据预处理
# 创建一个指示缺失值的数据框
missing_df <- df %>%
mutate(row_id = row_number()) %>% # 添加行索引
pivot_longer(cols = -row_id, names_to = "variable", values_to = "value") %>%
mutate(value = ifelse(is.na(value), "Missing", "Not Missing"))
# 绘制热图
ggplot(missing_df, aes(x = row_id, y = variable, fill = value)) +
geom_tile() +
scale_fill_manual(values = c("Missing" = "red", "Not Missing" = "gray")) +
theme_minimal() +
labs(x = "Row Number", y = "Variable", fill = "Status", title = "Heatmap of Missing Values")
# Checking for missing values
cat("Missing Values:\n")
print(sum(is.na(df)))
可以发现无缺失数据,接下来,可以对数据进行统计性分析:
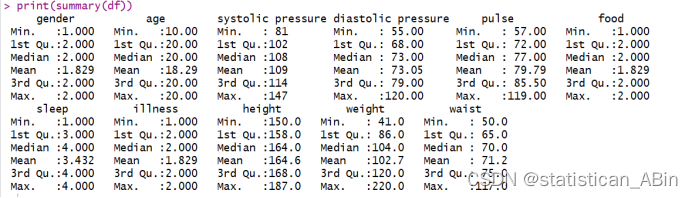
其中包含了最小值、第一四分位数、中位数、平均数、第三四分位数和最大值。这样的摘要为深入分析提供了基础,它揭示了各项指标的分布情况,包括血压、脉搏、饮食、睡眠、身高、体重和腰围等关键健康指标。
接下来对部分数据可视化
R
# Histograms for numerical features
hist_plots <- df %>%
pivot_longer(cols = -illness, names_to = "variables", values_to = "values") %>%
ggplot(aes(x = values, fill = variables)) +
geom_histogram(bins = 30, color = "black") +
facet_wrap(~variables, scales = 'free_x') +
theme_minimal() +
scale_fill_viridis_d() # 使用 Viridis 颜色方案
print(hist_plots)
年龄(Age): 年龄的分布集中在较低的值区域,这表明样本群体可能偏向年轻人。
舒张压(Diastolic pressure): 舒张压的分布显示了一个相对集中的范围,大多数值在70到90毫米汞柱之间。
饮食(Food): 饮食的分布图显示数据似乎是分类变量,大部分数据集中在两个值上。....
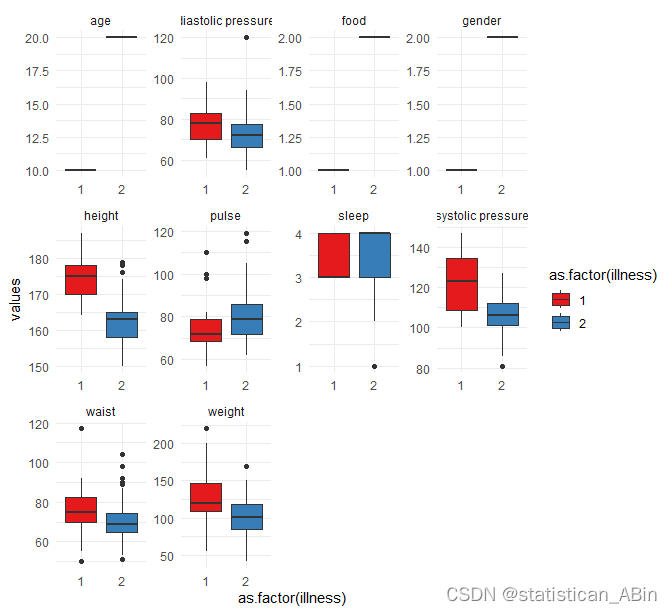
图像展示的是一系列箱形图,这些图表反映了不同变量在两个疾病状态(用"as.factor(illness)"标记,红色表示1,蓝色表示2)之间的分布差异。箱形图显示了数据的中位数(箱子中的横线)、四分位数范围(箱子的大小)、异常值(图中的小圆点)以及整体分布的偏态。例如年龄在两个疾病状态下的分布相似,中位数和四分位数范围较为接近。
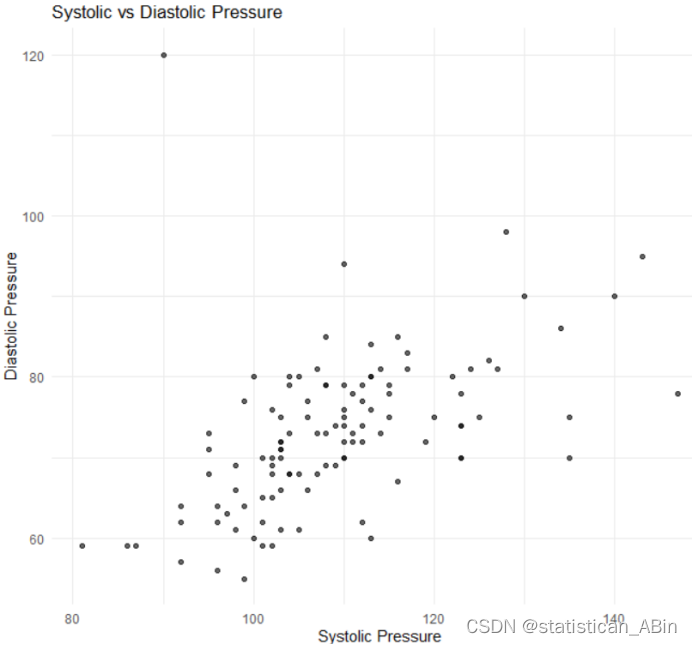
这张图是一个散点图,展示了收缩压(Systolic Pressure)与舒张压(Diastolic Pressure)之间的关系。从图中可以看出大部分数据点集中在收缩压100到120毫米汞柱和舒张压70到90毫米汞柱的区域,这通常被视为正常血压范围....
R
# 首先转换数据为长格式
long_df <- df %>%
pivot_longer(cols = -illness, names_to = "variables", values_to = "values")
# 使用 ggplot2 绘制密度图
ggplot(long_df, aes(x = values, fill = variables)) +
geom_density(alpha = 0.7) +
theme_minimal() +
scale_fill_viridis_d()
重叠的密度图,它展示了数据集中各个变量的分布密度。每个颜色代表一个变量,其在水平轴上的分布显示了该变量在数据集中的相对密度。例如舒张压(Diastolic Pressure): 分布较为集中,显示为一个较高、较窄的峰,这表明大部分数据落在一个相对狭窄的范围内。
R
library(corrplot)
cor_mat <- cor(df %>% select(-illness))
corrplot(cor_mat, method = "color")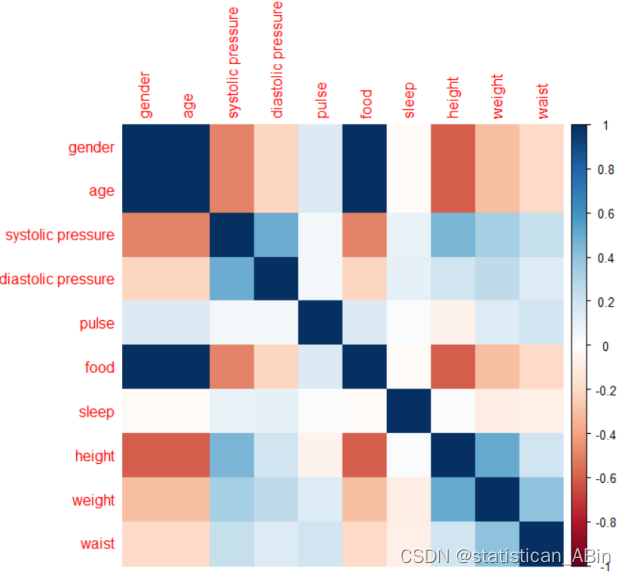
相关系数热力图,它显示了数据集中不同变量之间的相关性。在这个热力图中,颜色的强度代表相关系数的大小,从-1到1变化。蓝色表示正相关,红色表示负相关,颜色越深表示相关性越强。
从热力图可以观察到以下几点:
存在一些变量间的显著正相关,如身高和体重、腰围和体重,这是符合预期的,因为身体尺寸较大的个体通常体重更重。
有些变量之间的相关性较弱,如食物和睡眠、脉搏和性别,这些变量之间看起来没有明显的直接联系。
R
index <- sample(1:nrow(df), nrow(df)*0.7)
train_data <- df[index,]
test_data <- df[-index,]接下来随机森林模型的建立与预测

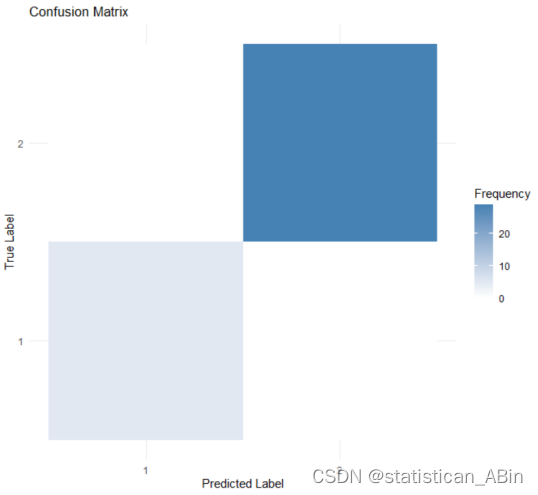
混淆矩阵为:
R
library(ggplot2)
# 计算混淆矩阵
# 计算混淆矩阵
confusion <- confusionMatrix(as.factor(predictions), as.factor(test_data$illness))
confusion_matrix <- confusion$table
# 将混淆矩阵转换为长格式的数据框
confusion_long <- as.data.frame(as.table(confusion_matrix))
# 确保列名是正确的
names(confusion_long) <- c("Prediction", "Actual", "Frequency")
# 可视化混淆矩阵
ggplot(confusion_long, aes(x = Prediction, y = Actual, fill = Frequency)) +
geom_tile() +
scale_fill_gradient(low = "white", high = "steelblue") +
theme_minimal() +
labs(title = "Confusion Matrix", x = "Predicted Label", y = "True Label")
随后绘制一下绘制精确度-召回率曲线
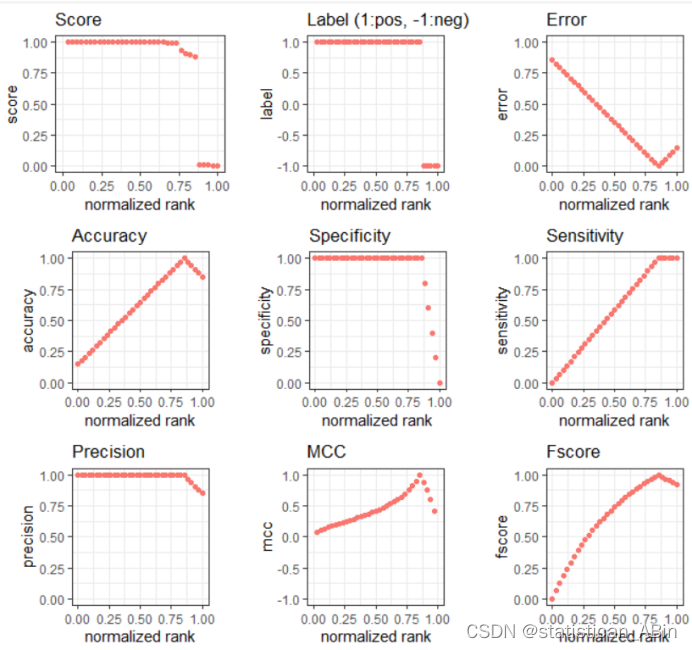
每个图表都显示了模型在特定指标上的得分,与归一化排名(可能基于预测概率)的关系。接下来查看重要性特征排序:

从图中可以看出:
食物(Food): 这个变量的重要性评分最高,表明它在模型预测疾病状态中起着关键作用。
年龄(Age): 排在第二位,也是模型中一个重要的预测变量。
接下来进行聚类分析:
针对该数据,聚类可以:
健康分析:通过聚类分析,可以将相似的健康状况的个体归为一类,例如根据血压、脉搏、体重等因素。这有助于识别特定健康风险群体或研究特定健康状况的共同特征....
R
# 使用肘方法确定簇的数量
wss <- map_dbl(1:10, ~kmeans(df_scaled, .x)$tot.withinss)
plot(1:10, wss, type = "b", pch = 19, frame = FALSE, xlab = "Number of clusters K", ylab = "Total within-clusters sum of squares")
# 应用k均值聚类
set.seed(123) # 为了可重复性
k <- 3 # 假设选择的簇数为3
km_result <- kmeans(df_scaled, centers = k)
运用手肘发法选择K值,它用于帮助确定在聚类分析中应选择多少个簇(即K值)。肘部方法的核心思想是增加簇的数量会导致每个簇内的总方差(或称为总内簇平方和)减少,但减少的速率会在某一点急剧下降,这一点就是"肘部"。
在图中,横轴表示簇的数量(K),纵轴表示总内簇平方和。图中显示当簇的数量从2增加到10时,总内簇平方和急剧下降并逐渐平缓,这表明随着簇数量的增加,新的簇不再显著降低总方差。
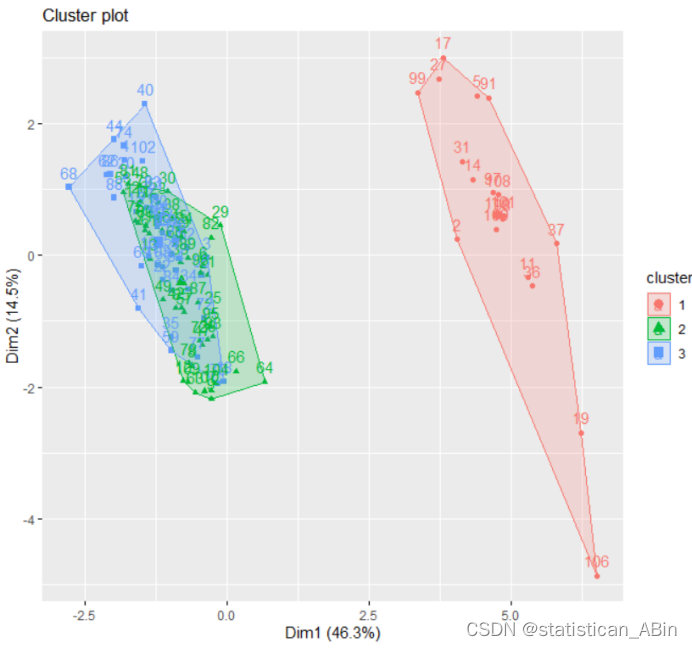
在此图中,可以观察到以下特点:
三个簇: 数据点被分成了三个簇,每个簇用不同的颜色标记。
簇的分布:
第一个簇(红色区域)似乎较为分散。
第二个簇(绿色区域)和第三个簇(蓝色区域)相对集中。
三、总结
总而言之,通过随机森林和聚类分析,不仅能够预测疾病的发生,并且还能够识别数据中的自然群体。这些洞察有助于形成对数据集的全面理解,并为进一步的研究和决策提供了数据驱动的基础。尽管如此,模型评估和验证的重要性不容忽视,特别是在准备将这些模型应用于新数据或实际情境中时。
创作不易,希望大家多点赞关注评论!!!