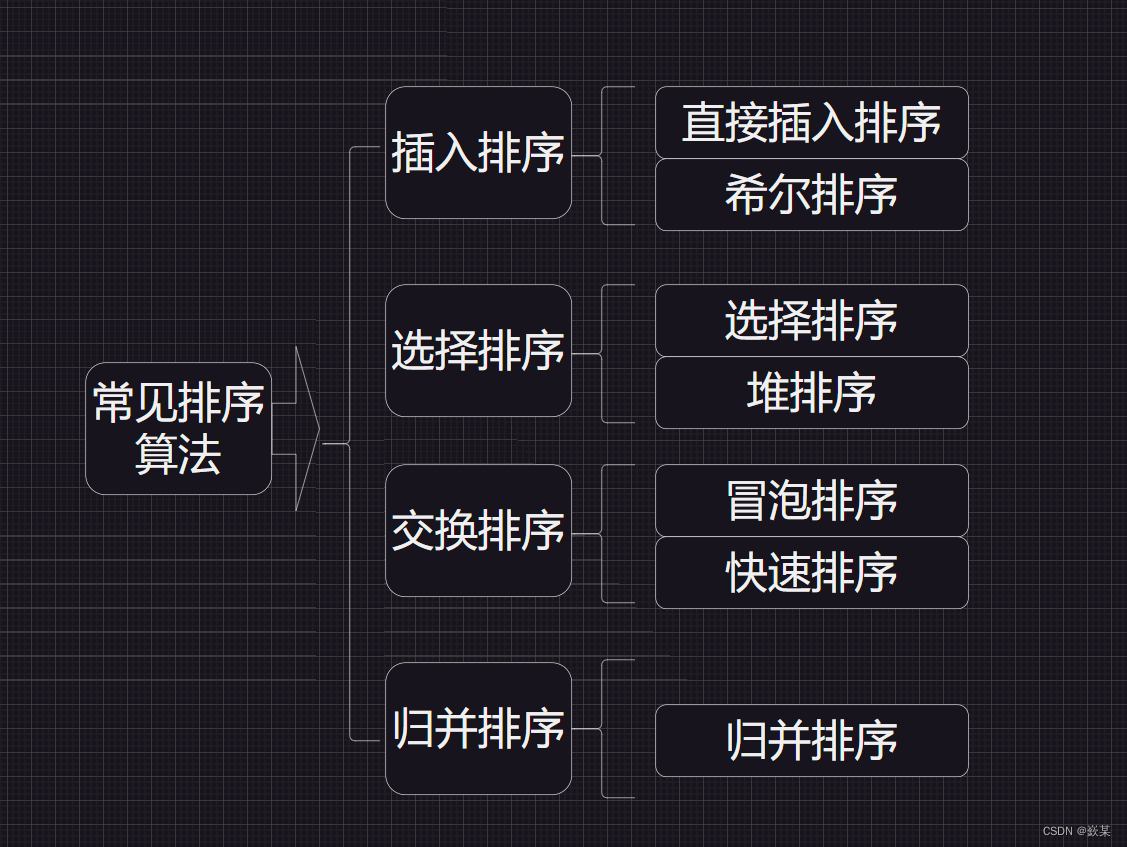
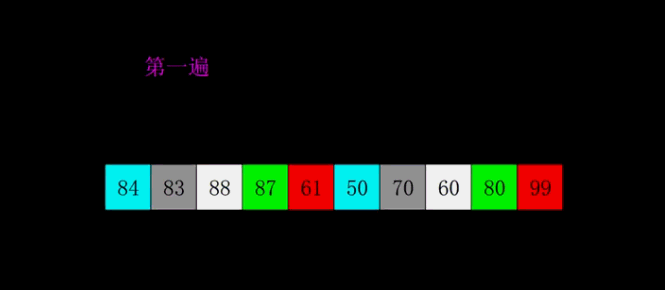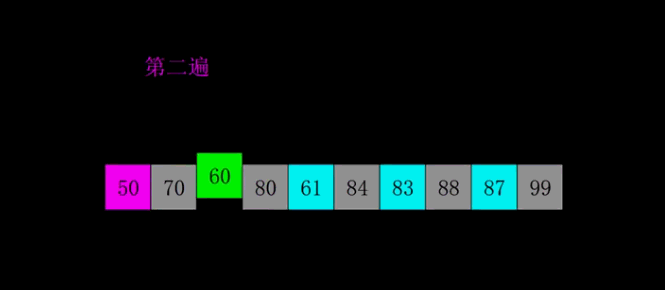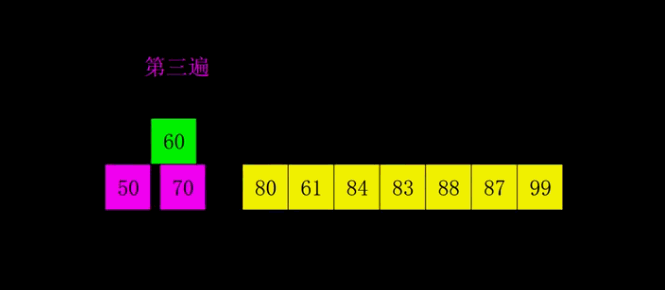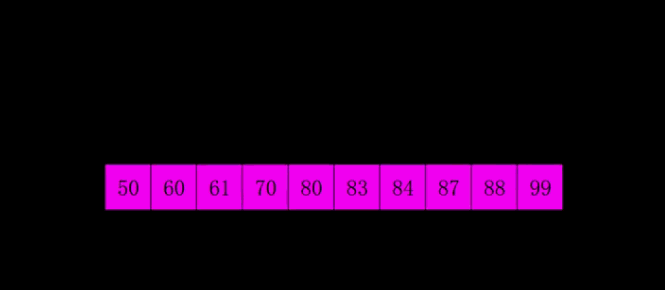
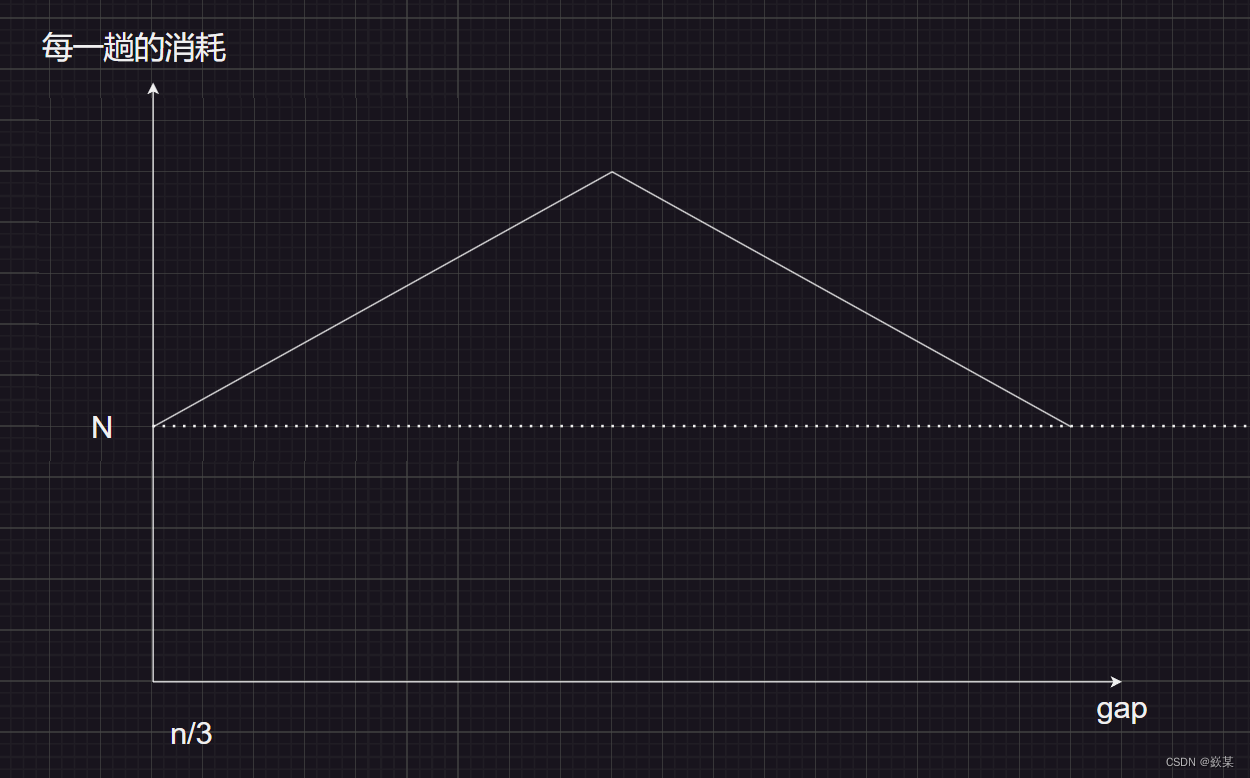
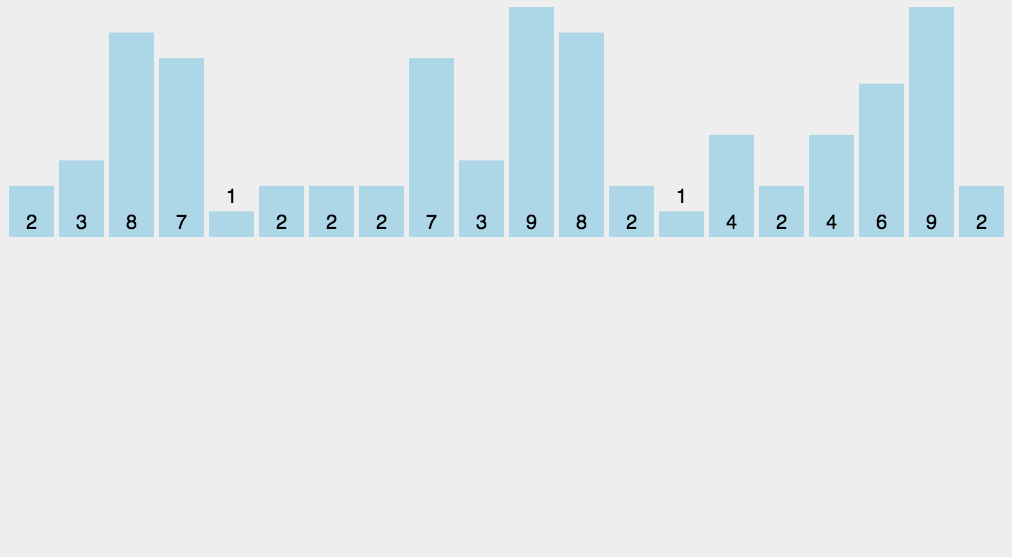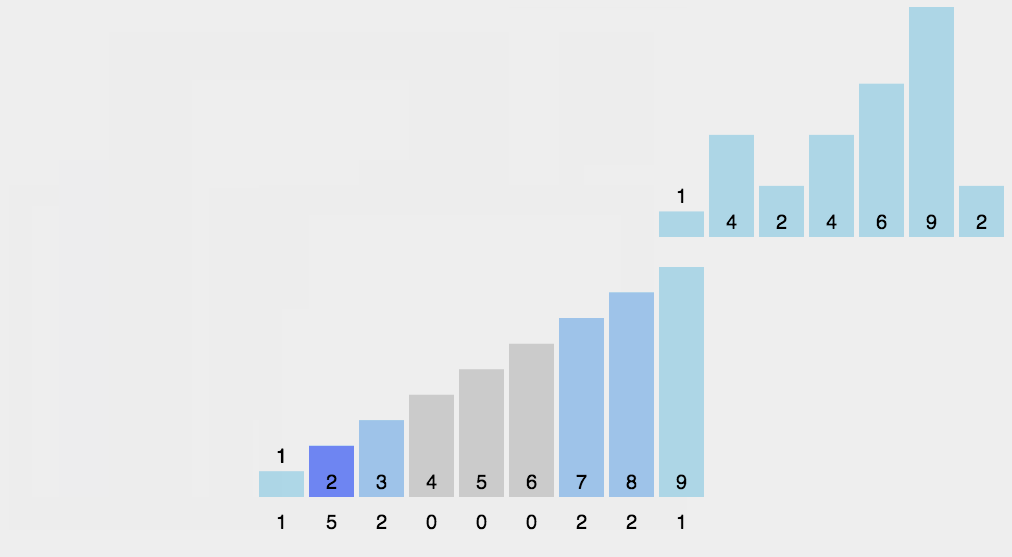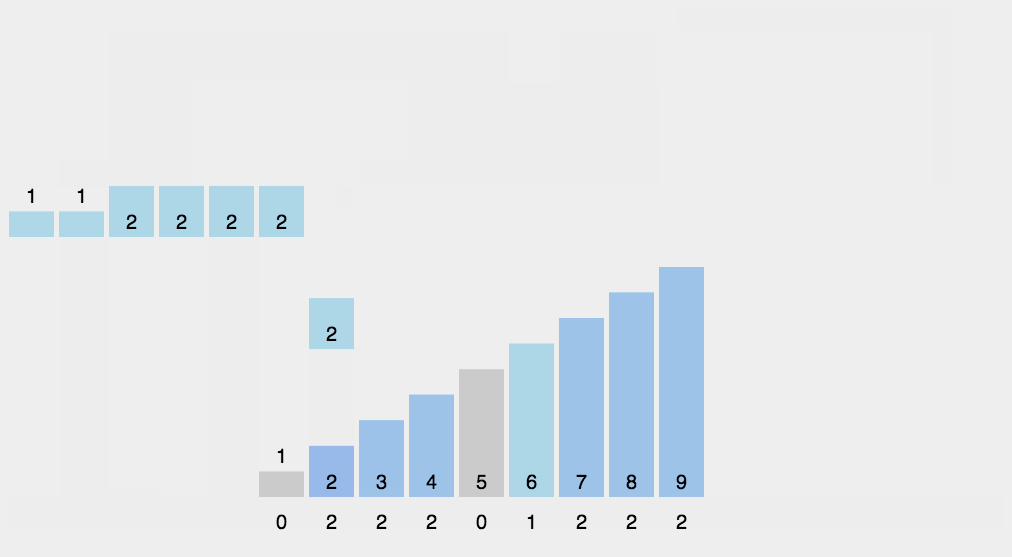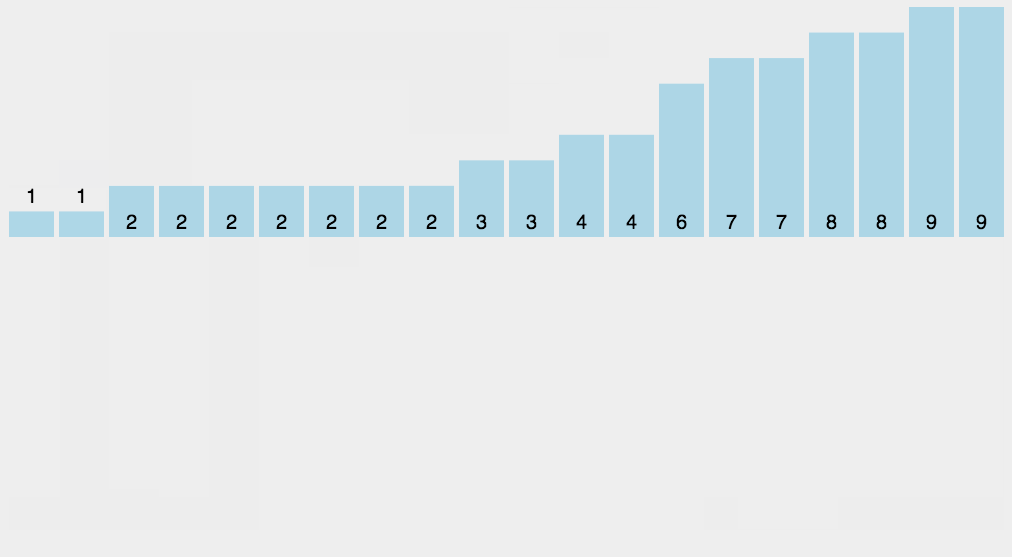// 希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > a[end + gap])
{
a[end + gap] = a[end];
end -= gap;
}
else
break;
}
a[end + gap] = tmp;
}
}
}
//选择排序
void SelectSort(int* a, int n)
{
int start = 0;
int end = n - 1;
while (end > start)
{
int mini = start;
int maxi = end;
for (int i = start; i <= end; i++)
{
if (a[mini] > a[i])
mini = i;
if (a[maxi] < a[i])
maxi = i;
}
if (mini == end)
{
Swap(&a[maxi], &a[end]);
mini = maxi;
Swap(&a[mini], &a[start]);
}
else
{
Swap(&a[maxi], &a[end]);
Swap(&a[mini], &a[start]);
}
end--;
start++;
}
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (a[child] < a[child + 1] && child + 1 < n)
child++;
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
//堆排序
void HeapSort(int* a, int n)
{
for (int i = (n - 2) / 2; i >= 0; i--)
AdjustDown(a, n, i);
for (int i = n - 1; i > 0; i--)
{
Swap(&a[0], &a[i]);
AdjustDown(a, i, 0);
}
}
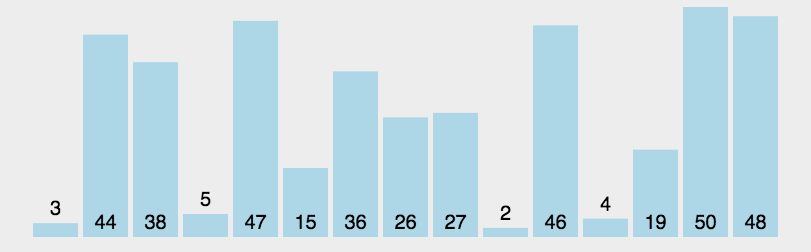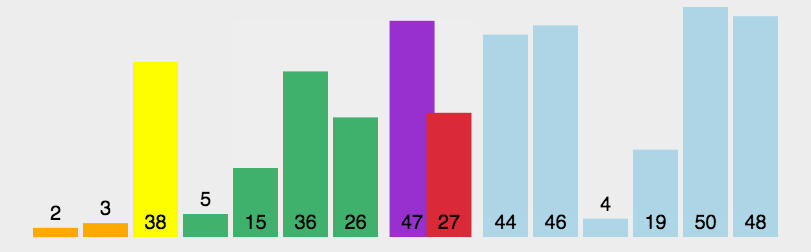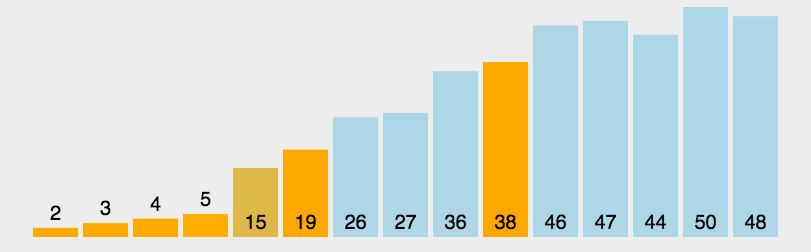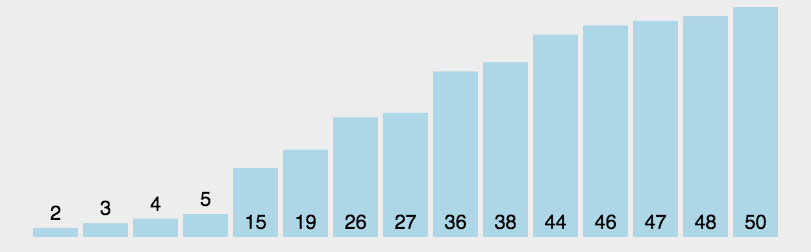
冒泡排序
示意图:
排序过程:
比较相邻的元素。如果第一个比第二个大,就交换它们两个;
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
针对所有的元素重复以上的步骤,除了最后一个;
重复步骤1~3,直到排序完成。
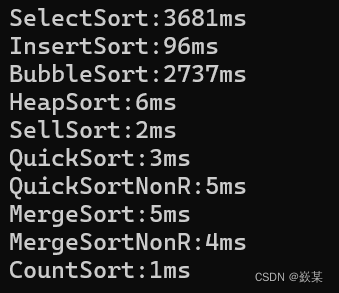
时间复杂度:
O(n^2)
代码实现:
cpp复制代码
//冒泡排序
void BubbleSort(int* a, int n)
{
for (int i = n; i > 0; i--)
{
int prev = 0;
int cur = 1;
int falg = 1;
while (cur < i)
{
if (a[prev] > a[cur])
{
falg = 0;
Swap(&a[prev], &a[cur]);
}
prev = cur;
cur++;
}
if (falg == 1)
break;
}
}
int Midofthree(int* a,int x, int y, int z)
{
if (a[x] > a[y])
if (a[x] > a[z])
if (a[y] > a[z])
return y;
else
return z;
else
return y;
else//a<b
if (a[x] < a[z])
if (a[y] < a[z])
return y;
else//b>c
return z;
else//a>c
return x;
}
时间复杂度:
O(n*log(n))
代码实现:
(1)hoare版本:
cpp复制代码
//hoare版本
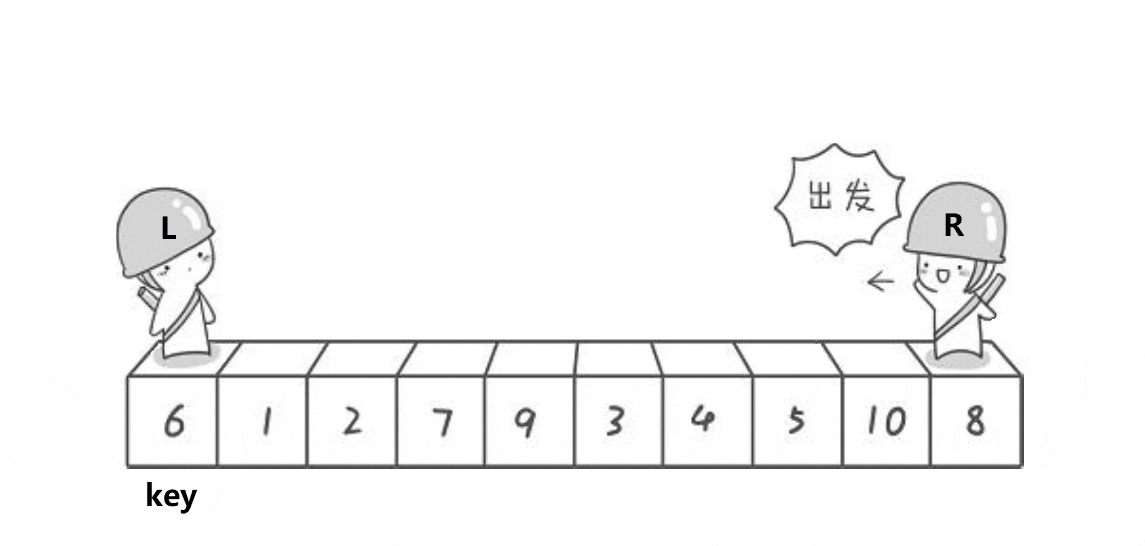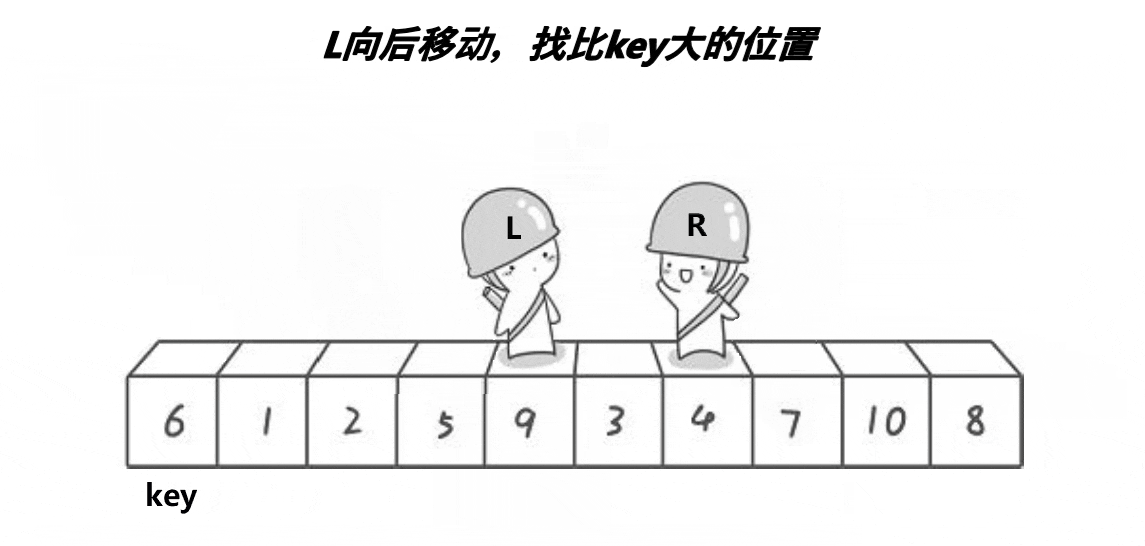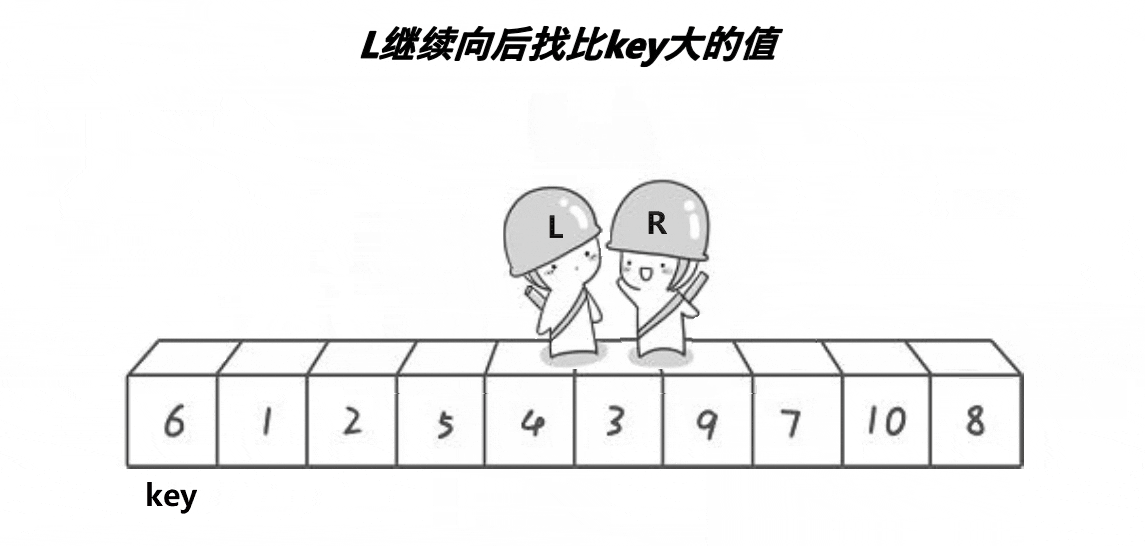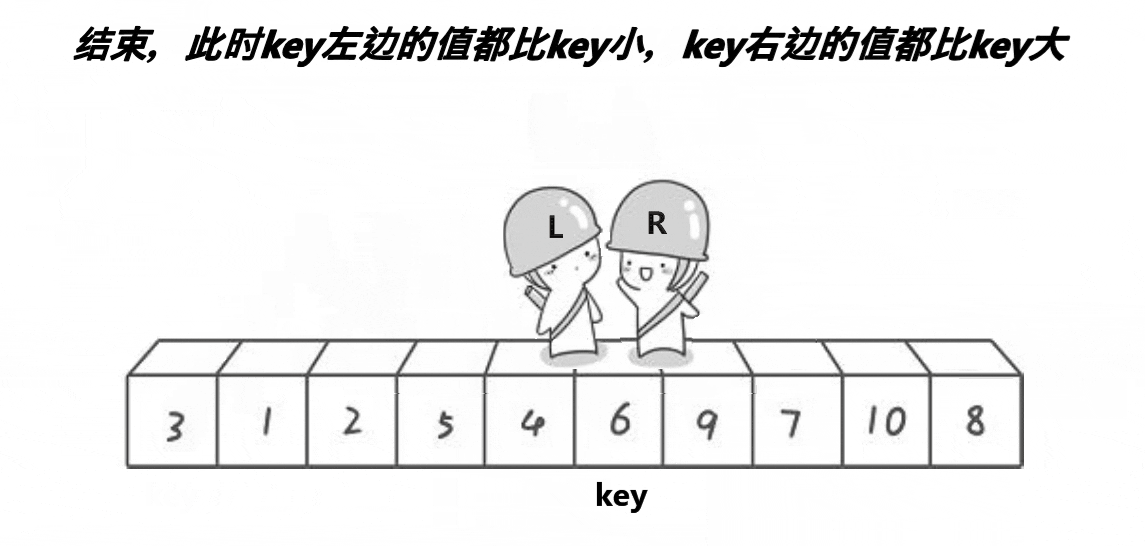
int partsort1(int* a, int left, int right)
{
int begin = left, end = right;
int x = Midofthree(a, left, right, (right + left) / 2);
Swap(&a[x], &a[left]);
int key = left;
while (begin < end)
{
while (begin < end)
{
if (a[end] < a[key])
break;
end--;
}
while (begin < end)
{
if (a[begin] > a[key])
break;
begin++;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[key], &a[begin]);
return begin;
}
(2)双指针版本:
cpp复制代码
//双指针版本
int partsort2(int* a, int left, int right)
{
int x = Midofthree(a, left, right, (right + left) / 2);
Swap(&a[x], &a[left]);
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[prev],&a[keyi]);
return prev;
}
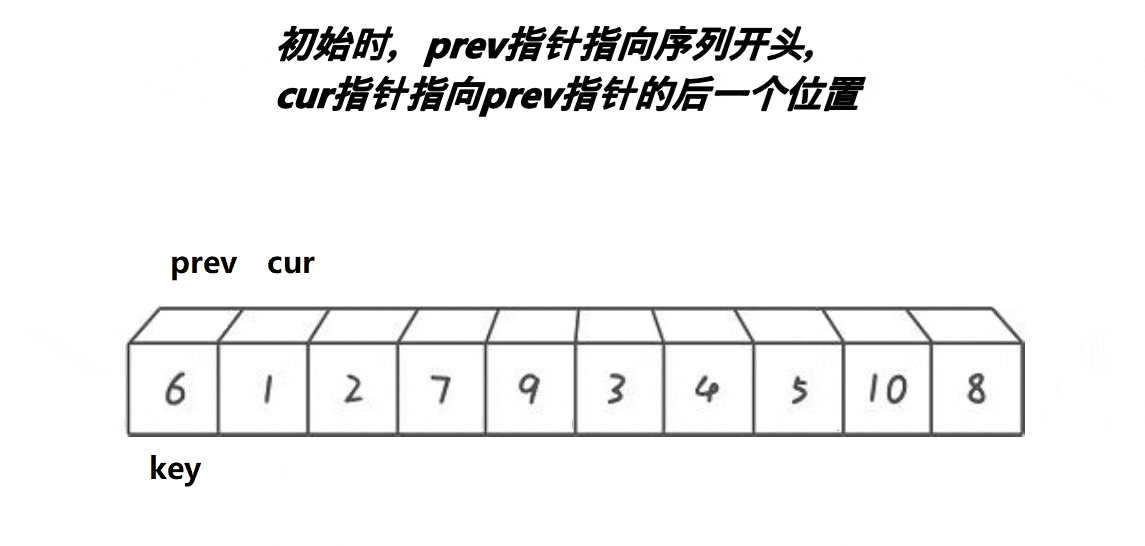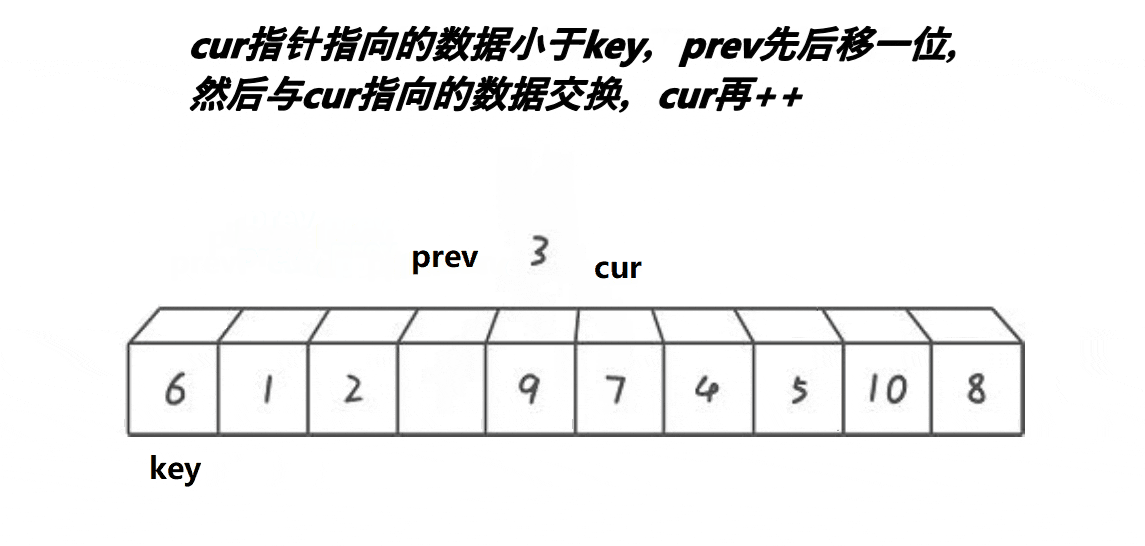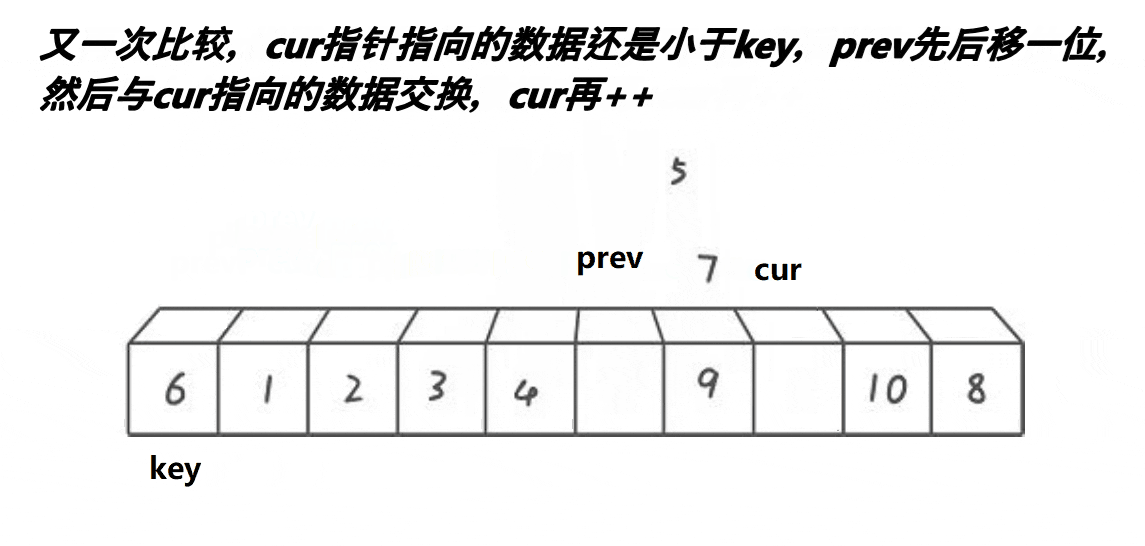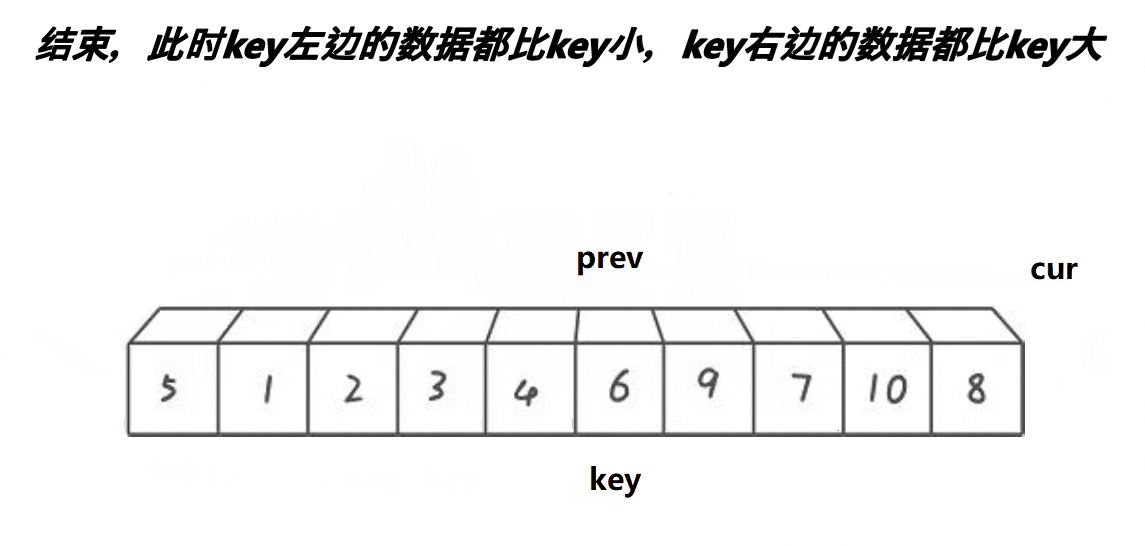
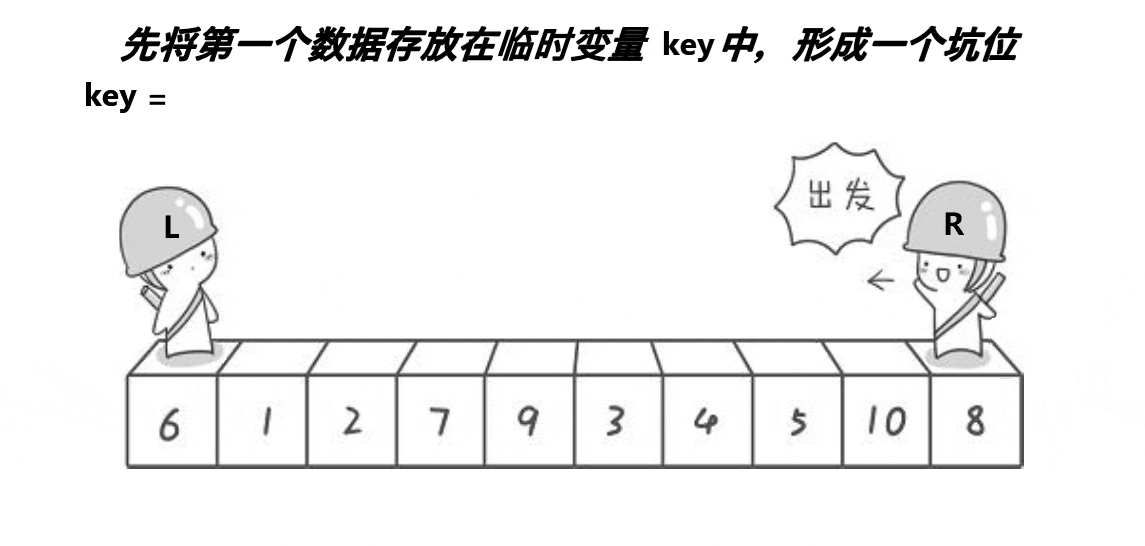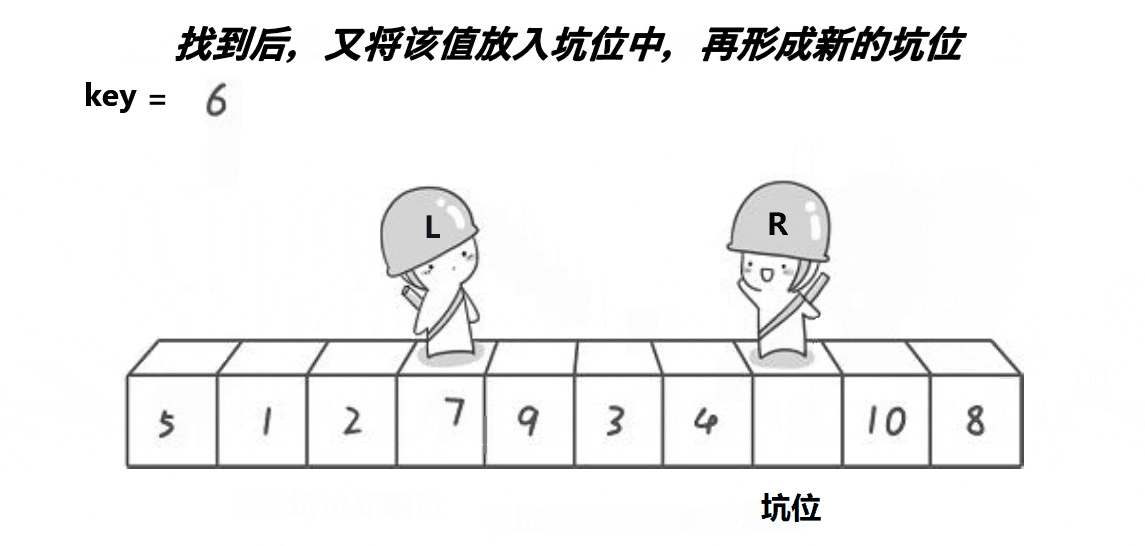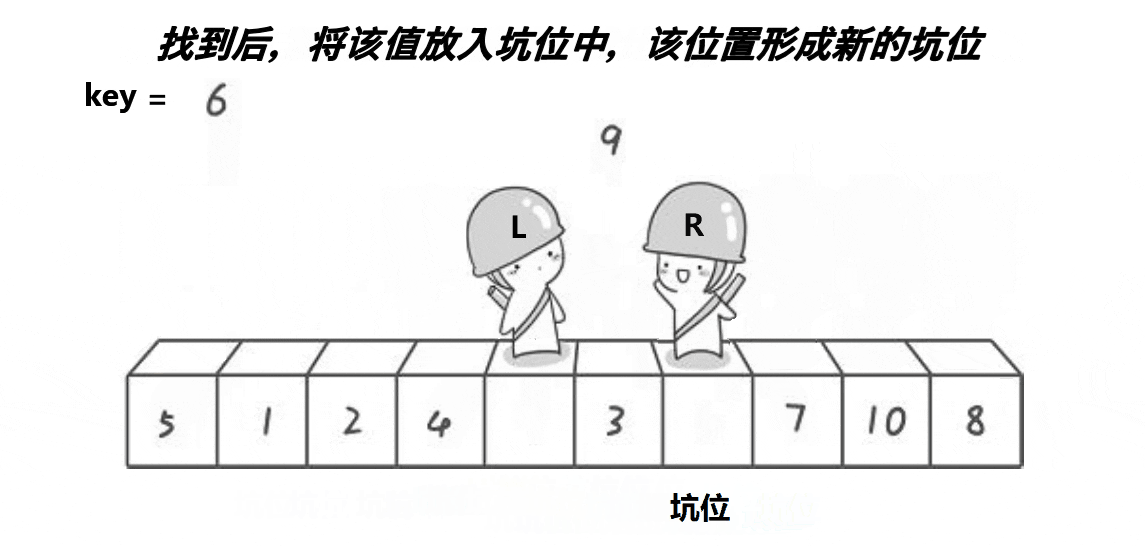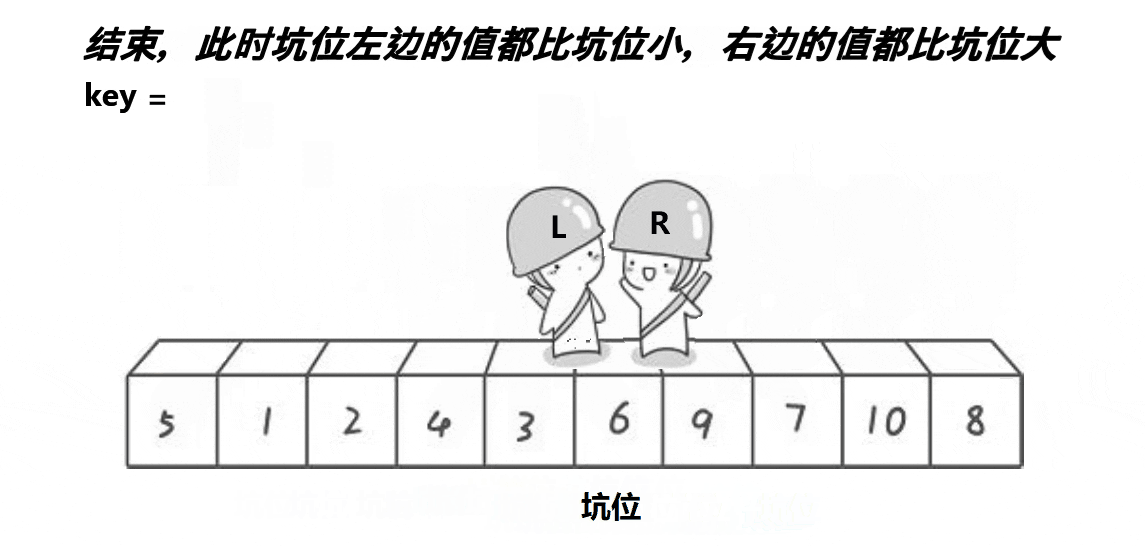
(3)挖坑版本:
cpp复制代码
//挖坑版本
int partsort3(int* a, int left, int right)
{
int x = Midofthree(a, left, right, (right + left) / 2);
Swap(&a[x], &a[left]);
int key = a[left];
int pit = left;
int begin = left;
int end = right;
while (begin < end)
{
while (a[end] >= key && begin < end)
end--;
a[pit] = a[end];
pit = end;
while (a[begin] <= key && begin < end)
begin++;
a[pit] = a[begin];
pit = begin;
}
a[pit] = key;
return pit;
}
递归:
cpp复制代码
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
if (right - left + 1 < 10)
{
InsertSort(a + left, right - left + 1);//小区间优化
return;
}
int keyi = partsort1(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortNonR(int* a, int left, int right)
{
ST s;
STInit(&s);
STPush(&s, right);
STPush(&s, left);
while (!STEmpty(&s))
{
int begin = STTop(&s);
STPop(&s);
int end = STTop(&s);
STPop(&s);
int mid = partsort1(a, begin, end);
if (mid + 1 < end)//注意这里需判断
{
STPush(&s, end);
STPush(&s, mid + 1);
}
if (begin < mid - 1)//注意这里需判断
{
STPush(&s, mid - 1);
STPush(&s, begin);
}
}
}
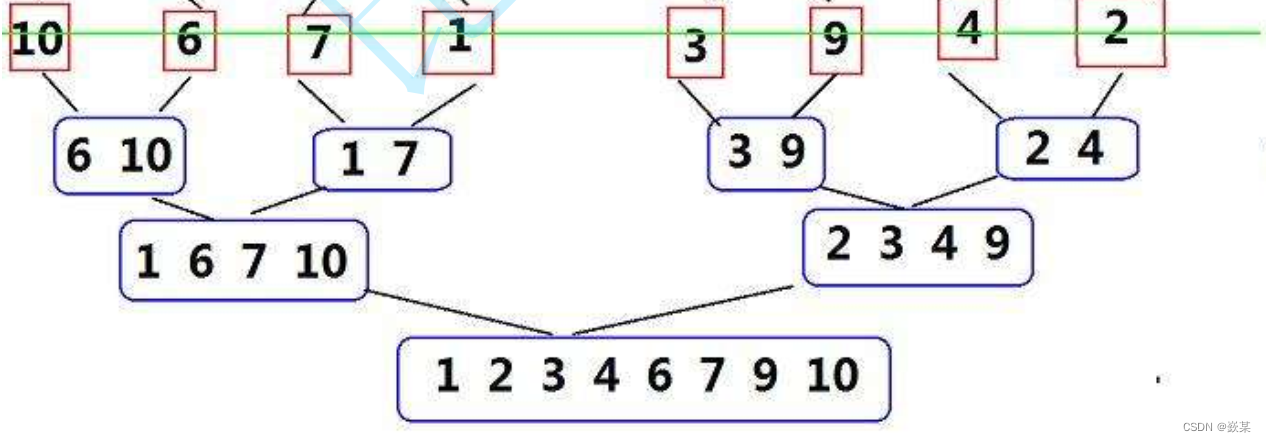
归并排序
示意图:
排序过程:
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
把长度为n的输入序列分成两个长度为n/2的子序列;
对这两个子序列分别采用归并排序;
将两个排序好的子序列合并成一个最终的排序序列。
时间复杂度:
O(n*log(n))
代码实现:
递归:
cpp复制代码
void _MergeSort(int* a, int* tmp, int left, int right)
{
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, tmp, left, mid);
_MergeSort(a, tmp, mid + 1, right);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if(a[begin1] < a[begin2])
tmp[i++] = a[begin1++];
else
tmp[i++] = a[begin2++];
}
while (begin1 <= end1)
tmp[i++] = a[begin1++];
while (begin2 <= end2)
tmp[i++] = a[begin2++];
memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc is fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}
非递归
cpp复制代码
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc is fail");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int j = i;
if (begin2 >= n)
break;
if (end2 >= n)
end2 = n - 1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[j++] = a[begin1++];
else
tmp[j++] = a[begin2++];
}
while (begin1 <= end1)
tmp[j++] = a[begin1++];
while (begin2 <= end2)
tmp[j++] = a[begin2++];
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}
void CountSort(int* a, int n)
{
int min = a[0];
int max = a[0];
for (int i = 0; i < n; i++)
{
if (a[i] > max)
max = a[i];
if (a[i] < min)
min = a[i];
}
int range = max - min + 1;
int* x = (int*)calloc(range, sizeof(int));
if (x == NULL)
{
perror("calloc is fail");
return;
}
for (int i = 0; i < n; i++)
x[a[i] - min]++;
int j = 0;
for (int i = 0; i < n; i++)
while (x[i]--)
a[j++] = i + min;
free(x);
}