一、AI知识库
将已知的问答知识,问题和答案转变成向量存储在向量数据库,在查找答案时,输入问题,将问题向量化,匹配向量库的问题,将向量相似度最高的问题筛选出来,将答案提交。
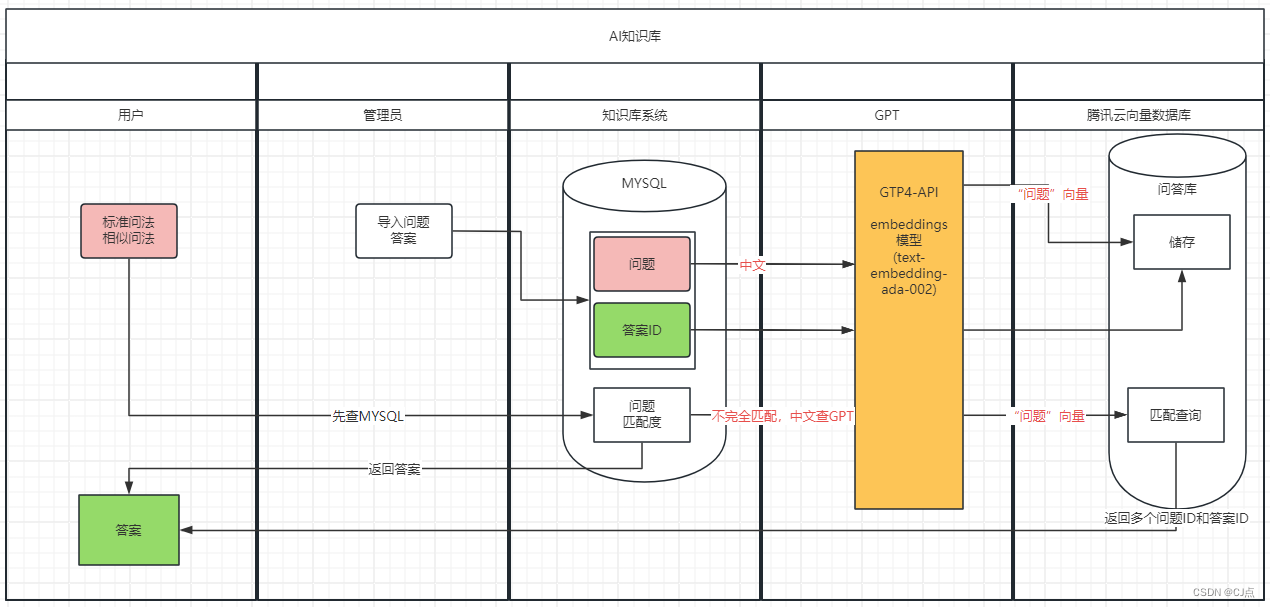
二、腾讯云向量数据库
向量数据库_大模型知识库_向量数据存储_向量数据检索- 腾讯云
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持千亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、自然语言处理等 AI 领域。
三、使用教程(java)
1、项目引用依赖
<!--腾讯云向量数据库使用-->
<dependency>
<groupId>com.tencent.tcvectordb</groupId>
<artifactId>vectordatabase-sdk-java</artifactId>
<version>1.2.0</version>
</dependency>2、application.properties 配置
#向量数据库地址-购买服务器后,获取到外网访问域名,账号密码
vectordb.url=${VECTORDB_URL:http://xxxxxxxxx.com:10000}
vectordb.user=${VECTORDB_USER:root}
vectordb.key=${VECTORDB_KEY:123456}3、初始化客户端
java
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.param.database.ConnectParam;
import com.tencent.tcvectordb.model.param.enums.ReadConsistencyEnum;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
@Component
public class InitVectorClient {
@Value("${vectordb.url:}")
private String vdbUrl;
@Value("${vectordb.user:}")
private String vdbUser;
@Value("${vectordb.key:}")
private String vdbKey;
@Bean
public VectorDBClient vdbClient(){
ConnectParam connectParam = ConnectParam.newBuilder()
.withUrl(vdbUrl)
.withUsername(vdbUser)
.withKey(vdbKey)
.withTimeout(30)
.build();
VectorDBClient client = new VectorDBClient(connectParam, ReadConsistencyEnum.EVENTUAL_CONSISTENCY);
return client;
}
}4、创建表结构
这里使用HTTP的方式
java
curl --location --request POST 'xxxxx.com:10000/database/create' \
--header 'Authorization: Bearer account=root&api_key=123456' \
--header 'Content-Type: application/json' \
--data-raw '{
"database": "db_xiaosi"
}'
curl --location --request POST 'xxxxx.com:10000/collection/create' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer account=root&api_key=123456' \
--data-raw '{
"database": "db_xiaosi",
"collection": "t_bug",
"replicaNum": 0,
"shardNum": 1,
"description": "BUG表关键字向量",
"indexes": [
{
"fieldName": "id",
"fieldType": "string",
"indexType": "primaryKey"
},
{
"fieldName": "bug_name",
"fieldType": "string",
"indexType": "filter"
},
{
"fieldName": "is_deleted",
"fieldType": "uint64",
"indexType": "filter"
},
{
"fieldName": "vector",
"fieldType": "vector",
"indexType": "HNSW",
"dimension": 1536,
"metricType": "COSINE",
"params": {
"M": 16,
"efConstruction": 200
}
}
]
}'5、封装http请求类
java
package com.ikscrm.platform.api.manager.bug;
import cn.hutool.core.date.DateUtil;
import com.ikscrm.platform.api.dao.vector.BugVector;
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.Collection;
import com.tencent.tcvectordb.model.Database;
import com.tencent.tcvectordb.model.DocField;
import com.tencent.tcvectordb.model.Document;
import com.tencent.tcvectordb.model.param.dml.*;
import com.tencent.tcvectordb.model.param.entity.AffectRes;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
/**
* 向量数据库能力
* 接口文档 https://cloud.tencent.com/document/product/1709/97768
* 错误码 https://cloud.tencent.com/document/product/1709/104047
* @Date 2024/3/6 13:49
*/
@Component
@Slf4j
public class VectorManager {
@Resource
private VectorDBClient vdbClient;
/**
* 根据向量查询相似数据。
*
* @param dbName 数据库名称
* @param tableName 表名称
* @param vector 向量
* @return 返回更新操作影响的记录数
* @throws RuntimeException 如果更新过程中发生业务异常
*/
public List<BugVector> findBugList(String dbName, String tableName, List<Double> vector) {
List<BugVector> resultList = new ArrayList<>();
Database database = vdbClient.database(dbName);
Collection collection = database.describeCollection(tableName);
Filter filter = new Filter("is_deleted=0");
//这部分的算法需要深入了解
SearchByVectorParam searchByVectorParam = SearchByVectorParam.newBuilder()
.addVector(vector)
// 若使用 HNSW 索引,则需要指定参数ef,ef越大,召回率越高,但也会影响检索速度
.withParams(new HNSWSearchParams(15))
// 指定 Top K 的 K 值
.withLimit(20)
// 过滤获取到结果
.withFilter(filter)
.build();
// 输出相似性检索结果,检索结果为二维数组,每一位为一组返回结果,分别对应 search 时指定的多个向量
List<List<Document>> svDocs = collection.search(searchByVectorParam);
for (List<Document> docs : svDocs) {
for (Document doc : docs) {
BugVector build = new BugVector();
build.setId(doc.getId());
build.setScore(doc.getScore());
build.setVector(doc.getVector());
for (DocField field : doc.getDocFields()) {
if (field.getName().equals("bug_name")) {
build.setBugName(field.getStringValue());
}
if (field.getName().equals("bug_title")) {
build.setBugTitle(field.getStringValue());
}
if (field.getName().equals("is_deleted")) {
build.setIsDeleted(Integer.valueOf(field.getStringValue()));
}
if (field.getName().equals("create_time")) {
build.setCreateTime(field.getStringValue());
}
if (field.getName().equals("update_time")) {
build.setUpdateTime(field.getStringValue());
}
}
resultList.add(build);
}
}
return resultList;
}
/**
* 将问题向量列表插入到指定的数据库和集合中。
*
* @param dbName 数据库名称,指定要操作的数据库。
* @param tableName 集合名称,即数据表名称,指定要插入数据的表。
* @param list 要插入的数据列表,列表中的每个元素都是TaskVector类型,包含了问题的向量信息及其他相关字段。
*/
public Long insertBugList(String dbName, String tableName, List<BugVector> list) {
try {
Database database = vdbClient.database(dbName);
Collection collection = database.describeCollection(tableName);
List<Document> documentList = new ArrayList<>();
list.forEach(item -> {
documentList.add(Document.newBuilder()
.withId(item.getId())
.withVector(item.getVector())
.addDocField(new DocField("bug_name", item.getBugName()))
.addDocField(new DocField("bug_title", item.getBugTitle()))
.addDocField(new DocField("is_deleted", item.getIsDeleted()))
.addDocField(new DocField("create_time", DateUtil.now()))
.addDocField(new DocField("update_time", DateUtil.now()))
.build());
});
InsertParam insertParam = InsertParam.newBuilder().addAllDocument(documentList).build();
// upsert 实际数据会有延迟
AffectRes upsert = collection.upsert(insertParam);
log.info("向量列表插入数量:{},完成:{}", list.size(), upsert.getAffectedCount());
return upsert.getAffectedCount();
} catch (Exception ex) {
log.error("向量列表插入异常", ex);
throw new RuntimeException("向量列表插入异常" + ex.getMessage());
}
}
}腾讯云的向量库使用方式基本就是这样着,在这里简单的使用到了他的插入和向量查询功能。下一篇讲解GPT的如何与向量数据库结合使用