1.采集中国地震局地震数据约100万条存入.csv和mysql,清洗后的.csv上传mysql;
3.分析指标离线可选用Hive,实时可选装PySpark/PyFlink,可三选一也可以只选一种或者三个都选;
4.计算结果使用sqoop工具对接到mysql数据库的指标表;
5.使用flask+echarts制作可视化大屏、layui查询表格;
6.使用卷积神经网络KNN CNN RNN对地震数据进行预测;
创新点:全新DrssionPage爬虫框架、可视化大屏、离线计算实时计算全部实现、深度学习算法预测地震。
2024 届本科毕业论文(设计)
基于Hadoop的地震预测的
分析与可视化研究
姓 名: ++++++++ ++++田伟情++++ ++++_____++++
系 别: ++++_++++ ++++信息技术学院++++ ++++++++
专 业: ++++数据科学与大数据技术++++
学 号: ++++++++ ++++2011103094++++ ++++______++++
指导教师: ++++++++ ++++王双喜++++ ++++___++++
年 月 日
目 录
[++++1 绪论++++](#1 绪论)
[++++2 相关技术与工具++++](#2 相关技术与工具)
[++++2.1 大数据技术概述++++](#2.1 大数据技术概述)
[++++2.2 hadoop介绍++++](#2.2 hadoop介绍)
[++++3 地震数据分析++++](#3 地震数据分析)
[++++3.1 数据收集与处理++++](#3.1 数据收集与处理)
[++++3.2 特征提取与选择++++](#3.2 特征提取与选择)
[++++4 地震数据可视化++++](#4 地震数据可视化)
[++++4.1 可视化技术概述++++](#4.1 可视化技术概述)
[++++4.2 可视化设计原则++++](#4.2 可视化设计原则)
[++++4.3 可视化实现与评估++++](#4.3 可视化实现与评估)
[++++5 实验设计++++](#5 实验设计)
[++++5.2 Hive数仓表++++](#5.2 Hive数仓表)
[++++5.3 Hive数据分析ads表++++](#5.3 Hive数据分析ads表)
[++++5.4 Spark数据分析++++](#5.4 Spark数据分析)
[++++5.5 Sqoop实现Hive数据同步至Mysql++++](#5.5 Sqoop实现Hive数据同步至Mysql)
[++++5.6 Echarts数据可视化++++](#5.6 Echarts数据可视化)
[++++5.7 地震数据维护++++](#5.7 地震数据维护)
[++++6 结果讨论++++](#6 结果讨论)
[++++6.1 结果总结++++](#6.1 结果总结)
[++++6.2 结果分析++++](#6.2 结果分析)
[++++6.3 存在问题++++](#6.3 存在问题)
[++++6.4 结果展望++++](#6.4 结果展望)
[++++致 谢++++](#致 谢)
基于Hadoop的地震预测的分析与可视化研究
田伟情 指导教师:王双喜
(商丘师范学院信息技术学院,河南商丘 476000)
摘 要:08年四川5·12汶川地震、10年青海玉树地震、13年四川雅安地震,到23年甘肃积石山地震,大大小小的地震无数次的上演,带给我们的不仅是肉体上的疼痛,还有无法治愈的心灵创伤。在睡梦中因地震而惊醒,轰隆隆的地裂声还有那些肉眼可见的消失的村庄恐怕是无数遭遇地震的人的噩梦,也是所有人共同的悲哀。即使没有亲身经历过,但新闻报道中倒坍的房屋,埋头救人的官兵,隔着屏幕也能感受到疼痛。 因此,准确地预测地震的发生时间、地点和震级对于人们的生命安全和财产安全具有重要意义。然而,地震预测是一个复杂而困难的问题,受到多种因素的影响,如地质构造、地下水位变化、地壳运动等。传统的地震预测方法往往依赖于经验和专家判断,准确度和效率有限。随着大数据技术的快速发展,越来越多的地震数据被收集和存储起来。大数据分析和处理技术能够对这些海量的地震数据进行高效的分析和建模,为地震预测提供更准确的预测模型。然而,大数据在地震预测中的应用也面临着一些挑战。首先,地震数据具有高维度和复杂的特征,需要选择合适的特征参数进行分析和建模。其次,地震数据的规模庞大,传统的数据处理方法无法满足实时性要求。此外,地震数据的可视化也是一个重要问题,如何将海量的地震数据以直观的方式展示给用户,提高地震预测的可理解性和可操作性,也是一个需要解决的问题。 因此,本研究基于Hadoop的大数据技术,对地震数据进行分析和可视化,提高地震预测的准确性和效率。具体而言,本研究将使用Hadoop框架对地震数据进行分析和建模,利用线性回归预测算法构建地震预测模型。同时,本研究利用echarts的可视化技术和工具,将地震数据以直观的方式展示给用户,提高地震预测的可理解性和可操作性。
关键词:大数据、地震、地震预测、Hadoop、线性回归预测算法
Analysis and visualization of earthquake prediction based on Hadoop
TIAN Weiqing Supervisor: WANG Shuangxi
(College of Information Technology, Shangqiu Normal University, Shangqiu 476000, China)
****Abstract :****The 5.12 Wenchuan earthquake in Sichuan in 08, the Yushu earthquake in Qinghai in 10, the Ya'an earthquake in Sichuan in 13, and the Jishishan earthquake in Gansu in 23 years, earthquakes of all sizes have been staged countless times, bringing us not only physical pain, but also incurable psychological wounds. Waking up in your sleep by the earthquake, the rumbling sound of the ground cracking, and the visible disappearance of the villages are probably the nightmare of countless people who have been hit by the earthquake, and it is also the sorrow shared by everyone. Even if you haven't experienced it yourself, you can feel the pain through the screen of the collapsed houses in the news reports and the officers and soldiers who buried their heads in saving people. Therefore, it is of great significance to accurately predict the time, place and magnitude of earthquakes for the safety of people's lives and property. However, earthquake prediction is a complex and difficult problem that is affected by a variety of factors, such as geological structure, changes in groundwater level, crustal movements, etc. Traditional earthquake prediction methods often rely on experience and expert judgment, and their accuracy and efficiency are limited. With the rapid development of big data technology, more and more seismic data is collected and stored. Big data analysis and processing technology can efficiently analyze and model these massive seismic data, and provide more accurate prediction models for earthquake prediction. However, the application of big data in earthquake prediction also faces some challenges. First of all, seismic data has high-dimensional and complex features, and it is necessary to select appropriate feature parameters for analysis and modeling. Secondly, the scale of seismic data is huge, and traditional data processing methods cannot meet the real-time requirements. In addition, the visualization of seismic data is also an important problem, and how to display massive seismic data to users in an intuitive way and improve the comprehensibility and operability of earthquake prediction is also a problem that needs to be solved. Therefore, this study analyzes and visualizes earthquake data based on Hadoop's big data technology to improve the accuracy and efficiency of earthquake prediction. Specifically, this study will use the Hadoop framework to analyze and model seismic data, and use the linear regression prediction algorithm to construct an earthquake prediction model. At the same time, this study uses the visualization technology and tools of ECHARTS to present earthquake data to users in an intuitive way, so as to improve the comprehensibility and operability of earthquake prediction.
Key words:big data,earthquake, earthquake prediction、Hadoop、Linear regression prediction algorithm
1 绪论
-
- 研究背景
关于地震的具体成因,纵观国内外研究,目前来说没有具体的共识,国内外学者关于地震的成因和预警进行了多方面的研究,将理论研究应用到具体实践,为探索地震发生的机制提供了宝贵的经验。而地震预警是应对当前地震灾害,减轻国家和人民生命和财产损失的有效方法。当前地震检测预警的方法主要有多指标数据预警法、震波强度预警法。但是关于地震预测仍存着困难,比如地震大小难测定,无法准确计算出地震的等级;震源位置难测定,震源的定位主要是通过计算地震波到达不同观测地点的时间,再根据地震波再介质中的传播速度来计算震源的具体位置,但是地球介质存在不匀质性,所以导致计算困难。
-
- 国内研究现状
关于当前国内关于地震的研究主要有以下几个方面。首先是不确定的地震具体成因但是关于诱发地震的人为原因,我国科学家也做出了具体的研究,比如注水、开采活动以及水库诱发等原因。自从08年经济快速发展以来,人们对地球的破坏越来越严重,从而导致地震发生的频率越来越高,有可能会导致从来不发生地震的地区变成地震频发地区。
关于地震学,现在也有了机器学习方法在其上面的具体应用,比如图像处理和影音处理,通过搭建卷积神经网络去识别震相和挑到时(下图为利用机器学习来识别汶川地震的震相和挑到时)。
-
- 国外研究现状
对于国外对于地震检测的研究,以美国为例。美国经济发达,科学技术遥遥领先,对于该方面的研究更具有代表意义,并且美国也是地震高发区(以下为美国地震危险模型)。
美国通过ANSS来实现地震早期预测、地震强度评估,但近年来ANSS管理复杂,设施老化,给美国的地震预测带来新的问题,通过投入资金、人力,优化设施的关键部分,确保ANSS能够在危急时刻发挥作用。关于地震的早期预警,通过获取和分析用以确定地震大小和位置的测震和大地测量数据,是人们能够在地震发生之前获得早期预警,减少人员伤亡和财产损失。美国ANSS的目标就是建立一套地震早期预警系统(以下为地震早期预警系统)。
2
|---|---|
| |
| | |
相关技术与工具
2.1 大数据技术概述
1.数据技术可以应用于地震数据的收集、存储、处理和分析。首先,大数据技术可以对大规模地震数据进行高效的收集和存储。并且通过分布式存储系统,像Hadoop的核心组件HDFS,可以存储大量的地震数据,具有高可靠性、高扩展性、高效性、高容错性。其次,大数据技术可以对地震数据进行预处理和清洗。地震数据通常包含大量的噪声和无效数据,需要进行数据清洗和预处理,以提高数据质量和准确性。可以通过Hadoop的MapReduce,实现对地震数据的高效处理和清洗。
2.大数据技术在地震预测中具有以下优势。首先,大数据技术可以处理大规模的地震数据,通过分布式计算和存储,实现对大规模地震数据的高效处理。然后,大数据技术可以提高地震预测的准确性。通过使用大数据处理工具和算法,可以提取地震数据中的特征参数,并构建准确的预测模型。并且,大数据技术还可以实现对地震数据的实时处理和分析。地震数据具有实时性和时序性,需要及时进行处理和分析,以实现及时的地震预测。通过使用大数据处理框架和实时数据流处理技术,可以实现对地震数据的实时处理和分析。
所以大数据在地震预测中具有重要的作用,通过大数据处理实现对大规模地震数据的高效处理和分析,提高自恨预测的准确性和效率。
2.2 hadoop介绍
Hadoop集群是一个分布式计算平台,用来处理各种各样的海量数据。Hadoop的核心组件是HDFS和MapReduce。HDFS是分布式存储系统,它将文件分成许多不同的块,并且存储在不同的节点上,实现数据的并行处理和高效性。MapReduce是将任务分解成多个子任务,在不同的节点上进行处理。Hadoop主要是在任务量很大的情况下,单机不能进行正常处理,所以采用分布式的方法进行处理,用分布式集群的方法处理数据,提高实现的复杂性和难度,能有效的降低难度和处理数据的工作量。
在地震预测中,Hadoop技术可以应用于以下几个方面:一、数据存储与管理,Hadoop可以存储大规模的地震数据。二、数据清洗与预处理,对地震数据进行清洗和预处理,提高数据的质量和准确性。三、特征提取与选择,通过提取与选择相关特征可以构建有效的数据预测模型。四、数据建模与分析,通过分布式计算,可以快速构建模型,并利用大规模数据进行优化,提高预测的准确性和效率。
2.3 线性回归预测算法
回归分析预测算法中最常用并且最简单的就是线性回归预测算法。线性回归预测算法处理的问题类型之一是需要在特定损失标准下,通过已知的一组输入样本和对应的目标值,找到目标值与输入之间的函数关系。所以当给定新的样本输入值时,可以预测相应的目标值是多少。
3 地震数据分析
3.1 数据收集与处理
数据收集与处理是地震预测研究中非常重要的一个环节,地震数据的来源主要包括地震监测站、地震目录和卫星观测等。地震监测站是用于实时监测地震活动的设备,可以记录地震事件的震级、震源位置、时间等信息。地震监测站会定期收集和记录地震数据,包括地震波形、地震事件的震级和震源位置等。这些数据通常以地震波形数据的形式存储,需要进行清洗和预处理以提取有用的特征。地震目录是一个包含地震事件基本信息的数据库,通常包括地震事件的震级、震源位置、发生时间等。地震目录数据通常由地震监测机构进行整理和发布,可以通过数据接口或者公开的数据集获取。地震目录数据的清洗和预处理包括去除重复数据、修正错误数据、填补缺失数据等。卫星观测可以提供地震事件的相关物理参数,例如地表形变、地壳运动等。这些观测数据可以通过卫星传感器获取,并经过处理得到有用的地震预测信息。卫星观测数据的清洗和预处理包括去除噪声、校正数据等。
数据清洗和预处理的过程包括数据去噪、数据插值、数据平滑等。最后,经过数据清洗和预处理的地震数据可以用于特征提取和选择,用于构建地震预测模型。特征提取和选择的方法可以从地震数据中提取出与地震预测相关的特征参数。
通过对地震数据的收集、清洗和预处理,可以得到高质量的地震数据,为后续的数据分析和建模提供可靠的基础。
3.2 特征提取与选择
3.2.1 特征提取
特征提取是将一些原始的数据维度减少或者将原始的特征进行重新组合用来方便后续的使用。特征提取的主要作用是减少数据维度和整理已有的数据特征。
特征提取的方法主要有频域特征提取、时域特征提取、波形特征提取。频域特征提取主要是对地震数据进行傅里叶变换,提取频域特征,如主频、频谱形态等。时域特征提取是提取地震数据的时域统计特征,如均值、方差、峰值等。波形特征提取是提取地震波形的特征,如振幅、持续时间、波形变换等。
3.2.2 特征选择
特征选择是一个过程,它的目的是找到最佳的特征子集,可以消除不相关或多余的特征,从而减少特征数量,提升模型精度,缩短执行时间。特征选择方法包括过滤法、包裹法和嵌入法。过滤式主要是使用统计方法,如方差分析、卡方检验等选取具有显著差异的特征;包裹法是使用启发式搜索算法,选择最佳特征子集;嵌入法是使用机器学习算法如决策树、随机森林等。
4 地震数据可视化
4.1 可视化技术概述
地震数据可视化是将地震数据转化为图形化的形式,以便更直观地理解和分析地震活动的模式和趋势。它在地震预测研究中具有重要意义,可以让我们更好地理解地震的发生规律,提高地震预测的准确性和效率。地震数据可视化的意义主要体现在以下几个方面:首先,地震数据可视化能够帮助研究人员更好地理解地震数据的特征和分布情况,发现其中的规律和趋势。通过可视化技术,可以对地震数据进行交互式的探索和分析,从而发现潜在的地震活动模式。其次,地震数据可视化可以将研究结果以直观、易懂的方式展示出来,使得非专业人士也能够理解和认识地震的危险性和重要性。这有助于提高公众的地震意识和防灾意识,促进地震预测技术的广泛应用和推广。然后,地震数据可视化可以为决策者提供直观的信息和洞察力,帮助他们制定科学合理的地震防灾和应急预案。通过可视化技术,地震数据可以以地图、图表等形式呈现,使决策者更好地了解地震活动的时空分布和趋势,从而采取相应的预防和应对措施。
目前常用的地震数据可视化的工具包括地震地图、时间序列表、热力图、3D可视化等等。地震地图是将地震活动以地理坐标的形式展示在地图上的工具。通过地震地图,可以直观地看到地震的空间分布和强度等信息。时间序列图能够以时间为横轴,地震活动的频率、强度等指标为纵轴,展示地震活动的时序变化。通过时间序列图,可以观察地震的季节性、周期性等规律。热力图可以通过颜色的深浅来展示地震活动的密度和强度等信息。通过热力图,可以直观地看到地震活动的高发区和低发区。3D可视化可以将地震数据以三维图形的形式展示出来,使得地震的空间分布更加直观。通过3D可视化,可以观察地震活动的立体特征和空间变化。随着技术的进步和发展,还有更多新的可视化工具不断涌现。通过这些工具,研究人员可以更好地理解和分析地震数据,提高地震预测的准确性和效率。
4.2 可视化设计原则
在地震数据的可视化设计中,需要遵循一些关键原则,以确保有效传达地震数据的信息并提供有用的见解。以下是一些可视化设计原则:1.简洁性:可视化应该简洁明了,避免过多的视觉元素和复杂的图表类型。清晰的布局和简单的图表能够更好地传达地震数据的特征和趋势。2.一致性:保持一致的颜色、字体和图表风格,以便用户能够轻松地识别和理解不同的图表和图形。一致性还包括在不同的可视化中使用相同的标记和符号,以便用户能够建立直观的关联。3.重点突出:通过使用颜色、大小和形状等视觉编码来突出强调地震数据中的重要信息。重要的数据点应该在可视化中明显可见,以便用户能够快速获取关键见解。4.上下文提供:在可视化中提供适当的上下文信息,例如地理位置、时间范围和地震强度等,以帮助用户更好地理解地震数据。上下文信息有助于用户建立对地震事件的整体认知,并能够更准确地解释和分析数据。5.互动性:提供交互式功能,使用户能够自定义和探索地震数据。例如,通过缩放、过滤和排序等操作,用户可以根据自己的需求和兴趣来进行数据探索和分析。互动性能够增强用户对数据的参与感和理解能力。6.可解释性:可视化应该能够清晰地解释地震数据的含义和趋势,而不仅仅是展示数据。提供合适的图例、标签和注释,以帮助用户解读图表和图形,并理解地震数据的背后含义。7.多维度呈现:地震数据通常具有多个维度,例如地震震级、深度、地点等。通过使用多个图表和视图,以及交叉过滤和联动操作等技术,可以同时展示多个维度的数据,从而提供更全面的地震数据分析。8.可比较性:在可视化中提供不同地震事件之间的比较,以便用户能够发现和理解地震数据中的模式和差异。例如,通过并列显示多个地震事件的图表,用户可以比较它们的震级、时间和地点等属性。
通过遵循以上可视化设计原则,可以提高地震数据可视化的效果和可用性,使用户能够更好地理解和分析地震数据,并从中获取有价值的见解。
4.3 可视化实现与评估
地震数据可视化是一种有效的方式,可以帮助人们更直观地理解地震数据,并发现其中潜在的规律和趋势。本节将介绍使用合适的工具实现地震数据可视化,并对可视化效果进行评估。
在地震数据可视化中,选择合适的工具非常重要。常用的可视化工具包括Tableau、D3.js、Matplotlib等。本研究选择使用echarts作为可视化工具,原因在于echarts可以提供直观、交互丰富、可以高度个性化定制的数据可视化图表。
在进行地震数据可视化设计时,需要考虑以下几个关键原则:(1)数据映射:将地震数据的各个维度映射到可视化元素上,例如将震级映射为柱状图的高度。(2)视觉编码:使用不同的颜色、形状、大小等视觉编码方式来展示地震数据的不同属性,以增强可视化效果和理解性。(3)空间关系:利用地图等空间关系来展示地震数据的地理位置信息,以便更好地理解地震分布和相关性。(4)交互性:提供交互功能,例如放大缩小、切换视图等,使用户可以根据需求自由探索地震数据。
其次,为了评估地震数据可视化的效果,可以考虑以下几个指标:(1)可读性:评估可视化结果是否能够清晰地传达地震数据的信息。(2) 交互性:评估交互功能的灵活性和用户体验。(3)准确性:评估可视化结果是否准确地反映了地震数据的特征和趋势。(4)实用性:评估可视化结果是否对地震预测和分析有实际的帮助。
通过合适的工具实现地震数据的可视化,并对可视化效果进行评估,可以帮助研究人员更好地理解地震数据的规律和趋势,提高地震预测的准确性和效率。同时,可视化结果也可以为决策者提供参考,以制定相应的地震应对策略。
5 实验设计
5.1首先将数据上传到hdfs上面
hdfs dfs -mkdir -p /project/earthquake
hdfs dfs -put /data/file/ods_eq.csv /project/earthquake
5.2 Hive数仓表
(1)ods层表(建立地震数据的数据库)
drop table if exists project.ods_earthquake_data;
CREATE TABLE project.ods_earthquake_data
(
`index_num` string COMMENT '序号',
`date_key` string COMMENT '发震时刻(国际时)',
`longitude` string COMMENT '经度(°)',
`latitude` string COMMENT '纬度(°)',
`source_depth` string COMMENT '震源深度(Km)',
`ms` string COMMENT '地表波震级,是由表面波振幅和频率谱密度计算得出的震级,适用于深度在70公里以下的大地震',
`ms7` string COMMENT '以7秒为周期的地表波震级,是Ms震级的一种变体,适用于大地震的研究',
`ml` string COMMENT '局部地震震级,也称为里氏震级,是由本地地震测站记录到的地震波振幅计算得出的震级,适用于浅层地震',
`local_mb` string COMMENT '体波震级,是由体波(即P波和S波)的振幅和频率计算得出的震级,适用于深部地震',
`body_wave_mb` string COMMENT '以1秒为周期的体波震级,是mb震级的一种变体,适用于大地震的研究',
`location` string COMMENT '地点'
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"",
"escapeChar" = "\\"
)
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
tblproperties ("skip.header.line.count" = "1","comment" = "地震数据")
;
load data inpath '/project/earthquake/ods_eq.csv' into table project.ods_earthquake_data;
(2)dwd层表
dwd层对原始数据做轻度清洗(数据类型转换,去重)
DROP TABLE IF EXISTS project.dwd_earthquake_data;
CREATE TABLE project.dwd_earthquake_data
stored as ORC AS
select index_num,
date_key,
longitude,
latitude,
source_depth,
ms,
ms7,
ml,
local_mb,
body_wave_mb,
location
from (select cast(index_num as bigint) as index_num,
date_key,
cast(longitude as decimal(10, 2)) as longitude,
cast(latitude as decimal(10, 2)) as latitude,
cast(source_depth as bigint) as source_depth,
cast(ms as decimal(10, 1)) as ms,
cast(ms7 as decimal(10, 1)) as ms7,
cast(ml as decimal(10, 1)) as ml,
cast(local_mb as decimal(10, 1)) as local_mb,
cast(body_wave_mb as decimal(10, 1)) as body_wave_mb,
location,
row_number() over (partition by longitude,latitude,source_depth,ms,
ms7,ml,local_mb,body_wave_mb order by index_num) as rn
from project.ods_earthquake_data) as t
where rn = 1;
清洗结果如下
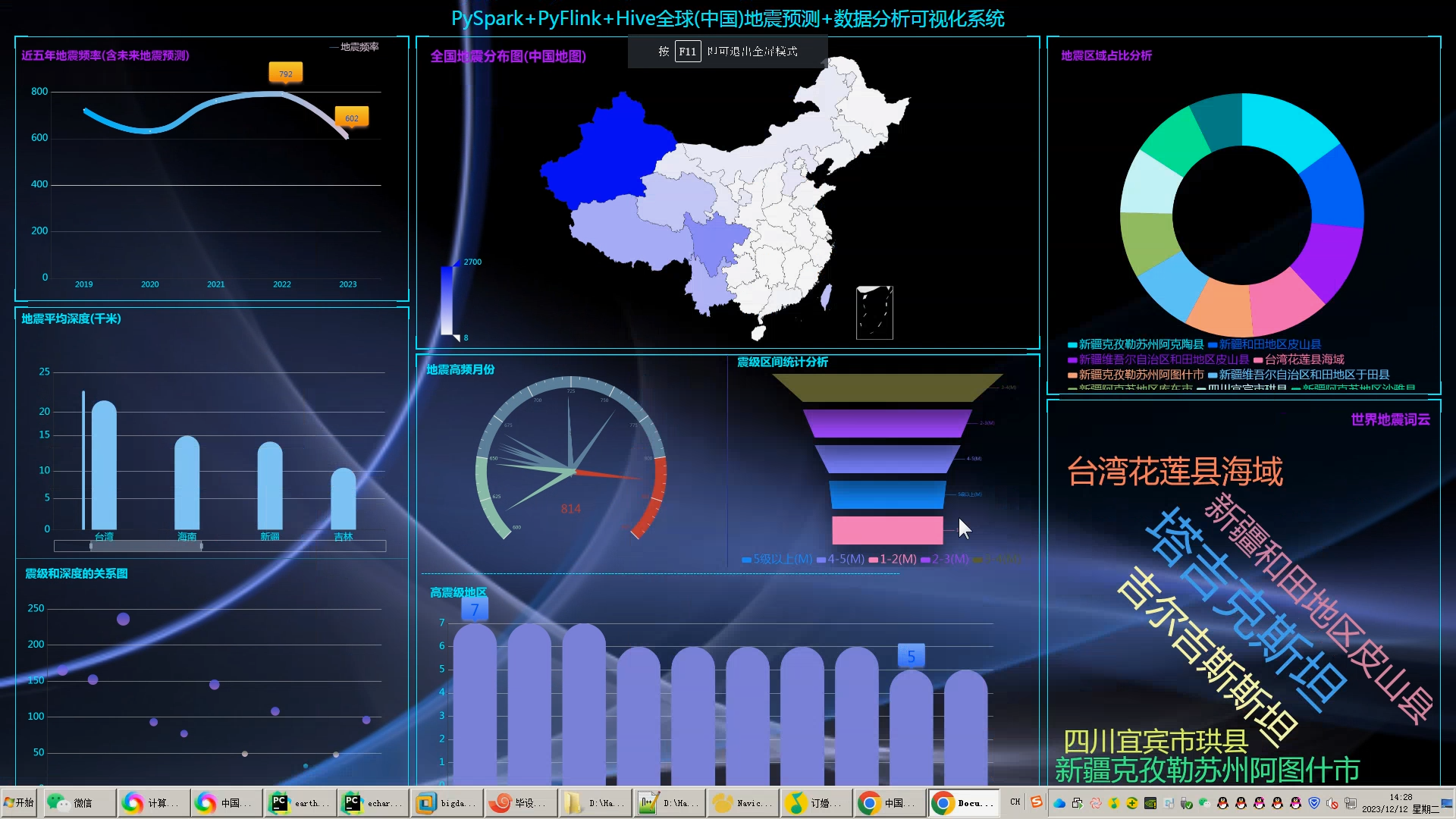
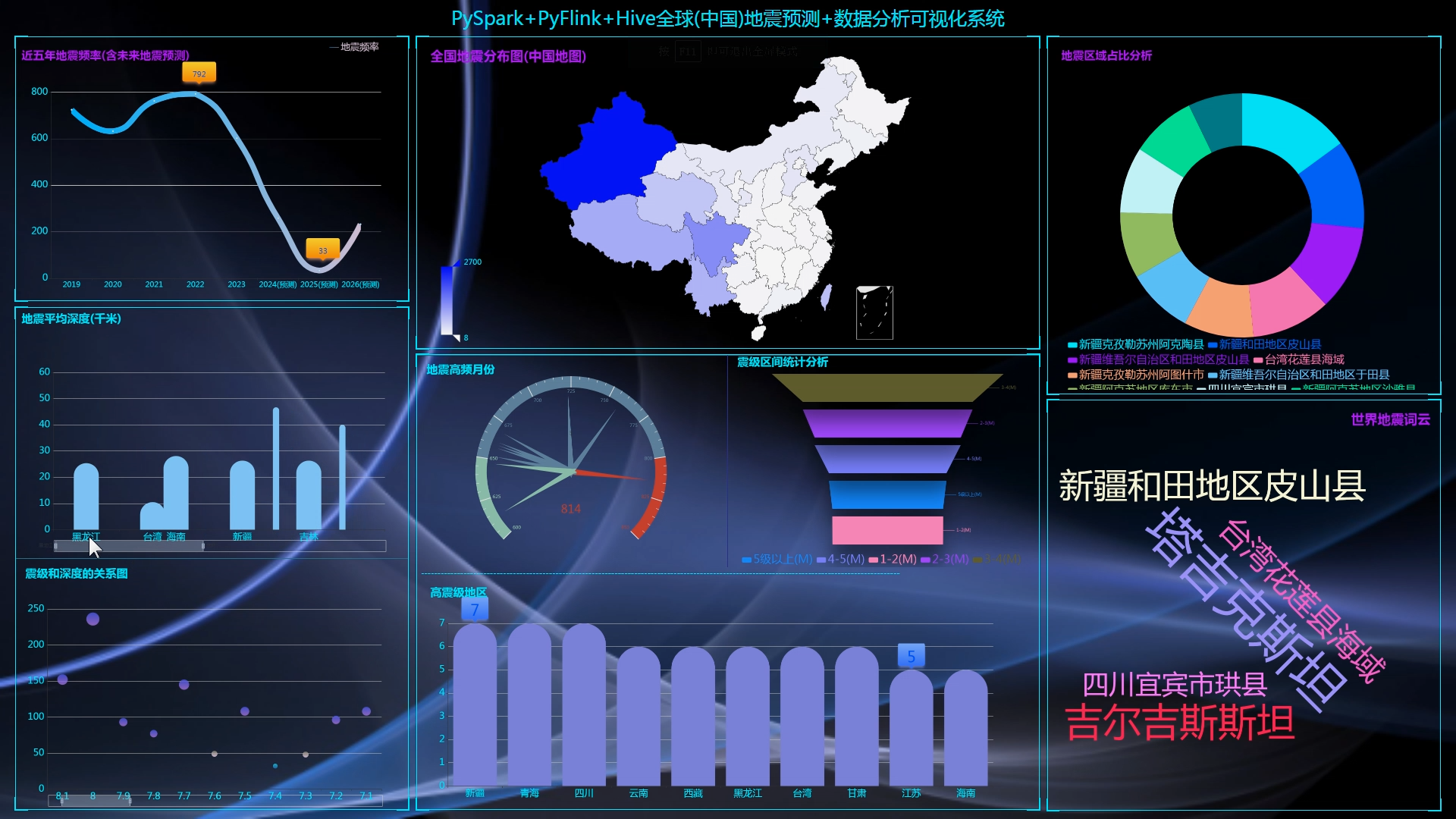
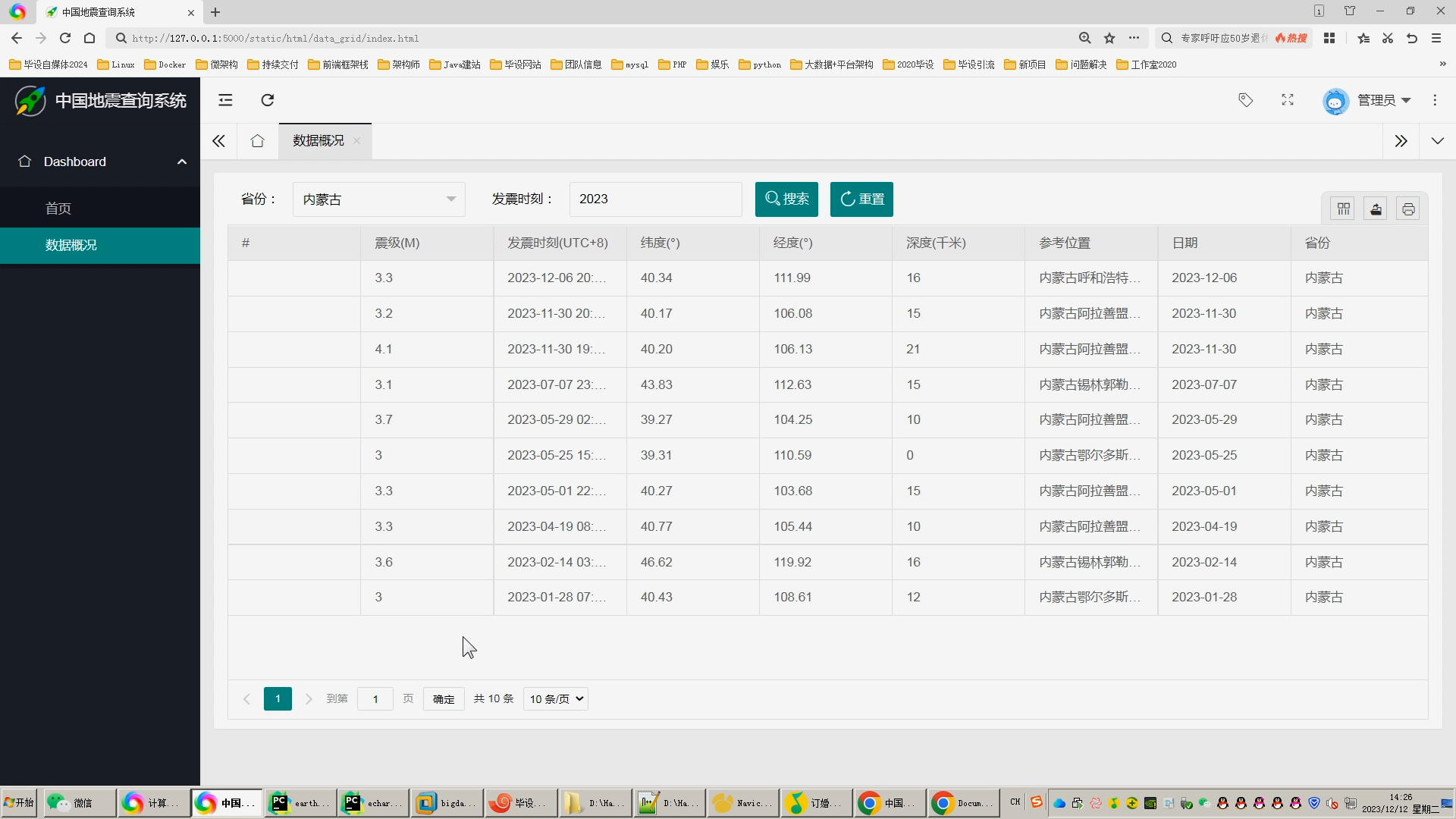
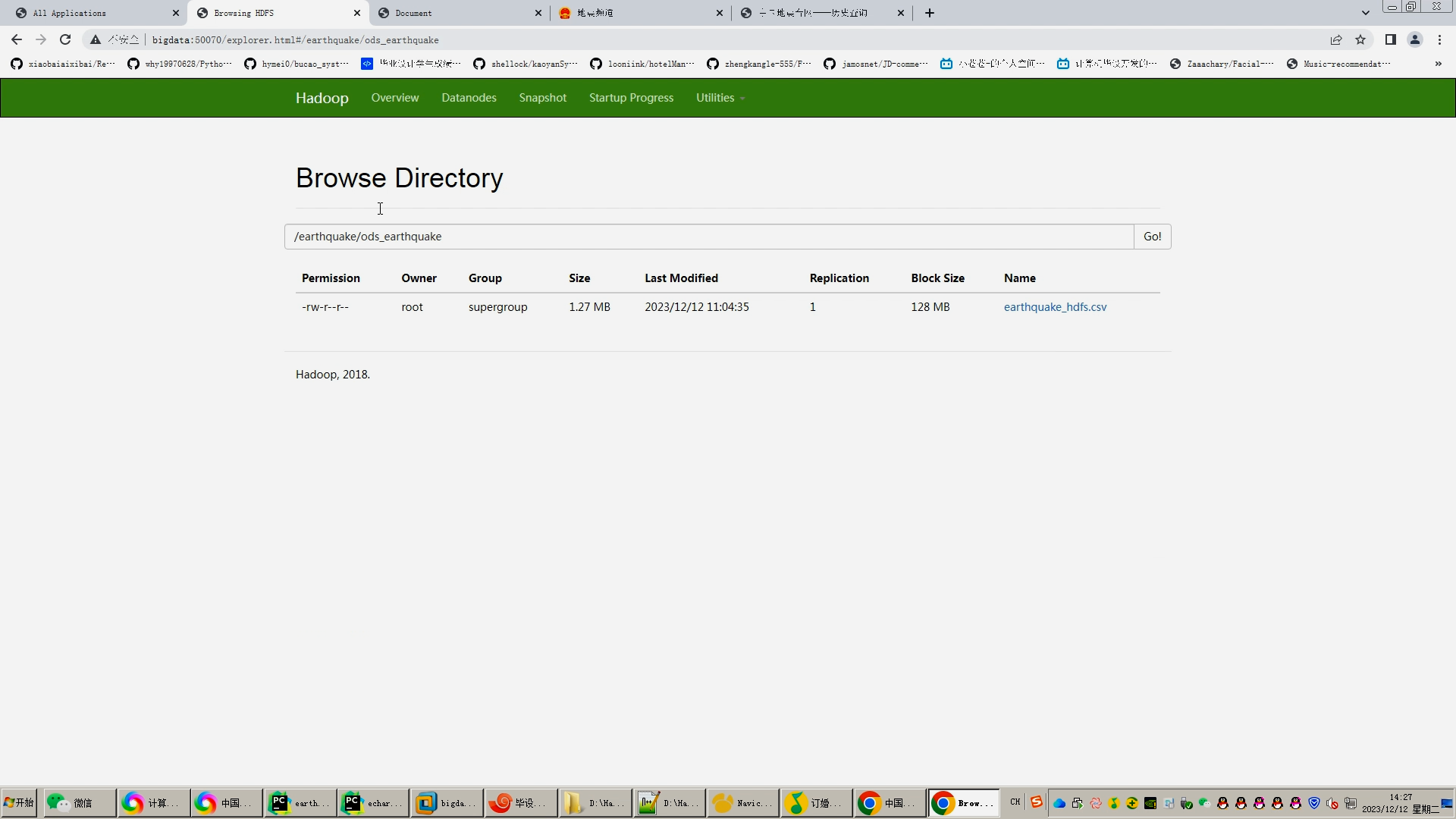

核心算法代码分享如下:
python
import sys
from db import cnn
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
def predict1():
sql = "select `stime_year`, `num` as value from table02" \
" order by stime_year asc "
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
def predict2():
sql = "select `stime_year`, `num` as value from table02" \
" order by stime_year asc "
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
def predict3():
sql = "select `stime_year`, `num` as value from table02" \
" order by stime_year asc "
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
def predict4():
sql = "select `stime_year`, `num` as value from table02" \
" order by stime_year asc "
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
if __name__ == '__main__':
#name = sys.argv[1]
ret = []
r1 = predict1()
r2 = predict2()
r3 = predict3()
r4 = predict4()
ret.append(r1)
ret.append(r2)
ret.append(r3)
ret.append(r4)
print(ret)
print(r1)
print(abs(int(r1[0])))
print(abs(int(r1[1])))
print(abs(int(r1[2])))
sql_day01="replace into table02(stime_year,num) values (%s,%s)"
data_day01 =('2024(预测)',abs(int(r1[0])))
sql_day02="replace into table02(stime_year,num) values (%s,%s)"
data_day02 = ('2025(预测)', abs(int(r1[1])))
sql_day03="replace into table02(stime_year,num) values (%s,%s)"
data_day03 = ('2026(预测)', abs(int(r1[2])))
cur=cnn.cursor()
cur.execute(sql_day01,data_day01)
cur.execute(sql_day02,data_day02)
cur.execute(sql_day03,data_day03)
cnn.commit()
cur.close()