文章目录
- [CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes](#CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes)
- 背景
- 1、什么是对抗攻击
-
- [1.1 主动防御与被动防御](#1.1 主动防御与被动防御)
- 2、整体思路
- 3、方法
-
- [3.1 整体流程](#3.1 整体流程)
- [3.2 如何破坏单个面部修改模型 G G G](#3.2 如何破坏单个面部修改模型 G G G)
- [3.3 对抗扰动融合](#3.3 对抗扰动融合)
- [3.4 基于TPE的自动步长调整](#3.4 基于TPE的自动步长调整)
- 4、攻击效果
-
- [4.1 对比现有方法](#4.1 对比现有方法)
- [4.2 ϵ \epsilon ϵ设置的影响](#4.2 ϵ \epsilon ϵ设置的影响)
CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes
论文地址:https://arxiv.org/abs/2105.10872
github地址:https://github.com/VDIGPKU/CMUA-Watermark
背景
对抗 StarGAN、AGGAN、AttGAN和 HiSD等一系列人脸变换网络。
- StarGAN 和 AGGAN 均在 CelebA 数据集上针对五个属性进行训练:黑发、金发、棕色头发、性别和年龄。
- AttGAN 在 CelebA 数据集上进行了多达 14 个属性的训练,与上述两个网络相比更加复杂。
- 面部修改网络 HiSD,该网络也是在 CelebA 数据集上进行训练的,并且可以为目标人添加一副眼镜。
1、什么是对抗攻击
一般来说,图片放入deepfake生成模型中,获得相应的视觉效果改变(换脸、属性编辑等)。
对抗攻击,训练一个对抗扰动加入图片中,在不影响原图的视觉效果的同时,图片+对抗扰动 放入deepfake生成模型中,破坏生成效果。
1.1 主动防御与被动防御
前面的deepfake检测论文讲解:https://blog.csdn.net/JustWantToLearn/article/details/138758033 是被动防御,图片被恶意更改后判断是否是AI合成的。
这一篇是主动防御,图片中加入扰动,防止被AI合成。如下图解释所示:
2、整体思路
以前论文的不足 :先前对抗性水印具有较低的图像级别和模型级别可转移性,只能保护一个特定deepfake模型的一张面部图像
本文 :生成跨模型通用对抗水印(CMUA-Watermark),保护大量面部图像免受多个深度伪造模型的攻击。
方法:提出了一个跨模型通用攻击管道,迭代地攻击多个deepfake模型。
- 首先引入了生成跨模型对抗水印(CMUAWatermark)的新思想,以保护人类面部图像免受多次深度伪造的影响,只需要128张训练面部图像就可以保护无数的面部图像。
- 提出了一种简单而有效的扰动融合策略来缓解冲突,并增强所提出的图像级和模型级可转移性CMUA-watermark。
- 分析跨模型优化过程,并开发了一种自动步长调优算法,以找到适合不同模型的攻击步长。
3、方法
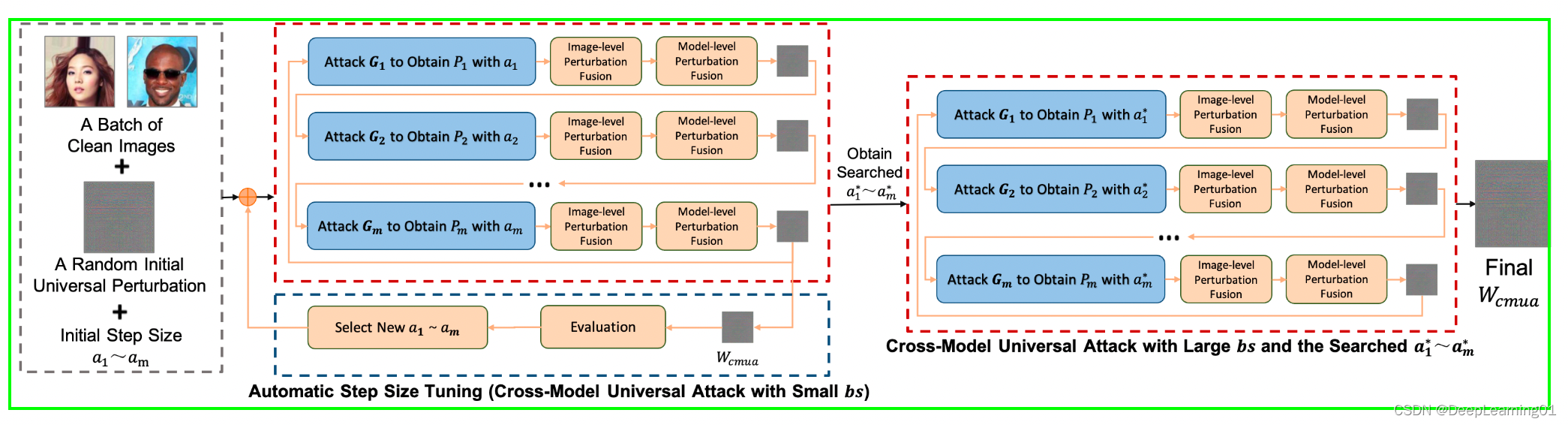
3.1 整体流程

给定不同的人脸图片 X 1 , . . . , X o X_1,...,X_o X1,...,Xo,不同的deepfake合成方法 G 1 , . . . , G m G_1,...,G_m G1,...,Gm,
- 输入图像批次迭代地通过PGD攻击产生对抗扰动,重复执行小批量(为了更快的搜索)的跨模型通用攻击,评估生成的CMUA - Watermark,然后使用自动调整步长来选择新的攻击步长 a 1 , . . . a m a_1,...a_m a1,...am
- 然后通过两级扰动融合机制组合成融合的CMUA - Watermark,作为下一个模型的初始扰动;使用发现的步长 a 1 , . . . a m a_1,...a_m a1,...am进行大批量(为了提高扰乱能力)的跨模型通用攻击,并生成最终的CMUA - Watermark。
3.2 如何破坏单个面部修改模型 G G G
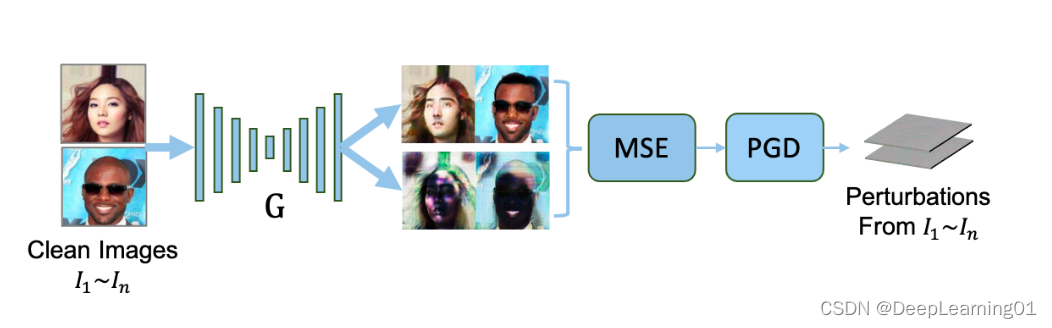
将一批干净图像 I 1 , . . . , I n I_1,...,I_n I1,...,In输入到 Deepfake 模型 G G G中,并获得原始输出 G ( I 1 ) . . . G ( I n ) G(I_1)...G(I_n) G(I1)...G(In)。然后,我们输入 I 1 , . . . , I n I_1,...,I_n I1,...,In以及初始对抗性扰动 W W W到 G G G,得到初始扭曲输出 G ( I 1 + W ) . . . G ( I n + W ) G(I_1 + W )...G(I_n + W ) G(I1+W)...G(In+W)。随后,我们利用均方误差 (MSE) 来测量 G ( I 1 ) . . . G ( I n ) G(I_1)...G(I_n) G(I1)...G(In)和 G ( I 1 + W ) . . . G ( I n + W ) G(I_1 + W )...G(I_n + W ) G(I1+W)...G(In+W)之间的差异
m a x W ∑ i = 1 n M S E ( G ( I i ) , G ( I i + W ) ) , s . t . ∥ W ∥ ∞ ≤ ϵ \underset{W}{max}\sum_{i=1}^{n}MSE(G(I_i),G(I_i+W)),s.t.\left \| W \right \|\infty \le \epsilon Wmaxi=1∑nMSE(G(Ii),G(Ii+W)),s.t.∥W∥∞≤ϵ
其中 ϵ \epsilon ϵ是对抗性水印 W W W的上限大小。最后,我们使用 PGD 作为基本攻击方法,在每次攻击迭代时更新对抗性扰动
I a d v 0 = I + W I_{adv}^{0} = I+W Iadv0=I+W
I a d v r + 1 = c l i p I , ϵ { I a d v r + a ⋅ s i g n ( ▽ I L ( G ( I a d v r ) , G ( I ) ) ) } I_{adv}^{r+1} = clip_{I,\epsilon }\left \{ I_{adv}^{r}+a\cdot sign(\bigtriangledown I L(G(I{adv}^{r}),G(I))) \right \} Iadvr+1=clipI,ϵ{Iadvr+a⋅sign(▽IL(G(Iadvr),G(I)))}
其中 I I I是干净的面部图像, I a d v r I_{adv}^{r} Iadvr是第 r 次迭代中的对抗性面部图像, a a a 是基本攻击的步长, L L L 是损失函数(MSE), G G G是我们攻击的人脸修改网络,操作剪辑将 I a d v I_{adv} Iadv限制在 I − ϵ , I + ϵ I − \\epsilon, I +\\epsilon I−ϵ,I+ϵ范围内。
通过这个过程,可以获得单图像对抗水印(SIA-Watermarks),保护一张面部图像免受特定深度伪造模型的影响。然而,精心制作的SIA-Watermarks在跨模型设置下是不够的;它们缺乏图像和模型级别的可移植性
论文中代码
代码位置:attacks.py
python
class LinfPGDAttack(object):
def __init__(self, model=None, device=None, epsilon=0.05, k=10, a=0.01, star_factor=0.3, attention_factor=0.3, att_factor=2, HiSD_factor=1, feat=None, args=None):
#epsilon: 攻击强度,即扰动的最大幅度。k: 攻击迭代次数。a: 每次迭代的步长。
"""
FGSM, I-FGSM and PGD attacks
epsilon: magnitude of attack
k: iterations
a: step size
"""
self.model = model
self.epsilon = epsilon
self.k = k
self.a = a
self.loss_fn = nn.MSELoss().to(device)
self.device = device
# Feature-level attack? Which layer?
self.feat = feat
# PGD or I-FGSM?
self.rand = True
# Universal perturbation
self.up = None
self.att_up = None
self.attention_up = None
self.star_up = None
self.momentum = args.momentum
#factors to control models' weights
self.star_factor = star_factor
self.attention_factor = attention_factor
self.att_factor = att_factor
self.HiSD_factor = HiSD_factor
def perturb(self, X_nat, y, c_trg):
"""
Vanilla Attack.
"""
if self.rand:
#如果 self.rand 为真,则在原始输入上添加一个在 [-epsilon, epsilon] 范围内的随机扰动。
X = X_nat.clone().detach_() + torch.tensor(np.random.uniform(-self.epsilon, self.epsilon, X_nat.shape).astype('float32')).to(self.device)
else:
X = X_nat.clone().detach_()
for i in range(self.k):
#每次迭代,将 X 标记为需要梯度
X.requires_grad = True
#通过模型计算输出 output 和特征 feats
output, feats = self.model(X, c_trg)
if self.feat:
output = feats[self.feat]
#将模型的梯度清零
self.model.zero_grad()
# Minus in the loss means "towards" and plus means "away from"
#计算损失,并对损失进行反向传播以获得梯度
loss = self.loss_fn(output, y)
loss.backward()
#根据梯度方向更新输入 X
grad = X.grad
X_adv = X + self.a * grad.sign()
#使用 epsilon 对扰动进行裁剪,并确保输入在 [-1, 1] 范围内
eta = torch.clamp(X_adv - X_nat, min=-self.epsilon, max=self.epsilon)
X = torch.clamp(X_nat + eta, min=-1, max=1).detach_()
self.model.zero_grad()
return X, X - X_nat3.3 对抗扰动融合
不同图像和模型生成的对抗水印之间的冲突会降低CMUA-Watermark的可移植性。
为了减弱这种冲突,提出了攻击过程中的两级扰动融合策略。
1、当我们攻击一个特定的深度伪造模型时,我们进行一个图像级别的融合来平均来自一组面部图像的符号梯度
G a v g = ∑ j b s s i g n ( ▽ I j L ( G ( I j a d v , G ( I j ) ) ) b s G_{avg} = \frac{ {\textstyle \sum_{j}^{bs}sign(\bigtriangledown {I_j}L(G(I{j}^{adv},G(I_j)))} }{bs} Gavg=bs∑jbssign(▽IjL(G(Ijadv,G(Ij)))
其中 b s bs bs 是面部图像的批次大小, I j a d v I_{j}^{adv} Ijadv是批次中的第 j 个对抗图像。此操作将使 G a v g G_{avg} Gavg更加关注人脸的共同属性,而不是特定人脸的属性。然后,我们使用 PGD 通过 G a v g G_{avg} Gavg生成对抗性扰动 P a v g P_avg Pavg,如式3.2所示。
2、从一个模型获得 P a v g P_{avg} Pavg后,我们进行模型级融合,将特定模型生成的 P a v g P_{avg} Pavg迭代地结合到训练中的 W C M U A W_{CMUA} WCMUA中,初始 W C M U A W_{CMUA} WCMUA就是根据第一个deepfake模型计算出的 P a v g P_{avg} Pavg
W C M U A 0 = P a v g 0 W_{CMUA}^{0} = P_{avg}^{0} WCMUA0=Pavg0
W C M U A t + 1 = α ⋅ W C M U A t + ( 1 − α ) ⋅ P a v g t W_{CMUA}^{t+1} = \alpha \cdot W_{CMUA}^{t}+(1-\alpha )\cdot P_{avg}^{t} WCMUAt+1=α⋅WCMUAt+(1−α)⋅Pavgt
其中 α \alpha α是衰减因子, P a v g t P_{avg}^{t} Pavgt是第t次攻击deepfake模型生成的平均扰动, W C M U A t W_{CMUA}^{t} WCMUAt是第t次攻击deepfake模型后的训练CMUA-Watermark。
3.4 基于TPE的自动步长调整
除了上面提到的两级融合之外,我们发现不同模型的攻击步长对于生成的 CMUA-Watermark 的可转移性也很重要。因此,我们利用启发式方法来自动找到合适的攻击步长。
根据公式3.2可知,整体优化方向受 a 1 , . . . a m a_1,...a_m a1,...am影响较大,跨模型选择合适的 a 1 , . . . a m a_1,...a_m a1,...am以找到理想的整体方向是跨模型攻击的关键问题。
这里引入TPE(Bergstra et al. 2011)算法来解决这个问题,自动搜索合适的 a 1 , . . . a m a_1,...a_m a1,...am来平衡多个模型计算出的不同方向。 TPE是一种基于序列模型优化(SMBO)的超参数优化方法,它根据历史测量值顺序构建模型来近似超参数的性能,然后基于该模型选择新的超参数进行测试。在我们的任务中,我们将步长 a 1 , . . . a m a_1,...a_m a1,...am视为输入超参数 x,将攻击的成功率视为 TPE 的相关质量得分 y。 TPE使用 P ( x ∣ y ) P(x|y) P(x∣y)和 P ( y ) P(y) P(y)来建模 P ( y ∣ x ) P(y|x) P(y∣x), P ( x ∣ y ) P(x|y) P(x∣y)由下式给出:
p ( x ∣ y ) = { l ( x ) i f y < y ∗ g ( x ) , i f y ≥ y ∗ p(x|y) = \left\{\begin{matrix} l(x) & if\quad y< y^*\\ g(x), & if\quad y \ge y^* \end{matrix}\right. p(x∣y)={l(x)g(x),ify<y∗ify≥y∗
其中 y ∗ y^* y∗由历史上最好的观测值确定, l ( x ) l(x) l(x)是由观测值 x ( i ) {x^{(i)}} x(i)形成的密度,使得相应的损失低于 y ∗ y^* y∗, g ( x ) g(x) g(x) 是由观测值形成的密度剩余的观察结果。对 P ( y ∣ x ) P (y|x) P(y∣x) 进行建模后,我们通过优化每次搜索迭代中的预期改进 (EI) 标准来不断寻找更好的步长。具体的细节,可以查看TPE的论文。
4、攻击效果
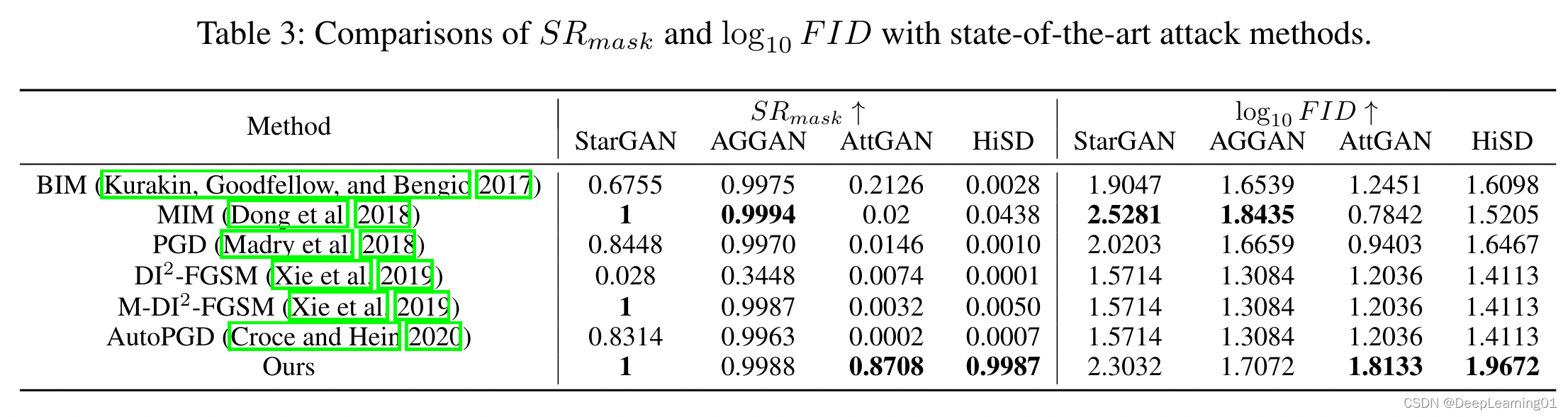
4.1 对比现有方法
我们的方法在所有模型上都取得了优异的性能。
所提出的方法比现有方法具有更好的图像级和模型级可移植性。
4.2 ϵ \epsilon ϵ设置的影响

当参数 ϵ \epsilon ϵ变大时,生成的假人脸图像更加扭曲,意味着防护性能变得更好。然而,当变得太大时,产生的对抗性水印更有可能被看到。我们根据经验发现,设置在 0.05 左右可以在保护性能和生成的对抗性水印的不可察觉性之间取得良好的权衡。