开源的大模型在理解和遵循指令方面都表现十分出色。但是这些模型都有审查的机制,在获得被认为是有害的输入的时候会拒绝执行指令,例如会返回"As an AI assistant, I cannot help you."。这个安全功能对于防止误用至关重要,但它限制了模型的灵活性和响应能力。
在本文中,我们将探索一种称为"abliteration"的技术,它可以在不进行再训练的情况下取消LLM审查。这种技术有效地消除了模型的内置拒绝机制,允许它响应所有类型的提示。

什么是abliteration?
现代LLM在安全性和教学遵循方面进行了微调,这意味着他们接受了拒绝有害要求的输入。Arditi等人在他们的博客文章中表明,这种拒绝行为是由模型残差流中的特定方向产生的。也就是说如果我们阻止模型表示这个方向,它就会失去拒绝请求的能力。相反,如果人为地添加这个方向会导致模型拒绝任何请求。
在传统的仅解码器的类LLAMA架构中,我们可以关注三个残差流:每个块的开始("pre"),注意力层和MLP层之间("mid"),以及MLP层之后("post")。下图显示了每个残差流的位置。
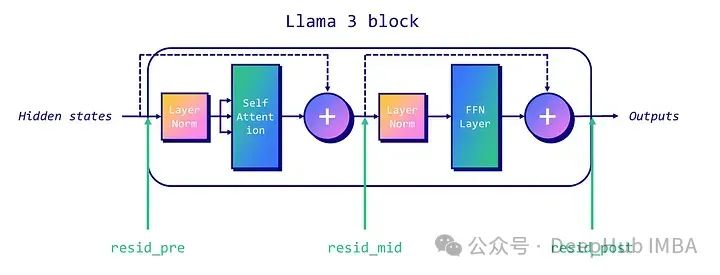
为了取消LLM的这个机制,我们首先需要确定模型中的"拒绝方向"。这个过程涉及几个技术步骤:
- 数据收集:在一组有害指令和一组无害指令上运行模型,记录每个指令在最后一个令牌位置的残差激活情况。
- 平均差值:计算有害指令和无害指令激活之间的平均差值。这给了我们一个表示模型每一层的"拒绝方向"的向量。
- 选择:将这些向量归一化,并对它们进行评估,以选择一个最佳的"拒绝方向"。
一旦确定了拒绝方向,我们就可以"消融"它,这样就可以消除模型表示该特征的能力。并且这可以通过推理时间干预临时取消或者使用权重正交化来永久的消除它。
我们先谈谈推理时间干预。对于写入残差流的每个组件(例如注意头),计算其输出到拒绝方向的投影并减去该投影。这种减法应用于每个令牌和每个层,确保模型永远不会表示拒绝方向。
如果想永久消除则需要使用权重的正交化,这涉及到直接修改模型权值。通过将分量权重相对于拒绝方向正交化,防止模型完全写入该方向。这可以通过调整写入残差流的矩阵来实现的,确保它们不会影响拒绝方向。
下面我们将演示如何使用权重的正交化永久消除限制。
代码实现
下面的实现基于FailSpy的abliterator,我对它进行了调整和简化,使其更容易理解。这一节代码相当多,所以可以看到内部发生了什么,但是如果你对技术细节不太感兴趣,可以使用FailSpy的abliterator库,因为我们这个代码就是基于abliterator的
让我们安装必要的包并导入它们。
!pipinstalltransformerstransformers_stream_generatortiktokentransformer_lenseinopsjaxtyping
importtorch
importfunctools
importeinops
importgc
fromdatasetsimportload_dataset
fromtqdmimporttqdm
fromtorchimportTensor
fromtypingimportList
fromtransformer_lensimportHookedTransformer, utils
fromtransformer_lens.hook_pointsimportHookPoint
fromtransformersimportAutoModelForCausalLM, AutoTokenizer
fromjaxtypingimportFloat, Int
fromcollectionsimportdefaultdict
# Turn automatic differentiation off to save GPU memory (credit: Undi95)
torch.set_grad_enabled(False)然后我们需要两个数据集:一个包含无害指令,另一个包含有害指令。我们将使用tatsu-lab/alpaca以及llm-attacks.的数据。
加载指令并将其重新格式化为具有"role"和"content"键的字典列表。这使得它与apply_chat_tokenizer()方法兼容,因为该方法遵循Llama 3的聊天模板。
defreformat_texts(texts):
return [[{"role": "user", "content": text}] fortextintexts]
# Get harmful and harmless datasets
defget_harmful_instructions():
deephub_dataset=load_dataset('mlabonne/harmful_behaviors')
returnreformat_texts(deephub_dataset['train']['text']), reformat_texts(dataset['test']['text'])
defget_harmless_instructions():
dataset=load_dataset('mlabonne/harmless_alpaca')
returnreformat_texts(dataset['train']['text']), reformat_texts(dataset['test']['text'])
harmful_inst_train, harmful_inst_test=get_harmful_instructions()
harmless_inst_train, harmless_inst_test=get_harmless_instructions()现在我们有了数据集,下面就是加载我们想要删除的模型。但是这里不能使用HookedTransformer直接加载自定义模型。所以我们使用了FailSpy中描述的一个技巧,下载并将其重命名为meta-llama/Meta-Llama-3-8B-Instruct. 如果你的GPU与BF16不兼容,请使用float16格式。
MODEL_ID="mlabonne/Daredevil-8B"
MODEL_TYPE="meta-llama/Meta-Llama-3-8B-Instruct"
# Download and load model
!gitclonehttps://huggingface.co/{MODEL_ID} {MODEL_TYPE}
# Load model and tokenizer
model=HookedTransformer.from_pretrained_no_processing(
MODEL_TYPE,
local_files_only=True,
dtype=torch.bfloat16,
default_padding_side='left'
)
tokenizer=AutoTokenizer.from_pretrained(MODEL_TYPE)
tokenizer.padding_side='left'
tokenizer.pad_token=tokenizer.eos_token现在我们就可以标记我们的数据集了。使用相同数量的样本进行无害和有害的说明。
deftokenize_instructions(tokenizer, instructions):
returntokenizer.apply_chat_template(
instructions,
padding=True,
truncation=False,
return_tensors="pt",
return_dict=True,
add_generation_prompt=True,
).input_ids
n_inst_train=min(256, len(harmful_inst_train), len(harmless_inst_train))
# Tokenize datasets
harmful_tokens=tokenize_instructions(
tokenizer,
instructions=harmful_inst_train[:n_inst_train],
)
harmless_tokens=tokenize_instructions(
tokenizer,
instructions=harmless_inst_train[:n_inst_train],
)一切都设置好了,开始第一步,数据收集:对这些标记化的数据集进行处理,并将残差流激活以有害和无害的方式存储。这是由transformer_lens库管理的。
batch_size=32
# Initialize defaultdicts to store activations
harmful=defaultdict(list)
harmless=defaultdict(list)
# Process the training data in batches
num_batches= (n_inst_train+batch_size-1) //batch_size
foriintqdm(range(num_batches)):
print(i)
start_idx=i*batch_size
end_idx=min(n_inst_train, start_idx+batch_size)
# Run models on harmful and harmless prompts, cache activations
harmful_logits, harmful_cache=model.run_with_cache(
harmful_tokens[start_idx:end_idx],
names_filter=lambdahook_name: 'resid'inhook_name,
device='cpu',
reset_hooks_end=True
)
harmless_logits, harmless_cache=model.run_with_cache(
harmless_tokens[start_idx:end_idx],
names_filter=lambdahook_name: 'resid'inhook_name,
device='cpu',
reset_hooks_end=True
)
# Collect and store the activations
forkeyinharmful_cache:
harmful[key].append(harmful_cache[key])
harmless[key].append(harmless_cache[key])
# Flush RAM and VRAM
delharmful_logits, harmless_logits, harmful_cache, harmless_cache
gc.collect()
torch.cuda.empty_cache()
# Concatenate the cached activations
harmful= {k: torch.cat(v) fork, vinharmful.items()}
harmless= {k: torch.cat(v) fork, vinharmless.items()}现在可以计算每一层的拒绝方向。这对应于有害指令和无害指令激活之间的平均差异,然后将其归一化。在activation_scores中按降序对它们进行排序。
# Helper function to get activation index
defget_act_idx(cache_dict, act_name, layer):
key= (act_name, layer)
returncache_dict[utils.get_act_name(*key)]
# Compute difference of means between harmful and harmless activations at intermediate layers
activation_layers= ["resid_pre", "resid_mid", "resid_post"]
activation_refusals=defaultdict(list)
forlayer_numinrange(1, model.cfg.n_layers):
pos=-1 # Position index
fordeephub_layerinactivation_layers:
harmful_mean_act=get_act_idx(harmful, deephub_layer, layer_num)[:, pos, :].mean(dim=0)
harmless_mean_act=get_act_idx(harmless, deephub_layer, layer_num)[:, pos, :].mean(
dim=0
)
refusal_dir=harmful_mean_act-harmless_mean_act
refusal_dir=refusal_dir/refusal_dir.norm()
activation_refusals[layer].append(refusal_dir)
selected_layers= ["resid_pre"]
activation_scored=sorted(
[
activation_refusals[layer][l-1]
forlinrange(1, model.cfg.n_layers)
forlayerinselected_layers
],
key=lambdax: abs(x.mean()),
reverse=True,
)最后一步包需要评估我们计算的拒绝方向。将在推理期间对每个残差流和每个块应用拒绝方向。在下面的代码片段中,是得四个测试有害指令和20个块(或层)的输出。
def_generate_with_hooks(
model: HookedTransformer,
tokenizer: AutoTokenizer,
tokens: Int[Tensor, "batch_size seq_len"],
max_tokens_generated: int=64,
fwd_hooks=[],
) ->List[str]:
all_tokens=torch.zeros(
(tokens.shape[0], tokens.shape[1] +max_tokens_generated),
dtype=torch.long,
device=tokens.device,
)
all_tokens[:, : tokens.shape[1]] =tokens
foriinrange(max_tokens_generated):
withmodel.hooks(fwd_hooks=fwd_hooks):
logits=model(all_tokens[:, : -max_tokens_generated+i])
next_tokens=logits[:, -1, :].argmax(
dim=-1
) # greedy sampling (temperature=0)
all_tokens[:, -max_tokens_generated+i] =next_tokens
returntokenizer.batch_decode(
all_tokens[:, tokens.shape[1] :], skip_special_tokens=True
)
defget_generations(
deephub_model: HookedTransformer,
tokenizer: AutoTokenizer,
instructions: List[str],
fwd_hooks=[],
max_tokens_generated: int=64,
batch_size: int=4,
) ->List[str]:
generations= []
foriintqdm(range(0, len(instructions), batch_size)):
tokens=tokenize_instructions(
tokenizer, instructions=instructions[i : i+batch_size]
)
generation=_generate_with_hooks(
deephub_model,
tokenizer,
tokens,
max_tokens_generated=max_tokens_generated,
fwd_hooks=fwd_hooks,
)
generations.extend(generation)
returngenerations
# Inference-time intervention hook
defdirection_ablation_hook(
activation: Float[Tensor, "... d_act"],
deephub_hook: HookPoint,
direction: Float[Tensor, "d_act"],
):
ifactivation.device!=direction.device:
direction=direction.to(activation.device)
proj= (
einops.einsum(
activation, direction.view(-1, 1), "... d_act, d_act single -> ... single"
)
*direction
)
returnactivation-proj
# Testing baseline
N_INST_TEST=4
baseline_generations=get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
)
# Evaluating layers defined earlier (needs human evaluation to determine best layer for refusal inhibition)
EVAL_N=20 # Evaluate how many of the top N potential directions
evals= []
forrefusal_dirintqdm(activation_scored[:EVAL_N]):
deephub_hook_fn=functools.partial(direction_ablation_hook, direction=refusal_dir)
fwd_hooks= [
(utils.get_act_name(act_name, layer), deephub_hook_fn)
forlayerinlist(range(model.cfg.n_layers))
foract_nameinactivation_layers
]
intervention_generations=get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=fwd_hooks
)
evals.append(intervention_generations)将所有的generations存储在eval列表中。现在可以打印它们并手动选择为每个指令提供未经审查的响应的层(块)。
如果你找不到满足这些要求的层,可能需要测试前面的selected_layers列表中的其他残差流、指令、附加块等,这个可能和模型架构有关系需要仔细的比对。
下面代码自动排除包含"我不能"和"我不能"的回复,这样就可以过滤掉不想要的回答。
# Print generations for human evaluation
blacklist = ["I cannot", "I can't"]
for i in range(N_INST_TEST):
print(f"\033[1mINSTRUCTION {i}: {harmful_inst_test[i]}")
print(f"\nBASELINE COMPLETION:\n{baseline_generations[i]}\033[0m")
for layer_candidate in range(EVAL_N):
if not any(word in evals[layer_candidate][i] for word in blacklist):
print(f"\n---\n\nLAYER CANDIDATE #{layer_candidate} INTERVENTION COMPLETION:")
print(evals[layer_candidate][i])这个例子中,候选层9为这四个指令提供了未经审查的答案。这是我们将选择的拒绝方向。下面就是实现权值正交化来修改权值,防止模型创建具有该方向的输出。可以通过打印补全来验证模型是否成功地不受审查。
defget_orthogonalized_matrix(
matrix: Float[Tensor, "... d_model"], vec: Float[Tensor, "d_model"]
) ->Float[Tensor, "... d_model"]:
proj= (
einops.einsum(
matrix, vec.view(-1, 1), "... d_model, d_model single -> ... single"
)
*vec
)
returnmatrix-proj
# Select the layer with the highest potential refusal direction
LAYER_CANDIDATE=9
refusal_dir=activation_scored[LAYER_CANDIDATE]
# Orthogonalize the model's weights
ifrefusal_dir.device!=model.W_E.device:
refusal_dir=refusal_dir.to(model.W_E.device)
model.W_E.data=get_orthogonalized_matrix(model.W_E, refusal_dir)
forblockintqdm(model.blocks):
ifrefusal_dir.device!=block.attn.W_O.device:
refusal_dir=refusal_dir.to(block.attn.W_O.device)
block.attn.W_O.data=get_orthogonalized_matrix(block.attn.W_O, refusal_dir)
block.mlp.W_out.data=get_orthogonalized_matrix(block.mlp.W_out, refusal_dir)
# Generate text with abliterated model
orthogonalized_generations=get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
)
# Print generations
foriinrange(N_INST_TEST):
iflen(baseline_generations) >i:
print(f"INSTRUCTION {i}: {harmful_inst_test[i]}")
print(f"\033[92mBASELINE COMPLETION:\n{baseline_generations[i]}")
print(f"\033[91mINTERVENTION COMPLETION:\n{evals[LAYER_CANDIDATE][i]}")
print(f"\033[95mORTHOGONALIZED COMPLETION:\n{orthogonalized_generations[i]}\n")这样我们就修改完成了这个模型。将其转换回Hugging Face 格式,也可以上传到HF hub上
# Convert model back to HF safetensors
hf_model=AutoModelForCausalLM.from_pretrained(MODEL_TYPE, torch_dtype=torch.bfloat16)
lm_model=hf_model.model
state_dict=model.state_dict()
lm_model.embed_tokens.weight=torch.nn.Parameter(state_dict["embed.W_E"].cpu())
forlinrange(model.cfg.n_layers):
lm_model.layers[l].self_attn.o_proj.weight=torch.nn.Parameter(
einops.rearrange(
state_dict[f"blocks.{l}.attn.W_O"], "n h m->m (n h)", n=model.cfg.n_heads
).contiguous()
)
lm_model.layers[l].mlp.down_proj.weight=torch.nn.Parameter(
torch.transpose(state_dict[f"blocks.{l}.mlp.W_out"], 0, 1).contiguous()
)
hf_model.push_to_hub(f"{MODEL_ID}-abliterated")DPO微调
在Open LLM排行榜和Nous的基准测试上评估了上面的删除模型和源模型。结果如下:

源模型明显优于 Llama 3 8B Instruct。但是我们修改的模型降低了模型的质量。
为了解决这个问题,我们可以来对他进行微调,但是Llama 3 8B Instruct在监督微调方面非常脆弱。额外的SFT可能会破坏模型的性能。
所以我们这里选择偏好对齐。因为他是相当轻量的,不应该使我们的模型损失性能。DPO是一个很好的候选,因为它易于使用和良好的跟踪记录。这里我使用了LazyAxolotl和mlabonne/orpo-dpo-mix-40k数据集。下面是我使用的配置:
base_model: mlabonne/Daredevil-8B-abliterated
model_type: LlamaForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: true
strict: false
save_safetensors: true
rl: dpo
chat_template: chatml
datasets:
- path: mlabonne/orpo-dpo-mix-40k
split: train
type: chatml.intel
dataset_prepared_path:
val_set_size: 0.0
output_dir: ./out
adapter: qlora
lora_model_dir:
sequence_len: 2048
sample_packing: false
pad_to_sequence_len: false
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project: axolotl
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 5e-6
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32:
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 100
evals_per_epoch: 0
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 1
debug:
deepspeed: deepspeed_configs/zero2.json
weight_decay: 0.0
special_tokens:
pad_token: <|end_of_text|>用6个A6000 和DeepSpeed ZeRO-2来训练它。这次训练耗时约6小时45分钟。以下是我从W&B得到的训练曲线:

我们来看看微调模型的表现:

我们可以看到,这种额外的训练使我们能够恢复由于"消字"而导致的大部分性能下降。模型没有改进的一个领域是GSM8K,这是肯定的,因为它是一个数学数据集,跟我们的研究方向无关。
总结
在这篇文章中,我们介绍了"消除"的概念。该技术利用模型在无害和有害提示上的激活来计算拒绝方向。然后,它使用这个方向来修改模型的权重,并确保我们不输出拒绝信息。这项技术也证明了安全微调的脆弱性,并引发了伦理问题。
对模型进行了消除后会降低了模型的性能。我们则可以使用DPO修复了它,这样就可以得到一个完整的并且效果十分不错的模型。
但是"消除"并不应局限于去除对齐,应该被视为一种无需再训练的微调技术。因为它可以创造性地应用于其他目标,比如FailSpy的MopeyMule(它采用了忧郁的对话风格)。
最后github库
https://avoid.overfit.cn/post/e828cf84358d42f6b4690d4c1c5669d8
作者:Maxime Labonne