概述
论文地址:https://arxiv.org/pdf/2402.19443.pdf
使用深度学习的语音识别技术已取得重大进展。这使得语音识别系统更加准确。然而,这项技术非常复杂,很难理解哪些信息用于何处。因此,本文提出了一种识别语音识别系统中哪些信息是重要信息的方法。具体来说,它提出了一种利用语音识别系统中间阶段的信息来评估系统性能的方法。
通过一系列实验表明,语音识别系统不仅能学习语音特征,还能学习其他信息,如说话者的特征和情绪。实验还发现,语音识别不需要的信息往往会在高级阶段被剔除。换句话说,使用深度学习的语音识别系统不仅能学习语音,还能学习其他信息。这使得语音识别更加准确,但其机制非常复杂,这意味着很难理解哪些信息被使用以及如何使用。
介绍
最近,随着深度学习与大量语音数据的结合,语音识别技术取得了重大进展,特别是在声学和语言学两个层面整合了深度学习方法。从经典语音识别系统到深度神经网络(DNN),语音识别的性能有了显著提高。然而,人们仍然难以理解 DNNs 是如何学习的。以前的研究重点是语音特征和音素,而最新的研究则试图深入了解语音识别系统是如何处理信息的。特别是,关注语音识别系统中的声学模型,研究哪些信息在哪一层被处理,将有助于开发出更好的语音识别技术。
算法框架
声学模型结构
声学模型是自动语音识别(ASR)系统的核心要素,经过训练可识别给定语音信号中的基本语音单元(通常是音素)。语音信号的处理非常复杂,因为它们携带了大量信息,如语言、噪音和说话者。因此,通过从传统方法转向使用 DNN(深度神经网络)的新架构,声学模型的准确性得到了提高。其中,TDNN-F(因果化 TDNN)架构就是这种演变的一个例子。该模型旨在处理信号中的复杂信息,在语音识别任务中表现出色。
建议的协议
这项研究使用多种分类任务来揭示声学模型中存在哪些特定信息的隐藏层,以及它们如何随神经网络的级别而变化。这样,我们就能了解声学模型的每一层提取了哪些信息,对哪些任务有用。我们希望这将为改进语音识别系统提供重要启示。下图显示了声学模型信息探测的拟议协议。

研究任务
说话人验证评估从语音中识别说话人的能力。语音速度分析则考察语音应对速度变化的能力。扬声器性别识别任务则评估声学模型对扬声器性别估计的准确度。此外,声学环境任务还能估计语音录制的环境。最后,语音情感/情绪识别任务评估从语音中估计情绪和情感的能力。这些任务为了解声学模型的性能及其信息的有用性提供了宝贵的见解。
试验
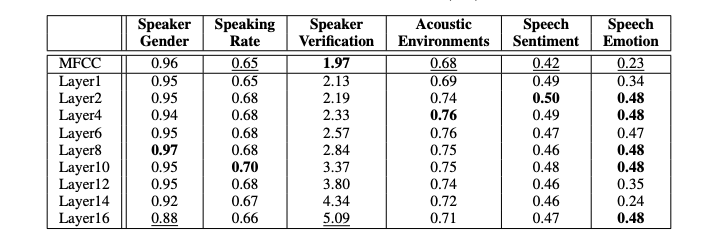
上表显示了不同探测任务(旨在获取特定信息的实验或任务)的性能。对于说话人验证,性能用等效错误率 (EER) 表示,对于其他任务,性能用准确率表示。表中比较了 TDNN-F 层和 MFCC(声学特征)基线的性能。结果表明,隐藏层的向量表示通常比传统的 MFCC 提供更好的分类结果。不过,MFCC 在扬声器验证任务中更胜一筹。这表明,与其他任务相比,与音素识别相关的说话人 ID 信息往往会被抑制。在自我监督学习模型中也观察到了这种趋势,这表明与说话人身份相关的信息对音素识别并无用处,需要加以抑制。这表明,声学模型的隐藏层包含对不同任务有用的结构化信息。
此外,研究还表明,信息的编码和抑制方式取决于网络的深度。隐藏层越低,对周围噪音的捕捉效果越好,在声学环境任务中表现最佳。另一方面,在扬声器性别和语速等任务中,中层隐藏层的性能最佳。这些结果对于理解声学模型在不同任务中如何处理信息非常重要。
结论
本文提出了一项协议,用于研究语音识别系统中使用的声学模型所包含的信息。研究人员使用不同的语音导向任务来详细研究基于神经的声学模型。研究分析了 TDNN-F 声学模型在不同隐藏层的表现,以了解声学模型不同层次所包含的信息,如说话者、声学环境和语音。例如,它显示了与性别、语速、说话者身份、情感和情绪有关的信息被编码。研究结果突出表明,在声学模型中,信息是以不同方式编码的。在较低的层级,信息被结构化,性能不断提高,但最终信息趋于被抑制。
未来的研究将尝试通过增加新的任务(如口音和年龄)来了解声学模型能编码哪些信息,从而获得更多信息。他们还希望重点研究其他声学信号的表示,如 wav2vec。