这一篇主要是关于生成对抗网络的模型笔记,有一些简单的证明和原理,是根据李宏毅老师的课程整理的,下面有链接。本篇文章主要就是梳理基础的概念和训练过程,如果有什么问题的话也可以指出的。
1.概述
GAN是Generative Adversarial Networks的缩写,也就是生成对抗网络,最核心在于训练两个网络分别是generator和discriminator,generator主要是输入一个向量,输出要生成的目标,discriminator接受一个输出的目标,然后输出为真的概率(来说就是打分)。
假设任务是生成一组图片,现在输入是一组图片数据集,一开始随便生成乱七八糟的数据,训练共有两个核心的步骤:
- 更新discriminator,将真实数据标记为1,生成的数据标记为0,然后进行训练,那么discrimator就可以辨别生成图片。
- 更新generator,更新生成网络的参数,让生成网络生成的图片能让discriminator输出尽可能大(打分尽可能高,也就是骗过discriminator)。
- 回到1,重复这个过程。
下面是最原始的论文提出的伪代码:

可以看到第一个阶段是在更新discriminator,D(x)表示对输入图像x的判别,损失函数是两项累加,前面的 x i x^i xi表示真实输入,这些应该输出1,后面的 x ~ i \widetilde{x}^i x i表示生成数据,这些应该给低分(接近0),两项的目标都是越大越好,所以 V ~ \widetilde{V} V 越大越好,因此 θ d \theta_d θd是梯度上升优化。
第二阶段在更新generator, G ( z i ) G(z^i) G(zi)就是对一个向量生成一个目标,然后进行打分,也是越大越好,因此梯度上升优化,这一部分的目标就是让生成的图片尽量得高分。
循环多次迭代就可以得到预期网络。
当然目前我还有一些疑问:
-
generator输出的图片是如何保证风格和数据集类似的?
应该是必须要像原风格一样的才能得到高分。
-
输入的向量是随机的,如何可控输入向量和输出特征的关系?如何解释每个输入的数字?(比如我想生成蓝色的头发,那么这个是可控的吗)
这个可能要看了一些具体的代码才能理解。
2.原理简单分析
生成一个图片或者一个语音本质是映射到一个高维点的问题,比如32×32的黑白图片就是 2 32 × 32 2^{32\times 32} 232×32空间中的一个点。下面都以图片生成任务为例,假设真实分布是 P d a t a P_{data} Pdata,生成的分布是 P G P_{G} PG,只有生成的点(图片)到了真实的分布中,才有极大可能是看上去真实的,因此目标就是让生成的分布 P G P_G PG尽可能接近真实的分布 P d a t a P_{data} Pdata ,方法就是KL散度或者JS散度,因此一个理想的生成器应该是这样的:
G ∗ = a r g min G D i v ( P G , P d a t a ) G^*=arg\min_G Div(P_G,P_{data}) G∗=argGminDiv(PG,Pdata)其中Div衡量两个分布的差异,而 G ∗ G^* G∗就是所有生成器 G G G中有着最小差异的那个,也就是最优的。
然而,实际情况中,真实的分布和实际的分布都是未知的,一些传统的算法可能假设高斯分布,但是很多时候可能不正确。
虽然不能直接得到分布,但是可以进行采样(Sample),在GAN中,discriminator就扮演了计算两个分布差异的角色,给出下式:
V ( G , D ) = E x ∼ P d a t a l o g ( D ( x ) ) + E x ∼ P G l o g ( 1 − D ( x ) ) V(G,D)=E_{x\sim P_{data}}log(D(x))+E_{x\sim P_{G}}log(1-D(x)) V(G,D)=Ex∼Pdatalog(D(x))+Ex∼PGlog(1−D(x))其中 D ( x ) D(x) D(x)表示一个discriminator对一个generator生成的结果进行打分,介于 0 , 1 0,1 0,1,下面证明这个式子本质上也是JS散度或者KL散度:
证明 :
max E x ∼ P d a t a l o g ( D ( x ) ) + E x ∼ P G l o g ( 1 − D ( x ) ) = max ∫ x p d a t a ( x ) l o g ( D ( x ) ) + ∫ x p G ( x ) l o g ( 1 − D ( x ) ) = max ∫ x p d a t a ( x ) l o g ( D ( x ) ) + p G ( x ) l o g ( 1 − D ( x ) ) \max E_{x\sim P_{data}}log(D(x))+E_{x\sim P_{G}}log(1-D(x))\\ =\max \int_xp_{data}(x)log(D(x))+\int_xp_{G}(x)log(1-D(x))\\ =\max \int_xp_{data}(x)log(D(x))+p_{G}(x)log(1-D(x)) maxEx∼Pdatalog(D(x))+Ex∼PGlog(1−D(x))=max∫xpdata(x)log(D(x))+∫xpG(x)log(1−D(x))=max∫xpdata(x)log(D(x))+pG(x)log(1−D(x))
这里假设D(x)可以拟合任何函数,那么对于任意一个x取值 x ∗ x^* x∗, D ( x ∗ ) D(x^*) D(x∗)都可以对应任何数值,这就意味着可以对每个x都计算最大值,然后求和得到最大值。
设 a = p d a t a ( x ) , b = p G ( x ) , D ( x ) = t a=p_{data}(x),b=p_G(x),D(x)=t a=pdata(x),b=pG(x),D(x)=t,那么可以得到下式:
f ( t ) = a l o g ( t ) + b l o g ( 1 − t ) f(t)=alog(t)+blog(1-t) f(t)=alog(t)+blog(1−t)求导计算最小值对应的t:(直接假设e为底了)
f ′ ( t ) = a x − b 1 − x f'(t)=\frac{a}{x}-\frac{b}{1-x} f′(t)=xa−1−xb
令 f ′ ( t ) = 0 f'(t)=0 f′(t)=0,得到 t = a a + b t=\frac{a}{a+b} t=a+ba,代入 a , b , t a,b,t a,b,t,假设这个值为最优值 D ∗ ( x ) D^*(x) D∗(x):
D ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p G ( x ) D^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_G(x)} D∗(x)=pdata(x)+pG(x)pdata(x)此时每个x都有对应的 D ∗ ( x ) D^*(x) D∗(x),代入得到:
max ∫ x p d a t a ( x ) l o g ( D ( x ) ) + p G ( x ) l o g ( 1 − D ( x ) ) = ∫ x p d a t a ( x ) l o g ( D ∗ ( x ) ) + p G ( x ) l o g ( 1 − D ∗ ( x ) ) = ∫ x p d a t a ( x ) l o g ( p d a t a ( x ) p d a t a ( x ) + p G ( x ) ) + p G ( x ) l o g ( p G ( x ) p d a t a ( x ) + p G ( x ) ) = − 2 l o g 2 + ∫ x p d a t a ( x ) l o g ( p d a t a ( x ) ( p d a t a ( x ) + p G ( x ) ) / 2 ) + p G ( x ) l o g ( p G ( x ) ( p d a t a ( x ) + p G ( x ) ) / 2 ) = − 2 l o g 2 + K L ( P d a t a ∣ ∣ P d a t a + P G 2 ) + K L ( P G ∣ ∣ P d a t a + P G 2 ) = − 2 l o g 2 + J S D ( P d a t a ∣ ∣ P G ) \max\int_xp_{data}(x)log(D(x))+p_{G}(x)log(1-D(x))\\ =\int_xp_{data}(x)log(D^*(x))+p_{G}(x)log(1-D^*(x))\\ =\int_xp_{data}(x)log(\frac{p_{data}(x)}{p_{data}(x)+p_G(x)})+p_{G}(x)log(\frac{p_{G}(x)}{p_{data}(x)+p_G(x)})\\ =-2log2+\int_xp_{data}(x)log(\frac{p_{data}(x)}{(p_{data}(x)+p_G(x))/2})+p_{G}(x)log(\frac{p_{G}(x)}{(p_{data}(x)+p_G(x))/2})\\ =-2log2+KL(P_{data}||\frac{P_{data}+P_G}{2})+KL(P_{G}||\frac{P_{data}+P_G}{2})\\ =-2log2+JSD(P_{data}||P_G) max∫xpdata(x)log(D(x))+pG(x)log(1−D(x))=∫xpdata(x)log(D∗(x))+pG(x)log(1−D∗(x))=∫xpdata(x)log(pdata(x)+pG(x)pdata(x))+pG(x)log(pdata(x)+pG(x)pG(x))=−2log2+∫xpdata(x)log((pdata(x)+pG(x))/2pdata(x))+pG(x)log((pdata(x)+pG(x))/2pG(x))=−2log2+KL(Pdata∣∣2Pdata+PG)+KL(PG∣∣2Pdata+PG)=−2log2+JSD(Pdata∣∣PG)
后面的几步其实不是很理解,不过到第三步,跟交叉熵形式很像,所以都是类似的衡量两个分布的差异。
训练一个discriminator,实际上就是为了更好区分真实和生成的样本,那么自然要让这个差异越大越好,此时这个discriminator可以最大程度区分生成和真实。D ∗ D^* D∗给的打分实际上可以看做生成分布和实际分布的差异 。
D ∗ = a r g max D V ( G , D ) D^*=arg\max_D V(G,D) D∗=argDmaxV(G,D)而训练generator的过程就是为了让discriminator不容易区分真实和生成样本,因此要减少这个差异:
D ∗ = a r g min G V ( G , D ∗ ) = a r g min G max D V ( G , D ) D^*=arg\min_G V(G,D^*) =arg\min_G \max_D V(G,D) D∗=argGminV(G,D∗)=argGminDmaxV(G,D)
也就是现在有一个最优的discriminator D ∗ D^* D∗,要优化generator使得 D ∗ D^* D∗打分尽量高,也就是:
θ g = θ g − η ∂ V ( G , D ∗ ) θ g \theta_g=\theta_g-\eta \frac{\partial V(G,D^*)}{\theta_g} θg=θg−ηθg∂V(G,D∗)这里实际上是对 θ G \theta_G θG也就是生成网络的参数求导,实际的网络架构是: v e c t o r → θ G → o u t → θ D → s c o r e vector\rightarrow \theta_G \rightarrow out \rightarrow \theta_D \rightarrow score vector→θG→out→θD→score,这里更新的时候,不更新 θ D \theta_D θD,这也就是固定discriminator的思想。
注意点 :每次更新的时候,对discriminator的更新要彻底,对generator的更新次数不能多,如下图:
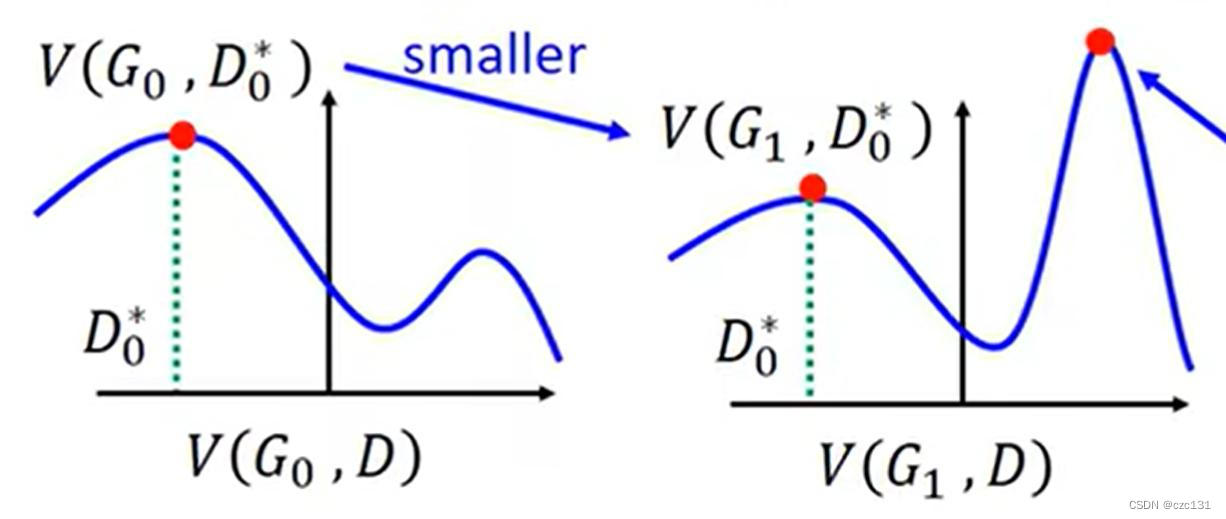
比如现在训练了一个discriminator是 D 0 ∗ D^*_0 D0∗,现在要让G变得更强,也就是让 D 0 ∗ D^*_0 D0∗对G生成的图辨别能力降低,直观体现就是 V ( G , D ) V(G,D) V(G,D)变小,但是因为更新参数对生成分布的影响是全局的,那么就可能导致生成图片和实际分布差异变得更大,因为变小的只有 D 0 ∗ D^*_0 D0∗的得分,可能这时候 D 0 ∗ D^*_0 D0∗已经不是最好的discriminator,而更好的discriminator可以将生成的和实际的分的更开,就像图二的最大值必原来的还大,那么对应于更高的 D ∗ D^* D∗计算得到的差异比原来还大。(有点绕这里)
所以有一个简单的假设,就是generator更新后的图形基本和原来保持一致,那么此时优化最大值让最大值变小,那么就相当于生成分布和实际分布差异更小,要达到这样的目的,那么不能更新generator太多;而对于discriminator,因为要找到最大值,应该要更新彻底。
3.实际操作
上面都是理论上的分析,下面讲一讲在实际的操作中是怎么做的。
3.1.训练discriminator
一个discriminator其实就是一个二分分类器,输入一个生成的数据,给出为真的概率,所以训练的过程也是和训练分类器是一样的,上面提到了 V ( G , D ) V(G,D) V(G,D)优化目标,里面有期望,期望一般会被转化为求多个样本的均值来获得。对于一个确定的生成器G,假设抽样取得m个真实样本X,生成了m个生成样本X',那么期望可以转化为:
V ( D ) = E x ∼ P d a t a l o g ( D ( x ) ) + E x ∼ P G l o g ( 1 − D ( x ) ) = > V ~ = 1 m ∑ i = 1 m l o g ( D ( x i ) ) + 1 m ∑ i = 1 m l o g ( 1 − D ( x i ′ ) ) V(D)=E_{x\sim P_{data}}log(D(x))+E_{x\sim P_{G}}log(1-D(x))\\ =>\widetilde{V}=\frac{1}{m}\sum_{i=1}^{m}log(D(x_i))+\frac{1}{m}\sum_{i=1}^{m}log(1-D(x'_i)) V(D)=Ex∼Pdatalog(D(x))+Ex∼PGlog(1−D(x))=>V =m1i=1∑mlog(D(xi))+m1i=1∑mlog(1−D(xi′))
一般会采用梯度上升法:(因为要求最大值)
θ d = θ d + η ▽ θ d V ~ ( θ d ) \theta_d=\theta_d+\eta ▽_{\theta_d}\widetilde{V}(\theta_d) θd=θd+η▽θdV (θd)
3.2.训练generator
训练generator实际上是为了减少 V ( G , D ∗ ) V(G,D^*) V(G,D∗),也就是让目前最好的分类器分不清,还是抽样,生成n个样本X',那么目标如下:
V ( D ) = 1 m ∑ i = 1 m l o g ( 1 − D ( G ( x i ′ ) ) ) V(D)=\frac{1}{m}\sum_{i=1}^{m}log(1-D(G(x'i))) V(D)=m1i=1∑mlog(1−D(G(xi′)))此时在变的是gegenerator的参数 θ g \theta_g θg,要通过改变生成参数让最好的discriminator得分降低,一般是梯度下降:
θ g = θ g − η ▽ θ g V ~ ( θ g ) \theta_g=\theta_g-\eta ▽{\theta_g}\widetilde{V}(\theta_g) θg=θg−η▽θgV (θg)要注意,不能训练次数太多(一般一次就可以)。
具体的代码实现我还没有去看过,就不进一步展开了,这一篇主要还是记录一些简单的原理。