研究背景
论文针对的主要问题是如何将预训练的大型语言模型(LLMs)适应特定领域的检索增强生成(RAG)。这些模型通常在广泛的文本数据上进行预训练,已经表现出在广义知识推理任务上的优越性能。然而,在特定领域,如法律、医学或最新新闻等,普遍的知识推理不足以满足精确性的要求,因此需要对这些模型进行适应性调整以增强其在这些领域内的应用性能。
研究目标
研究的主要目标是通过新的训练方法------RAFT(Retrieval Augmented Fine Tuning)提高LLMs在特定领域的性能。RAFT方法旨在通过链式思考风格的答案生成来提高模型对问题的理解和回答质量,同时确保模型能够有效地从相关文档中提取信息,并忽视那些无助于问题解答的干扰文档。
相关工作
研究背景部分详细讨论了现有的技术和挑战,特别是在RAG和监督式微调(SFT)的应用上。现有的RAG方法允许模型在回答问题时引用文档,但这些方法未能利用固定领域设置中的学习机会。监督式微调提供了学习文档中更通用模式的机会,更好地与结束任务和用户偏好对齐,但现有的微调方法在测试时未能考虑检索过程中的不完美。
方法论
数据处理
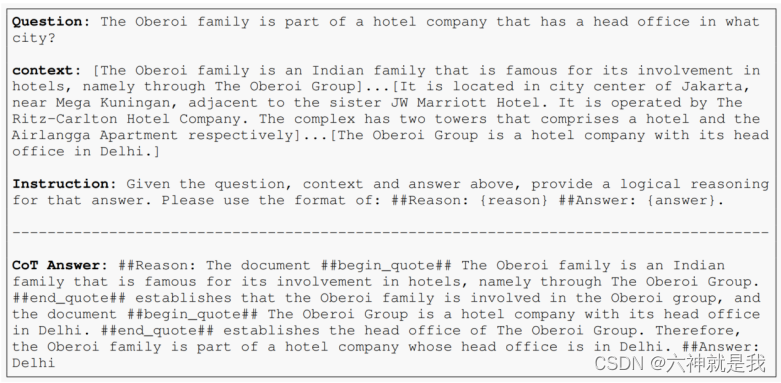
在RAFT中,训练数据的准备非常关键。每个数据点包括一个问题(Q)、一组文档(Dk),以及一个从文档中生成的链式思考风格的答案(A*)。这些文档分为"oracle"文档(D*),即可以从中推导出问题答案的文档,和"干扰"文档(Di),即不包含答案相关信息的文档。示例如下:
解决方案
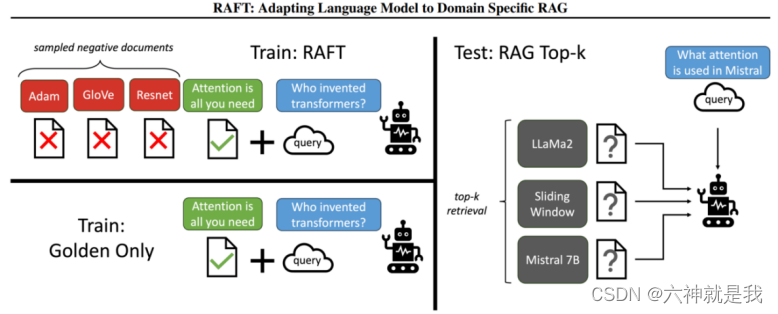
RAFT的核心是一个修改版的一般指令微调方法。通过精心设计的训练数据和模型微调过程,模型被训练为基于问题和提供的文档来生成答案,同时忽略那些干扰文档。这种方法的目标是提高模型在特定域内的性能,即在域特定的开放书本设置中更有效地使用RAG。
实验
实验设计
实验部分使用多个数据集来评估RAFT的性能,并将其与其他基线模型进行比较,例如LlaMA2-7B聊天模型和域特定的微调模型。这些数据集包括自然问题(NQ)、Trivia QA和HotpotQA等,涵盖从通用知识到特定领域的不同类型。
数据:
| 数据 | 描述 |
|---|---|
| PubMed | 医学QA问题。(二分类问题) |
| Natural Questions (NQ) | 通用领域 |
| HotpotQA | 通用领域 |
| Trivia QA | 通用领域 |
| HuggingFace | 编程的api领域 |
| Torch Hub | 编程的api领域 |
| TensorFlow Hub | 编程的api领域 |
实验结论
RAFT在多个评估任务上表现出色,尤其是在包含干扰文档的设置中。实验结果显示,与其他基线相比,RAFT在提取信息和处理干扰文档方面具有更高的鲁棒性和准确性。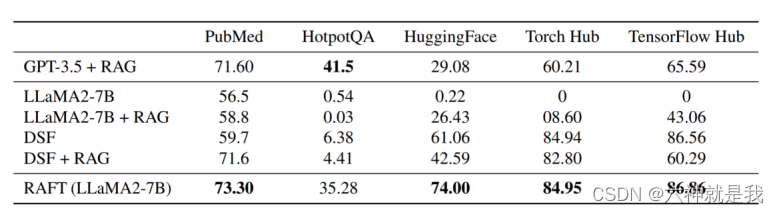
注:DSF是指对LlaMA2-7B-chat直接进行SFT(query-answer,预测时没有参考内容),预测时直接输入问你题。
-
有了思维链,结合推理链不仅可以引导模型找到答案,还可以丰富模型的理解,从而提高整体准确性。 在实验中,整合思想链显着增强了训练的稳健性。

-
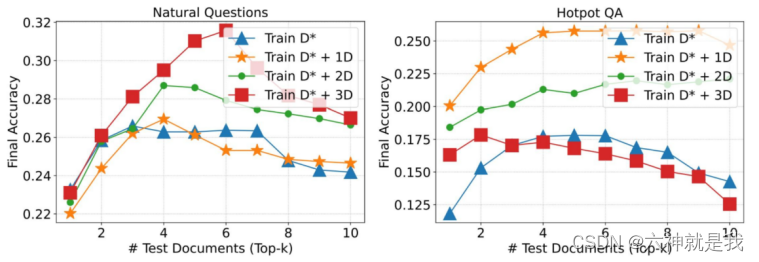
训练集中适当包含一定比例的不相关文档,会提高性能,但数量并不是绝对的,需要看具体的数据集,如在NQ数据集上,正负配比是1:3,HotpotQA数据上是1:1。