首先,多数情况下免费版本的功能,已经可以满足绝大多数采集需求,想了解八爪鱼采集器版本区别的详情,请访问这篇帖子: https://blog.csdn.net/cctv1123/article/details/139581468
八爪鱼采集器免费版和个人版、团队版下载链接:
通过前面的学习,我们已经进入到设计采集规则的实操课程。下面以一个实际案例来解答今天的课程要点:
滚动/瀑布流加载方式
 在这个案例就是线下滚动鼠标会一直加载出更多的信息。
在这个案例就是线下滚动鼠标会一直加载出更多的信息。
那么我们就可以用这个功能模块来实现网页向下滚动

根据箭头指示,点击"添加流程"
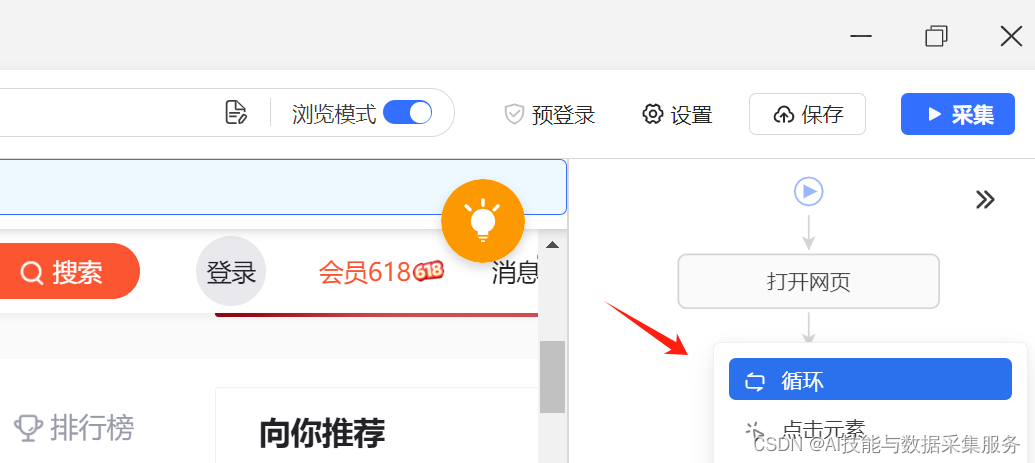
点击"循环"添加功能模块

在基础设置中点击"循环方式",切换到"滚动网页"
 根据需要修改滚动模式,如果只是滚动某一个小区域,就切换到"局部"
根据需要修改滚动模式,如果只是滚动某一个小区域,就切换到"局部"
滚动方式根据情况,选择滚动到底部还是向下滚动一屏。
如果需要设定滚动次数,就在这里的"循环次数"进行设定。
无内容更新时结束循环,也就是滚动到最下面了,1秒钟(根据你的设置)没有加载新的内容,就自动停止这个循环,进行后面的动作。
如果你要把其他的功能,再做一下详细的设置,根据实际情况操作即可。
翻页/分页的加载方式

例如我们要采集京东评论的内容,这里有100页,它的翻页按钮是"下一页",
那么我们就需要定位"下一页"按钮的xpath,然后构建一个循环点击它的动作来执行自动翻页。

上图是通过点选方案进行循环点击的构建,下图再说一下,通过手动添加模块的方式构建

先将"循环"中的循环方式调整为"单个元素",在填入正确的xpath信息

然后在循环中,添加一个点击动作,这个动作的xpath为空,但是在前面需要选择"拼接循环项xpath"

最后,我们在这个循环的中间,添加一个数据提取的模块,提取的元素信息为,当前评论的页码数

我们来测试一下

本接课程我们说了两种翻页情况,滚动/瀑布流和翻页加载方式,下节课我们来说说网页界面中的弹出窗口怎么移除。
这贴是教程专栏的目录链接: