每周一篇小博客,你我都没小烦恼;这次来讲讲数据结构中的重点内容,二叉树的堆
此次总共分为三篇,上中下;分别讲的是堆、链式结构二叉树、经典例题的讲解;接下就是树的概念和堆

目录
[5. 二叉树的顺序结构及实现](#5. 二叉树的顺序结构及实现)
[5.1堆的实现 在下面堆排序更详细的解释](#5.1堆的实现 在下面堆排序更详细的解释)
1.树概念及结构
- 树是一种非线性的数据结构,由根和节点组成;为什么是树?因为看起来像一颗倒挂过来的树
- 根节点没有前置节点
- 可以发现 走到 j的时候,问题就被 大事化小 ,小事化了;也就是大家常说的分治;分治就是分而治之
- 而分治呢? 又可以说是 分治 == 递归,可以画上等号他们两有着紧密的关联

1.2树形结构之间不可以相交
- 通过A 分为了三个子树 B C D ,子树之间不可以相交;如果相交了,那么就不是树了
- 子树相交就是 图 了,图是另外一个数据结构;本篇文章重点还是 堆

树的表示,这里用左孩子右兄弟;这里解释一下大概的思路做下了解即可
- 第一个父节点指向第一个孩子节点,不管有多少个孩子,child始终都指向左边开始的第一个孩子
- 孩子节点指向兄弟节点

2.树的的相关概念
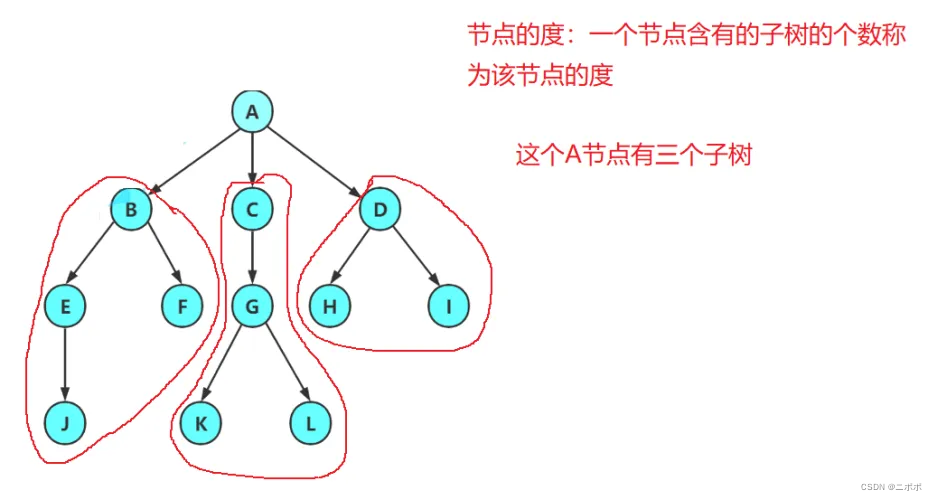
红色部分是最重要的概念
-
节点的度:一个节点含有的子树的个数 称为该节点的度(画红圈的部分)
-
叶节点或终端节点:度为0的节点称为叶节点;也是图中的J F K L H I 都是的
-
非终端节点或分支节点:度不为0的节点; 列如B G D这是都是分支节点;那么一个树就由叶节点 + 分支节点
-
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 意思就是B的父亲是A,那么A就是父节点
- 而且比如 C,C是G的父亲,但是C也是A的孩子,就是和家庭关系一样;像不像人到中年上有老下有小
-
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- A有三个孩子分别是:B、C、D
-
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图

- G H就不能是兄弟节点了,不是共同的父亲;只能说是有共同的爷爷
-
树的度 :一棵树中,最大的节点的度称为树的度;
- 就是刚刚的第一个概念,主要看哪个节点的度多,谁多谁就是这颗树最大节点的度;上面的图最大的度就是3
-
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
-
树的高度或深度:树中节点的最大层次;如上图:树的高度为4
- 那么根节点可以不可以用0表示?就像和数组一样,最后的高度就是3,当然也是可以的,假如说是按照数组的下标一样从0开始的
- 那么数组为啥不从 1 开始?,其实有原因的 举个例子

-
堂兄弟节点:双亲在同一层的节点互为堂兄弟;
- 就是刚刚所说的H 和 l,他两是堂兄弟
-
节点的祖先:从根到该节点所经分支上的所有节点;A是所有节点的祖先;当然这个祖先要是直系亲属才行
-
子孙:以某节点为根的子树 中 任一节点都称为该节点的子孙
- A的子孙是下面的所有,而B的子孙是E F J;

-
森林:由m(m>0)棵互不相交的树的集合称为森林;有很多很多数组成的森林 后面有个叫并查集的也是多个树


3.二叉树概念及结构
3.1概念

- 从图中可以看出二叉树由一个根节点和左孩子、右孩子组成;最多节点不能大于2;
- 二叉树的组成方式,由下面五种方式组成

3.2特殊二叉树
- 满二叉树:它可以存储的数据有很多;假设 满二叉树是20层那么可存储的数据量是2^20 约等于 100w;2^30 约等于 10亿
- 完全二叉树: 完全二叉树是效率很高的数据结构;有个条件前面h - 1层都是满的;并且最后一层不满从左到右连续存储的 ;
下面这种就不是完全二叉树了,



4.二叉树的存储结构
4.1数组存储的方式
顺序结构
-
第一种满二叉树

-
第二种完全二叉树;满二叉树可以是完全二叉树,但是完全二叉树不一定是满二叉树

-
第三种非完全二叉树
- 那么非完全而二叉树可不可以存储呢?可以,但是会造成很多的空间浪费
- 假如你让D存到3的位置,E存到4的位置;那么E查找父节点的时候就会找到B(带入公式);但是E的父节点是C啊;这不就找错爹了(doge)肯定不行啊

5. 二叉树的顺序结构及实现

- 小堆;那么是不是降序呢?不是的;同一层之间没有大小比较,所以不能确定大小关系
- 特点:根节点始终都是最小的

- 大堆; 特点:根节点始终都是最大的

- topK问题,就是在10w数据中查找最大前10个
5.1堆的实现 在下面堆排序更详细的解释
- 基本结构,底层基于数组存储
cpp
typedef int HPDataType;
typedef struct heap
{
HPDataType* a;
int size;//数据个数
int capacity;//有效空间
}HP;- 堆的初始化和销毁,根据物理结构我们用数组来存储
- 初始化:两种方式 这里我使用第一种
- 接收一个结构体指针,对结构体申请空间,无返回值 Init
- 直接创建一块空间,通过返回空间,那边去接收,有返回值 create
cpp
//初始化
void HPInit(HP* php)//穿过来一个结构体
{
assert(php);
php->a = NULL;
php->size = php->capacity = 0;
}
//销毁
void HPDestroy(HP* php)
{
assert(php);
//assert(php->a);//可以不加因为freeNULL,也不会有事
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}这个的初始化和销毁很简单,这里就不说,重点讲一下Push和Pop
5.2Push
-
插入一个数据时,要一直和祖先比较,这个是小堆,假如插入的数一直比父节点小,那么要和父节点交换位置
-
最好的情况是刚好比父节点大;就不用交换break退出;
-
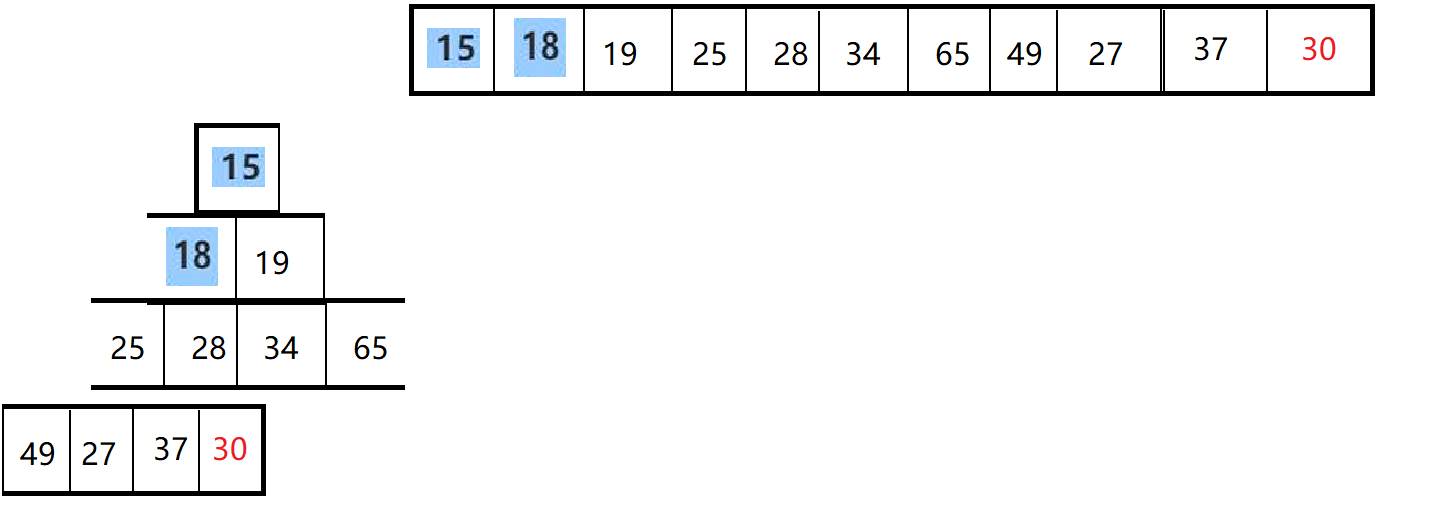
-
最坏的情况要当所以父节点的爸 (根节点);这里讲的是AdjustUP核心交换逻辑
-

-
代码逻辑: 更详细的
1.孩子节点(child),就是数组的最后的位置;父节点(parent)就可以通过(child-1)/2 ;找到孩子
2.if判断如果孩子节点位置的数据比父节点小,那么就交换
3.循环条件,使得child不能出堆顶 -
这里不要拿父节点当结束循环的条件;
-
孩子节点和父节点交换成功后,让孩子节点到父节点去;然后通过孩子节点计算父节点
-
如果要创建大堆,改变if 大于或者小于号;

1.向上调整算法
- 注意:此个算法,在堆排序中有对应的动图
- 像空间申请那部分的代码,如果学习顺序表或者栈都应该会了,如果还不会可以去看看之前顺序表那篇博客 -> 快速跳转**顺序表详细版**
- 那么对应的复杂度是logN,每调整一个数,最坏要调整高度次
cpp
//交换数据
void Swap(HPDataType* x, HPDataType* y)
{
HPDataType tmp = *x;
*x = *y;
*y = tmp;
}
//向上调整
void AdjustUP(HPDataType* a,int child)
{
//通过孩子找父亲
int parent = (child - 1) / 2;
while (child > 0)//小于等于0,已经到根节点
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;//进行上层的比较,让父节点刷新
parent = (child - 1) / 2;//通过
}
else//比父节点小,就不用调整了
{
break;
}
}
}
void HPPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
int new = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * new);//这里需要realloc来动态开辟,假如a为NULL则是malloc的功能
if (tmp == NULL)
{
perror("HPPush()::malloc()");
return;
}
php->a = tmp;
php->capacity = new;
}
//使用空间
php->a[php->size] = x;
php->size++;
//先把数据插入到数组再变成堆
AdjustUP(php->a,php->size - 1);//传递孩子的位置
}5.3Pop
Pop的要求是,让我们删除堆顶的元素,而不是数组末尾的;
- Pop分为三步 建议:代码,画图,文字结合查看
- 先找到最后一个叶节点与堆顶元素交换
- 然后删除最后一个叶节点,
- 利用向下调整算法调整堆顶元素位置,让该位置的值到对应位置
- 调整到对应位置就需要用到一个向下调整的算法 通过父亲找孩子
- 这里是小堆, 首先可以利用假设法,计算左孩子(这里的左孩子是用数组存储的位置在1),假设左孩子(child)更小;
- if判断,如果假设失败则child++,那就是第二个了

- if (child < size - 1 && achild + 1 < achild)//右孩子更小,child要小于size 不然会越界;
- 这个是小堆,child位置的数据小于parent,意味着大的数往下放交换;
- 向下调整的过程中;看图,让之前的child位置成为新的parent,那么再次计算child,循环比较
- 那么结束条件是什么? 这就需要考虑边界值了;可以看看size的边界在哪里,就可以设计出while循环了; 后面堆排序和这个紧密相关
1.向下调整算法
-
向下调整的复杂度也是需要调整高度次 的,复杂度就是logN
cpp//向下调整 void AdjustDown(HPDataType* a, int size, int parent) { int child = parent * 2 + 1;//计算出孩子位置,假设是左孩子 //假设法 while(child < size)//假如是 child >= size 说明没有孩子了 { if (child < size - 1 && a[child + 1] < a[child])//右孩子更小,child要小于size 不然会越界 { child++; } if (a[child] < a[parent])//小堆 { Swap(&a[child], &a[parent]); parent = child;//让小的孩子成为新爸 child = parent * 2 + 1;//通过父亲找孩子 } else { break;//老爸小于孩子,不交换,图4 } } } //删除数据 void HPPop(HP* php) { assert(php); assert(php->size > 0);//删除数据要注意不能删到负数,而且数组的空间是一次性开辟的 Swap(&php->a[0], &php->a[php->size - 1]); php->size--; //向下调整 AdjustDown(php->a, php->size, 0);//传过去的是根的位置,让根位置数据调整 }5.4判空,堆顶元素,有效个数
- 即使对应的代码很少,也要单独写成一个函数;因为多了assert的判断;就算不调用这个函数也要提前声明
cpp
//判空
bool HPEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
//取堆顶元素
HPDataType HPTop(HP* php)
{
assert(php);
assert(php->size > 0);//数组是用size,而链表每次销毁数据要看还有没有这块空间
return php->a[0];
}
//有效个数
int HPSize(HP* php)
{
assert(php);
return php->size;
}5.5堆的高度为什么是logN

6.堆排序
按照思维惯性,可能大部分人会认为升序建小堆,降序建大堆;但是不是的
- 升序建大堆
- 降序建小堆;为什么呢?假如是降序建大堆 那么刚好数据在堆顶可以直接拿到,但是呢 看图例

所以降序建小堆才是对的,再来看看过程

6.1向上调整建堆
- 可以观察到,最后结果和调试图一致,自己可以弄一组试试;复杂度是 O(N * logN)

cpp
void TestHeapSort()
{
//建堆
//升序建大堆
//降序建小堆
int a[] = { 4,2,8,1,5,6,9,7 };
int sz = sizeof(a) / sizeof(a[0]);
//向上调整建堆,遍历每个数,放进去的每个数都要调整
for (int i = 0; i < sz; i++)
{
AdjustUp(a, i);
}
int end = sz - 1;
while (end)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
for (int i = 0; i < sz; i++)
{
printf("%d ", a[i]);
}
}向上调整建堆复杂度
- 每层节点多,向上调整次数就多
- 每层节点少,向上调整次数就少


6.2向下调整建堆
- 向下调整建堆的动图 复杂度:O(N)

再来看看调式代码中对不对

6.2.1代码排序逻辑
- 经过上面了解,这里知道了向下调整建堆更好;
- 降序举例:先交换堆顶数据,最小数是不是就到了数组的最末尾
- 刚好是数组最后一个数,然后end --范围缩小;通过向下调整堆
- 如此往复,最后数组中就是倒叙了
这里用动图调试代码的过程来展示排序逻辑为什么降序要建小堆;
注意: 这里主要展示排序逻辑

找到第一个非叶子节点
- 这里为什么写成(sz - 1 - 1) / 2,可以从上面的动图得知 sz - 1是数组的最后一个元素,那么还有一个 -1呢?,则是要通过字节点找到父节点,所需要的 - 1
- 假设两个子节点, 下标****分别是5和6; (5 - 1) / 2 = 2 和 (6 - 1) / 2 = 2 ,通过计算就可得出他们的父节点都是下标2
- 以此向前遍历直到下标为0,建堆就完成了
cpp
void TestHeapSort()
{
//建堆
//升序建大堆
//降序建小堆
int a[] = { 4,2,8,1,5,6,9,7 };
int sz = sizeof(a) / sizeof(a[0]);
//向下调整建堆,遍历每个数,放进去的每个数都要调整
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, sz, 0);
}
int end = sz - 1;
while (end)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
for (int i = 0; i < sz; i++)
{
printf("%d ", a[i]);
}
}- 排序的向下调整复杂度
- 这个调整过程中次数是变化的
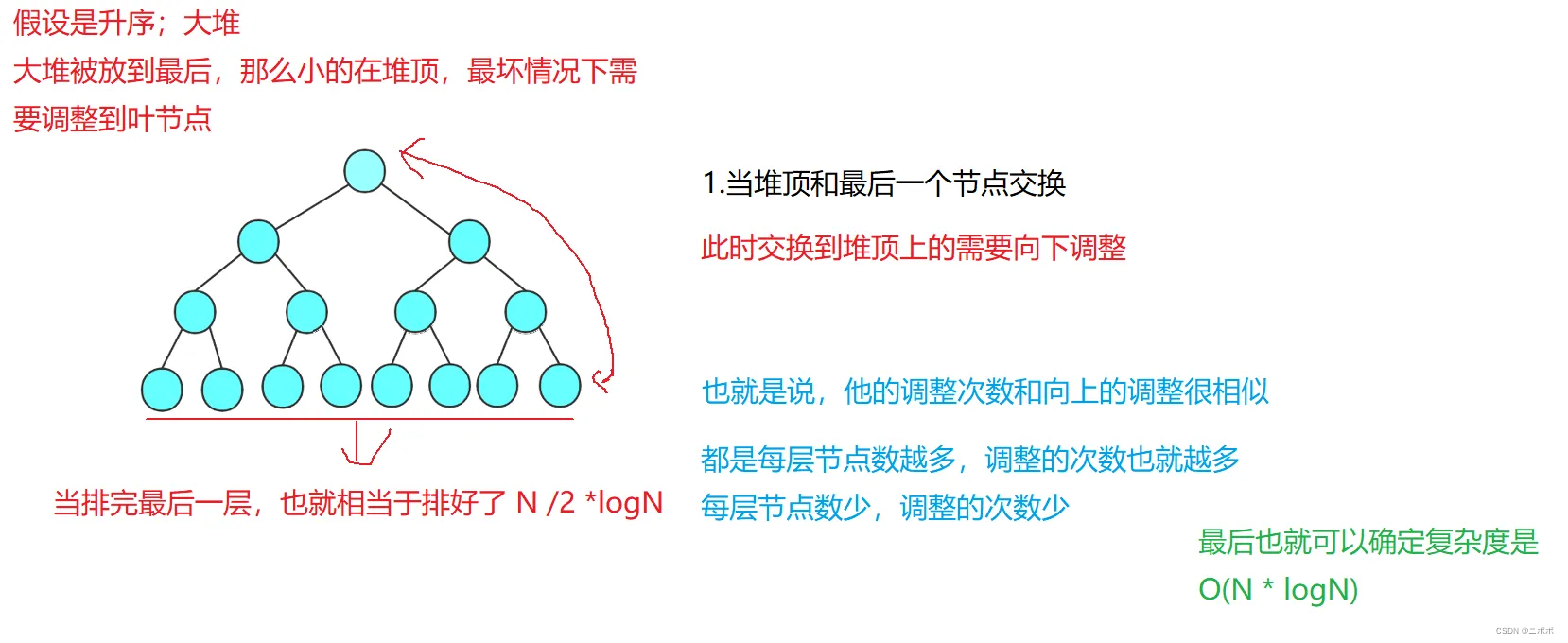
6.2.2向下调整建堆复杂度
- 每层节点越少,调整次数多
- 每层节点越多,调整次数少
- 小堆,父节点始终要大于字节的;也跟高度息息相关
- 该层节点向下调整的总次数,每次只会选择最小的那个向下调整


7.TopK问题
TopK,意思就是找出前10个最大的,或者最小的数据;常用于购物排序金额,或者前10的首富等等
7.1方法1
- 建N个数的堆 O(N)
- Pop k次 O(k*logN)
- 如果10亿数据你要怎么办?,先来看看这些数据有多大
- 从下面图中,可以看出数据量有大约4G,但是不到4G,虽然可以分多次进行
- 因为是用数组开辟的空间,占用的空间太大,本来电脑内存不算大,你还要占几G,所以还是换个方法吧

7.2方法2
前N最大,建小堆
前N最小,建大堆
- k是什么就建一个K个大小的堆;找出前10个最大的,建小堆;依次和堆顶比较,比对顶大就替换堆顶数据,然后向下调整
- 调整过后,最小的又会到堆顶,依次循环;最后堆里就是前10个最大的了

代码逻辑
- 造数据,把获取到的随机数数据都放到文件中,就不占用内存了
- 打开数据文件,malloc K个大小的数组空间
- 因为是前十个最大的,所以建小堆,读取数据给给数组建小堆;
- 通过fscanf读取数据,和scanf一样会过滤掉空格换行,制表符等等;如果还不会fscanf的可以去看看这篇博客 --> 文件操作
- 接下来就是比较堆顶数据,比堆顶大向下调整;
- 还有一个小问题:你怎么知道找到的数据是最大的前10个。解决方法是: 固定产生10W以内的数据**,然后更改文件内数据,设置比10w大的数据,最后排序是你设置的这些数,那就没问题了**
- int x = (rand() + i) % 100000;
cpp
//造数据
void CreateData()
{
int n = 100;
srand(time(0));
//写入文件
FILE* pf = fopen("Data.txt", "w");//w 写入 ,r读取
if (pf == NULL)
{
perror("fopen fail");
return;
}
for (int i = 0; i < n; i++)
{
int x = (rand() + i) % 100000;// + i 减少数据重复,rand最多产生3w不重复的
//写入
fprintf(pf, "%d\n", x);
}
fclose(pf);
pf = NULL;
}
void TopK(int k)
{
//打开文件
FILE* pf = fopen("Data.txt", "r");//w 写入 ,r读取
if (pf == NULL)
{
perror("fopen fail");
return;
}
//开辟k个空间大小
int* kminHeap = (int*)malloc(sizeof(int) * k);
if (kminHeap == NULL)
{
perror("malloc fail");
return;
}
//读取文件中数据
for (int i = 0; i < k; i++)
{
fscanf(pf, "%d", &kminHeap[i]);//从pf读数据写到kminHeap
}
//建小堆
for (int j = (k - 1 - 1) / 2; j >= 0; j--)
{
AdjustDown(kminHeap, k, j);//向下调整建堆
}
//比较
int x = 0;//创建一个临时的变量,读取到x中
//int ret = 0;
while (fscanf(pf, "%d", &x) > 0)//遇到文件末尾返回非0值,
{
//printf("%d\n", 66);
if (x > kminHeap[0])
{
kminHeap[0] = x;
AdjustDown(kminHeap, k, 0);
}
}
for (int i = 0; i < k; i++)
{
fprintf(stdout,"%d ",kminHeap[i]);
}
}- 排序结束,找到的数据均是我设置比10w大的,说明这个找前10个最大的没问题

总结
最近快期末了,很烦,很不喜欢做自己不喜欢的时候;这期稍微更新慢了,一眨眼博客半个月没写了
加油!,各位希望以后有机会相见!