sklearn简介
Scikit-learn(简称 sklearn)是一个强大的 Python 库,用于机器学习 和数据挖掘 。它内置了许多常用的机器学习算法和工具,适合初学者和专家使用。本文将带你入门 sklearn,并提供一些基本的例子。
sklearn开源在github,可以很方便的获取源码.
当前,pytorch大行其道,那么sklearn是否还有什么优势呢?还是有的:
-
适用于传统机器学习:scikit-learn提供了丰富的传统机器学习算法和工具,特别擅长处理结构化数据和应用于监督学习、无监督学习和特征工程等领域。
-
易于上手:scikit-learn的API设计简单直观,适合机器学习的初学者和快速原型开发。
-
成熟稳定:scikit-learn是一个成熟的机器学习库,拥有丰富的文档和社区支持,对于传统机器学习问题有很好的解决方案。
安装 sklearn
在开始使用 sklearn 之前,需要先安装它。可以使用 pip 进行安装:
bash
pip install scikit-learn也可以用conda进行安装
bash
conda install -c conda-forge scikit-learn如果使用conda还可以创建env与安装sklearn在同一个命令中完成
bash
conda create -n sklearn-env -c conda-forge scikit-learn
conda activate sklearn-env要注意sklearn安装有一些依赖要求:
- Python (>= 3.9)
- NumPy (>= 1.19.5)
- SciPy (>= 1.6.0)
- joblib (>= 1.2.0)
- threadpoolctl (>= 3.1.0)
导入库
在使用 sklearn 之前,首先需要导入相关的库。通常情况下,我们还会导入 NumPy 和 Pandas 以便处理数据:
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score下面我们给出一个机器学习领域的Hello World. 训练流程如下:
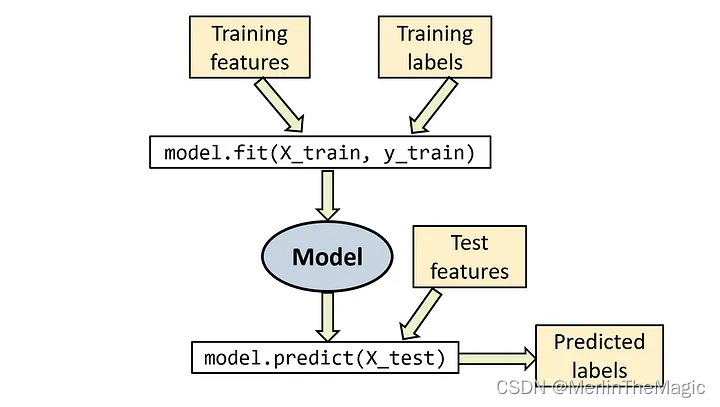
数据准备
我们将使用一个简单的例子来演示 sklearn 的基本使用。这里使用一个常见的鸢尾花(Iris)数据集。你可以从 sklearn 中直接加载这个数据集:
python
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)数据预处理
数据预处理是机器学习过程中非常重要的一步。常见的预处理步骤包括标准化、归一化、处理缺失值等。这里我们进行标准化处理:
python
scaler = StandardScaler()
# 计算训练数据的均值和标准差,然后将训练数据进行标准化
X_train = scaler.fit_transform(X_train)
# 使用在训练数据上计算的均值和标准差将测试数据进行标准化
X_test = scaler.transform(X_test)训练模型
在 sklearn 中,训练模型非常简单。这里我们使用逻辑回归模型
逻辑回归模型
逻辑回归是一种用于处理分类问题的统计学习方法,尽管其名称中包含"回归"一词,但实际上逻辑回归是一种分类算法,用于预测输入变量与离散输出变量之间的关系。以下是逻辑回归的一些关键特点和基本原理:
-
适用于二分类问题:逻辑回归主要用于解决二分类问题,即目标变量只有两种可能的取值。
-
输出为概率值:逻辑回归模型的输出是输入变量属于某个类别的概率,通常用于判断一个样本属于某一类的可能性有多大。
-
基于线性回归:逻辑回归的基本原理是基于线性回归的思想,通过对输入特征进行加权求和得到一个线性预测值,然后通过一个逻辑函数(如sigmoid函数)将线性值映射到0, 1之间,作为类别为1的概率。
-
损失函数:逻辑回归使用对数损失函数来衡量预测概率与实际类别之间的差距,并通过最小化损失函数来拟合模型参数。
-
参数估计:通常使用最大似然估计或梯度下降等方法来估计模型参数,以使模型能够最好地拟合训练数据。
-
可解释性强:逻辑回归模型的输出可以解释为对数几率(log odds),因此可以很好地理解输入特征对输出的影响。
逻辑回归是一种简单而有效的分类算法,常用于实践中的二分类问题,如信用风险预测、疾病诊断等。在scikit-learn中,逻辑回归模型可以很容易地进行构建和应用。
sklearn逻辑回归
用sklearn实现非常简单
python
model = LogisticRegression()
# 在训练数据上训练模型
model.fit(X_train, y_train)预测与评估
训练好模型后,我们可以在测试数据上进行预测,并评估模型的表现:
python
# 使用训练好的模型进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型的准确率: {accuracy:.2f}")完整代码示例
以下是上述步骤的完整代码示例, 注意安装依赖:
bash
pip install pandas
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据预处理:标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型表现
accuracy = accuracy_score(y_test, y_pred)
print(f"模型的准确率: {accuracy:.2f}")总结
本文介绍了 sklearn 的基础使用方法,包括数据加载、预处理、模型训练和评估。通过这些步骤,你可以快速上手 sklearn,进行简单的机器学习任务。希望这篇入门指南对你有所帮助!