DeepIV 是什么?
DeepIV(Deep Instrumental Variables)是一种用于因果推断的计量经济学和机器学习方法。它的核心目标是在存在**内生性(Endogeneity)**问题时,估计处理(Treatment)对结果(Outcome)的因果效应。
内生性问题: 在标准的回归分析(如 OLS)中,我们假设处理变量 T 与模型的误差项 ε 不相关 (Cov(T, ε) = 0)。但很多现实场景下,这个假设不成立,原因可能包括:
-
遗漏变量偏差(Omitted Variable Bias):
存在一些未观测到的混淆因子(Unobserved Confounders),它们既影响处理 T,也影响结果 Y。
-
同时性(Simultaneity):
T 和 Y 互相决定。
-
测量误差(Measurement Error):
处理变量 T 的测量不准确。
当内生性存在时,直接用 OLS 等方法估计 T 对 Y 的效应会得到有偏(biased)和不一致(inconsistent)的结果,无法代表真实的因果关系。
工具变量(Instrumental Variables, IV)方法: IV 是解决内生性问题的经典方法。一个有效的工具变量 Z 必须满足三个核心条件:
-
相关性(Relevance):
Z 必须与内生处理变量 T 相关 (Cov(Z, T) ≠ 0)。
-
排他性约束(Exclusion Restriction):
Z 只能通过影响 T 来影响 Y,不能有直接影响 Y 的其他路径 (Z 直接影响 Y 的系数为 0)。
-
外生性/独立性(Exogeneity/Independence):
Z 必须与模型中未观测到的混淆因子(即误差项 ε)不相关 (Cov(Z, ε) = 0)。
传统的 IV 方法(如两阶段最小二乘法,2SLS)通常假设模型是线性的。
DeepIV 的创新: DeepIV 将深度学习(神经网络)的强大表征能力引入了 IV 框架。它允许我们:
-
处理复杂的非线性关系:
变量之间的关系(如 Z 对 T,T 对 Y,以及协变量 X/W 的影响)可能非常复杂,神经网络可以有效地拟合这些非线性模式。
-
估计异质性处理效应(Heterogeneous Treatment Effects, HTE):
处理 T 的效果可能因个体的特征(协变量 X/W)而异。DeepIV 可以估计这种变化的效应,即条件平均处理效应(Conditional Average Treatment Effect, CATE)。
CausalForestDML(因果森林双重机器学习)
CausalForestDML(因果森林双重机器学习)是一种用于因果推断的统计方法,特别是在处理观测数据时的一种灵活和强大的工具。它结合了随机森林的灵活性与双重机器学习(Double Machine Learning, DML)的框架,旨在估计处理效应(treatment effect)并控制潜在的混杂变量。
-
因果森林:因果森林是随机森林的一种扩展,专门设计用于估计个体处理效应(ITE,Individual Treatment Effect)。它是基于对各种个体特征的学习,从而能够做出处理与未处理个体之间的比较。
-
双重机器学习(DML):DML是一种用于因果推断的方法,旨在通过机器学习技术在存在高维控制变量的情况下减少偏差。它通过首先使用机器学习模型来控制混杂因素,然后通过残差(如处理变量和结果变量的残差)来估计因果效应。
如何使用CausalForestDML
使用CausalForestDML进行因果推断的一般步骤如下:
-
数据准备:收集包含处理变量、结果变量和一系列控制变量的数据集。
-
模型拟合:
-
使用机器学习模型(如线性回归、随机森林或其他合适的模型)来预测结果变量(Y)和处理变量(T)在给定控制变量(X)下的值。
-
计算残差:从结果变量和处理变量中减去模型预测值,得到残差 Y−Y^
-
-
因果森林模型:基于残差拟合因果森林,估计处理效应。
-
效果估计:从因果森林模型中提取个体处理效应的估计。
何时使用CausalForestDML
-
高维数据
当你有大量控制变量(特征)且不希望因为使用简单的线性模型而导致的偏差时。
-
非线性关系
在数据中存在线性和非线性关系,随机森林可以捕捉这些复杂关系。
-
异质性处理效应
当你怀疑不同个体对处理的反应是不同的时候,可以估计个体处理效应。
第一阶段:导入必要的库
# 初始设置:抑制警告
import warnings
warnings.simplefilter('ignore')
`
基础库导入`
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from itertools import product
import time
`
机器学习库`
from sklearn.linear_model import Lasso, LogisticRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
`
Keras和深度学习库`
import keras
from keras.optimizers import Adagrad
from keras.callbacks import EarlyStopping
`
因果推断库`
import econml
from econml.dml import CausalForestDML
from econml.iv.nnet import DeepIV
这部分代码主要是导入分析所需的各种库:
-
warnings: 用于抑制警告信息。
-
numpy,
pandas: 基础数据处理和操作库。 -
matplotlib,
seaborn: 数据可视化库。 -
itertools.product: 用于生成笛卡尔积。
-
time: 用于计时。
-
sklearn: 机器学习库,这里主要用到线性模型和评估指标。
-
keras: 深度学习框架,用于构建神经网络。
-
econml: 因果推断库,包含了各种因果推断方法。
第二阶段:定义辅助函数
def exp_te(x):
"""
定义指数形式的真实处理效应函数
参数:
x: 一维数组,协变量向量
返回:
float: 处理效应值
"""
return np.exp(2*x[0])
defepsilon_sample(n):
"""生成结果变量的噪声"""
return np.random.uniform(-1, 1, size=n)
defeta_sample(n):
"""生成处理变量的噪声"""
return np.random.uniform(-1, 1, size=n)
这部分定义了一些辅助函数:
-
exp_te: 定义了真实的处理效应函数,这里假设是指数形式。
-
epsilon_sample,
eta_sample: 分别生成结果变量和处理变量的噪声项。
第三阶段:生成合成数据
def generate_synthetic_data(n=1000, n_w=30, n_x=1, support_size=5, random_seed=1234):
"""
生成用于因果推断分析的合成数据
参数:
n: 样本数量
n_w: 控制变量W的维度
n_x: 协变量X的维度
support_size: 支持大小(影响结果的特征数量)
random_seed: 随机种子,确保结果可重现
返回:
W: 控制变量
X: 协变量
T: 处理变量
Y: 结果变量
instrument: 工具变量
TE: 真实处理效应
X_test: 测试数据点
"""
`
设置随机种子`
np.random.seed(random_seed)
`
结果变量的支持`
support_Y = np.random.choice(range(n_w), size=support_size, replace=False)
coefs_Y = np.random.uniform(0, 1, size=support_size)
`
处理变量的支持`
support_T = support_Y # 使用相同的支持,创造内生性
coefs_T = np.random.uniform(0, 1, size=support_size)
`
生成变量`
W = np.random.normal(0, 1, size=(n, n_w)) # 控制变量
X = np.random.uniform(0, 1, size=(n, n_x)) # 协变量
instrument = np.random.uniform(0, 1, size=(n, n_x)) # 工具变量
`
异质性处理效应`
TE = np.array([exp_te(x_i) for x_i in X])
`
定义处理(通过倾向性模型)`
log_odds = np.dot(W[:, support_T], coefs_T) + eta_sample(n)
T_sigmoid = 1/(1 + np.exp(-log_odds))
T = np.array([np.random.binomial(1, p) for p in T_sigmoid])
`
定义结果`
Y = TE * T + np.dot(W[:, support_Y], coefs_Y) + epsilon_sample(n)
`
测试数据`
X_test = np.array(list(product(np.arange(0, 1, 0.01), repeat=n_x)))
return W, X, T, Y, instrument, TE, X_test
这个函数用于生成合成数据,模拟了一个存在内生性和异质性处理效应的场景:
-
首先设置随机种子,确保结果可重现。
-
然后定义结果变量
Y和处理变量T的支持集,即哪些控制变量会影响它们。这里让Y和T共享相同的支持集,以创造内生性。 -
接着生成控制变量
W、协变量X和工具变量instrument。 -
根据
X计算异质性处理效应TE。 -
通过一个倾向性模型定义处理变量
T,这里用W的一个子集加上噪声项来生成T的对数几率,然后通过 sigmoid 函数转换为概率,最后根据这个概率生成二元的T。 -
最后,结果变量
Y是TE、T、W的一个子集和噪声项的函数。 -
同时还生成了一些测试数据点
X_test。
第四阶段:构建模型
def build_treatment_model(input_shape, dropout_rate=0.17):
"""构建处理模型(简化版本)"""
model = keras.Sequential([
keras.layers.Dense(64, activation='relu', input_shape=input_shape),
keras.layers.Dropout(dropout_rate),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dropout(dropout_rate),
keras.layers.Dense(1)
])
return model
defbuild_outcome_model(input_shape, dropout_rate=0.17):
"""构建结果模型(简化版本)"""
model = keras.Sequential([
keras.layers.Dense(64, activation='relu', input_shape=input_shape),
keras.layers.Dropout(dropout_rate),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dropout(dropout_rate),
keras.layers.Dense(1)
])
return model
defcreate_deepiv_model(W_shape, learning_rate=0.0009, dropout_rate=0.17, n_components=10):
"""
创建DeepIV模型
参数:
W_shape: 控制变量W的形状
learning_rate: 学习率
dropout_rate: Dropout率
n_components: 混合成分数量
返回:
DeepIV模型实例
"""
`
构建处理模型`
treatment_model = build_treatment_model((W_shape[1]+1,), dropout_rate)
`
构建结果模型`
outcome_model = build_outcome_model((W_shape[1]+1,), dropout_rate)
`
训练配置`
keras_fit_options = {
"epochs": 100, # 减少训练轮数
"validation_split": 0.20,
"callbacks": [EarlyStopping(patience=2, restore_best_weights=True)]
}
`
创建DeepIV模型`
deepiv_model = DeepIV(
n_components=n_components,
m=lambda z, x: treatment_model(keras.layers.concatenate([z, x])),
h=lambda t, x: outcome_model(keras.layers.concatenate([t, x])),
n_samples=2,
use_upper_bound_loss=True,
n_gradient_samples=0,
optimizer=Adagrad(learning_rate=learning_rate),
first_stage_options=keras_fit_options,
second_stage_options=keras_fit_options
)
return deepiv_model
defcreate_dml_forest_model():
"""创建CausalForestDML模型"""
return CausalForestDML(
model_y=Lasso(alpha=0.01),
model_t=LogisticRegression(C=1.0),
n_estimators=100, # 减少树的数量
min_samples_leaf=10,
max_depth=10,
n_jobs=1# 避免并行处理问题
)
这部分定义了模型构建函数:
-
build_treatment_model构建 DeepIV 的处理模型和结果模型,这里使用简化版本的多层感知机。
-
create_deepiv_model创建 DeepIV 模型实例,将处理模型和结果模型组合起来,并设置训练参数。
-
create_dml_forest_model:创建 CausalForestDML 模型实例,这是一种基于双机器学习(DML)的因果森林方法。
第五阶段:评估模型
def evaluate_model(model, X, T, W, true_effect, model_name="Model"):
"""
评估模型性能
参数:
model: 模型实例
X: 协变量
T: 处理变量
W: 控制变量
true_effect: 真实处理效应
model_name: 模型名称(用于显示)
返回:
评估指标字典
"""
start_time = time.time()
try:
`
预测效应(根据模型类型选择不同的预测方法)`
ifisinstance(model, DeepIV):
`
DeepIV需要特殊处理`
pred_effect = model.effect(X=W, T0=np.zeros_like(T), T1=np.ones_like(T))
else:
`
其他模型使用统一的方法`
pred_effect = model.effect(X=X)
`
计算评估指标`
mse = mean_squared_error(true_effect, pred_effect)
mae = mean_absolute_error(true_effect, pred_effect)
r2 = r2_score(true_effect, pred_effect)
elapsed_time = time.time() - start_time
`
返回评估结果`
metrics = {
"name": model_name,
"mse": mse,
"mae": mae,
"r2": r2,
"time": elapsed_time,
"predictions": pred_effect
}
print(f"{model_name} - MSE: {mse:.4f}, MAE: {mae:.4f}, R²: {r2:.4f}, Time: {elapsed_time:.2f}s")
return metrics
except Exception as e:
print(f"评估{model_name}时出错: {str(e)}")
return {
"name": model_name,
"error": str(e),
"predictions": np.zeros_like(true_effect)
}
这个函数用于评估模型性能:
-
它接受模型实例、数据和真实效应作为输入。
-
根据模型类型,选择不同的方法来预测处理效应。DeepIV 需要特殊处理,因为它需要提供处理变量的基线值和目标值。
-
然后计算均方误差(MSE)、平均绝对误差(MAE)和决定系数(R²)作为评估指标。
-
最后返回一个包含评估结果的字典。如果评估过程中出现错误,会捕获异常并返回错误信息。
第六阶段:可视化模型预测与真实效应的对比
def visualize_predictions(X, true_effect, model_metrics, figsize=(14, 10)):
"""
可视化模型预测与真实效应的对比
参数:
X: 协变量
true_effect: 真实处理效应
model_metrics: 评估指标列表,每个元素是一个包含预测和指标的字典
figsize: 图像大小
"""
plt.figure(figsize=figsize) # 创建一个指定大小的图形
sns.set_style("whitegrid") # 设置图形样式为白色网格
sort_idx = np.argsort(X.flatten()) # 对协变量X进行排序,获取排序后的索引
x_sorted = X.flatten()[sort_idx] # 根据排序索引对X进行重排
true_effect_sorted = true_effect[sort_idx] # 根据排序索引对真实效应进行重排
plt.plot(x_sorted, true_effect_sorted, 'k-', linewidth=2.5, label='True Effect') # 绘制真实效应曲线
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd'] # 定义不同模型的颜色
for i, metrics inenumerate(model_metrics): # 遍历每个模型的评估指标
if"error"notin metrics: # 如果模型没有错误
pred_effect_sorted = metrics["predictions"][sort_idx] # 根据排序索引对模型预测效应进行重排
plt.plot(x_sorted, pred_effect_sorted, color=colors[i % len(colors)],
linestyle='-', linewidth=1.5,
label=f'{metrics["name"]} (MSE: {metrics.get("mse", 0):.4f})') # 绘制模型预测效应曲线
plt.title('Heterogeneous Treatment Effect Estimation', fontsize=16) # 设置图标题
plt.xlabel('Covariate X', fontsize=14) # 设置X轴标签
plt.ylabel('Treatment Effect', fontsize=14) # 设置Y轴标签
plt.legend(fontsize=12) # 显示图例
plt.grid(True, alpha=0.3) # 显示网格线,透明度为0.3
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show() # 显示图形
这个函数的目的是可视化模型预测的处理效应与真实处理效应的对比。它接受协变量 X、真实处理效应 true_effect、模型评估指标列表 model_metrics 和图像大小 figsize 作为参数。函数首先对协变量 X 和真实处理效应进行排序,然后绘制真实效应曲线。接下来,它遍历每个模型的评估指标,如果模型没有错误,就根据排序索引对模型预测效应进行重排,并绘制模型预测效应曲线。最后,函数设置图标题、坐标轴标签、图例,并显示图形。
第七阶段:可视化预测的条件平均处理效应与真实结果
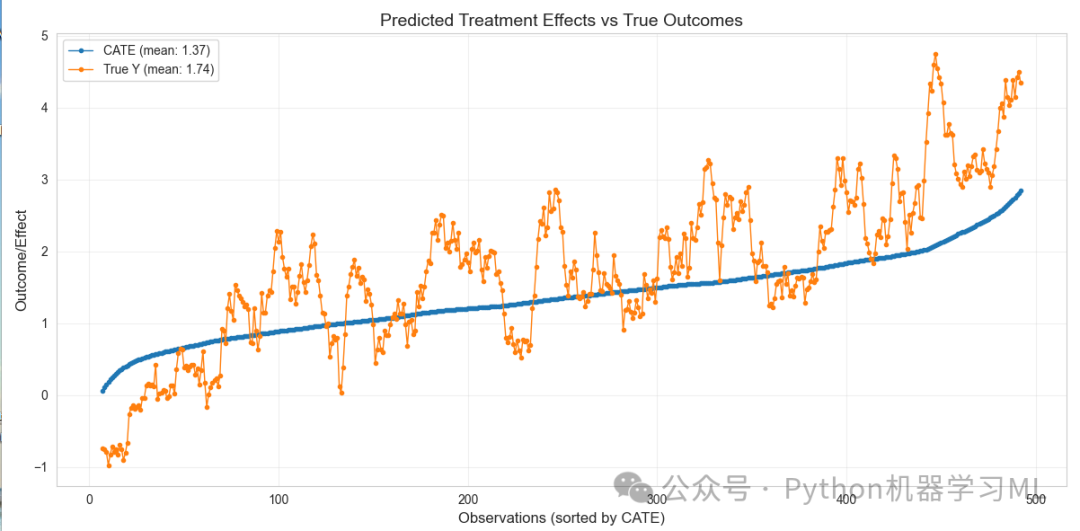
def visualize_predictions_vs_outcomes(model, T, W, Y, window_size=15):
"""
可视化预测的条件平均处理效应(CATE)与真实结果
参数:
model: 模型实例(必须有predict方法)
T: 处理变量
W: 控制变量
Y: 结果变量
window_size: 滚动窗口大小(用于平滑)
"""
try:
y_pred = model.predict(T, W) # 获取模型预测结果
df = pd.DataFrame({
'cate': y_pred.flatten(),
'true_y': Y
}) # 创建包含预测CATE和真实结果的数据框
df = df.sort_values('cate', ascending=True).reset_index(drop=True) # 按CATE对数据框进行排序,并重置索引
z = df.rolling(window=window_size, center=True).mean() # 计算滚动平均值
cate_mean = np.mean(df['cate']) # 计算CATE的均值
y_mean = np.mean(df['true_y']) # 计算真实结果的均值
plt.figure(figsize=(12, 6)) # 创建一个指定大小的图形
plt.plot(z['cate'],
marker='.', linestyle='-',
linewidth=1.0,
label=f'CATE (mean: {cate_mean:.2f})',
color='#1f77b4') # 绘制CATE曲线
plt.plot(z['true_y'],
marker='.', linestyle='-',
linewidth=1.0,
label=f'True Y (mean: {y_mean:.2f})',
color='#ff7f0e') # 绘制真实结果曲线
plt.ylabel('Outcome/Effect', fontsize=12) # 设置Y轴标签
plt.xlabel('Observations (sorted by CATE)', fontsize=12) # 设置X轴标签
plt.title('Predicted Treatment Effects vs True Outcomes', fontsize=14) # 设置图标题
plt.legend(fontsize=10) # 显示图例
plt.grid(True, alpha=0.3) # 显示网格线,透明度为0.3
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show() # 显示图形
except Exception as e:
print(f"可视化预测时出错: {str(e)}") # 捕获并打印可视化过程中的错误
这个函数的目的是可视化预测的条件平均处理效应(CATE)与真实结果的对比。它接受模型实例 model、处理变量 T、控制变量 W、结果变量 Y 和滚动窗口大小 window_size 作为参数。函数首先使用模型的 predict 方法获取预测结果,然后创建一个包含预测 CATE 和真实结果的数据框。接下来,函数按 CATE 对数据框进行排序,并计算滚动平均值。然后,函数计算 CATE 和真实结果的均值,并绘制 CATE 曲线和真实结果曲线。最后,函数设置图标题、坐标轴标签、图例,并显示图形。如果在可视化过程中发生错误,函数会捕获并打印错误信息。
第八阶段:可视化处理组和控制组的结果分布
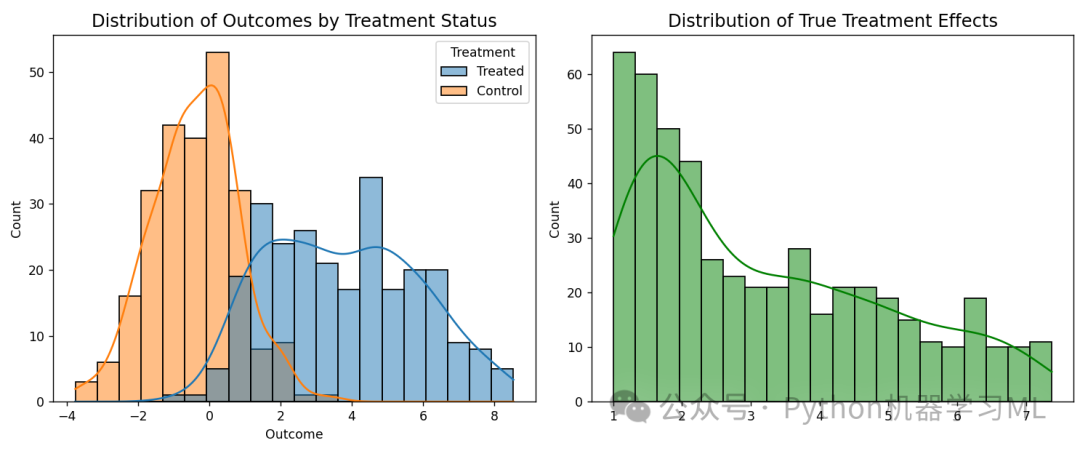
def visualize_treatment_distribution(T, Y, TE):
"""可视化处理组和控制组的结果分布"""
plt.figure(figsize=(12, 5)) # 创建一个指定大小的图形
plt.subplot(1, 2, 1) # 创建第一个子图
sns.histplot(data=pd.DataFrame({
'Treatment': ['Treated'if t == 1else'Control'for t in T],
'Outcome': Y
}), x='Outcome', hue='Treatment', kde=True, bins=20) # 绘制处理组和控制组的结果分布直方图和密度曲线
plt.title('Distribution of Outcomes by Treatment Status', fontsize=14) # 设置第一个子图的标题
plt.subplot(1, 2, 2) # 创建第二个子图
sns.histplot(TE, kde=True, bins=20, color='green') # 绘制真实处理效应的分布直方图和密度曲线
plt.title('Distribution of True Treatment Effects', fontsize=14) # 设置第二个子图的标题
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show() # 显示图形
这个函数的目的是可视化处理组和控制组的结果分布,以及真实处理效应的分布。它接受处理变量 T、结果变量 Y 和真实处理效应 TE 作为参数。函数首先创建一个包含两个子图的图形。在第一个子图中,函数使用 sns.histplot 绘制处理组和控制组的结果分布直方图和密度曲线。在第二个子图中,函数使用 sns.histplot 绘制真实处理效应的分布直方图和密度曲线。最后,函数设置子图标题,并显示图形。
第九阶段:主函数,运行完整的分析流程
def main():
"""主函数,运行完整的分析流程"""
print("=== 生成合成数据 ===")
W, X, T, Y, instrument, TE, X_test = generate_synthetic_data(n=500) # 生成合成数据,样本量为500
print(f"数据维度 - W: {W.shape}, X: {X.shape}, T: {T.shape}, Y: {Y.shape}") # 打印数据维度
print(f"处理率: {np.mean(T):.2f}") # 打印处理率
visualize_treatment_distribution(T, Y, TE) # 可视化处理分布
print("\n=== 创建因果推断模型 ===")
deepiv_model = create_deepiv_model(W.shape) # 创建DeepIV模型
dml_forest = create_dml_forest_model() # 创建CausalForestDML模型
print("\n=== 训练DeepIV模型 ===")
try:
deepiv_model.fit(Y=Y, T=T, X=W, Z=instrument) # 训练DeepIV模型
print("DeepIV模型训练完成")
except Exception as e:
print(f"DeepIV模型训练失败: {str(e)}") # 捕获并打印DeepIV模型训练过程中的错误
print("\n=== 训练CausalForestDML模型 ===")
try:
dml_forest.fit(Y=Y, T=T, X=X, W=W) # 训练CausalForestDML模型
print("CausalForestDML模型训练完成")
except Exception as e:
print(f"CausalForestDML模型训练失败: {str(e)}") # 捕获并打印CausalForestDML模型训练过程中的错误
print("\n=== 评估模型性能 ===")
metrics_list = [] # 创建一个空列表,用于存储模型评估指标
try:
deepiv_metrics = evaluate_model(deepiv_model, X, T, W, TE, "DeepIV") # 评估DeepIV模型
metrics_list.append(deepiv_metrics) # 将DeepIV模型的评估指标添加到列表中
except Exception as e:
print(f"评估DeepIV模型时出错: {str(e)}") # 捕获并打印评估DeepIV模型过程中的错误
try:
dml_forest_metrics = evaluate_model(dml_forest, X, T, W, TE, "CausalForestDML") # 评估CausalForestDML模型
metrics_list.append(dml_forest_metrics) # 将CausalForestDML模型的评估指标添加到列表中
except Exception as e:
print(f"评估CausalForestDML模型时出错: {str(e)}") # 捕获并打印评估CausalForestDML模型过程中的错误
if metrics_list: # 如果评估指标列表不为空
print("\n=== 可视化结果 ===")
visualize_predictions(X, TE, metrics_list) # 比较模型预测
try:
visualize_predictions_vs_outcomes(deepiv_model, T, W, Y) # 可视化DeepIV模型的预测vs真实结果
except Exception as e:
print(f"可视化DeepIV预测时出错: {str(e)}") # 捕获并打印可视化DeepIV预测过程中的错误
print("\n=== 分析完成 ===")
if __name__ == "__main__":
main() # 如果当前脚本作为主程序运行,则执行main函数
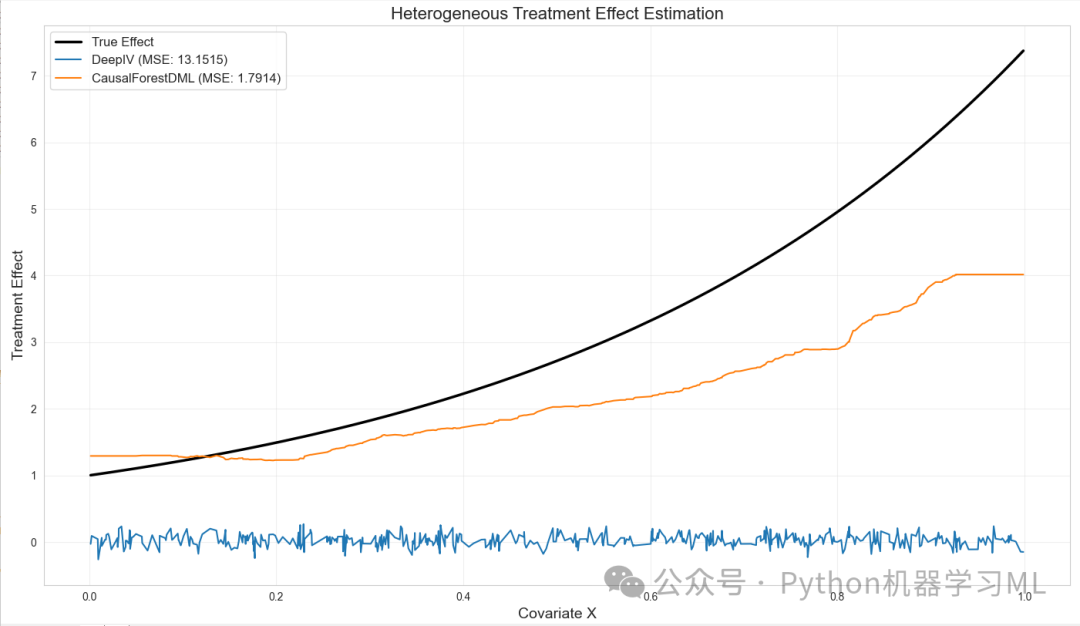
=== 评估模型性能 ===16/16 [==============================] - 0s 1ms/step16/16 [==============================] - 0s 1ms/stepDeepIV - MSE: 13.1515, MAE: 3.1542, R²: -3.1236, Time: 0.36sCausalForestDML - MSE: 1.7914, MAE: 1.0284, R²: 0.4383, Time: 0.01s项目展示了一个完整的因果推断分析流程,包括数据生成、模型创建、模型训练、模型评估和结果可视化。通过将代码分为不同的函数和阶段,可以更好地组织和理解整个分析过程。这种模块化的方法也使得将代码应用于其他数据集。