研究背景
尽管大型语言模型(LLM)展示出了显著的能力,但它们在生成回答时经常包含事实错误,因为它们仅依赖于封装在模型中的参数知识。增强型检索生成(Retrieval-Augmented Generation, RAG)是一种方法,通过检索相关知识来减少此类问题。然而,无论是否需要检索,或检索的段落是否相关,不加选择地检索和整合固定数量的检索段落会降低语言模型的多功能性,或可能导致生成无用的回答。
研究目标
介绍了自反式增强型检索生成(Self-Reflective Retrieval-Augmented Generation, SELF-RAG)框架,旨在通过检索和自我反思提高语言模型的质量和事实性,训练一个可以根据需求适应性检索段落的模型,并通过生成特殊的反思标记来反思检索到的段落及其自身的生成内容。
相关工作
传统的RAG方法可能会妨碍LLM的多功能性或引入不必要或偏题的段落,导致生成质量低下。此外,输出并不保证与检索到的相关段落一致,因为这些模型并未明确训练以利用并遵循提供的段落中的事实。
方法论
数据处理
四种反思tokens的类型:

Retrieve:这是一个决策过程,它决定了是否从某个资源 R 中检索信息。
IsREL:这是一个相关性检查,目的是确定给定的数据 d 是否包含解决问题 x 所需的相关信息。
IsSUP:这是一个验证过程,用于检查提供的响应 y 中的声明是否得到了数据 d 的支持。
IsUSE:这是一个评估过程,旨在评估给定的响应 y 对于问题 x 有多么有用。输出是一个从1到5的评分,5分代表最有用。
数据样例如下:
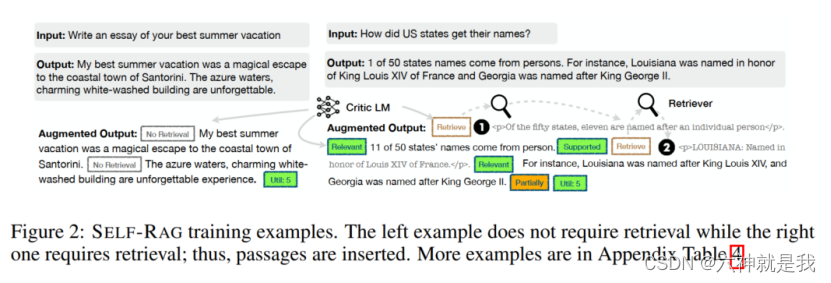
这个框架主要需要训练2个模型,一个评判家模型(critic model),一个生成模型(generator model)。
解决方案
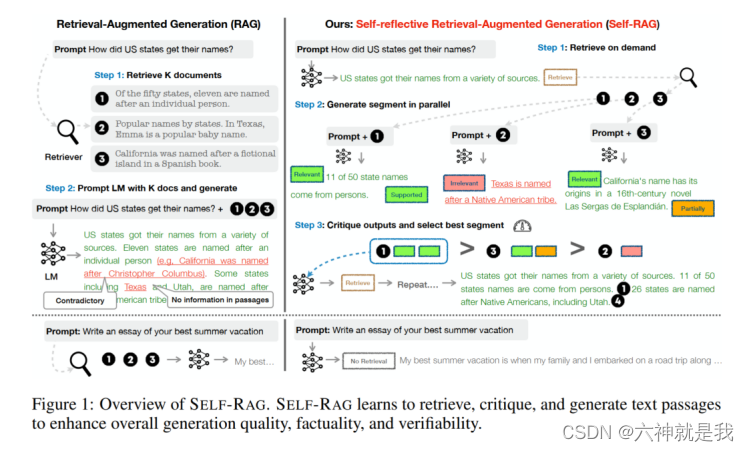
SELF-RAG首先会判断通过检索段落来增强生成会有帮助。如果是,它输出一个检索标记,按需调用检索模型(步骤1)。然后,SELF-RAG同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤2)。接着,它依据事实性和总体质量生成批评标记以批评其自身的输出并选择最佳输出(步骤3)。
实验
实验设计
实验设计包括使用7B和13B参数的SELF-RAG模型,在多样化的任务集上进行测试,以展示其在开放领域问答、推理和事实验证任务上的表现。像事实验证和多项选择推理等闭集任务,使用准确性作为评估指标。对于开放域问答这样简短的生成任务,作者使用groundtruth答案是否包含在模型生成中来进行评估,而不是严格要求精确匹配。
对于传记生成和长格式QA等长文本生成任务,作者使用FactScore(https://github.com/shmsw25/FActScore)来评估传记------基本上是对生成的各种信息及其事实正确性的衡量。对于长格式QA,使用了引用精度和召回率。
实验结论
ELF-RAG在所有测试任务中显著优于现有的最先进的LLM和增强型检索模型。特别是在提高长文本生成的事实性和引用准确性 方面,与其他模型相比,显示出显著的优势。
