专栏:数学建模学习笔记
目录
第一阶段:基础知识和工具
1.Python基础
掌握Python基础是进行数学建模的第一步。Python的易用性和丰富的库使其成为数据科学和数学建模的理想选择。
1.学习内容
1.基本语法
变量和数据类型 :学习如何声明变量以及不同的数据类型(整数int,浮点数float,字符串str,列表list,元组tuple,字典dict,集合set)。
a = 10 # 整数
b = 3.14 # 浮点数
c = "Hello, World!" # 字符串
d = [1, 2, 3] # 列表
e = (1, 2, 3) # 元组
f = {"name": "Alice", "age": 25} # 字典
g = {1, 2, 3} # 集合运算符:熟悉算术运算符(+,-,*,/),比较运算符(==,!=,>,<,>=,<=),逻辑运算符(and,or,not)。
# 算术运算符
print(a + b) # 13.14
print(a * b) # 31.4
# 比较运算符
print(a == b) # False
print(a > b) # True
# 逻辑运算符
print(a > 5 and b < 5) # True
print(not (a > 5)) # False控制结构:掌握条件语句(if,elif,else)和循环语句(for,while)。
if a > b:
print("a is greater than b")
else:
print("a is not greater than b")
for i in range(5):
print(i)
count = 0
while count < 5:
print(count)
count += 12.函数和模块
-
自定义函数:学会定义函数,传递参数和返回值。
def add(x, y): return x + y result = add(10, 5) print(result) # 15内置函数 :使用Python提供的内置函数,如
len(),sum(),max(),min()等。my_list = [1, 2, 3, 4, 5] print(len(my_list)) # 5 print(sum(my_list)) # 15 print(max(my_list)) # 5 print(min(my_list)) # 1模块的导入和使用 :学习如何导入和使用模块,例如
math模块。import math print(math.sqrt(16)) # 4.0 print(math.pi) # 3.1415926535897933.面向对象编程
-
类和对象:学习如何定义类和创建对象。
class Person: def __init__(self, name, age): self.name = name self.age = age def greet(self): print(f"Hello, my name is {self.name} and I am {self.age} years old.") person = Person("Alice", 25) person.greet() # Hello, my name is Alice and I am 25 years old.继承和多态:理解类的继承机制和多态性。
class Animal: def __init__(self, name): self.name = name def speak(self): pass class Dog(Animal): def speak(self): return "Woof" class Cat(Animal): def speak(self): return "Meow" animals = [Dog("Fido"), Cat("Whiskers")] for animal in animals: print(f"{animal.name} says {animal.speak()}") # Fido says Woof # Whiskers says Meow4.文件操作
-
文件的读写:学习如何读取和写入文本文件及CSV文件。
# 写入文件 with open("example.txt", "w") as file: file.write("Hello, World!") # 读取文件 with open("example.txt", "r") as file: content = file.read() print(content) # Hello, World!异常处理:掌握如何处理程序运行中的异常。
try: result = 10 / 0 except ZeroDivisionError: print("Cannot divide by zero") finally: print("Execution finished")2.推荐资源
书籍:
- 《Python编程:从入门到实践》:这本书由Eric Matthes编写,覆盖了Python编程的基础知识和实际项目,非常适合初学者。
- 《Python基础教程》:Mark Lutz编写的这本书详细介绍了Python的核心概念和编程实践。
在线课程:
- Codecademy的Python课程:提供交互式的编程练习,适合零基础入门。
- Coursera上的"Python for Everybody"系列课程:由密歇根大学提供,讲师Charles Severance详细讲解了Python基础。
在线教程:
- W3Schools的Python教程:提供简洁明了的Python语法和示例。
- GeeksforGeeks的Python教程:涵盖了从基础到高级的Python编程知识,适合系统学习。
2.数学基础
扎实的数学基础是进行数学建模的基石。以下是需要掌握的数学知识:
1.学习内容
1.高等数学
微积分:
微分:学习导数的定义、求导法则、函数的微分应用(如极值问题、最速下降法)。
import sympy as sp
x = sp.symbols('x')
f = x**3 + 2*x**2 + x
f_prime = sp.diff(f, x)
print(f_prime) # 3*x**2 + 4*x + 1积分:理解定积分和不定积分的概念,以及如何进行积分运算。
F = sp.integrate(f, x)
print(F) # x**4/4 + 2*x**3/3 + x**2/2函数和极限:
-
学习函数的定义和各种类型的函数(如多项式函数、指数函数、对数函数)。
-
理解极限的概念及其在分析中的应用
limit_value = sp.limit(f/x, x, sp.oo) print(limit_value) # 1函数和极限:
-
学习函数的定义和各种类型的函数(如多项式函数、指数函数、对数函数)。
-
理解极限的概念及其在分析中的应用。
limit_value = sp.limit(f/x, x, sp.oo) print(limit_value) # 1数列和级数:
-
学习数列的定义及其基本性质。
-
理解级数的概念,特别是收敛和发散。
n = sp.symbols('n') series_sum = sp.Sum(1/n**2, (n, 1, sp.oo)).doit() print(series_sum) # pi**2/62.线性代数
b = sp.Matrix([5, 11]) x = A.LUsolve(b) print(x) # Matrix([[1], [2]])
矩阵和向量:
-
学习矩阵和向量的基本运算(如加法、乘法、转置)。
-
理解矩阵的逆、行列式和特征值。
A = sp.Matrix([[1, 2], [3, 4]]) A_inv = A.inv() print(A_inv) # Matrix([[-2, 1], [3/2, -1/2]])线性方程组:
-
学习如何使用矩阵求解线性方程组。
b = sp.Matrix([5, 11]) x = A.LUsolve(b) print(x) # Matrix([[1], [2]])特征值和特征向量:
-
理解特征值和特征向量的定义及其计算方法。
eigenvals = A.eigenvals() eigenvects = A.eigenvects() print(eigenvals) # {5: 1, -1: 1} print(eigenvects)3.概率论与数理统计
概率基础:
学习概率的基本概念和规则(如概率分布、条件概率、独立性)
from sympy import FiniteSet
outcomes = FiniteSet(1, 2, 3, 4, 5, 6)
event = FiniteSet(2, 4, 6)
probability = len(event) / len(outcomes)
print(probability) # 0.5随机变量和分布:
理解随机变量的概念和常见的概率分布(如正态分布、二项分布)。
from scipy.stats import norm
mean, std_dev = 0, 1
probability = norm.cdf(1) - norm.cdf(-1)
print(probability) # 0.6826894921370859统计推断:
-
学习假设检验、置信区间等统计推断方法。
import numpy as np data = np.random.normal(mean, std_dev, 100) conf_interval = np.percentile(data, [2.5, 97.5]) print(conf_interval)2.推荐教材
-
《高等数学》:教材详细介绍了微积分和高等数学的基本概念和应用。
-
《线性代数》:涵盖了矩阵、向量和线性方程组的基础知识。
-
《概率论与数理统计》:提供了概率论和统计推断的基本理论和应用。
2.常用Python库
熟练使用Python中的几个重要库可以大大简化数值计算、数据处理和可视化的过程。
1.学习内容
1.NumPy
-
数组和矩阵操作:
-
学习如何创建和操作NumPy数组和矩阵。
import numpy as np a = np.array([1, 2, 3]) b = np.array([[1, 2], [3, 4]]) print(a + 1) # [2 3 4] print(b.T) # [[1 3] [2 4]]数学函数和随机数生成:
-
使用NumPy进行常用的数学运算和生成随机数。
c = np.sin(a) d = np.random.normal(0, 1, 1000) print(c) print(d.mean(), d.std())线性代数运算:
-
进行矩阵乘法、求逆、特征值计算等线性代数运算。
e = np.linalg.inv(b) f = np.dot(b, e) print(f) # [[1 0] [0 1]]2.Pandas
-
数据结构:
-
学习Pandas中的基本数据结构:Series和DataFrame。
import pandas as pd s = pd.Series([1, 2, 3]) df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) print(s) print(df)数据导入和导出:
-
学习如何读取和写入CSV文件及其他格式的数据文件。
df.to_csv('example.csv', index=False) df_read = pd.read_csv('example.csv') print(df_read)数据清洗和处理:
-
使用Pandas进行数据清洗和处理操作,如缺失值处理、数据筛选和排序。
df['C'] = df['A'] + df['B'] df_cleaned = df.dropna() df_sorted = df.sort_values(by='C') print(df_cleaned) print(df_sorted)3.Matplotlib和Seaborn
-
基本图形绘制:
-
使用Matplotlib绘制基本图形,如折线图、柱状图、散点图。
import matplotlib.pyplot as plt plt.plot(a) plt.bar(range(len(a)), a) plt.scatter(a, c) plt.show()高级绘图:
-
使用Seaborn进行高级数据可视化,如热力图、分布图。
import seaborn as sns sns.heatmap(df.corr(), annot=True) sns.distplot(d) plt.show()2.推荐资源
书籍:
- 《Python数据分析》:Wes McKinney编写,详细介绍了Pandas的使用。
- 《利用Python进行数据分析》:Wes McKinney编写,涵盖了Pandas和NumPy的基础和进阶使用。
在线课程:
- Coursera的"Data Analysis with Python"课程:提供全面的数据分析教程。
- edX的"Analyzing Data with Python"课程:深入讲解数据分析的各个方面。
在线教程:
- 官方文档:NumPy、Pandas、Matplotlib和Seaborn的官方文档是学习这些库的最佳资源。
- GeeksforGeeks:提供了从基础到高级的详细教程。
-
-
-
第二阶段:数学建模基础
数学建模入门
在具备了基本的编程和数学知识后,可以开始接触数学建模的基本概念和方法。
学习内容
数学建模概念
什么是数学建模:
数学建模是利用数学工具和方法对实际问题进行描述、分析和求解的过程。
数学模型通过对实际问题进行抽象和简化,建立数学表达式或方程来描述问题。
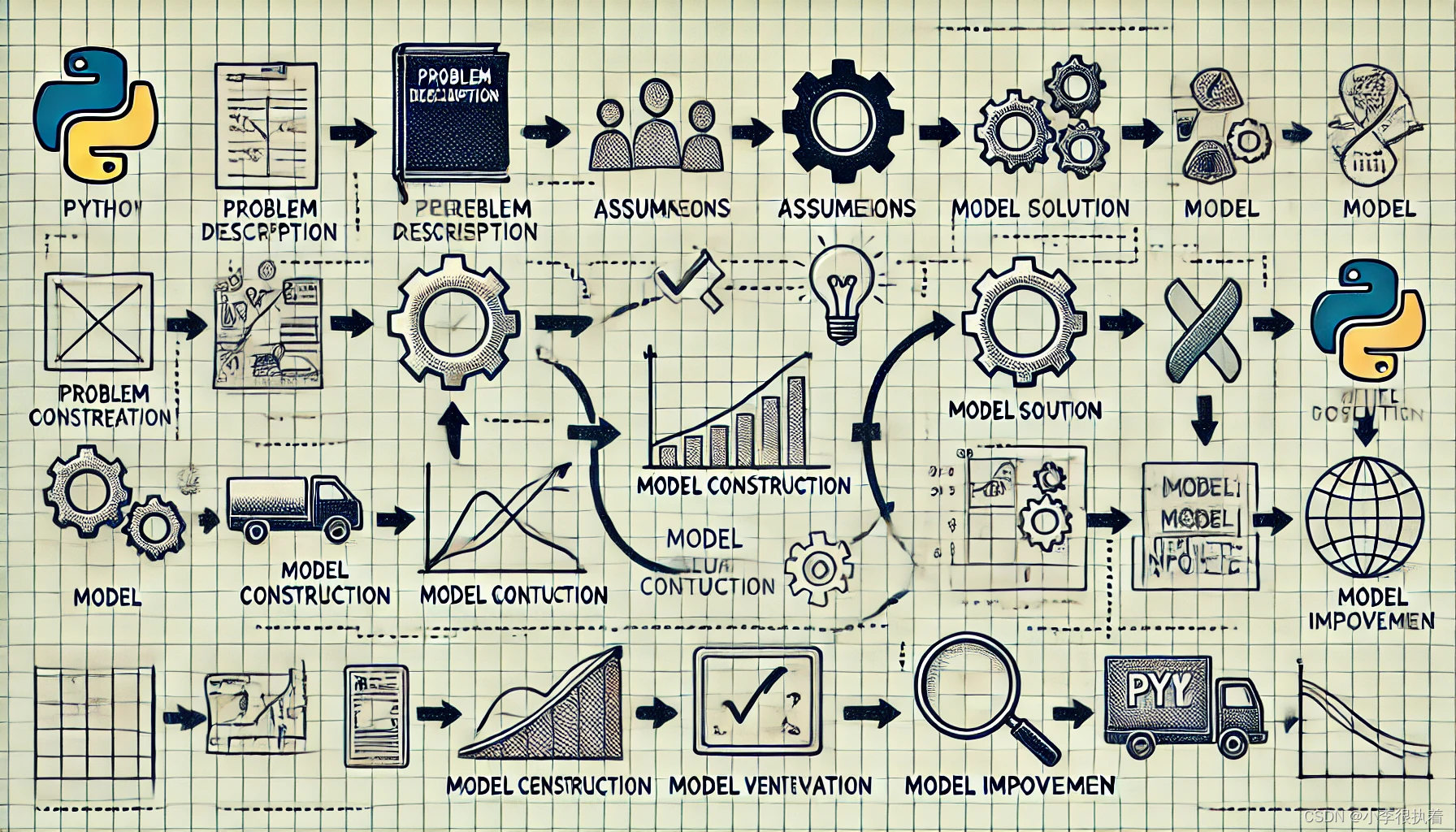
数学建模的基本步骤:
- 问题描述:明确要解决的问题,收集相关信息和数据。
- 假设条件:对实际问题进行合理的简化和假设,以便建立模型。
- 模型构建:根据假设条件,建立数学模型,如方程、函数、关系式等。
- 求解模型:利用数学方法或计算工具求解模型,得到结果。
- 模型验证:将模型结果与实际情况进行比较,验证模型的有效性。
- 模型改进:根据验证结果,修正假设和模型,进一步优化模型。
经典数学模型
优化问题:
线性规划:求解线性约束条件下的最优化问题。
from scipy.optimize import linprog
c = [-1, -2]
A = [[2, 1], [1, 2]]
b = [20, 20]
x0_bounds = (0, None)
x1_bounds = (0, None)
result = linprog(c, A_ub=A, b_ub=b, bounds=[x0_bounds, x1_bounds])
print(result)整数规划:线性规划的整数解形式,常用于资源分配和调度问题。
from scipy.optimize import linprog
c = [-1, -2]
A = [[2, 1], [1, 2]]
b = [20, 20]
x0_bounds = (0, None)
x1_bounds = (0, None)
result = linprog(c, A_ub=A, b_ub=b, bounds=[x0_bounds, x1_bounds], method='simplex')
print(result)回归分析:
线性回归:用于预测连续型变量,假设因变量与自变量之间存在线性关系。
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 3, 5, 7, 9])
model = LinearRegression().fit(X, y)
predictions = model.predict(X)
print(predictions)多项式回归:适用于因变量与自变量之间存在非线性关系的情况。
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
model_poly = LinearRegression().fit(X_poly, y)
predictions_poly = model_poly.predict(X_poly)
print(predictions_poly)时间序列分析:
-
ARIMA模型 :用于预测时间序列数据,结合了自回归、差分和移动平均成分
from statsmodels.tsa.arima.model import ARIMA model_arima = ARIMA(y, order=(1, 1, 1)) result_arima = model_arima.fit() predictions_arima = result_arima.forecast(steps=5) print(predictions_arima)推荐书籍和课程
书籍:
- 《数学建模(原书第5版)》:Steven C. Chapra和Raymond P. Canale编写,详细介绍了数学建模的基本原理和应用。
- 《运筹学》:涵盖了线性规划、整数规划等优化方法。
在线课程:
- Coursera的"Mathematical Modeling Basics"课程:由荷兰代尔夫特理工大学提供,介绍了数学建模的基础知识。
- edX的"Introduction to Mathematical Modeling"课程:由麻省理工学院提供,详细讲解了数学建模的基本方法。
2.编程实现
用Python实现简单的数学模型是从理论到实践的重要一步。
学习内容
线性回归模型
数据预处理:
对数据进行预处理,包括数据清洗、特征选择和数据标准化。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)模型训练和预测:
使用线性回归模型进行训练和预测。
model = LinearRegression().fit(X_scaled, y)
predictions = model.predict(X_scaled)模型评估:
使用均方误差(MSE)、决定系数(R^2)等指标评估模型性能。
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y, predictions)
r2 = r2_score(y, predictions)
print(f"MSE: {mse}, R^2: {r2}")多项式回归模型
多项式特征生成:
使用PolynomialFeatures生成多项式特征。
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)模型训练和预测:
-
使用多项式回归模型进行训练和预测。
model_poly = LinearRegression().fit(X_poly, y) predictions_poly = model_poly.predict(X_poly)模型评估和选择:
-
比较多项式回归模型与线性回归模型的性能,选择最佳模型。
mse_poly = mean_squared_error(y, predictions_poly) r2_poly = r2_score(y, predictions_poly) print(f"Polynomial Regression - MSE: {mse_poly}, R^2: {r2_poly}")实践练习
利用Python库实现上述模型:
使用scikit-learn库实现线性回归和多项式回归模型,掌握从数据导入、清洗、建模到结果分析的完整流程。
第三阶段:进阶学习

优化方法
优化方法是数学建模的重要工具,涉及如何找到最优解或最优策略。
学习内容
线性规划
-
线性规划的基本概念和标准形式:
- 理解线性规划问题的定义、目标函数、约束条件。
- 学习如何将实际问题转化为线性规划问题。
-
单纯形法和对偶理论:
- 学习单纯形法的基本原理和算法步骤。
- 理解对偶理论及其在求解线性规划问题中的应用。
-
非线性规划
-
非线性规划的基本概念:
- 理解非线性规划问题的定义、目标函数、约束条件。
- 学习常见的非线性规划问题及其应用场景。
-
常用算法:
-
梯度下降法:用于求解无约束优化问题,通过迭代逼近最优解。
import numpy as np def gradient_descent(f, grad_f, x0, learning_rate, max_iter): x = x0 for _ in range(max_iter): x = x - learning_rate * grad_f(x) return x牛顿法:用于求解无约束优化问题,通过二阶导数加速收敛。
def newton_method(f, grad_f, hessian_f, x0, max_iter): x = x0 for _ in range(max_iter): H_inv = np.linalg.inv(hessian_f(x)) x = x - H_inv @ grad_f(x) return x推荐书籍
-
《运筹学》:详细介绍了线性规划、非线性规划等优化方法及其应用。
-
《线性规划与网络流》:深入讲解了线性规划和网络流问题的理论和算法。
-
-
机器学习基础
机器学习是数学建模的一个重要方向,尤其在数据驱动的建模中,机器学习方法发挥了巨大作用。
学习内容
监督学习
回归算法:
线性回归:学习线性回归的原理和实现方法。
from sklearn.linear_model import LinearRegression
model = LinearRegression().fit(X, y)
predictions = model.predict(X)岭回归:学习如何通过正则化防止过拟合。
from sklearn.linear_model import Ridge
model_ridge = Ridge(alpha=1.0).fit(X, y)
predictions_ridge = model_ridge.predict(X)Lasso回归:学习Lasso回归的原理和实现方法。
from sklearn.linear_model import Lasso
model_lasso = Lasso(alpha=0.1).fit(X, y)
predictions_lasso = model_lasso.predict(X)分类算法:
-
决策树:学习决策树算法的原理和实现方法。
from sklearn.tree import DecisionTreeClassifier model_tree = DecisionTreeClassifier().fit(X, y) predictions_tree = model_tree.predict(X)支持向量机:学习SVM算法的原理和实现方法。
from sklearn.svm import SVC model_svm = SVC(kernel='linear').fit(X, y) predictions_svm = model_svm.predict(X)K近邻:学习KNN算法的原理和实现方法。
from sklearn.neighbors import KNeighborsClassifier model_knn = KNeighborsClassifier(n_neighbors=3).fit(X, y) predictions_knn = model_knn.predict(X)无监督学习
-
聚类算法:
-
K均值聚类:学习K-means算法的原理和实现方法。
from sklearn.cluster import KMeans model_kmeans = KMeans(n_clusters=3).fit(X) predictions_kmeans = model_kmeans.predict(X)层次聚类:学习层次聚类算法的原理和实现方法。
from scipy.cluster.hierarchy import dendrogram, linkage Z = linkage(X, 'ward') dendrogram(Z) plt.show()降维方法:
-
主成分分析(PCA):学习PCA的原理和实现方法。
from sklearn.decomposition import PCA model_pca = PCA(n_components=2).fit(X) X_pca = model_pca.transform(X)t-SNE:学习t-SNE的原理和实现方法。
from sklearn.manifold import TSNE X_tsne = TSNE(n_components=2).fit_transform(X)推荐资源
书籍:
- 《统计学习方法》:李航编写,系统介绍了机器学习的基本算法和理论。
- 《机器学习实战》:Peter Harrington编写,提供了丰富的实际案例和代码示例。
在线课程:
- Coursera的"Machine Learning"课程:由斯坦福大学提供,Andrew Ng教授讲解,覆盖了机器学习的核心内容。
- Udacity的"Intro to Machine Learning"课程:提供了丰富的实践练习和项目。
项目实践
项目实践是将所学知识应用到实际问题中的重要环节。通过项目可以锻炼解决实际问题的能力。
实践内容
-
选择实际问题
- 预测股市价格:利用历史数据构建模型,预测未来的股市价格。
- 优化生产调度:利用线性规划和整数规划优化生产计划,提高效率。
- 分析社交网络:利用图论和机器学习分析社交网络中的用户行为和关系。
-
项目流程
- 问题描述和数据收集:明确问题和目标,收集相关数据。
- 数据预处理和特征工程:对数据进行清洗、处理和特征提取。
- 模型选择和训练:选择合适的模型,进行训练和调参。
- 模型评估和优化:使用各种指标评估模型性能,并进行优化。
- 结果分析和报告撰写:分析模型结果,撰写详细的项目报告。
实践平台
- Kaggle:数据科学竞赛平台,提供丰富的数据集和竞赛题目。
- 天池:阿里云的人工智能竞赛平台,有很多有趣的竞赛和项目。
-
第四阶段:专业提升
高级算法和模型
掌握高级算法和模型是迈向专家级别的必经之路。这些方法通常应用于复杂问题和前沿研究。
学习内容
-
深度学习
-
深度神经网络(DNN):
-
学习DNN的基本结构和原理。
-
了解常见的激活函数(如ReLU、Sigmoid、Tanh)和损失函数。
from keras.models import Sequential from keras.layers import Dense model_dnn = Sequential() model_dnn.add(Dense(units=64, activation='relu', input_dim=100)) model_dnn.add(Dense(units=10, activation='softmax')) model_dnn.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])卷积神经网络(CNN):
-
学习CNN的基本结构和原理,了解卷积层、池化层和全连接层。
from keras.layers import Conv2D, MaxPooling2D, Flatten model_cnn = Sequential() model_cnn.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3))) model_cnn.add(MaxPooling2D(pool_size=(2, 2))) model_cnn.add(Flatten()) model_cnn.add(Dense(units=128, activation='relu')) model_cnn.add(Dense(units=1, activation='sigmoid')) model_cnn.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])循环神经网络(RNN):
-
学习RNN的基本结构和原理,了解LSTM和GRU等变体。
from keras.layers import SimpleRNN, LSTM model_rnn = Sequential() model_rnn.add(LSTM(units=50, return_sequences=True, input_shape=(10, 1))) model_rnn.add(LSTM(units=50)) model_rnn.add(Dense(units=1)) model_rnn.compile(optimizer='adam', loss='mean_squared_error')强化学习
-
基本概念:
- 理解强化学习的基本概念,如马尔可夫决策过程(MDP)、状态、动作、奖励、价值函数。
- 学习强化学习的框架和工作流程。
-
算法:
-
Q-learning:学习Q-learning算法的原理和实现方法。
import numpy as np def q_learning(env, num_episodes, alpha, gamma, epsilon): Q = np.zeros((env.observation_space.n, env.action_space.n)) for i in range(num_episodes): state = env.reset() done = False while not done: if np.random.rand() < epsilon: action = env.action_space.sample() else: action = np.argmax(Q[state, :]) next_state, reward, done, _ = env.step(action) Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[state, action]) state = next_state return Q深度Q网络(DQN):学习DQN的原理和实现方法,结合深度学习进行策略优化。
import keras from keras.models import Sequential from keras.layers import Dense model_dqn = Sequential() model_dqn.add(Dense(units=24, activation='relu', input_dim=env.observation_space.shape[0])) model_dqn.add(Dense(units=24, activation='relu')) model_dqn.add(Dense(units=env.action_space.n, activation='linear')) model_dqn.compile(loss='mse', optimizer=keras.optimizers.Adam(lr=0.001))推荐资源
-
书籍 :
- 《深度学习(Goodfellow)》:Ian Goodfellow编写,全面介绍了深度学习的基础理论和实践方法。
- 《强化学习(Sutton)》:Richard S. Sutton和Andrew G. Barto编写,详细讲解了强化学习的基本原理和算法。
-
-
-
科学计算和仿真
科学计算和仿真是解决复杂问题的重要工具,常用于物理、工程和经济等领域。
学习内容
-
蒙特卡洛仿真
-
基本原理 :理解蒙特卡洛仿真的基本思想,通过随机数生成和概率统计模拟复杂系统
import numpy as np def monte_carlo_simulation(num_simulations, num_steps): results = [] for _ in range(num_simulations): position = 0 for _ in range(num_steps): position += np.random.choice([-1, 1]) results.append(position) return np.mean(results), np.std(results) mean, std = monte_carlo_simulation(1000, 100) print(mean, std)元胞自动机
-
基本原理 :学习元胞自动机的定义和基本规则,理解其在复杂系统建模中的应用。
import numpy as np def game_of_life(initial_state, num_generations): state = np.copy(initial_state) for _ in range(num_generations): new_state = np.copy(state) for i in range(1, state.shape[0] - 1): for j in range(1, state.shape[1] - 1): num_neighbors = np.sum(state[i-1:i+2, j-1:j+2]) - state[i, j] if state[i, j] == 1 and (num_neighbors < 2 or num_neighbors > 3): new_state[i, j] = 0 elif state[i, j] == 0 and num_neighbors == 3: new_state[i, j] = 1 state = new_state return state数值方法
-
微分方程数值解 :学习常微分方程和偏微分方程的数值解法,如欧拉法、龙格-库塔法。
from scipy.integrate import odeint def model(y, t): dydt = -0.5 * y return dydt y0 = 5 t = np.linspace(0, 10, 100) y = odeint(model, y0, t) plt.plot(t, y) plt.xlabel('time') plt.ylabel('y(t)') plt.show()推荐书籍
-
《科学计算与仿真》:介绍了科学计算的基本方法和仿真技术。
-
《数值分析》:详细讲解了数值方法及其在科学计算中的应用。
-
学术研究
学术研究是深入理解数学建模和优化方法的重要途径,通过阅读和撰写学术论文可以了解领域的最新进展。
学习内容
-
阅读学术论文
- 选择合适的论文:在Google Scholar、arXiv等平台上查找相关领域的学术论文。
- 批判性阅读:阅读论文时,重点关注问题的提出、方法的应用、结果的分析和结论的提炼。
-
撰写学术论文
- 选题和文献综述:选择研究方向,进行相关文献的综述。
- 研究方法和实验设计:详细描述研究方法和实验设计,包括数据收集、模型构建和结果分析。
- 论文写作和发表:按照学术规范撰写论文,选择合适的期刊或会议进行投稿。
推荐资源
- Google Scholar:学术搜索引擎,提供丰富的学术论文资源。
- arXiv:预印本论文存档,涵盖了物理、数学、计算机科学等多个领域。
实践经验和竞赛
多参加数学建模竞赛,如全国大学生数学建模竞赛、美赛等,通过竞赛积累经验,提升实战能力。
竞赛内容
-
全国大学生数学建模竞赛
- 竞赛形式:每年9月举行,持续3天,参赛队伍需要在规定时间内完成数学建模论文。
- 竞赛题目:题目涉及实际问题,要求参赛队伍运用数学建模方法进行分析和求解。
-
美赛(Mathematical Contest in Modeling, MCM)
- 竞赛形式:每年2月举行,持续4天,参赛队伍需要在规定时间内完成数学建模论文。
- 竞赛题目:题目涉及实际问题,要求参赛队伍运用数学建模方法进行分析和求解。
竞赛准备
- 团队组建:选择合适的队友,分工明确,充分发挥团队优势。
- 题目选择:根据自身优势和兴趣选择竞赛题目,合理分配时间和任务。
- 文献查找:利用各种资源查找相关文献,了解问题背景和现有研究成果。
- 模型构建和求解:运用所学知识构建模型,利用编程工具进行求解和验证。
- 论文撰写和修改:按照竞赛要求撰写论文,重点突出模型的创新点和实际应用价值,反复修改和润色。
总结
通过详细的学习和实践路线,初学者可以逐步提升Python数学建模的能力,最终在相关竞赛中取得优异成绩。整个过程可以分为以下四个阶段:
第一阶段:基础知识和工具
- Python基础:掌握Python的基本语法、数据类型、控制结构、函数和模块、面向对象编程、文件操作等内容。推荐学习资源包括《Python编程:从入门到实践》和Codecademy的Python课程。
- 数学基础:复习高等数学、线性代数、概率论与数理统计等课程。推荐教材有《高等数学》、《线性代数》和《概率论与数理统计》。
- 常用Python库:熟练使用NumPy、Pandas、Matplotlib和Seaborn等库进行数值计算、数据处理和可视化。推荐学习资源包括《Python数据分析》和官方文档。
第二阶段:数学建模基础
- 数学建模入门:了解数学建模的基本概念和步骤,学习经典数学模型如优化问题(线性规划、整数规划)、回归分析(线性回归、多项式回归)和时间序列分析(ARIMA模型)。推荐书籍包括《数学建模(原书第5版)》和《运筹学》。
- 编程实现:用Python实现简单的数学模型,如线性回归和多项式回归。通过数据预处理、模型训练、预测和评估,掌握从理论到实践的完整流程。
第三阶段:进阶学习
- 优化方法:学习线性规划和非线性规划的基本概念和常用算法,如单纯形法、梯度下降法和牛顿法。推荐书籍有《运筹学》和《线性规划与网络流》。
- 机器学习基础:掌握监督学习和无监督学习的基本算法,如线性回归、决策树、支持向量机、K均值聚类和主成分分析。推荐学习资源包括《统计学习方法》和Coursera的"Machine Learning"课程。
- 项目实践:选择实际问题进行建模,通过项目锻炼解决实际问题的能力。推荐实践平台包括Kaggle和天池。
第四阶段:专业提升
- 高级算法和模型:学习深度学习(如DNN、CNN、RNN)和强化学习(如Q-learning、DQN)的原理和实现方法。推荐书籍有《深度学习(Goodfellow)》和《强化学习(Sutton)》。
- 科学计算和仿真:掌握蒙特卡洛仿真、元胞自动机和数值方法的基本原理和应用。推荐书籍有《科学计算与仿真》和《数值分析》。
- 学术研究:通过阅读和撰写学术论文,了解数学建模领域的最新进展和研究方向。推荐资源包括Google Scholar和arXiv。
实践经验和竞赛
多参加数学建模竞赛,如全国大学生数学建模竞赛和美赛,通过竞赛积累经验,提升实战能力。竞赛准备包括团队组建、题目选择、文献查找、模型构建和求解、论文撰写和修改等步骤。
通过系统的学习和实践,你可以逐步提升数学建模能力,最终在相关竞赛中取得优异成绩,实现从初学者到专家的飞跃。