1、VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
中文标题:VideoGPT+:集成图像和视频编码器以增强视频理解
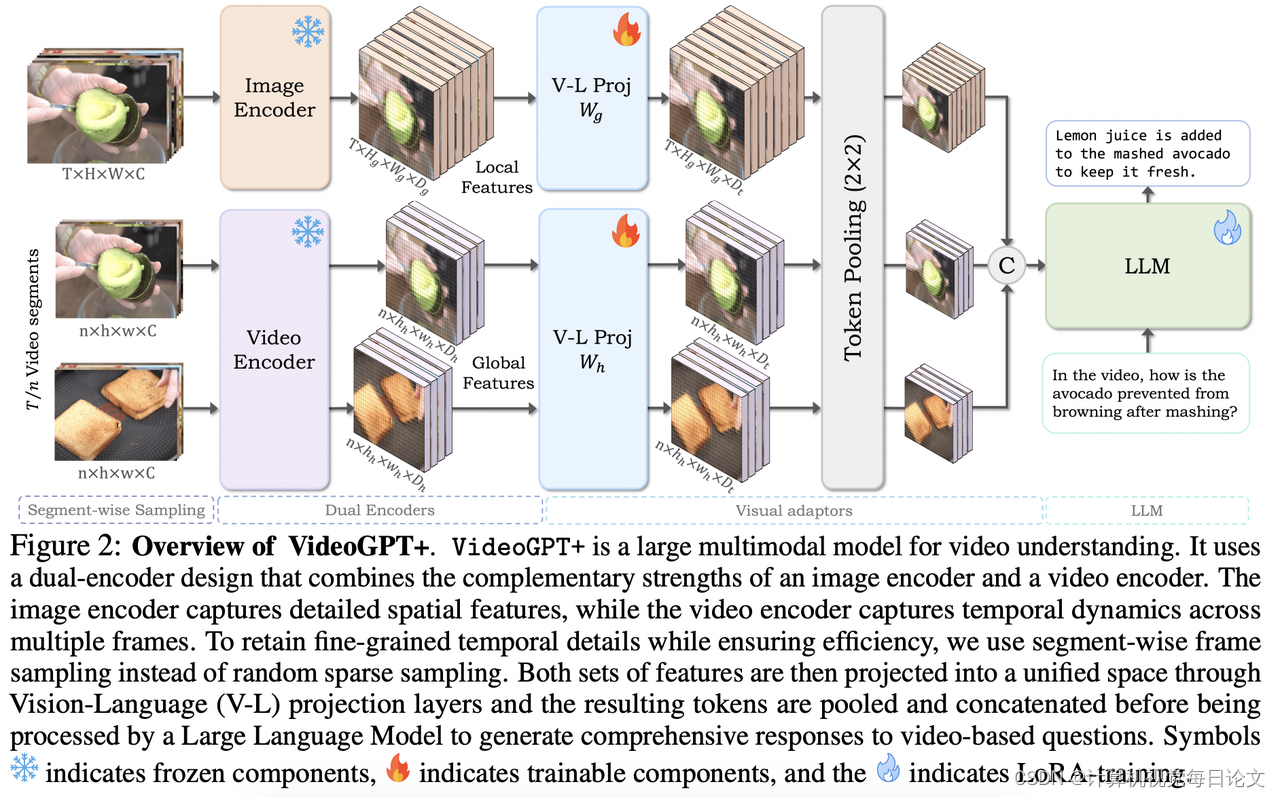

简介:该文章讨论了基于语言模型的进展如何为视频理解做出重要贡献。
尽管当前的视频大型多模态模型(LMM)利用了先进的大型语言模型(LLM),但它们依赖于图像或视频编码器来处理视觉输入,每个编码器都有其自身的局限性。图像编码器擅长从帧序列中捕捉丰富的空间细节,但缺乏明确的时间上下文;而视频编码器提供时间上下文,但受到计算限制的影响,只处理低分辨率的稀疏帧,从而降低了上下文和空间理解能力。
为此,作者提出了VideoGPT+,它结合了图像编码器(用于详细的空间理解)和视频编码器(用于全局时间上下文建模)的互补优势。该模型通过将视频分成较小的片段并在图像和视频编码器提取的特征上应用自适应池化策略来处理视频。实验结果表明,该模型在多个视频基准测试中都有显著的性能提升。
此外,作者使用一种新颖的半自动注释管道开发了112K个视频指令集,进一步提高了模型性能。为了全面评估视频LMM,作者还提出了VCGBench-Diverse基准测试,涵盖18个广泛的视频类别,以确保在不同的视频类型和动态下进行全面评估。
代码可在https://github.com/mbzuai-oryx/VideoGPT-plus获得。
2、Vision-LSTM: xLSTM as Generic Vision Backbone
中文标题:Vision-LSTM:xLSTM 作为通用视觉主干
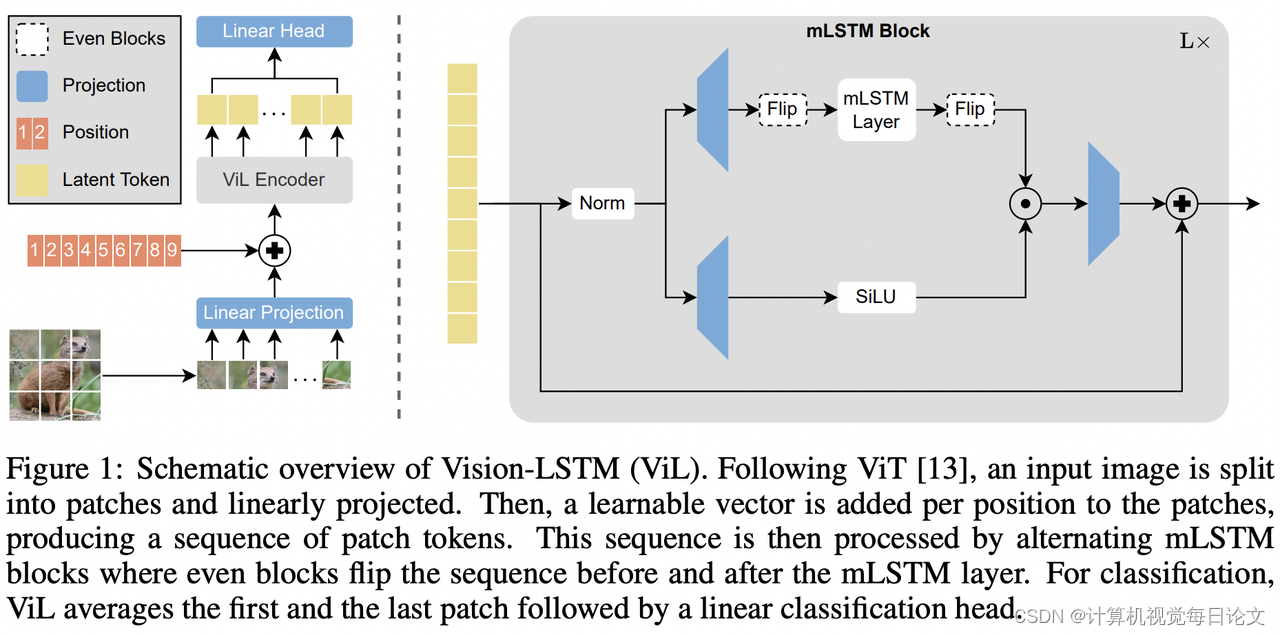
简介:该报告介绍了Vision-LSTM(ViL)模型,它是将可扩展和高性能的长短期记忆(xLSTM)架构适应于计算机视觉的一种方法。
目前,Transformer已经广泛应用于计算机视觉领域,尽管它最初是为自然语言处理而引入的。最近,xLSTM通过指数门控和可并行化的矩阵存储结构克服了长期存在的LSTM的局限性,成为一种可扩展和高性能的架构。
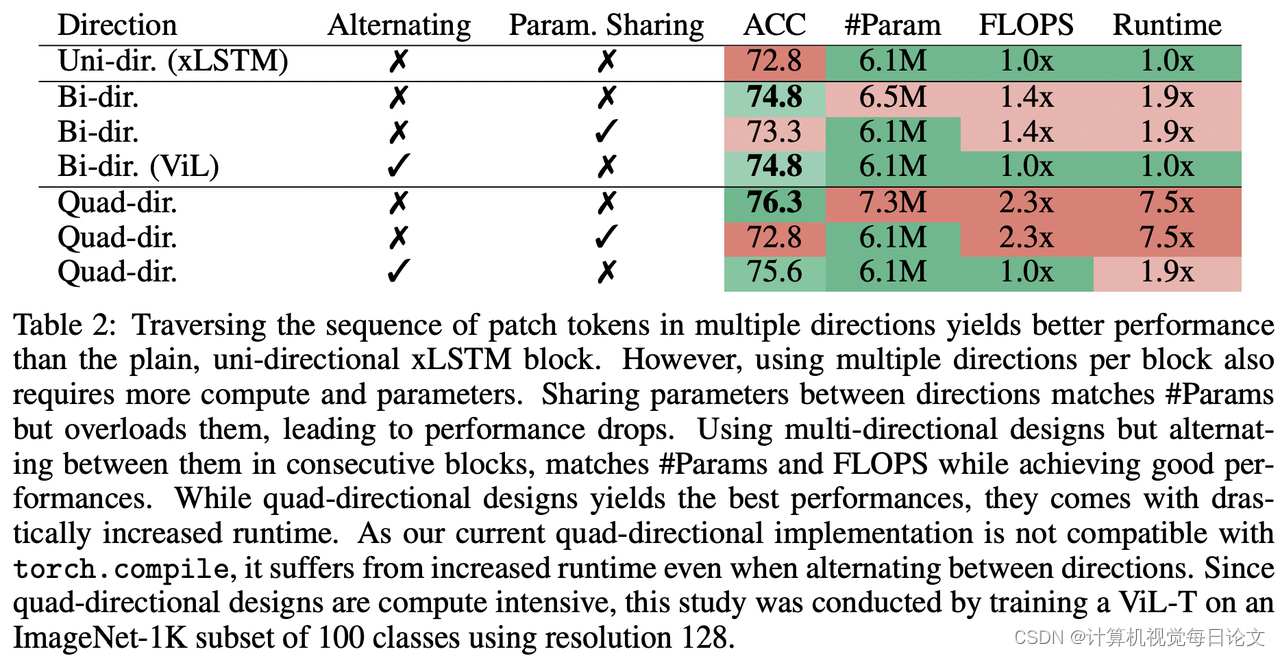
ViL由一堆xLSTM块组成,其中奇数块从上到下处理补丁令牌序列,而偶数块从下到上处理。这种设计旨在利用xLSTM的优势,以期成为计算机视觉领域的新通用骨干网络。
实验结果表明,ViL有望进一步部署为计算机视觉架构的新通用骨干网络。
3、Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
中文标题:自回归模型击败扩散:用于可扩展图像生成的 Llama

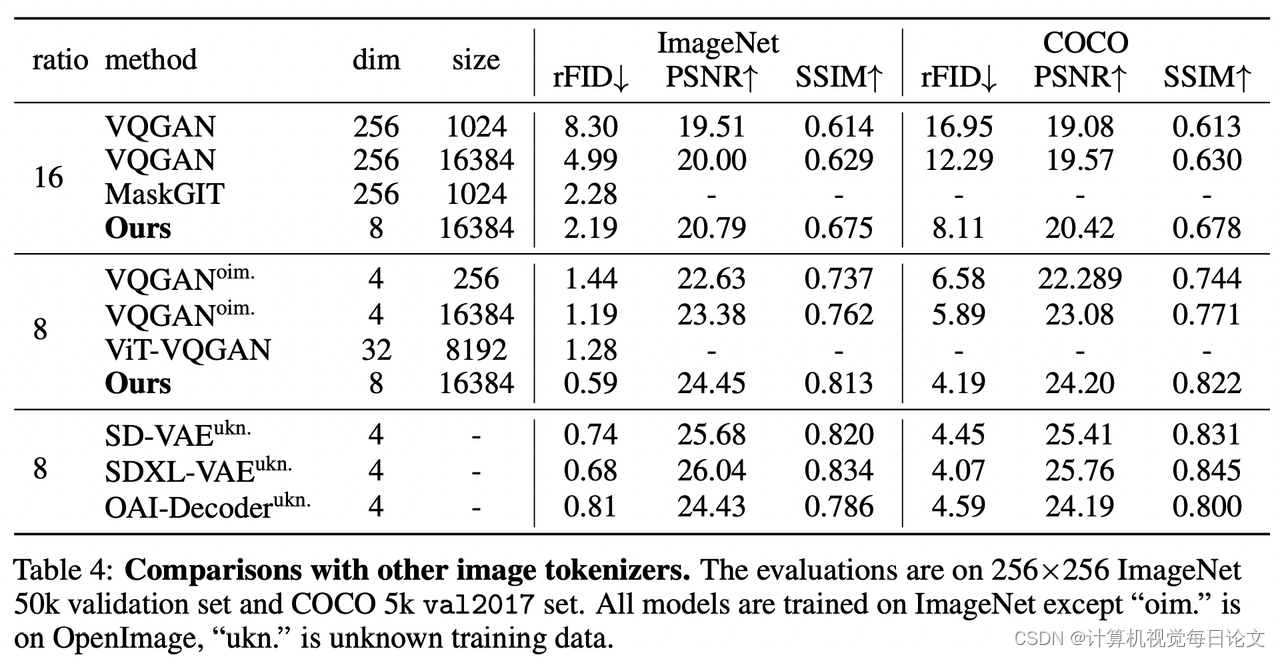
简介:本报告介绍了一种新的图像生成模型系列LlamaGen,它将大型语言模型的"下一个令牌预测"范式应用于视觉生成领域。
该研究探索了图像分词器的设计空间、图像生成模型的可扩展性属性以及训练数据质量等关键问题,取得了以下重要成果:
-
开发了一个图像分词器,下采样比率为16,重构质量为0.94 rFID,在ImageNet基准测试中代码本使用率达到97%。
-
提出了一系列条件类图像生成模型,参数范围从111M到3.1B,在ImageNet 256x256基准测试中达到2.18 FID,优于流行的扩散模型。
-
开发了一种775M参数的文本条件图像生成模型,经过LAION-COCO的两阶段训练,展示了视觉质量和文本对齐的竞争性表现。
-
验证了LLM服务框架在优化图像生成模型推理速度方面的有效性,实现了326%到414%的加速。
该研究表明,没有对视觉信号进行归纳偏置的普通自回归模型(如Llama)在适当缩放的情况下,也能实现最先进的图像生成性能。报告中的所有模型和代码都已发布,促进了视觉生成和多模态基础模型的开源社区。