阿里新发布的UniAnimate,与 AnimateAnyone 非常相似,它可以根据单张图片和姿势指导生成视频。项目核心技术是统一视频扩散模型,通过将参考图像和估计视频内容嵌入到共享特征空间,实现外观和动作的同步。

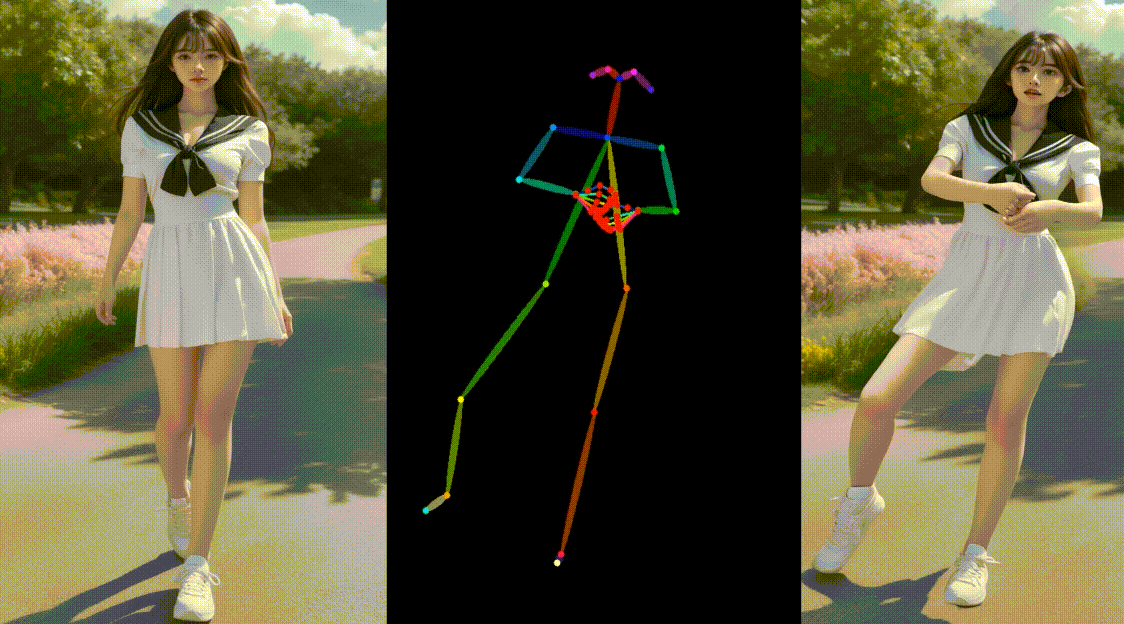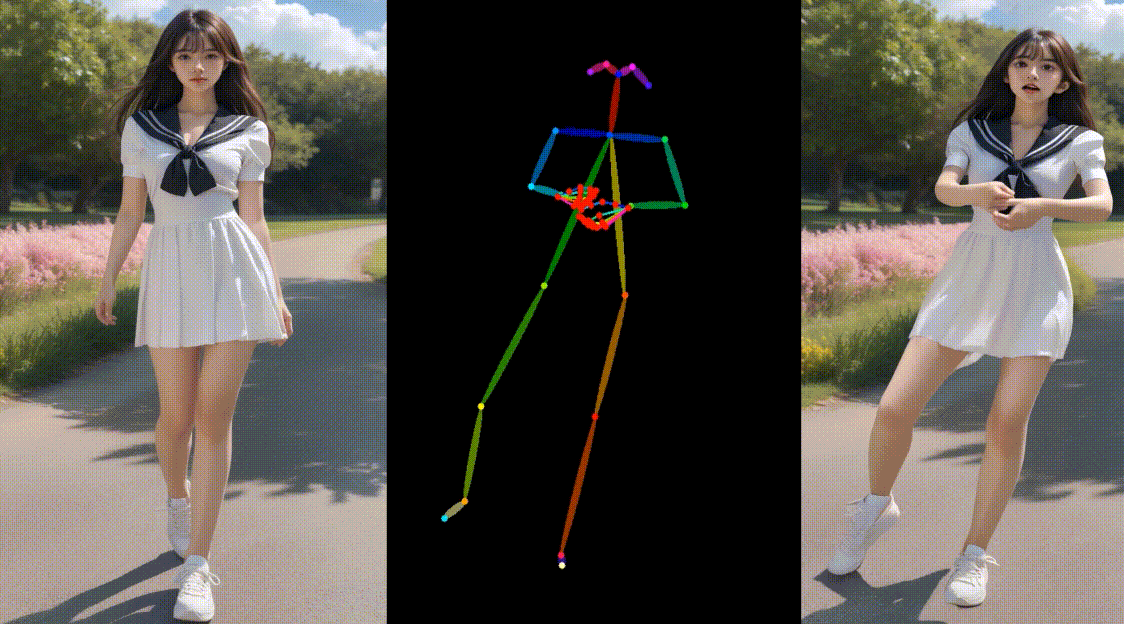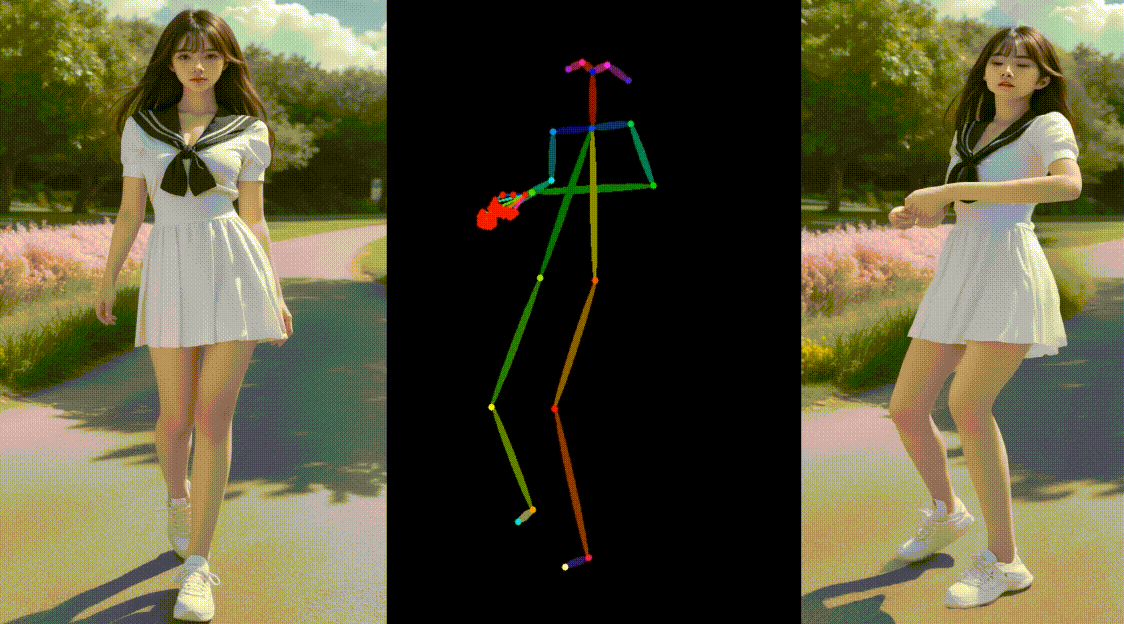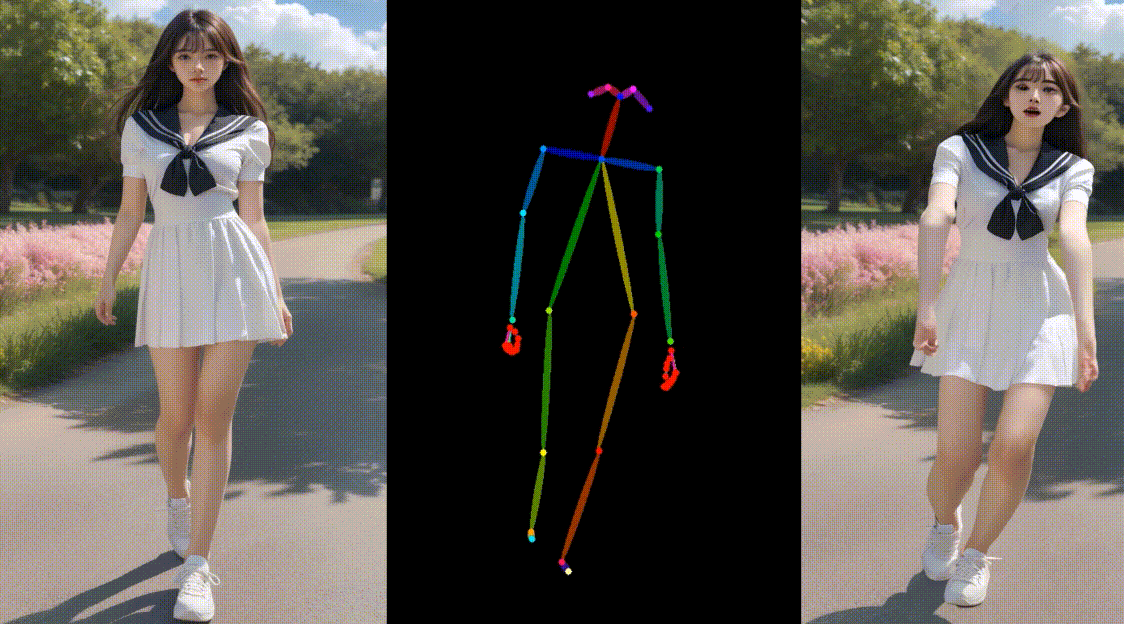
相关链接
代码:github.com/ali-vilab/UniAnimate
论文阅读

利用统一视频传播模型实现一致的人体图像动画
摘要
最近基于扩散的人体图像动画技术在合成完全遵循给定参考身份和所需运动姿势序列的视频方面取得了令人印象深刻的成功。
尽管如此,仍然存在两个限制:
-
需要额外的参考模型来将身份图像与主视频分支对齐,这显著增加了优化负担和模型参数;
-
生成的视频通常时间较短(例如24帧),阻碍了实际应用。
为了解决这些缺点,我们提出了一个 UniAnimate 框架来实现高效和长期的人体视频生成。
首先,为了降低优化难度并确保时间连贯性,我们通过结合统一的视频扩散模型将参考图像与姿势指导和噪声视频一起映射到一个共同的特征空间中。
其次,我们提出了一种统一的噪声输入,它支持随机噪声输入以及第一帧条件输入,从而增强了生成长期视频的能力。
最后,为了进一步有效地处理长序列,我们探索了一种基于状态空间模型的替代时间建模架构,以取代原始的计算耗时的 Transformer。
大量实验结果表明,UniAnimate 在定量和定性评估中都取得了优于现有最先进技术的合成结果。值得注意的是,UniAnimate 甚至可以通过迭代采用第一帧调节策略来生成高度一致的一分钟视频。代码和模型将公开提供。
方法
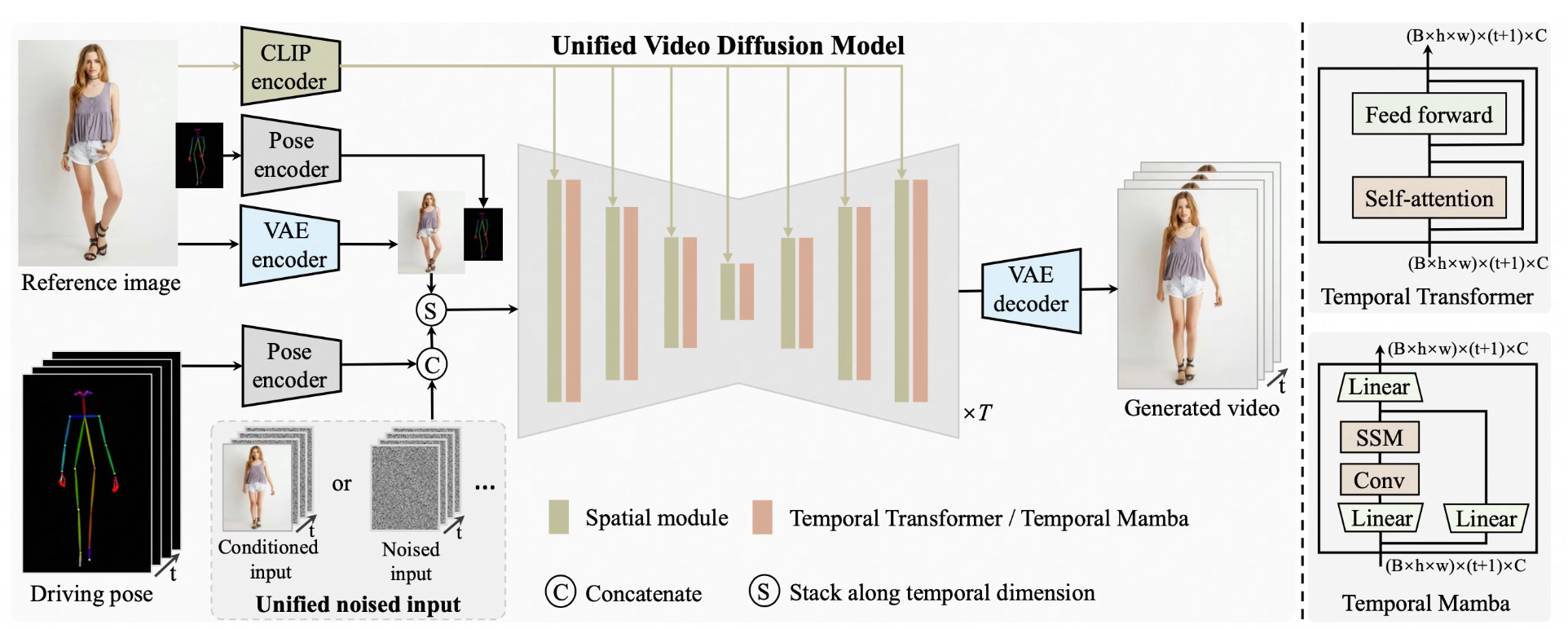
所提出的 UniAnimate 的整体架构。
首先,我们利用 CLIP 编码器和 VAE 编码器提取给定参考图像的潜在特征。为了便于学习参考图像中的人体结构,我们还将参考姿势的表示纳入最终的参考指导中。
随后,我们使用姿势编码器对目标驱动姿势序列进行编码,并将其与沿通道维度的噪声输入连接起来。噪声输入来自第一帧条件视频或噪声视频。
然后,将连接的噪声输入与参考指导沿时间维度堆叠,并输入到统一视频扩散模型中以消除噪声。统一视频扩散模型中的时间模块可以是时间 Transformer 或时间 Mamba。
最后,采用 VAE 解码器将生成的潜在视频映射到像素空间。
实验

为合成模型角色制作动画
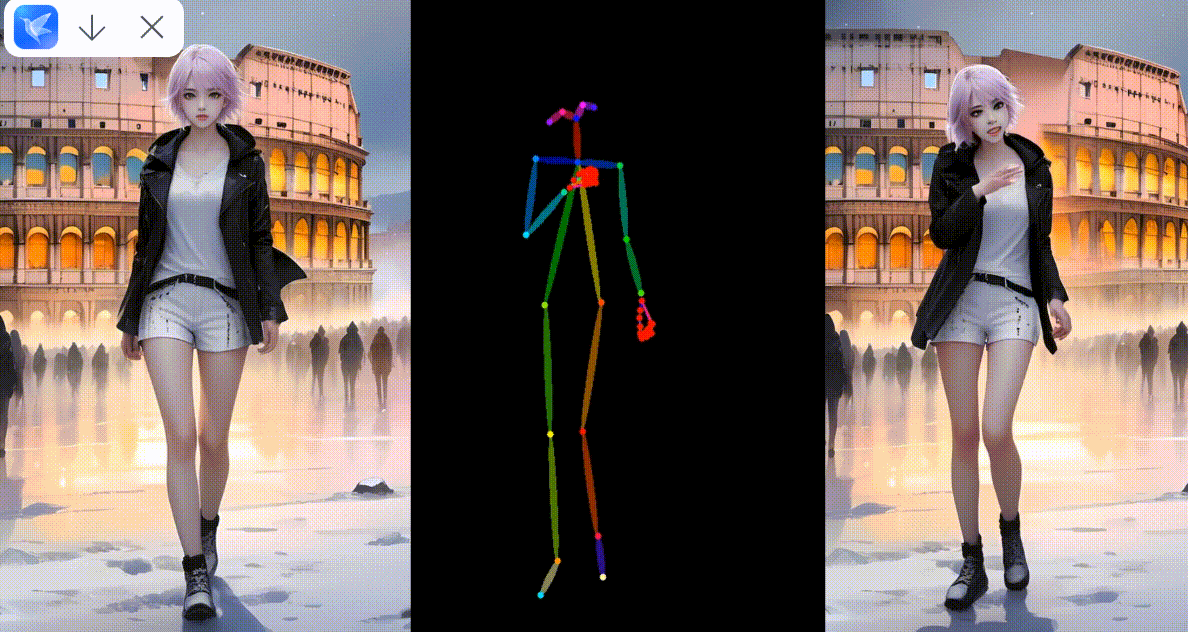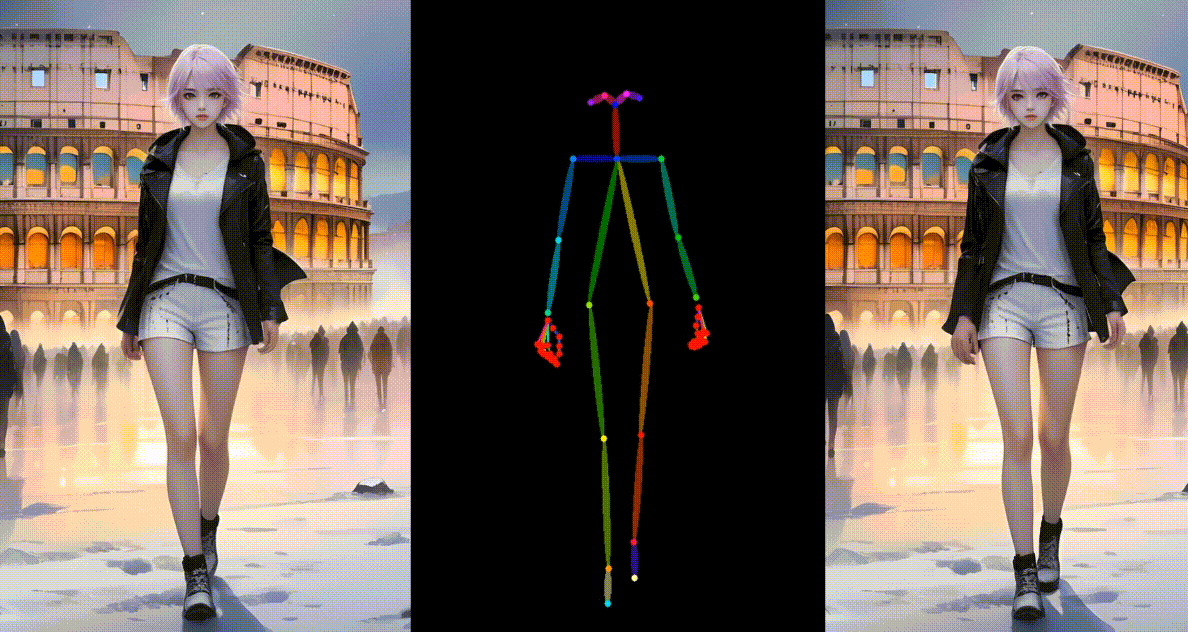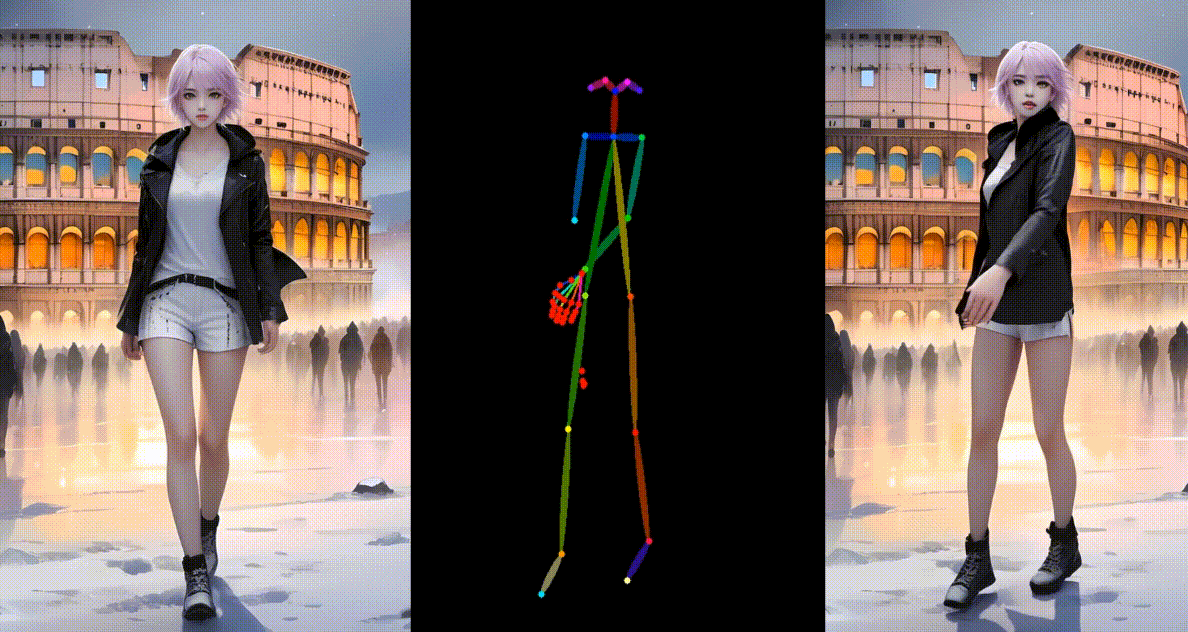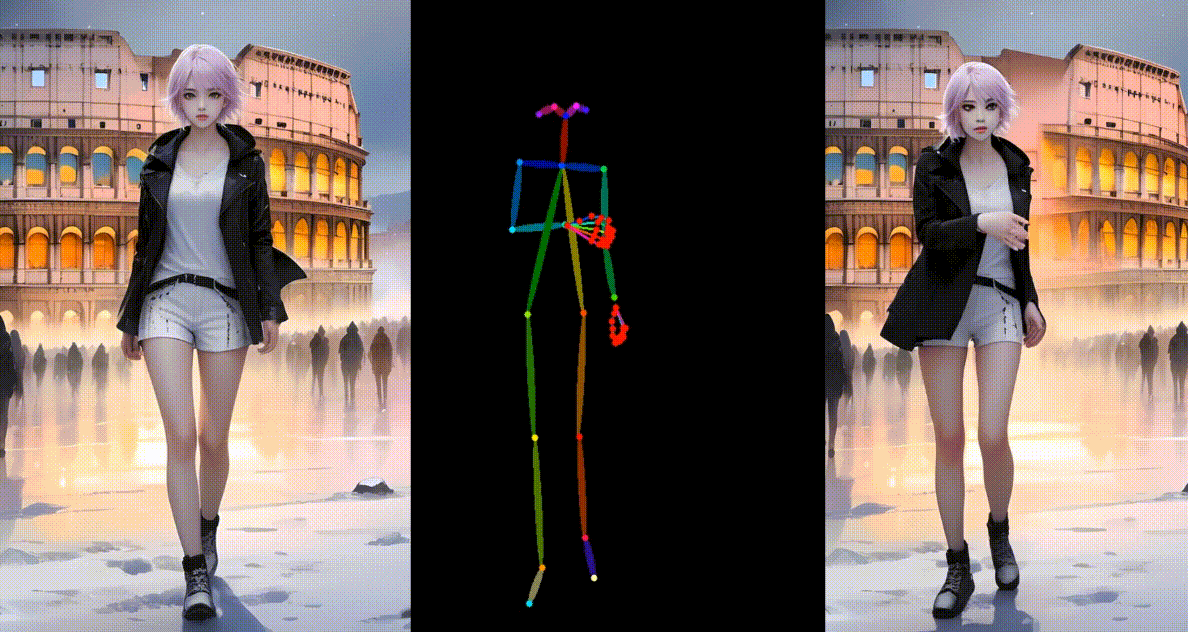
真实模型角色动画
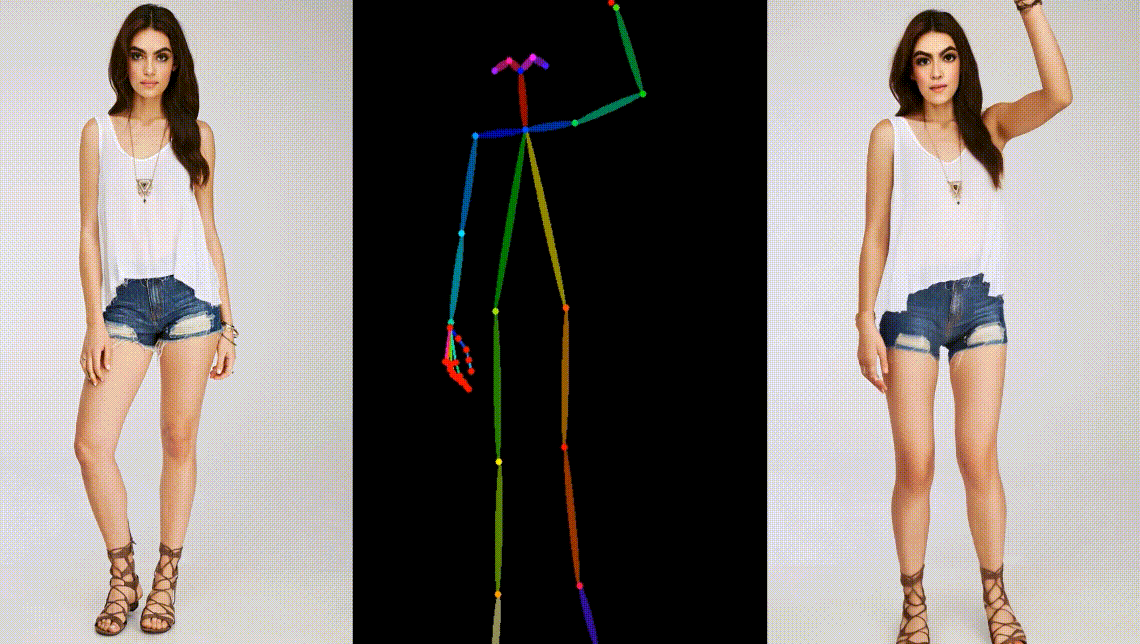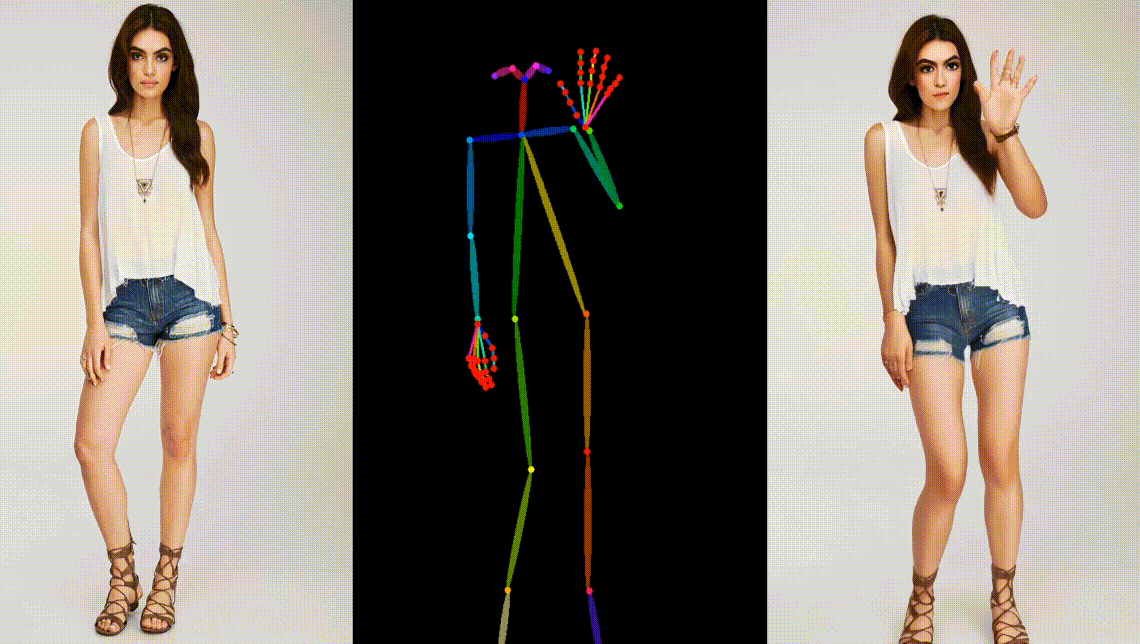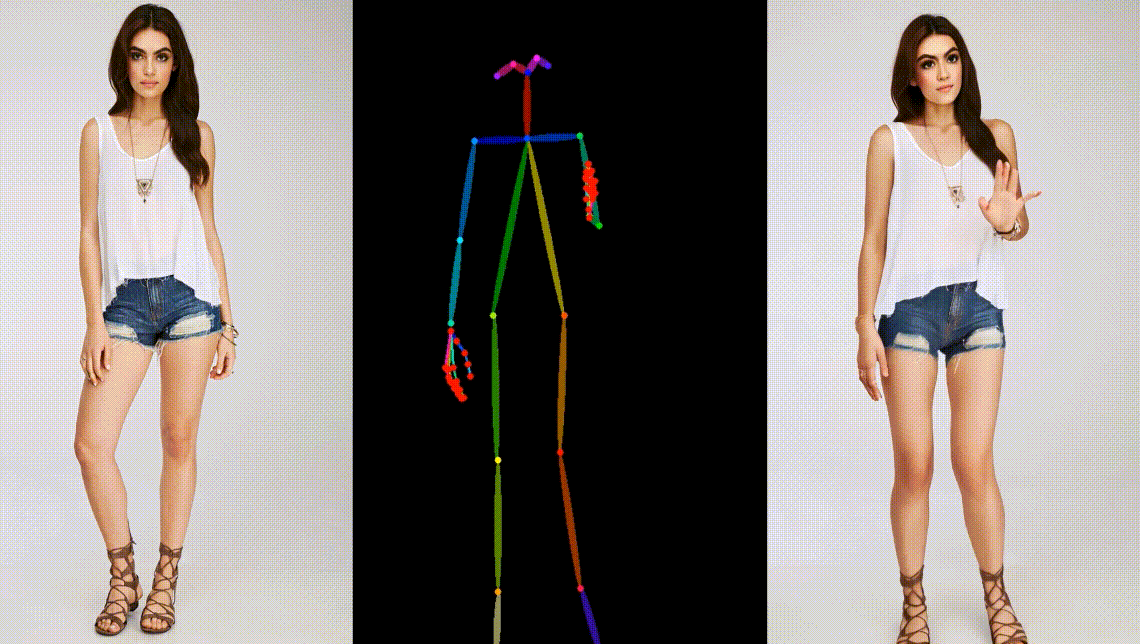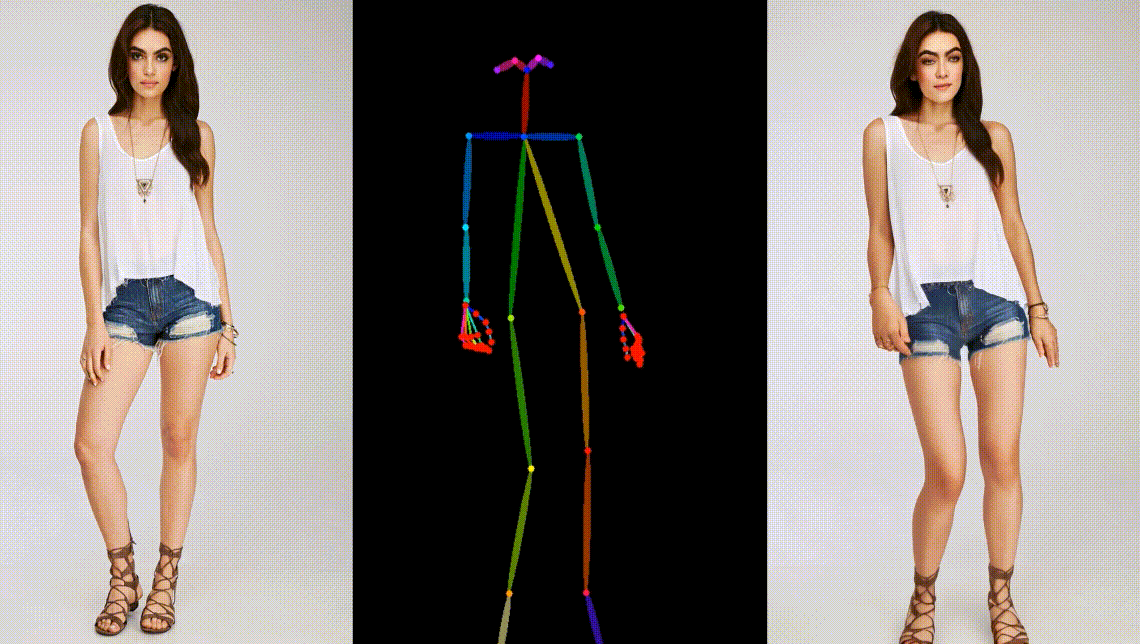
制作粘土风格角色动画

人物:Yann LeCun & Elon Musk

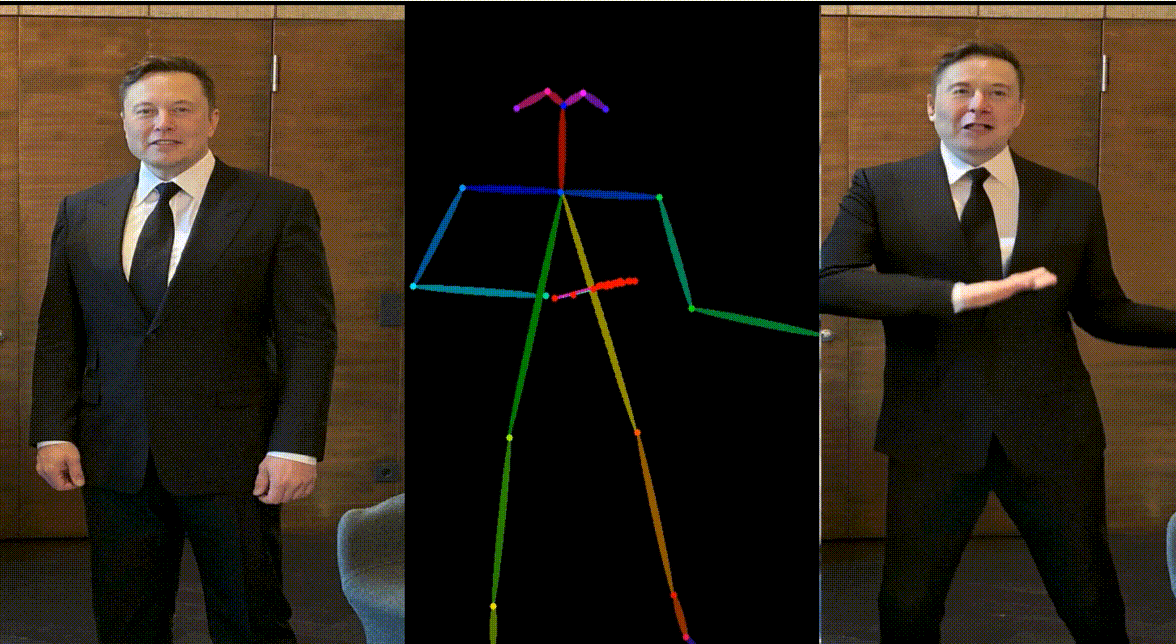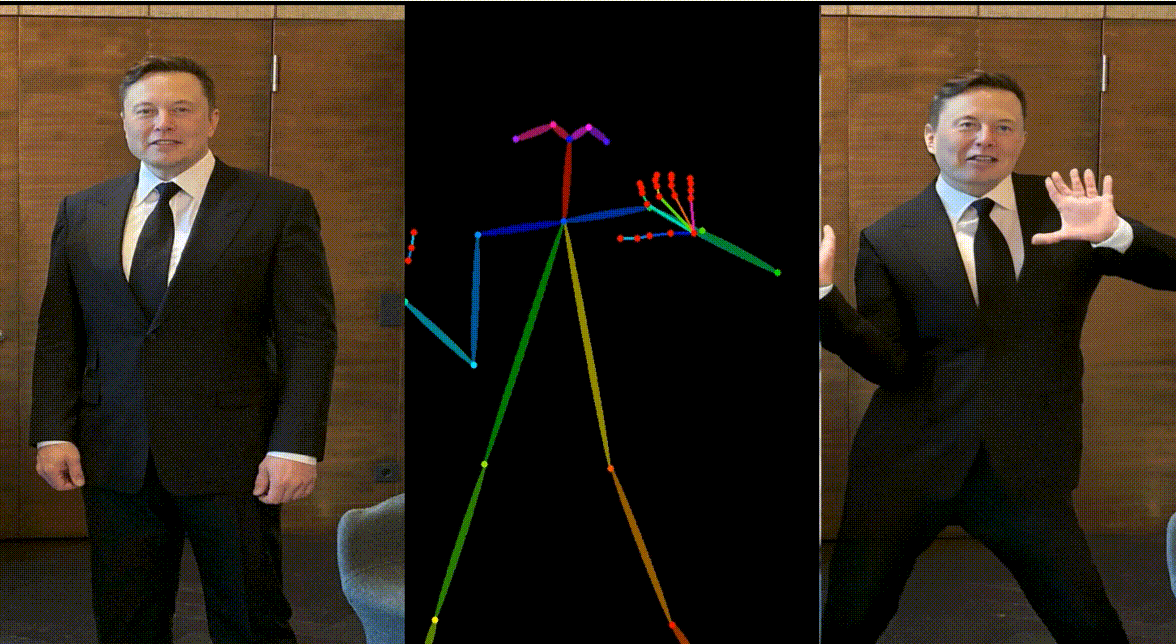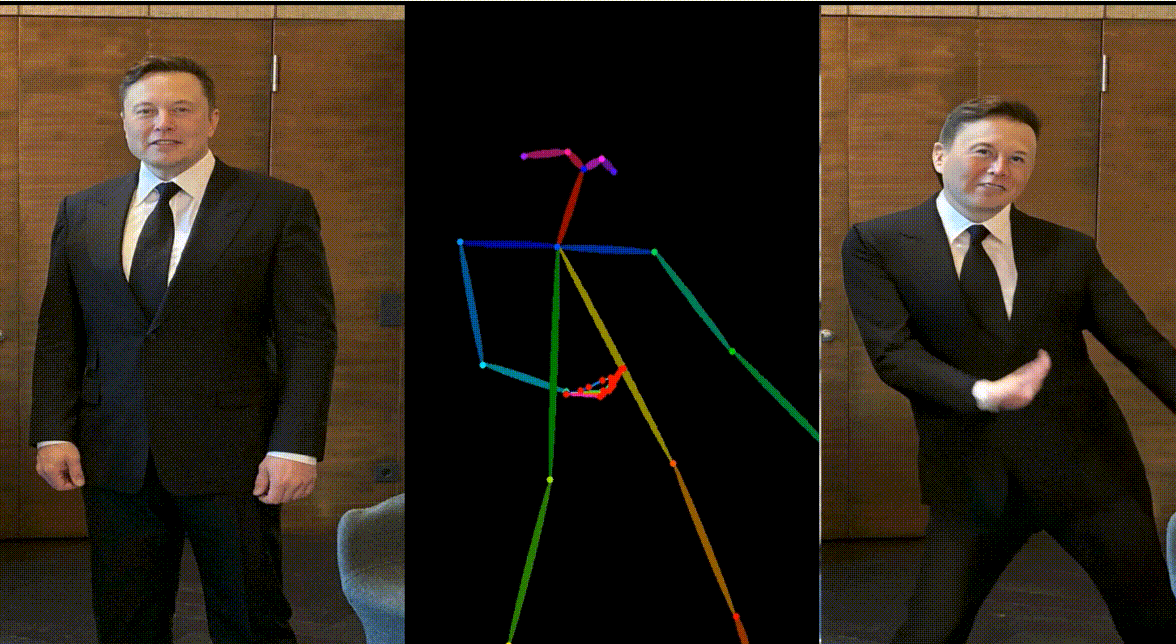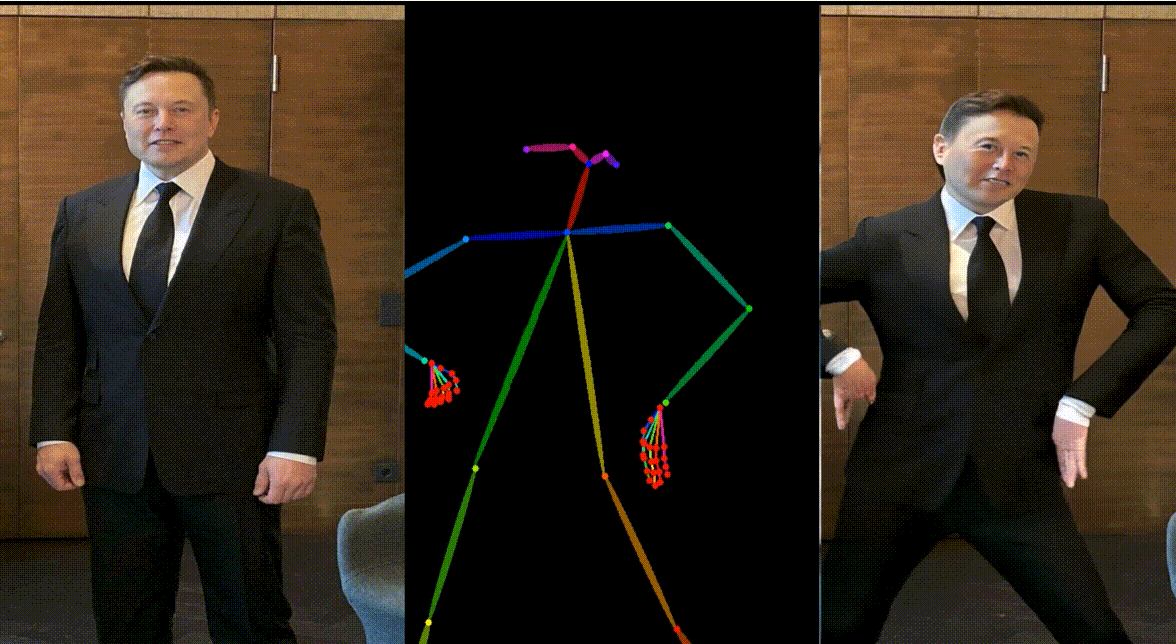
动画其他跨域角色

更多

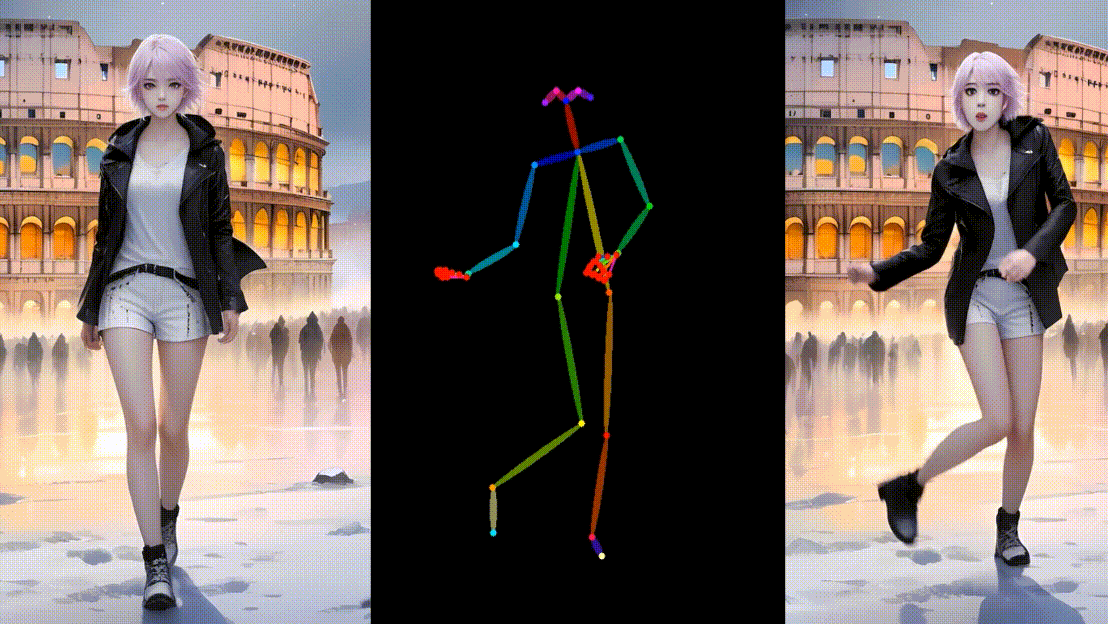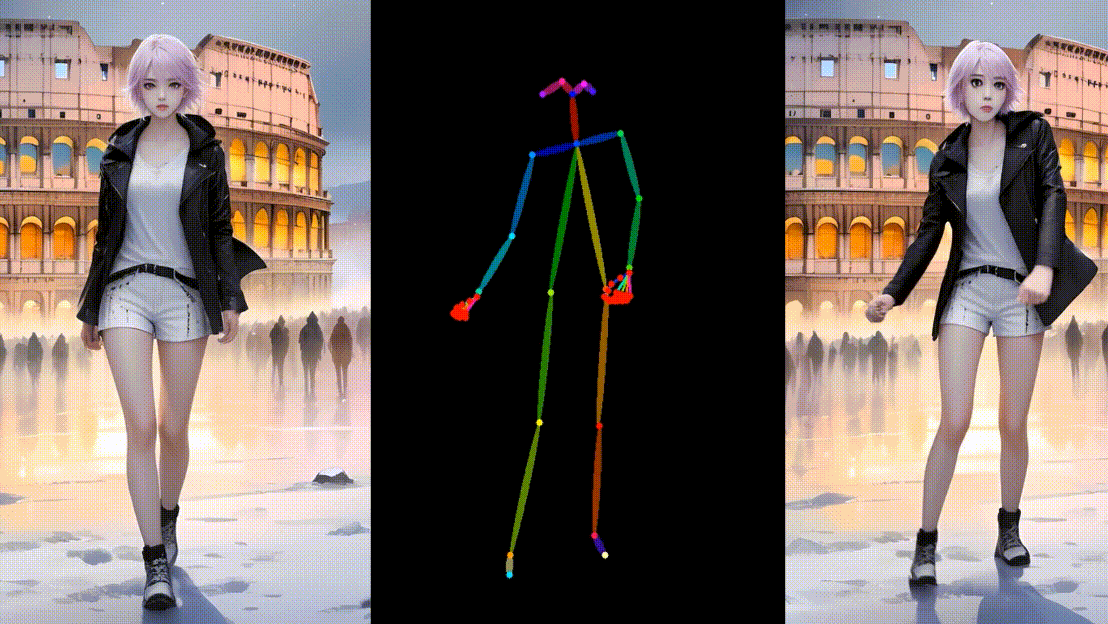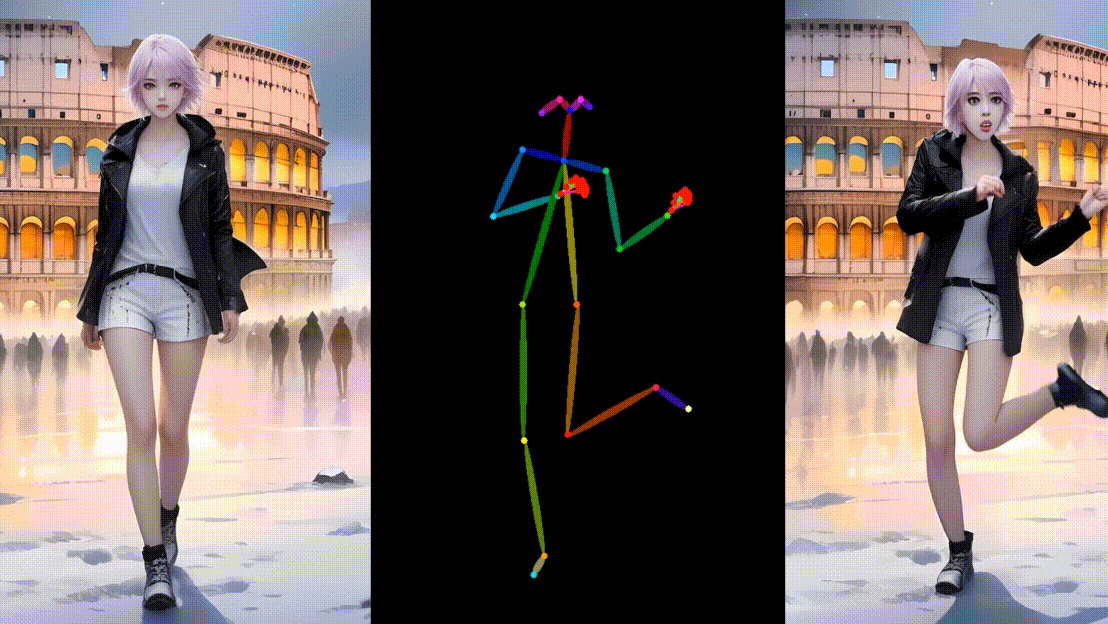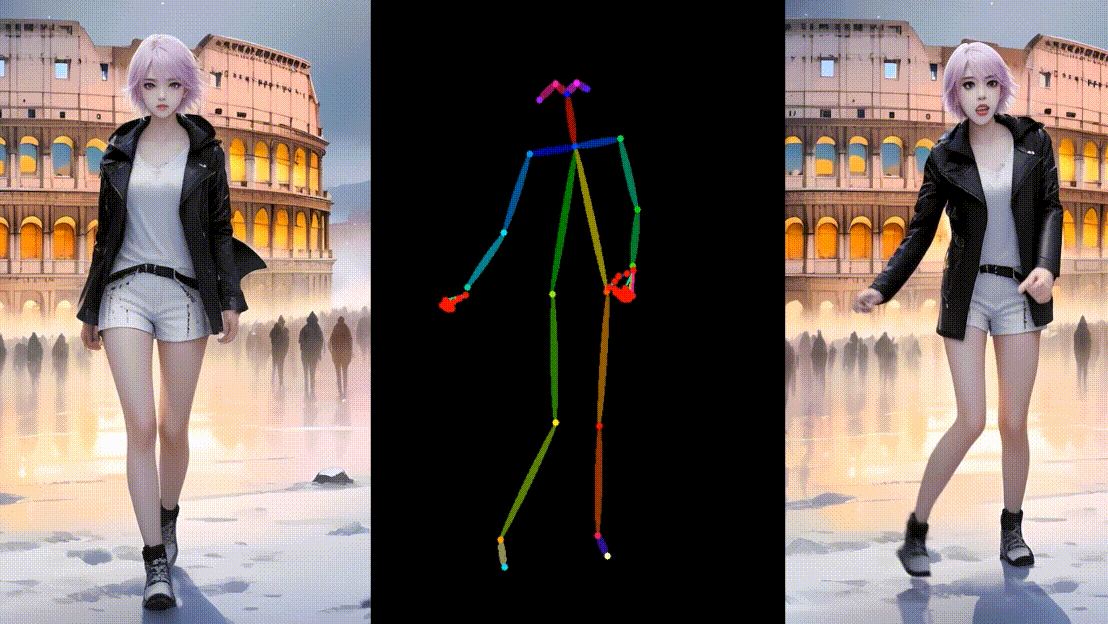
结论
在本文中,我们介绍了 UniAnimate,这是一种用于生成高保真、时间平滑的人体图像动画视频的新方法。通过引入统一视频扩散模型、统一噪声输入和时间 Mamba,我们解决了现有方法的外观错位限制,并提高了视频生成质量和效率。大量实验结果定量和定性地验证了所提出的 UniAnimate 的有效性,并强调了其在实际应用部署中的潜力。